
들어가며
본 시리즈에서는 상향식 접근을 토대로 코루틴의 동작 방식을 알아봅니다.
1편에서는 코틀린 코루틴 간의 협력이 어떻게 이루어지는지를 설명하기 위해, 기본적인 운영체제 개념을 다루었습니다.
2편에서는 동시성을 구현하는 방식의 발전 과정을 살펴보며, 프로세스와 스레드, 코루틴 각각의 장단점과 함께 코루틴을 활용하는 것이 좋은 이유를 설명했습니다.
이번 편에서는 동기와 비동기의 개념을 이해하고, 비동기 원리가 코루틴 동시성 구현에 어떻게 적용되는지 자세히 살펴보겠습니다.
선행 지식
본 편에서 나오는 개념들로, 알아두면 이 글을 이해하는 데 도움이 됩니다.
- 동기(Synchronous), 비동기(Asynchronous) 프로그래밍
이전 편 요약
프로세스
프로세스는 실행 중인 프로그램입니다. 각 프로세스는 코드, 데이터, 힙, 스택의 네 가지 주요 영역으로 구성된 독립적인 메모리 공간을 할당받습니다. 이러한 독립성 덕분에 프로세스는 다른 프로세스의 실행에 영향을 받지 않으며, 다른 프로세스에도 영향을 미치지 않습니다. 프로세스 간 데이터 교환은 IPC(Inter-Process Communication)를 통해 이루어집니다.
프로세스는 생성 및 종료 비용이 크고, 문맥 교환 과정에서의 오버헤드가 큽니다. 또한 운영체제는 프로세스의 메타데이터를 관리하기 위해 각 프로세스마다 PCB(Process Control Block)를 생성합니다. 따라서 단일 실행 흐름을 가진 프로세스로만 동시성을 구현하는 방식은 효율성이 떨어집니다. 이 한계를 극복하기 위해 스레드를 활용할 수 있습니다.
스레드
스레드는 프로세스 내의 실행 흐름으로, 같은 프로세스 내의 여러 스레드는 프로세스의 메모리 공간을 공유합니다. 동시에 각 스레드는 독립적으로 스택을 가지며, 각자 TCB(Thread Control Block)를 관리합니다. 즉 스레드는 프로세스보다 가벼운 실행 단위로, 스레드를 활용하면 프로세스 내에서 동시성을 효율적으로 구현할 수 있습니다.
코루틴
코루틴은 스레드 안에서 실행되는 작업 단위입니다. 코루틴끼리는 운영체제의 개입 없이 동시성을 구현할 수 있습니다. 스레드 내부에서 여러 코루틴을 번갈아 가며 처리함으로써 동시성을 달성할 수 있는 것입니다. 또한 한 코루틴의 중단은 일반적으로 코루틴이 실행되는 스레드의 블로킹으로 이어지지 않습니다. 결국 코루틴을 활용하면 적은 자원 활용과 협력적 멀티태스킹을 통해 스레드보다 더 효율적으로 동시성을 실현할 수 있습니다.
동기와 비동기
🤔 판단 기준 : 작업의 '순서'
A 작업이 B 작업을 실행시켰을 때, A 작업이 B 작업의 응답을 기다리는가?
➡️ A 작업과 B 작업이 완료되는 순서가 항상 고정되어 있는가?
동기 프로그래밍(Synchronous Programming)
순차적인 실행, 실행 순서 고정
➡️ 한 작업이 끝나야 다음 작업을 시작할 수 있음
아래 코드는 동기 프로그래밍의 대표적인 모습입니다.
fun main() {
println("요리 시작~")
cook() // 대기
println("먹어야지~") // 위 코드 라인보다 절대로 먼저 실행되지 않음!
}
fun cook() {
println("요리 끝~")
}요리 시작~
요리 끝~
먹어야지~
해당 코드는 위에서 아래로 순차적으로 실행되며, 각 코드 라인의 실행 순서는 항상 같습니다. main()은 cook()를 호출한 후, cook()이 완료될 때까지 대기합니다.
