Network
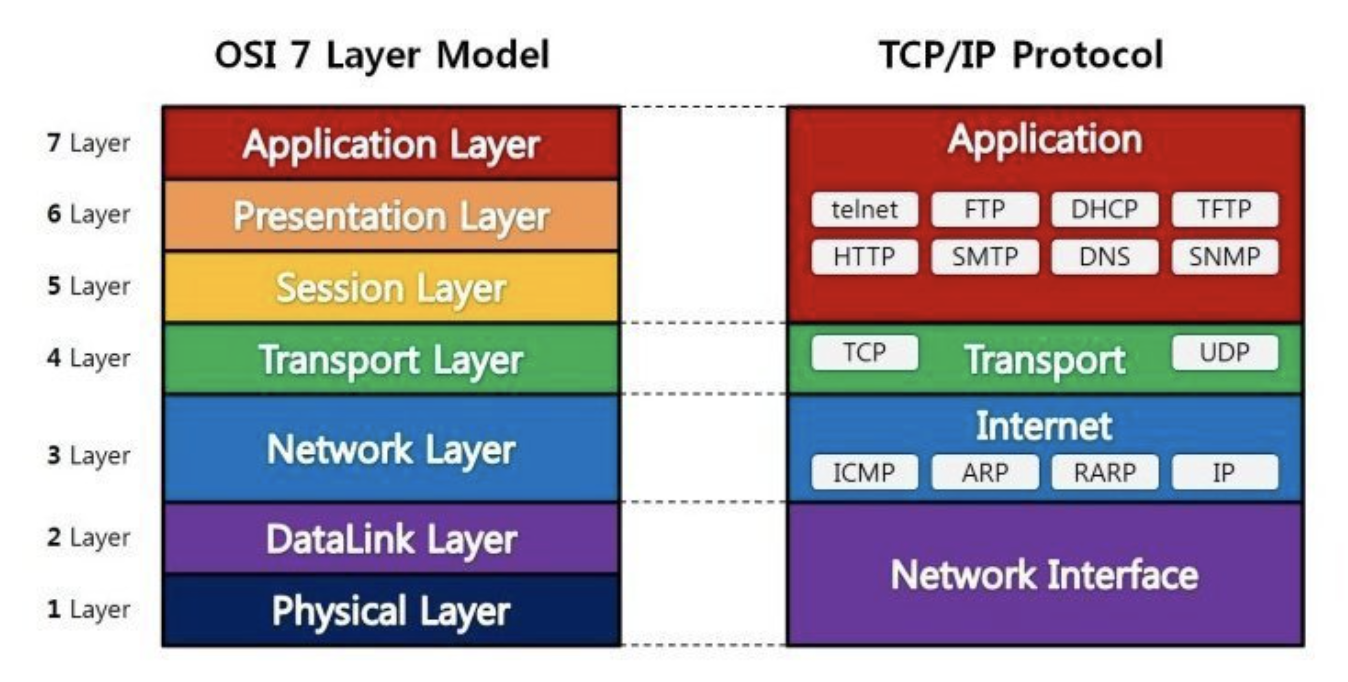
Network 7계층
계층이 있는 이유?
계층을 나눈 이유는 통신이 일어나는 과정이 단계별로 파악할 수 있기 때문이다.
흐름을 한눈에 알아보기 쉽고, 사람들이 이해하기 쉽고,
7단계 중 특정한 곳에 이상이 생기면 다른 단계의 장비 및 소프트웨어를 건들이지 않고도 이상이 생긴 단계만 고칠 수 있기 때문이다.
-
물리 계층
통신 케이블/리피터/허브로 데이터를 전송, 비트단위로 전송(1,0)
데이터 전달만 할뿐 데이터가 무엇인지, 어떤 에러가 있는지 신경 X -
데이터 링크 계층
물리계층에서 송수신 되는 정보의 오류와 흐름을 관리해 안전히 정보전달을 할 수 있도록 하는 역할.
통신의 오류도 찾고, 재전송도함.
맥주소(프레임의 물리적 주소)를 통해 통신함 -
네트워크 계층
데이터를 목적지까지 안전하고 빠르게 전달하는 기능(라우팅)
주소부여(IP), 경로 설정(라우팅) -
전송 계층
통신을 활성화 하기 위한 계층, TCP프로토콜을 보통이용
TCP (Transmission Control Protocol)
데이터가 반드시 전달되는 것을 보장하는 프로토콜로 다음 특징들을 갖는다
- 연결지향(Connection-oriented) 으로 2개의 호스트가 통신을 하기 전 연결이 이루어져야 한다.
