코드를 입력하세요
📚 A Survey on Deep Neural Network Pruning
Taxonomy, Comparison, Analysis, and Recommendations
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
📄 arXiv PDF 보기
🔗 GitHub Repository: awesome-pruning
Abstract 요약
현대의 딥 뉴럴 네트워크(DNN), 특히 대형 언어 모델(LLM)은
매우 큰 모델 크기를 가지고 있어 계산 및 저장 자원이 많이 필요합니다.
이러한 이유로 모델 경량화와 추론 속도 향상을 위한
핵심 연구 주제로 Pruning(가지치기) 기술이 주목받고 있습니다.
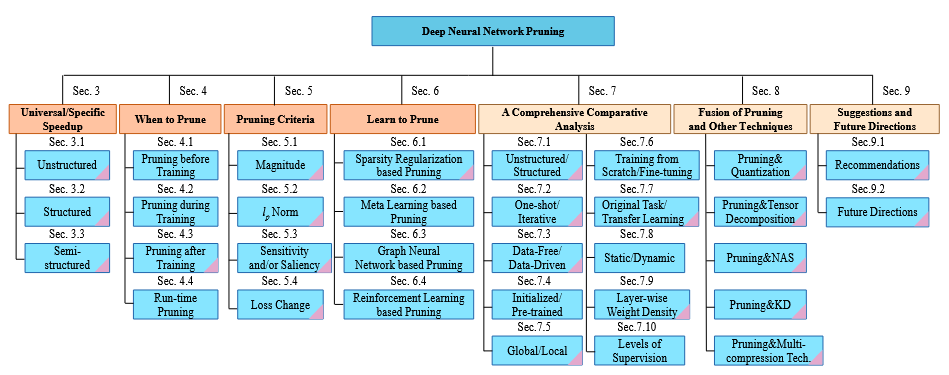
본 논문에서 제시하는 가지치기 분류 체계 (Taxonomy)
-
보편적 가속 vs. 특수 하드웨어 기반 가속
(Universal / Specific speedup) -
가지치기 수행 시점
- 학습 전 (Before training)
- 학습 중 (During training)
- 학습 후 (After training)
-
가지치기 수행 방식
- 기준 기반 (Criteria-based)
- 학습 기반 (Learn-to-prune)
-
다른 압축 기법들과의 융합
- 양자화 (Quantization)
- 지식 증류 (Knowledge Distillation)
- NAS
- 텐서 분해 등
주요 비교 기준 분석 (8쌍의 컨트라스트)
- 구조적 / 비구조적 (Structured / Unstructured)
- 단회 / 반복 (One-shot / Iterative)
- 데이터 기반 / 비데이터 기반 (Data-driven / Data-free)
- 초기화 / 사전 학습 기반 (Initialized / Pre-trained)
- 정적 / 동적 (Static / Dynamic)
- 원래 작업 / 전이 학습 (Original Task / Transfer Learning)
- 층별 희소성 (Layer-wise sparsity)
- 전역 / 지역 기준 (Global / Local)
다루는 최신 주제
- 대형 언어 모델(LLM)을 위한 가지치기
- Vision Transformers
- Diffusion Models
- Large Multimodal Models
- Post-training Pruning
- 가지치기 시 감독 수준 다양화 (Levels of Supervision)
Introduction
딥 뉴럴 네트워크(DNN)의 발전과 한계
- DNN은 최근 다양한 분야에서 큰 발전을 이룸
- 컴퓨터 비전(CV), 자연어 처리(NLP), 오디오 처리(ASP), 멀티모달 응용 등
- 대표 모델 크기 예시:
- ResNet-50: 95MB, 2,300만 개 파라미터
- BERTBASE: 440MB, 1억 1천만 개 파라미터
- GPT-3: 1,750억 개 파라미터
- 모델 규모는 계속 커지고 있음 → 연산 시간과 메모리 사용량 증가
모델 배포의 현실적 문제
- 엣지 디바이스(CPU, GPU, 메모리 등 제약)에서 DNN 활용 어려움
- 실시간 응답과 경량화가 요구되는 응용:
- 자율주행, 재난 구조, 산불 감지 등
- 고차원 특징은 적대적 공격에 취약 → 일반화 성능 저하 우려
대응 방안: 신경망 압축 기법
- 가지치기(Pruning)
- 저랭크 분해(Low-rank factorization)
- 양자화(Quantization)
- 지식 증류(Knowledge Distillation)