실행 순서가 보장된다는 특성 덕분에, 실행 흐름이 직관적이고 예측 가능하다는 장점이 있습니다.
Blocking 작업을 동기적으로 실행한다면?
만약 아래 예시처럼 메인 스레드에 오래 걸리는 작업(Blocking)을 동기적(Synchronously)으로 실행하면, 프로그램 전체가 그 작업이 끝날 때까지 멈추게 되며, 반응 속도는 느려질 것입니다.
fun main() {
println("요리 시작~")
cook() // 3초 동안 대기!!
println("먹어야지~")
}
fun cook() {
Thread.sleep(3000)
println("3초...")
println("요리 끝~")
}파일 입출력, 네트워크 통신, 데이터베이스 작업처럼 시간이 오래 걸리는 일을 동기적으로 처리하면, 그 일이 끝날 때까지 프로그램의 다른 부분은 아무것도 할 수 없습니다.
이런 상황에서는 다음과 같은 문제들이 발생할 수 있습니다.
- UI가 있는 프로그램 - 화면이 멈추거나 버튼 클릭 등 사용자 입력에 반응하지 못함
- 서버 프로그램 - 하나의 요청을 처리하는 동안 다른 요청을 받지 못해 여러 사용자를 동시에 지원하지 못함
대표적인 예시가 안드로이드의 ANR(Application Not Responding)입니다. 메인 스레드에서 Blocking 작업을 동기적으로 실행했을 때 5초 이상 응답이 없으면, 시스템이 ANR 오류를 발생시켜 앱을 강제 종료할 수 있습니다.
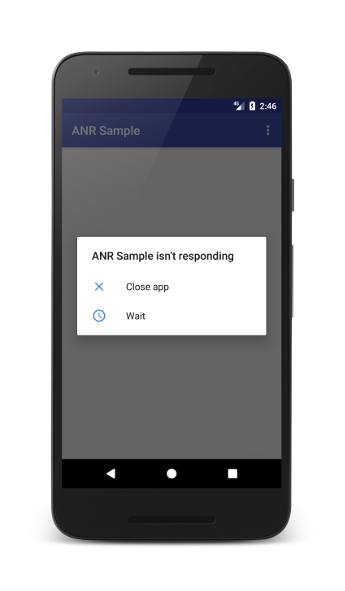
따라서 Blocking 작업을 효율적으로 처리하려면, 다른 방법을 사용해야 합니다.
비동기 프로그래밍(Asynchronous Programming)
한 작업이 끝나기를 기다리지 않고, 바로 다음 작업 시작 가능
유동적인 실행 순서
❓ 퀴즈
아래 코드를 실행하면, 어떤 순서로 출력이 이뤄질까?
fun main() {
println("요리 시작~")
cookAsync() // 대기??
println("먹어야지~")
}
fun cookAsync() {
thread {
println("요리 끝~")
}
}정답은, "시작" 출력 이후의 순서는 확신할 수 없다! 입니다.
실행 결과를 다음과 같이 확인해볼 수 있습니다.

4회에 걸쳐 실행해 보니, 실행 시마다 출력의 순서가 같지 않았습니다.
- 3회 동안,
요리 시작~→먹어야지~→요리 끝~(요리 하면서 먹는 상황?) - 1회 동안,
요리 시작~→요리 끝~→먹어야지~
이유는 작업을 호출하는 쪽(main 함수)에서 호출한 작업(cookAsync 함수)이 끝나기를 기다리지 않기 때문입니다.
cookAsync 함수에서는 "요리 끝~"을 출력하는 작업을 새로운 스레드에 맡기고, main 함수는 작업의 완료 여부와 상관없이 즉시 다음 줄인 println("먹어야지~")를 실행하게 됩니다.