- 높은 신뢰성(Reliability) 과 순서대로 전송하는 것(In-order delivery) 을 보장한다.
- 흐름 제어(Flow control) 를 통해 송신자의 데이터 양을 조절한다.
- 혼잡 제어(Congestion control) 를 통해 네트워크 상황을 감지하고 송신자의 데이터 양을 조절한다.
- 전 이중(Full duplex) 방식 으로 두 호스트 모두 송신자와 수신자가 될 수 있다.
UDP (User Datagram Protocol) --> TCP와 반대, 빠름, 일을 안하니까
- TCP와 달리 데이터의 신뢰성을 보장하지 않는 프로토콜이며 다음 특징들을 갖는다.
- 비연결형(Connection-less) 으로 연결을 설정하고 해제하는 과정이 없다.
- 신뢰성이 없고 전송되는 데이터의 순서를 보장하지 않는다.
- 흐름제어, 혼잡제어가 없다.
- 에러감지는 헤더의 체크섬(Checksum)을 이용한 정도밖에 없다.
- 서버와 클라이언트는 유니캐스트(1:1), 브로드캐스트(1:N), 멀티캐스트(1:M)가 가능하다. (N은 전체, M은 일부)
- TCP에 비해서 하는 작업들이 굉장히 적기 때문에 속도가 빠르다.
- DNS, DHCP, 비디오/오디오 스트리밍 등에 사용된다.
- 세션 계층
데이터가 통신하기 위한 논리적인 연결. 통신하기 위한 대문.
6. 표현 계층
데이터 표현이 상이한 프로세스의 독립성을 제공하고 암호화 함.
코드간의 번역을 담당함
인코딩/디코딩하는부분, 해당 데이터가 TExt인지, 그림인지 구분해줌
- 응용계층
최종목적지임. HTTP, SMTP, POP3 등 프로토콜이있음
모든 통신의 양끝은 HTTP와 같은 프로토콜임. 응용프로그램이 아님.
HTTP
- 웹상에서 웹 서버<-->브라우저 상호간의 데이터 전송을 위한 응용계층 프로토콜
- HTML 문서, 이미지, 영상, 오디오, 텍스트등 주고받음
동작방식
클라이언트: 브라우저를 통해 서버에 요청( 프로토콜 + 도메인 + URL)
서버 : 클라이언트로 받은 요청을 처리하여 결과 응답
HTTP 특징
1)Connectionless + Stateless
- 1번 요청-응답후 연결 해제
- 클라이언트의 이전상태 알수 없음(쿠키/세션이 필요함)
2)Keep-Alive
- 1번의 요청에 1번 응답한 기준으로 HTTP는 설계되어있음(하지만 한페이지에 수십개의 이미지,css,js파일로 구성되어 있음)
- 1요청 1응답기준 연결을 붙였다 끊었다 비효율적
- 그래서 지정된 시간 동안 연결을 끊지않고 유지함
REST API란?
HTTP요청을 보낼때 어떤 URI에 어떤 method를 사용할지 사용하는 규약 (GET, POST, DELETE, PATCH)
강점 : 메소드와 URL을 조합해서 예측가능하고 일정한 요청을 보낼 수 있음!
REST란??
어떤 자원에 대해 CRUD(Create, Read, Update, Delete) 연산을 수행하기 위해 URI(Resource)로 요청을 보내는 것
REST의 특징
1. Uniform Interface(일관된 인터페이스)
통일된 요청으로 특정언어나 기술,플램폼에 종속되지 않아 모든 HTTP플랫폼에서 사용가능
2. Stateless(무상태성)
각각의 요청은 별개임 --> 이전요청이 다음 요청에 연관 X --> 세션/쿠키 활용 하여 상태저장 X
3. Client-Server Architecture (서버-클라이언트 구조)
두 관계간 역할을 구분하여 서로 의존성을 줄임
- 서버: API 제공
- 클라이언트 : 사용자인증, 세션, 로그인정보등 관리
4. Self-Descriptiveness(자체 표현)
요청만 보고도 이를 쉽게 이해할수 있는 구조임(Post, Put 등)
Restful APi와 GraphQL 차이점
RestFul API - Rest 규약을 잘 지키면서 설계한 API를 제공하는것
- CRUD 요청을 할떄 요청을 위한 URI와 Method, 어떻게 보낼지(JSON)을 사용하면 명확해지므로 이를 REST라고 함
RestFul API의 구성요소
- Resource - 서버는 Unique한 ID를 가지는 Resource를 가지고 있으며, 클라이언트는 이러한 Resource(URI)에 요청을 보냅니다.