- NAS(Neural Architecture Search)
가지치기(Pruning)의 주목도
- 추론 효율성(메모리/연산량) 향상에 효과적
- 성능 유지 또는 향상 가능
- 2015년 이후 관련 논문 급증 → 전체 신경망 압축 논문의 절반 이상 차지
논문 목표
- 딥 뉴럴 네트워크 가지치기(Pruning)에 대한 포괄적이고 체계적인 리뷰 제공
- 대표 기법 정리, 새로운 분류 체계 제시, 실제 성능 분석, 실무 적용을 위한 가이드 제안
주요 기여
(1) 포괄적 리뷰
- 300편 이상의 논문을 분석하여 소형~대형 모델까지 포함한 가지치기 기술 정리
- 새로운 분류 체계 제시 및 각 분류에 따른 대표 기법 설명
(2) 비교 실험 및 분석
- 8쌍의 가지치기 기법 비교:
- 예: 구조적 vs 비구조적, 초기화 vs 사전 학습 기반 등
- LLM, 감독 수준별 가지치기 등 최신 주제 포함
- 기존 리뷰와 달리 실험 기반 분석 포함
(3) 자료 및 자원 정리
- 가지치기 응용 분야 정리
- 평가용 데이터셋, 네트워크, 벤치마크 제공
- 깃허브 저장소에서 지속적 업데이트
(4) 실용적 추천 및 향후 연구 방향
- 다양한 요구 조건에 맞춘 가지치기 방법 추천
- 향후 연구 과제 및 트렌드 제시
논문 구성
- 2장: 가지치기 분류 체계
- 3~6장: 속도 향상, 가지치기 시점, 수행 방식 개요
- 7장: 가지치기 기법 간 비교 분석
- 8장: 다른 압축 기법과의 통합
- 9장: 실무자용 가이드 + 미래 방향
- 10장: 결론
2 TAXONOMY(3가지 핵심 분류 기준)
1. 가속 방식에 따른 분류 (Universal vs. Specific Acceleration)
-
Unstructured Pruning
- 임의의 개별 가중치 제거
- 특수 하드웨어/소프트웨어 필요
-
Semi-structured Pruning (Pattern-based)
- 일정 패턴의 희소성 적용
- 특수 하드웨어 필요 (예: NVIDIA Ampere 2:4 sparsity)
-
Structured Pruning
- 필터, 채널, 층 단위로 제거
- 보편적 가속 가능 (추가 하드웨어 필요 없음)
2. 가지치기 수행 시점 (When to Prune)
-
Pruning Before Training (PBT)
- 학습 전 초기화된 네트워크에 가지치기 적용
-
Pruning During Training (PDT)
- 학습과 동시에 가지치기 진행
-
Pruning After Training (PAT)
- 학습이 끝난 후 가지치기 수행
-
Dynamic Pruning
- 런타임 중 입력 데이터에 따라 서브네트워크 실시간 생성
3. 가지치기 방식 (How to Prune)
-
Criteria-based Pruning
- 사전 정의된 기준으로 중요도 판단
- 예:
- Magnitude
- Norm
- Loss 변화
-
Learn-to-Prune
- 학습을 통해 가지치기 구조 최적화
- 예:
- Sparsity Regularization
- Dynamic Sparse Training
정리
- 이 세 가지 기준은 가지치기 알고리즘의 핵심 특성을 구성
- 다양한 조합을 통해 서로 다른 가지치기 전략 형성
- 논문의 Section 3~6, 8에서 이 분류 체계가 상세히 설명됨
3가지 질문에 대해 정리한 표(Fig3)
3 SPECIFIC OR UNIVERSAL SPEEDUP
가지치기 유형 분류
-
Unstructured Pruning (비구조적 가지치기)
- 개별 가중치 수준에서 제거
- 특수 가속 (Specific Speedup) 필요
- 특수 하드웨어/소프트웨어 없이 성능 향상 어려움