이때 cookAsync() 내부의 작업은 운영체제의 CPU 스케줄링 상황이나 시스템 부하 등에 따라 나중에 실행되기도 하고, 경우에 따라 예상보다 빠르게 완료되기도 합니다.
두 작업이 서로 독립적인 흐름에서 병행 처리되기 때문에, 출력되는 순서는 매 실행마다 다를 수 있던 것입니다. 이것이 비동기 프로그래밍의 주요 특성입니다.
Non-Blocking하게, 비동기로 실행해보자!
앞선 예시에서는 cookAsync 함수에 백그라운드 스레드를 새로 생성하여 작업을 처리함으로써, 비동기를 구현할 수 있었습니다.
해당 코드에 두 가지 요소를 추가해보겠습니다.
- 각 코드가 어떤 스레드에서 실행되는지 확인
- 요리가 3초 동안 걸리는 작업이라고 가정
fun main() {
println(Thread.currentThread().name) // main
println("요리 시작~")
cookAsync()
println("요리 하면서 먹어야지~")
}
fun cookAsync() {
thread {
println(Thread.currentThread().name) // Thread-0
Thread.sleep(3000)
println("요리 끝~")
}
}main
요리 시작~
요리 하면서 먹어야지~
Thread-0
<3초 후...>
요리 끝~
main 측에서 cookAsync를 호출한 이후에도 요리가 완료될 때까지(3초 동안) 기다리지 않고, 즉시 다음 작업인 println(“요리 하면서 먹어야지~”)로 넘어가는 모습입니다.
그리고 "요리 끝~" 메시지는 3초 후에 백그라운드 스레드(Thread-0)에서 출력되었습니다. 즉 작업 호출자인 메인 스레드를 멈추지 않고 이후의 작업을 처리하는 모습으로, 사실 Non-Blocking하게 실행되기도 하는 코드였던 것입니다.
작업을 호출한 측에서,
작업의 완료를 기다리지 않고 (Asynchronous), 기존 작업 흐름을 멈추지 않고 그대로 진행 (Non-Blocking)
이러한 구조를 채택하면, 복잡한 작업들을 효율적으로 처리하면서도 프로그램 전체의 반응성을 유지할 수 있습니다.
UI를 가진 프로그램의 경우, Blocking하면서 동기적으로 실행할 때와는 달리 응답을 기다리는 동안에도 사용자와 상호작용할 수 있을 것입니다. 대표적인 예시가, 서버로부터 데이터를 불러오는 작업(다운로드 등)을 진행하는 와중에도 화면을 정지시키지 않고 사용자가 다른 기능(검색 등)을 활용할 수 있도록 하는 것입니다.
비동기를 구현하는 방법
이전 내용을 통해, 비동기 프로그래밍(+ Non-Blocking)의 필요성을 확인했습니다. 앞선 예시(cookAsync)에서는, 별도의 작업을 비동기로 진행하긴 했지만 작업의 결과를 반환하여 호출자에서 활용하지 않았습니다.
하지만 실제 프로그램을 개발할 때는 비동기 처리로 얻은 결과를 활용해야 하는 상황이 빈번합니다. 서버에서 데이터를 가져오거나 파일을 읽은 후 그 결과를 화면에 표시하는 경우가 대표적인 예시입니다.
문제는 일반적으로 비동기로 구현할 때는 동기적으로 구현할 때처럼 return 문으로 값을 직접 반환하지 않는다는 것입니다. 동기 함수는 결과가 준비될 때까지 실행을 멈추고 기다리지만, 비동기 함수는 작업을 백그라운드에 맡기고 즉시 다음 코드를 실행해야 하기 때문입니다.
// 💩 코드
fun fetchData(): String {
thread {
Thread.sleep(1000)
return "Data" // 컴파일 오류! 스레드에서 반환 불가
}
return "" // 의미 없는 값 반환
}지금부터 비동기 방식으로 실행한 코드의 결과를 가져와 활용할 수 있는 방법과 함께, 그 발전상을 살펴보도록 하겠습니다. 또한 코루틴이 비동기 프로그래밍의 좋은 수단인 이유를 탐구해보겠습니다.