- Method - CRUD 연산에 맞는 method를 서버에 보내야함(Delete,patch,put,post)
- Representation of state - 클라이언트 <-> 서버가 데이터를 주고 받는 형태 ( Json, xml, text 등)
참고 Q) URI 과 URL의 차이점은?
- URL은 Uniform Resource Locator로 인터넷 상 자원의 위치를 의미합니다. 자원의 위치라는 것은 결국 어떤 파일의 위치를 의미합니다.
- URI는 Uniform Resource Identifier로 인터넷 상의 자원을 식별하기 위한 문자열의 구성으로, URI는 URL을 포함하게 됩니다. 그러므로 URI가 보다 포괄적인 범위라고 할 수 있습니다.
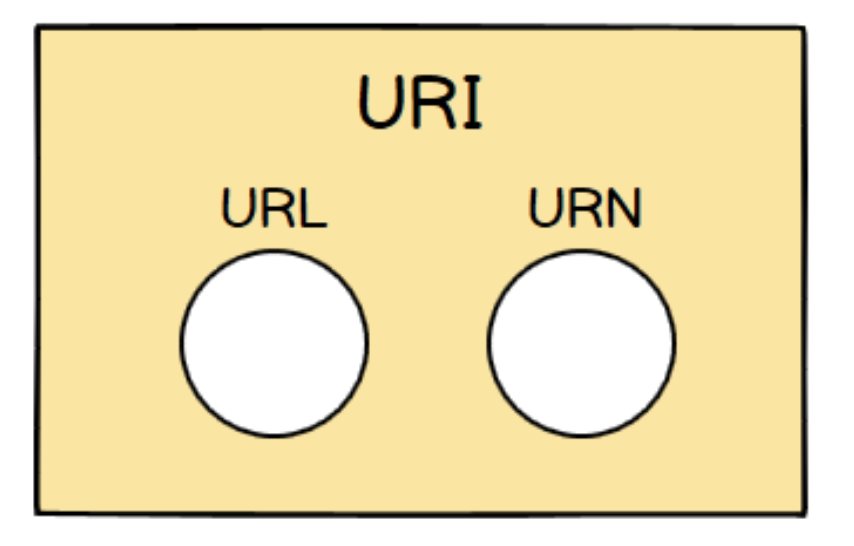
차이점
Graph QL이 좋은점. (요청은 복잡 데이터는 효율적)
Rest API는 URI로 연결되어있기 떄문에 부분적으로 원하는 정보를 얻을 때는 여러번의 요청을 거치게 된다.
하지만 Graph QL은 필요한 정보를 한번의 요청으로 쏙 뽑아서 사용할 수 있기 떄문에 편리함. 또한 상황마다(사용하는 기기, 유저)마다 필요한 정보가 다르기 떄문에 그부분에 있어서는 훨씬 유연하게 대처 가능.
또한 여러 Depth 의 정보들을 한번에 받아올수 있어서 더욱 편리 ( Class, student , name 모든 depth의 것들 한번에 받아올수 있다 )
Post ( Query ) 수정/삭제 (Mutation)으로 구현한다.
Rest API 이 좋은점. (요청은 단순 데이터는 복잡)
받아오고자 하는 정보가 많을때에는 일일이 작성해서 graph QL로 가져 오는것보다 URL한줄로 요청하는 Rest API가 더 편리하다.