-
Semi-structured Pruning (세미구조적 가지치기)
- 일정 패턴(예: 2:4 sparsity)을 적용한 가지치기
- 특수 가속 (Specific Speedup) 필요
- 패턴 최적화를 위한 하드웨어 지원 필요
-
Structured Pruning (구조적 가지치기)
- 채널, 필터, 레이어 단위 제거
- 보편적 가속 (Universal Speedup) 가능
- 하드웨어 특수화 없이도 추론 속도 개선
3.1 Unstructured Pruning
정의
- 다른 명칭: Non-structured pruning, Weight-wise pruning
- 개별 가중치 단위로 제거하는 가장 세분화된 가지치기 방식
최적화 문제 정의
- ( |W|_0 ): 0이 아닌 가중치의 개수
- ( k ): 유지할 최대 비제로(Non-zero) 가중치 수
마스킹 방식 적용
- 각 가중치에 binary mask ( M ) (0 또는 1)을 곱해 제거
- 마스크 기반 최적화 식:
- ( W \odot M ): 요소별 곱 (Hadamard product)
- 마스킹된 가중치는 학습에 사용되지 않으며, 모델은 보통 재학습(fine-tuning) 또는 처음부터 학습(training from scratch)됨
대형 모델에서의 처리
- LLM과 같은 모델은 파라미터가 너무 많아 마스크 관리가 비효율적
- 따라서 직접 가중치를 0으로 설정하는 방식이 흔히 사용됨
가속성과 하드웨어 의존
- 제거 위치가 불규칙 → 연산 최적화 어려움
- 실제 가속을 얻기 위해선 특수 하드웨어/소프트웨어 필요
- 예: 커스텀 GPU 커널, 희소 행렬 라이브러리 등
Fig. 3: The visualization of unstructured pruning
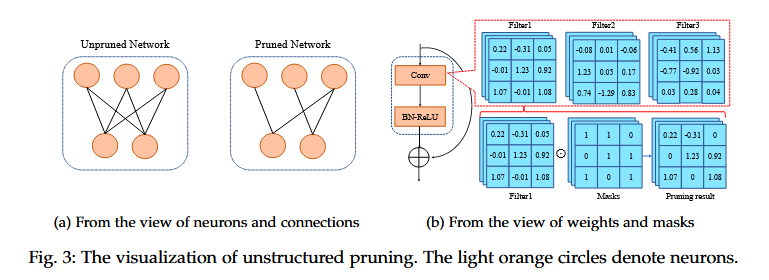
(a) From the view of neurons and connections
-
Unpruned Network (왼쪽)
- 모든 뉴런 간의 연결(가중치)이 유지된 상태
- 연한 주황색 원: 뉴런 (neuron)
- 연결선: 가중치(weight)
-
Pruned Network (오른쪽)
- 일부 연결이 제거된 상태
- 뉴런은 그대로지만, 가중치 일부가 0으로 제거
- 구조 변경 없이 파라미터 수만 감소
(b) From the view of weights and masks
-
Filter (왼쪽 상단)
- CNN 필터의 가중치 행렬
- 예: 3×3 커널 (Filter1, Filter2, Filter3)
-
Mask (가운데)
- Binary Mask (0 또는 1)
- 1 → 해당 weight 유지
- 0 → 해당 weight 제거 (실제로는 곱해서 0으로 만듦)
-
Pruning Result (오른쪽)
- Filter ⊙ Mask 결과
- 비구조적으로 제거되어 불규칙한 희소성(sparsity) 형성
- 실제 가속에는 특수 하드웨어/라이브러리 필요
결론
- Unstructured Pruning (비구조적 가지치기)는
Specific Speedup (특수 가속)에 해당하는 방식으로 분류됨
3.2 Structured Pruning (구조적 가지치기)
정의
-
뉴럴 네트워크의 각 레이어는 다음과 같이 구성됨:
- 여기서 ( s_i )는 채널, 필터, 뉴런, 트랜스포머 어텐션 헤드 등으로 구성됨
-
Structured Pruning은 다음 조건을 만족하는 하위 구조 ( S' )를 선택함:
- 목적:
- 성능 저하 최소화
- 속도 향상 최대화
- 주어진 가지치기 비율 하에서 최적 구조 찾기
제거 대상 예시