Callback
말 그대로 콜백 함수를 활용하는 방식입니다.
호출자에서는 실행하고자 하는 코드 블록을 미리 전달합니다. 피호출자에서는 작업의 결과가 나오고 나서 넘겨받은 콜백 함수의 매개변수로 결과를 전달해 호출합니다.
fun main() {
println("아무 요리 하나 해주세요~")
cook { dish ->
println("$dish 받았다~ 잘 먹을게요!")
}
println("요리되는 동안 TV 봐야지~")
}
fun cook(onDishReady: (String) -> Unit) {
thread {
println("👨🍳 셰프: 요리 시작!")
println("👨🍳 셰프: 요리 끝!")
onDishReady("라면")
}
}출력 순서를 1000% 확신할 수는 없지만, 코드를 실행하면 다음과 같은 결과를 확인할 수 있습니다.
아무 요리 하나 해주세요~
요리되는 동안 TV 봐야지~
👨🍳 셰프: 요리 시작할게요!
👨🍳 셰프: 요리 끝났어요!
라면 받았다~ 잘 먹을게요!
cook을 호출한 main 함수는 작업이 완료되기를 기다리지 않고, 바로 다음 코드("TV 봐야지~")를 실행하며 비동기적으로 동작합니다.
여기에 콜백(callback)이라는 수단을 도입함으로써, 비동기적으로 실행된 작업의 결과를 호출자에게 전달할 수 있는 통로를 마련했습니다. cook 함수는 라면이 준비된 후, 호출자가 넘긴 콜백 함수를 호출하며 결과를 전달합니다.
이러한 구조에는 중요한 특징이 하나 더 숨어 있는데, 그 힌트는 앞선 문장에 있습니다.
"피호출자에서는 작업의 결과가 나오고 나서 넘겨받은 콜백 함수의 매개변수로 결과를 전달해 호출하는 방식으로 결과를 전달합니다."
별도의 흐름에서 실행되는 작업이라고 하더라도, 콜백 함수의 실행 시점은 언제나 결과가 준비된 이후입니다. 즉 비동기 흐름 속에서도 콜백을 활용하면 결과를 사용해야 하는 코드는 반드시 결과가 준비된 뒤에 실행되도록 순서를 보장할 수 있다는 의미입니다.
물론, 결과값 전달이 필요 없는 경우에도 콜백을 활용할 수 있습니다. 특정 작업이 끝난 시점에 실행될 동작을 등록하는 용도로 활용할 수 있는 것입니다. 예를 들어, 단순히 “요리 잘 먹을게요!”라는 메시지를 표시하는 상황을 생각해볼 수 있습니다.
fun main() {
println("아무 요리 하나 해주세요~")
cook {
println("요리 잘 먹을게요!")
}
println("요리되는 동안 TV 봐야지~")
}
fun cook(onFinished: () -> Unit) {
thread {
println("👨🍳 셰프: 요리 시작합니다!")
println("👨🍳 셰프: 요리 끝났습니다!")
onFinished() // 완료 시점에 콜백 호출
}
}아무 요리 하나 해주세요~
요리되는 동안 TV 봐야지~
👨🍳 셰프: 요리 시작합니다!
👨🍳 셰프: 요리 끝났습니다!
요리 잘 먹을게요!
콜백은 비동기 작업 결과 전달의 역할을 넘어, 비동기 작업 중 특정 시점을 기준으로 후속 동작을 예약하는 수단으로도 작동합니다.
콜백 지옥
나도 한 번 쏴본다 장풍!!