세선스토리지 vs 쿠키
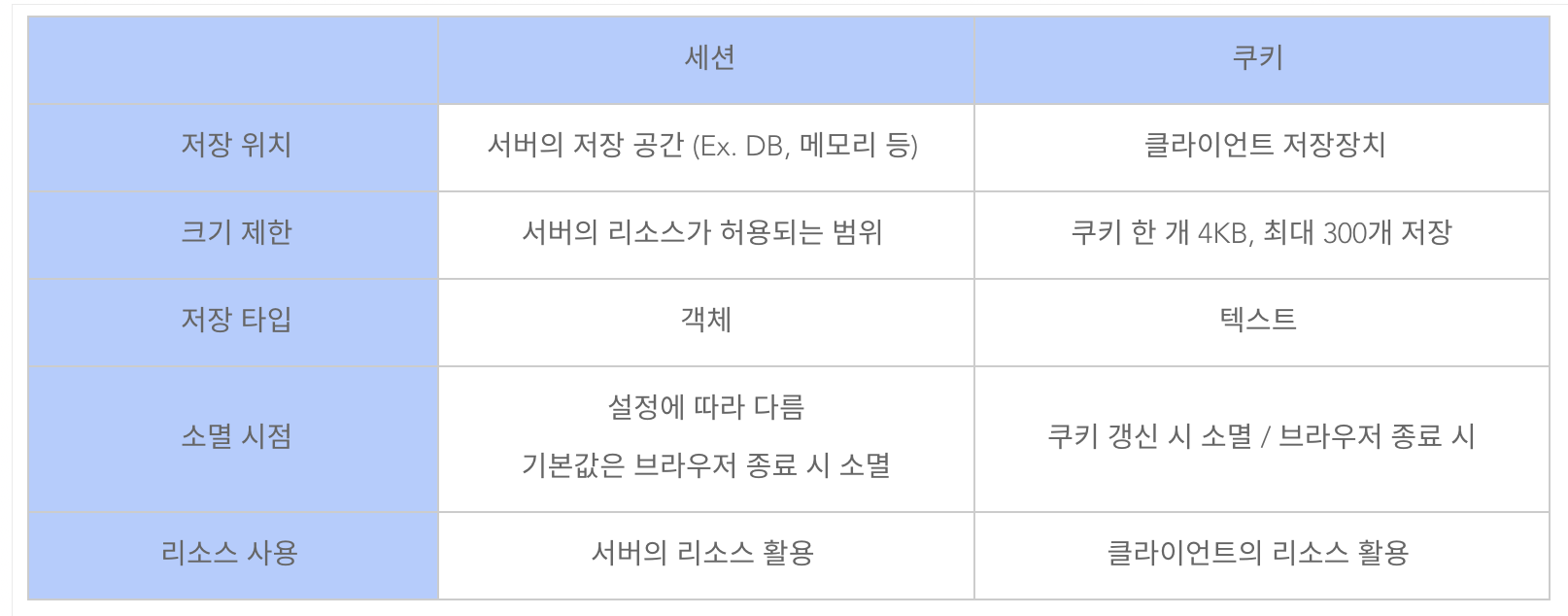
쿠키
쿠키를 이용해서 서버는 브라우저에 데이터를 넣을수 있음(로그인 데이터, 언어설정)
쿠키는 받은곳으로만 다시보냄 (유투브에서 받았으면 유투브로)
쿠키는 유효기간이 있음
클라이언트에 저장(텍스트 형태)
세션
HTTP의 Stateless속성때문에 연결이 끊기면 우리가 누군지 잊어버림.
그래서 Session ID를 이용하여 우리가 누군지 말해줌.
Request시 쿠키 + Session ID 를 서버로 보내면 서버에서 알수 있음
서버에 유저정보가있고 유저는 session ID만가짐
쿠키는 세션ID를 전달하기위한 매개체일뿐
세션 DB를 가지고 있어야해서 유저가 늘어날수록 점점 DB가 커지게됨(객체)
URL을 입력하면 벌어지는일
1. 브라우저의 URL 파싱
URL을 받은 브라우저는 URL의 구조를 해석한다.
- 어떤 프로토콜로
- 어느 도메인으로
- 어느 포트로 보낼지 해석하는 것이다.
--> 포트를 선언안했으면 기본값으로 보냄(Http =80 포트, HTTPS= 443포트)

2. HSTS 목록 조회
HSTS는 HTTP가아닌 HTTPS로 연결을 사용하는 기능이다.
HTTP로 요청이오면 HTTP응답 헤더에 "Strict Transport Security"라는 필드를 포함하여 응답하고 이를 확인한 브라우저는 해당 서버에 요청할 때 HTTPS만을 통해 통신하게 된다.
그리고 자신의 HSTS캐시에 해당 URL을 저장하는데 이를 HSTS 목록이라고 부른다.
--> HTST목록에 해당 URL이 있으면 HTTP를 통해 요청해도 HTTPS로 요청한다.
3.URL을 IP주소로 변환
www.naver.com 같은 주소는 컴퓨터간 통신을 할 수 없다. 컴퓨터간 상호작용 가능한 IP주소로 변환한다.
도메인 주소를 IP주소로 변환해주는 DNS(Domain Name System)서버에 요청해 URL을 IP주소로 변환한다.
4.라우터를 통해 해당 서버의 게이트웨이로 이동.
라우팅 테이블(경로)을 통해 해당 IP의 서버로 간다.