- 전체 필터 제거
- 채널 제거
- 트랜스포머 어텐션 헤드 제거
- 레이어 제거
특징
- 제거 결과, 좁고 규칙적인(narrow and regular) 모델 구조 형성
- 구조적 단위 제거이므로 희소성 없이도 효율적 실행 가능
장점
- 보편적 가속 (Universal Speedup) 가능
- 특수 하드웨어/소프트웨어 없이도 실제 속도 향상 달성
- 모델 크기 감소와 실용적 연산 최적화에 적합
3.3 Semi-structured Pruning
정의 및 목적
- Structured Pruning보다 더 유연하고 세밀한(fine-grained) 가지치기 방식
- 높은 가지치기 비율에서도 정확도 저하를 최소화하고
구조적 규칙성(structural regularity)을 유지함 - 일부 문헌에서는 Pattern-based Pruning이라고도 불림
주요 예시
-
Meng et al
- 필터를 여러 개의 스트라이프(stripe)로 나누고,
- 각 필터 내에서 stripe 단위로 가지치기를 수행
-
SparseGPT
- LLM(대형 언어 모델)의 파라미터를 절반으로 줄이기 위해
- 2:4 또는 4:8 희소성 패턴(sparsity pattern) 적용
- 예: 2:4 패턴 → 4개의 값 중 2개 이상은 반드시 0
- NVIDIA Ampere GPU의 sparse tensor core와 호환되어
행렬 연산 가속 가능 ([60])
Structured vs. Semi-structured
| 방식 | 제거 단위 | 특성 | 분류 |
|---|---|---|---|
| Structured Pruning | 필터, 채널, 레이어 등 | 큰 단위 제거 | Coarse-grained |
| Semi-structured Pruning | 패턴, stripe 등 | 정해진 패턴 제거 | Fine-grained |
특징 요약
- 정확도 보존 + 구조 유지 + 하드웨어 가속 모두 고려
- GPU 희소 커널과 결합 시 실질적인 속도 향상 가능
- 정해진 패턴을 따르는 규칙적 제거 방식
Fig. 4: Structured & Semi-structured Pruning
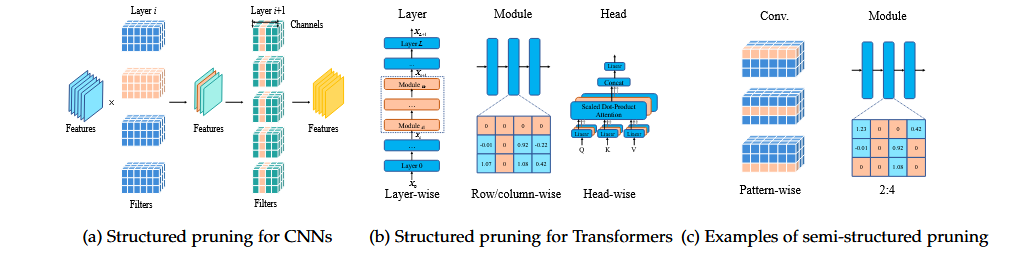
(a) Structured pruning for CNNs
-
필터 단위 제거 (Filter-wise pruning)
- 레이어에서 전체 필터를 제거
- 필터 제거 → 연산량 감소, 메모리 절약
-
채널 단위 제거 (Channel-wise pruning)
- 다음 레이어의 입력 채널 일부 제거
- 입력 feature map 크기 축소 → 연산 효율 개선
-
➤ 오렌지색 블록은 제거된 필터나 채널을 시각적으로 나타냄
(b) Structured pruning for Transformers
-
레이어 단위 제거 (Layer-wise pruning)
- 전체 레이어(예: Transformer block) 삭제
-
행/열 제거 (Row/column-wise pruning)
- Attention 또는 FFN 내부 가중치 행/열 제거
- 파라미터 수 및 연산량 동시 감소
-
어텐션 헤드 제거 (Head-wise pruning)
- 멀티헤드 어텐션에서 일부 헤드를 완전히 제거
- 성능 유지하면서 연산량 줄임
(c) Semi-structured pruning 예시
-
패턴 기반 제거 (Pattern-wise pruning)
- 필터 내에서 정해진 패턴에 따라 weight 제거
- 예: 대각선, 블록 형태 등
-
2:4 Pruning (2-out-of-4)
- 4개의 weight 중 2개만 남기고 나머지 제거