모 기업의 채용 프로세스를 진행했을 때, 팀의 관리자께서 인터뷰어로 참석하셨습니다. 마지막으로 궁금한 점을 물어볼 수 있는 시간이 주어졌고, 평소 늘 고민해왔던 질문을 드렸습니다. 그때 돌아온 답변은 생각보다 간결했지만, 그동안 생각해왔던 좋은 코드의 정의를 송두리째 바꿔주었습니다.
🤔 : “어떤 코드가 좋은 코드라고 생각하시나요? 제가 생각하는 좋은 코드는 ... ”
🧑🏫 : "그냥 잘 읽히는 코드가 좋은 코드다. 개발자는 코드를 읽는 데 업무 시간의 상당수를 사용하기 때문이다."콜백 지옥이 그 '잘 읽히는 코드'의 대척점에 있는 것이 아닌가 싶습니다.
요리가 완성되기까지의 여러 과정을 비동기적으로 표현해 보았습니다.
👀 아래 코드의 결과를 예측해보시길 바랍니다!
fun main() {
println("요리 시작~")
cook { ingredient ->
println("$ingredient 준비 완료~")
boil(ingredient) { boiled ->
println("$boiled 끓이기 완료~")
season(boiled) { seasoned ->
println("$seasoned 양념 완료~")
serve(seasoned) { dish ->
println("$dish 완성! 이제 먹자~")
}
println("$seasoned 양념까지 했으니 거의 다 됐네")
}
println("$boiled 끓이느라 고생했어")
}
}
println("요리하면서 TV나 보자~")
}
fun cook(onPrepared: (String) -> Unit) {
thread {
Thread.sleep(300)
onPrepared("재료 ${Random.nextInt(100)}")
}
}
fun boil(ingredient: String, onBoiled: (String) -> Unit) {
thread {
Thread.sleep(300)
onBoiled(ingredient)
}
}
fun season(ingredient: String, onSeasoned: (String) -> Unit) {
thread {
Thread.sleep(300)
onSeasoned(ingredient)
}
}
fun serve(ingredient: String, onServed: (String) -> Unit) {
thread {
Thread.sleep(300)
onServed(ingredient)
}
}요리 시작~
요리하면서 TV나 보자~
재료 88 준비 완료~ (재료 숫자는 랜덤)
재료 88 끓이기 완료~
재료 88 끓이느라 고생했어
재료 88 양념 완료~
재료 88 양념까지 했으니 거의 다 됐네
재료 88 완성! 이제 먹자~
위 코드는 단순한 요리 시뮬레이션임에도 불구하고, 콜백이 중첩되며 들여쓰기가 깊어져 코드의 흐름을 한눈에 파악하기 어렵습니다. 이런 형태를 콜백 지옥(Callback Hell)이라고 부릅니다.
😏 : "나는 읽기 쉬웠는데?"
콜백 지옥의 무서움은 그 규모가 커지고 복잡해질수록 더 크게 와닿을 것입니다. 또한 중첩된 콜백으로 읽기 복잡해진 코드는 아래의 추가적인 문제들을 파생시킬 수 있습니다.
1️⃣ 복잡한 에러 핸들링
콜백 내부에서 예외가 발생할 수 있는 작업을 수행할 때, 각 콜백마다 별도로 예외 처리를 해주어야 합니다.
중첩이 이뤄질 때마다 이러한 코드가 추가된다면 예외가 어디서 발생했는지 추적하기 어려워집니다. 또한, 공통적인 예외 처리 로직(리소스 정리, 로그 전송 등)이 있어도 중복해서 명시해 주어야 하므로 유지보수가 까다로워집니다.
boil(ingredient) { boiled ->
try {
println("$boiled 끓이기 완료~")
season(boiled) { seasoned ->
try {
println("$seasoned 양념 완료~")
serve(seasoned) { dish ->
println("$dish 완성!")