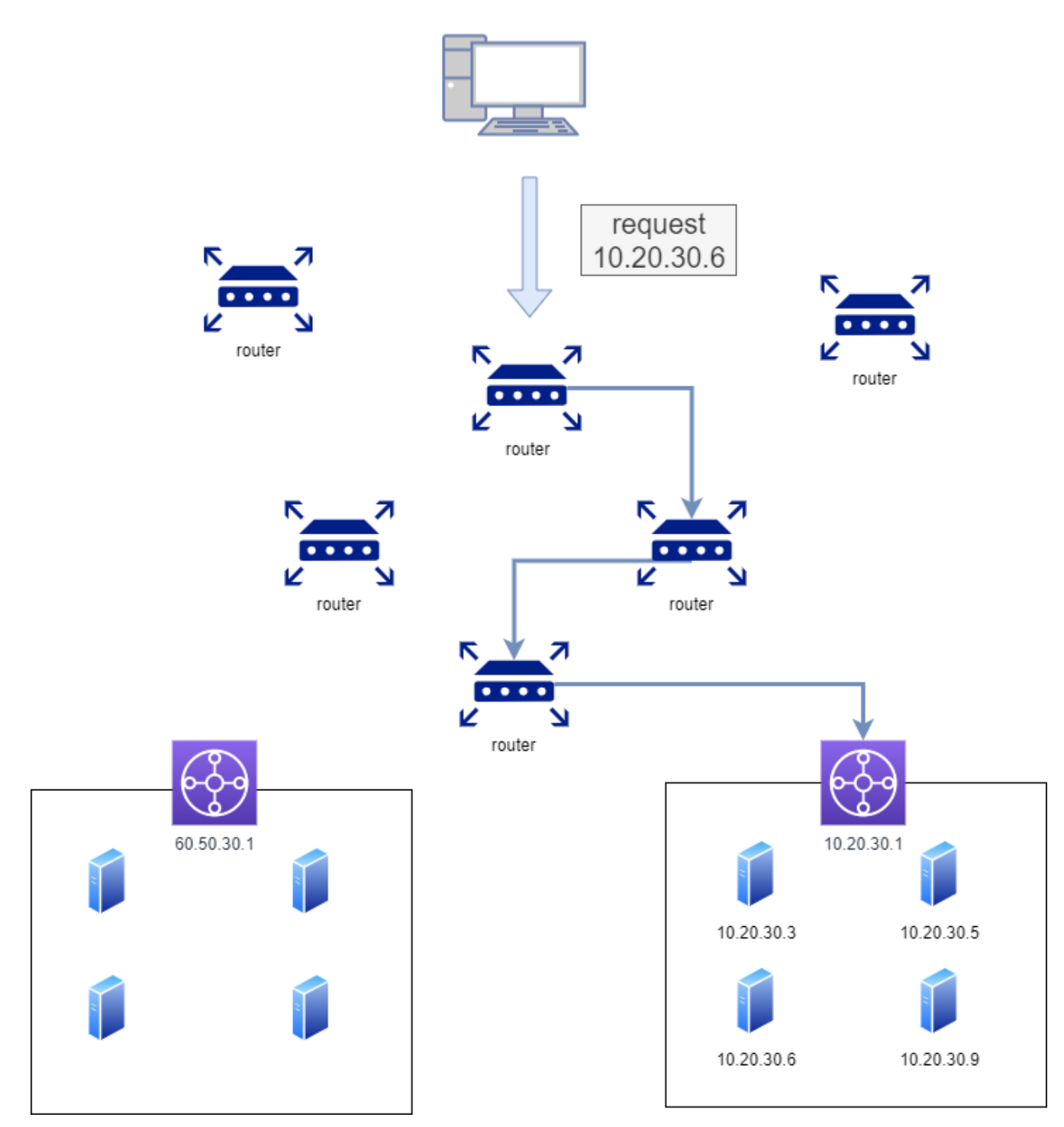
5. ARP을 통해 IP주소를 MAC 주소로 반환
실질적인 통신을 위해 논리 주소인 IP주소를 물리 주소인 MAC 주소로 변환한다.
--> APR: IP와 MAC을 매칭시키는 프로토콜
6. 대상 서버와 TCP 소켓 연결
이제 서버와 통신하기위해 TCP 소켓 연결을 한다. 연결은 3-way-handshake라는 과정으로 이루어 진다.
이 과정은 마치 전화를 거는 것과 유사하다. 서버에게 전화를 걸고, 서버는 해당 전화를 확인하고 전화를 받습니다. 그리고 전화를 건 사람은 말합니다. "여보세요"라고 하는 것처럼요.