- NVIDIA GPU (Ampere)에서 가속 지원
4. When to Prune
핵심 분류
- 가지치기는 언제 수행하는지에 따라 크게 네 가지로 나뉨:
1. Pruning Before Training
- 모델 초기화 이후, 학습 전에 구조를 줄임
2. Pruning During Training
- 학습 진행 중 일정 시점에 가지치기를 반복 수행
3. Pruning After Training
- 사전 학습된 모델에서 불필요한 가중치를 제거하고 다시 미세조정
4. Run-time Pruning
- 입력마다 실행 시점에 동적으로 서브네트워크 구성
4.1 Pruning Before Training
정의 및 개요
Pruning Before Training (PBT)는
학습 전에 무작위로 초기화된 가중치에서 가지치기를 수행하는 방식이다.
이는 foresight pruning 또는 pruning at initialization이라고도 불린다.
핵심 개념
- PBT의 목적: 사전 학습(pre-training) 없이 빠르게 학습 시작
- 일반적인 네트워크는 다음과 같이 정의된다:
- 여기서
• ( W ): 초기화된 가중치
• ( M ): 가지치기 마스크 (0 또는 1)
초기화된 가중치란?
- ( W_0 )는 Xavier, He 초기화 등
특정 분포에서 무작위로 샘플링된 값 - 이를 기반으로 가지치기 수행
가지치기 후 학습 과정
- 가지치기 후 네트워크는 다음과 같이 학습됨:
-
변수 설명:
• ( W_0 ): 초기화된 가중치
• ( M' ): 가지치기 후 희소성 유지 마스크
• ( t ): 학습 에폭 수 -
고정된 희소 구조를 유지하며 가중치만 학습됨
작동 절차 (2단계)
- 학습되지 않은 밀집 네트워크에 기준 기반 가지치기 수행
- 고정된 희소 구조를 그대로 학습 (Static Sparse Training)
➡️ 관련 구조(Fig. 5 (a) )

장점
- 사전 학습 없이 바로 가지치기 가능 → 시간 절약
- 추론 속도 향상 가능
- 고정된 희소성 → 하드웨어 친화적
주요 PBT 방식 요약 (SNIP, GraSP, SynFlow 중심)
현재 PBT의 주요 적용 분야
- PBT(Pruning Before Training)는 현재 주로 CNN에 적용되고 있음
1. SNIP (Single-shot Network Pruning) — Lee et al
-
핵심 아이디어:
손실 변화가 가장 적은 가중치부터 제거 → 네트워크 성능 유지 -
작동 원리:
초기 가중치에서 손실 민감도기반으로 pruning
-
Lee et al. [72] 주요 기여:
- SNIP을 신호 전파(signal propagation) 관점에서 분석
- 가지치기가 신경망의 동적 등거리성(dynamical isometry)을 훼손함을 발견
- 이를 보완하기 위해 정확한 등거리성에 근접한 데이터프리 직교 초기화 제안
2. GraSP (Gradient Signal Preservation) — Wang et al. [56]
-
핵심 아이디어:
가지치기 후에도 그래디언트 흐름이 잘 유지되도록 weight 선택 -
기법 특징:
- SNIP이 신호 전파 기반이라면, GraSP는 그래디언트 흐름 보존에 초점
- 네트워크가 학습 가능성을 잃지 않도록 함
3. SynFlow (Iterative Synaptic Flow Pruning) — Tanaka et al. [50]
-
핵심 아이디어:
학습도, 데이터도 없이 가지치기 가능한 완전한 데이터프리 기법 -
기법 설명:
- 신경망 내에서 정보가 거의 흐르지 않는 weight 제거
- Synaptic flow 값이 작은 weight부터 제거