}
} catch (e: Exception) {
// 예외 처리 1
println("서빙 중 에러")
// 공통 처리 중복 명시 1
handleError(e)
}
}
} catch (e: Exception) {
// 예외 처리 2
println("양념 중 에러")
// 공통 처리 중복 명시 2
handleError(e)
}
}
fun handleError(t: Throwable) { /* ... */ }2️⃣ 메모리 누수
cook 함수를 안드로이드 개발에 활용하는 상황을 가정해보겠습니다.
콜백이 Activity 등 생명주기를 가진 객체를 참조하고 있는 상태에서, 작업이 완료되기 전 해당 객체가 파괴되면 참조가 해제되지 않아 메모리 누수(memory leak)로 이어질 수 있습니다.
fun cook(
context: Context, // ActivityContext
onDone: () -> Unit
) {
thread {
Thread.sleep(1000)
// 실행 중, Activity가 종료되어 context가 파괴되었을 가능성 존재!
Toast.makeText(context, "요리 완료!", Toast.LENGTH_SHORT).show()
onDone()
}
}
class CookingActivity : AppCompatActivity() {
// ...
fun startCooking() {
cook(this) { // ActivityContext 전달
// ...
}
}
}Coroutines
비동기적인 작업을 동기적인 코드로 작성할 수 있도록 하는 수단
앞서 살펴본 콜백 지옥과 같은 구조는 코드 가독성, 예외 처리, 메모리 누수 등 다양한 문제를 발생시킬 수 있습니다. 이를 해결하기 위해 코루틴(Coroutines)을 활용할 수 있습니다.
코루틴을 활용하면, suspend 키워드를 통해 비동기 작업을 마치 순차적으로 실행되는 동기 코드처럼 작성할 수 있게 해줍니다. 이를 통해 복잡한 중첩 없이도 흐름을 명확히 표현할 수 있고, 각 작업의 순서를 직관적으로 파악할 수 있습니다.
fun main() = runBlocking {
println("요리 시작~")
val ingredient = ingredient()
println("$ingredient 준비 완료~")
val boiled = boil(ingredient)
println("$boiled 끓이기 완료~")
val seasoned = season(boiled)
println("$seasoned 양념 완료~")
val dish = serve(seasoned)
println("$dish 완성! 이제 먹자~")
}
suspend fun ingredient(): String {
delay(3000)
return "재료 ${Random.nextInt(100)}"
}
suspend fun boil(ingredient: String): String {
delay(3000)
return ingredient
}
suspend fun season(ingredient: String): String {
delay(3000)
return ingredient
}
suspend fun serve(ingredient: String): String {
delay(3000)
return ingredient
}생명주기 자동 관리
안드로이드 개발에서는 코루틴의 스코프(scope)를 적절히 활용하면 메모리 누수 없이 안전하게 작업을 처리할 수 있습니다.
// 뷰모델이 onCleared() 될 때 코루틴도 자동으로 취소
viewModelScope.launch { ... }// 액티비티/프래그먼트의 생명주기에 따라 자동 관리
lifecycleScope.launch { ... }Main-safe한 suspend 함수
Retrofit이나 Room에서 제공하는 suspend 함수는 내부적으로 백그라운드 스레드에서 실행되도록 구성되어 있으며, 메인 스레드에서 안전하게 호출할 수 있도록 설계되어 있습니다.
Retrofit사용 시
suspend fun fetchData(): ResponseRoom사용 시
suspend fun getUsers(): List<User>코루틴을 활용하면 비동기 로직을 안전하고 깔끔하게 처리할 수 있습니다. 특히 Android 개발에서는 lifecycleScope, viewModelScope와 함께 사용하여 생명주기를 인식하고, Main-safe한 suspend 함수를 적극 활용함으로써 안정적이고 유지보수가 쉬운 코드를 작성할 수 있게 됩니다.
마치며
다음 시리즈에서는 본 시리즈에서 살펴보았던 원리들을 바탕으로 코틀린 코루틴 라이브러리의 구현을 자세히 살펴보도록 하겠습니다.

한번 더 정리되는 느낌입니다. 감사합니다.