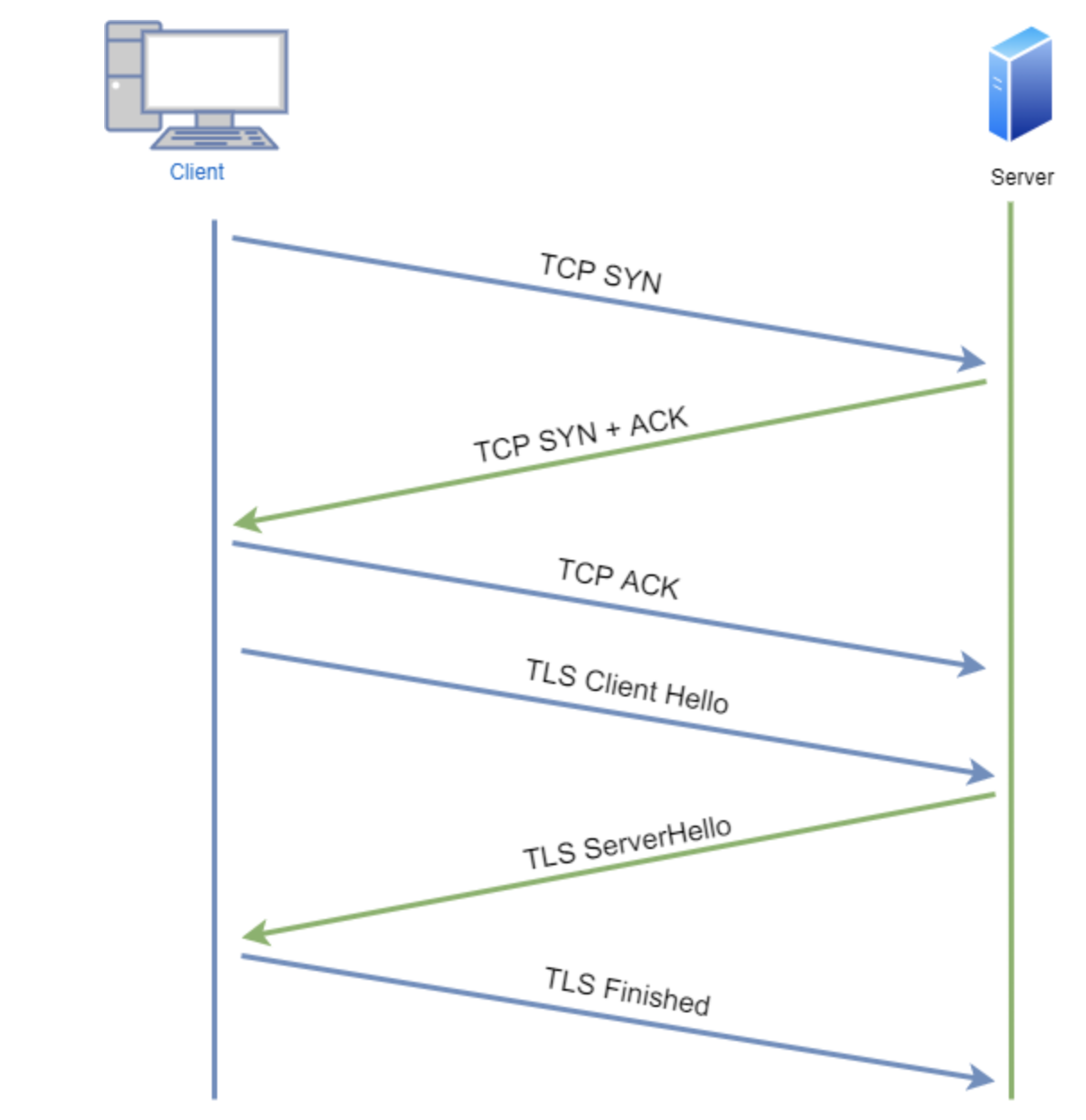
7. HTTP(HTTPS)프로토콜로 요청, 응답
연결이 되고나면 www.naver.com 페이지를 달라고 서버에 요청한다.
서버는 요청을 받고 수락할수 있는지 검사한후 응답을 브라우저에 전달한다.
8.브라우저에서 응답을 해석
서버에서 응답한 해석은 HTML,CSS,Javascript등을 포함하고 있다. 이를 브라우저에서 해석하여 원하는 URL이 그려진다.