- 점진적 가지치기로 레이어 붕괴(layer collapse) 방지
4. Path Kernel Framework — Gebhart et al. [74]
- 기여 내용:
- SNIP, GraSP, SynFlow를 하나의 이론적 틀로 통합
- Neural Tangent Kernel (NTK) 기반으로 가지치기 기법들의 공통 수학적 구조 분석
5. Smart Ratios — Su et al. [55]
- 핵심 주장:
정교한 가지치기 기준보다 중요한 건 레이어별 희소 비율 - 방법:
- 각 레이어를 데이터 없이 무작위 비율(smart-ratios)로 가지치기
6. Edge-popup & Weight Agnostic Neural Networks — Ramanujan et al. [78]
-
발견:
- 학습되지 않은, 충분히 넓고 깊은 네트워크는
성능 좋은 서브네트워크를 포함하고 있음
- 학습되지 않은, 충분히 넓고 깊은 네트워크는
-
Edge-popup:
- 이런 서브네트워크를 초기화 상태에서 찾아내는 방법
7. DLTH & RST — Bai et al. [71]
-
DLTH (Dual Lottery Ticket Hypothesis):
- 서브네트워크와 가중치를 모두 무작위로 선택
-
RST (Random Sparse Network Transformation):
- 희소 구조는 고정하고, 살아남은 가중치만 점진적으로 학습
8. 최근 논의: "왜 초기화만으로 좋은 서브네트워크가 가능할까?"
-
Liu et al. [69]:
- 네트워크의 크기와 레이어별 가지치기 비율이 성능 결정 요인
-
Kumar et al. [80]:
- 동일한 가지치기 비율일 경우,
학습 중/후에 가지치기된 서브네트워크가
초기 가지치기 방식보다 더 표현력이 높고 효과적인 파라미터 수가 큼
- 동일한 가지치기 비율일 경우,
4.2 Pruning During Training (PDT, 학습 중 가지치기)
✅ 정의 및 기본 개념
-
PDT는 무작위로 초기화된 밀집 네트워크 ( f(x; W_0) )를 입력으로 사용하여,
학습 도중 가중치 ( W )와 마스크 ( M )를 동시에 학습하면서 가지치기를 수행하는 방식이다. -
이 과정에서 마스크는 매 반복/에폭마다 동적으로 변화하며,
t 에폭 후 가지치기된 서브네트워크는 다음과 같이 표현됨:
- 여기서:
- ( W_t ): t번째 에폭에서 학습된 가중치
- ( M_t ): 해당 시점의 가지치기 마스크 (동적으로 변경됨)
✅ 특징 및 장점
- 많은 PDT 방법([59, 81–86])은 별도의 재학습(training-from-scratch)이나
파인튜닝(fine-tuning) 없이도 즉시 사용 가능한 서브네트워크를 생성함 - 전체 파이프라인은 Fig. 5 (b)에 시각적으로 제시됨
⚠️ 왜 연구가 적을까?
- PBT나 PAT에 비해, 학습 중 weight와 mask를 동시에 최적화해야 하는 동적 처리 과정이 복잡하여
실제 구현과 실험이 어렵고 불안정할 수 있음
🔹 주요 PDT 방법 분류 (4가지 패러다임)
1. Sparsity Regularization 기반
- 손실 함수에 희소성(sparsity)을 유도하는 정규화 항 추가
- ex: L1 정규화, group lasso 등
- 네트워크가 자연스럽게 불필요한 weight를 0에 가깝게 만들어 제거
2. Dynamic Sparse Training (DST) 기반
- 처음부터 희소한 구조로 시작해서 학습 중에도 그 구조를 유지하며
일부 연결을 제거하거나 추가 → sparse-to-sparse training
🔹 sparse-to-sparse란?
- 처음부터 구조가 sparse(희소)하며, 학습 중에도 sparse한 상태 유지
- pruning뿐 아니라 연결 복원도 동시에 고려함
3. Score-based 방식
-
학습 중 각 가중치의 중요도를 점수(score)로 계산
→ 중요도가 낮은 weight를 제거 -
대표 점수 기준:
- magnitude (절댓값 크기)
- gradient 기반 중요도
- 기타 학습 통계 기반
-
일반적으로 dense-to-sparse 방식
→ 완전한 네트워크에서 시작해서 가지치기를 통해 희소 구조 생성
4. Differentiable Pruning 기반
🔹 핵심 개념
- 가지치기 마스크는 원래 0 또는 1 → 미분 불가능
- 이를 연속값(0~1)으로 relax(완화)하여 학습 가능하게 만듦
- 이처럼 연속화된 마스크를 포함하여 전체 네트워크를 end-to-end 학습함
(즉, 가중치와 마스크를 동시에 역전파로 최적화)
🔹 예시 기법
- Soft mask: 마스크 값을 확률처럼 처리
- Gumbel-softmax: 이산 선택을 연속적으로 근사하여 미분 가능하게 함
🔹 dense-to-sparse란?
- 학습 초기에는 모든 weight가 존재하는 dense 구조에서 시작
- 점진적으로 weight를 제거하면서 희소 구조(sparse)로 전환
✅ 전체 요약
PDT 전체 구조

| 방식 | 데이터 사용 | 시작 구조 | 마스크 방식 | 설명 |
|---|---|---|---|---|
| Sparsity Regularization | ✅ | dense | discrete | 손실함수에 희소성 유도 항 추가 |
| Dynamic Sparse Training | ✅ | sparse | discrete | 희소 구조 유지하며 연결 조정 |
| Score-based | ✅ | dense | discrete | 중요도 점수 기반 가지치기 |
| Differentiable Pruning | ✅ | dense | relaxed (연속값) | 마스크를 연속화하여 동시에 학습 |
참고:
- (2)번인 DST만 sparse-to-sparse,
- 나머지 방식은 dense-to-sparse
4.2.1 Sparsity Regularization based Methods (Pruning During Training)
✅ 개요
- Sparsity Regularization은 PDT(학습 중 가지치기)에서 가장 널리 사용되는 방식 중 하나다.
- 방식: 학습 중 손실 함수에 희소성(sparsity) 유도 항을 추가해,
불필요한 가중치나 구조를 자동으로 0에 수렴하게 만들어 제거함 - 이 방식은 dense-to-sparse 접근에 해당함
🔹 원리 요약
- 초기에는 모든 weight를 가진 dense 모델에서 시작
- 손실 함수에 정규화 항을 추가하여,
weight 또는 구조 단위를 0으로 유도 - 학습이 진행될수록 특정 weight 또는 구조의 영향력이 사라지고 제거됨
🔹 대표 연구 사례
▶ Wen et al. [58] — Structured Sparsity Learning (SSL)
-
Group LASSO 정규화를 활용해
구조 단위(채널, 필터, 레이어 등)를 한 번에 제거할 수 있도록 함 -
손실 함수:
-
특징:
- 구조적 pruning 가능
- 그러나 정규화 항의 gradient 계산이 복잡하고 계산 비용이 큼
▶ Gordon et al. [88] — MorphNet
- Batch Normalization(BN)의 scaling factor 에 sparsity 정규화를 적용하는 방식
- BN을 사용하는 구조에서 간단하게 채널의 중요도를 학습 중 평가 가능
- 단점:
- BN이 없는 네트워크 (예: VGGNet 등)에는 적용 불가
▶ Huang & Wang [59] — Sparse Structure Selection (SSS)
- BN이 없더라도 적용 가능한 구조
- 각 구조 단위(채널, 블록 등)에 scaling factor를 부여한 뒤,
이를 sparsity 정규화로 0으로 유도 - 출력이 0에 수렴하면 해당 구조는 제거 가능
- 특징:
- BN 없이 사용 가능
- 파인튜닝 없이도 pruning 가능
▶ Li et al. [89] — Factorized Convolutional Filter (FCF)
- 각 필터에 이진 스칼라(binary scalar) 값을 부여하여,
이 값이 0이면 해당 필터는 제거 - ADMM (Alternating Direction Method of Multipliers) 알고리즘을 통해
가중치와 스칼라를 동시에 학습
🔸 비교 요약
| 연구 | 방식 | 주요 구조 대상 | 핵심 원리 | 장점 | 단점 |
|---|---|---|---|---|---|
| Wen et al. [58] | SSL (Group LASSO) | 채널, 필터 등 | 그룹 단위로 L2 정규화 | 구조적 가지치기 가능 | 정규화 gradient 계산 복잡 |
| Gordon et al. [88] | MorphNet | BN 채널 | BN의 scaling 파라미터에 정규화 | 구현 쉬움 | BN이 없으면 적용 불가 |
| Huang & Wang [59] | SSS | 채널, 블록 | 구조 단위의 scaling factor를 0으로 유도 | BN 없이 사용 가능, 파인튜닝 불필요 | 다소 간접적인 제거 방식 |
| Li et al. [89] | FCF + ADMM | 필터 | 이진 스칼라와 weight 동시 학습 | 명시적 제어 가능 | ADMM 최적화 구조가 복잡 |
4.2.2 Dynamic Sparse Training based Methods(DST)
✅ 개요
- Dynamic Sparse Training (DST)은 학습 중 희소 구조를 지속적으로 변경하며 더 나은 sparse 구조를 찾아가는 방법이다.
- 기존의 dense-to-sparse 방식과 달리, DST는 초기부터 sparse한 네트워크로 시작하며,
- 학습 도중 Prune-and-Grow 과정을 반복하여 구조를 점진적으로 개선한다.
🔁 Prune-and-Grow 사이클
- 중요하지 않은 가중치를 Prune (제거)
- 새로운 위치에 가중치를 Grow (재생성)
- 이 과정을 학습 중 반복함으로써 효율적인 sparse 구조 탐색
🔹 왜 DST가 필요한가?
- 기존 방식은 dense 모델을 학습한 후 pruning → 비효율
- DST는 처음부터 희소한 구조로 시작하여 메모리·연산 절감
- 구조를 실시간으로 변경함으로써 성능도 유지 혹은 향상 가능
🔬 주요 연구 및 방법
🔸 SET (Sparse Evolutionary Training) — Mocanu et al. [91]
- 가장 기본적인 DST 방식
- 작은 양수와 큰 음수 weight를 제거하고,
무작위로 새로운 weight를 생성 - 생물학적 진화에서 영감 받은 방식
🔸 DSR (Dynamic Sparse Reparameterization) — Mostafa & Wang [95]
- SET과 달리 pruning 비율을 고정하지 않고, 적응형 threshold 사용
- weight를 레이어 간에도 재분배할 수 있어 구조적 유연성 향상
🔸 GraNet (Gradual Pruning + Neuroregeneration) — Liu et al. [92]
- pruning 기준: weight 크기
- regrowth 기준: gradient 크기
- 중요한 통찰: gradient가 0인 weight도 제거 대상이 될 수 있음
- "신경 재생" 개념 도입 → 생물학적 연결 형성에서 영감
🔸 FreeTickets — Liu et al. [93]
- 다양한 sparse subnetworks를 DST로 생성한 후 앙상블(ensemble) 구성
- 서로 다른 구조를 조합하여 성능을 향상시킴
🔸 Sokar et al. [98]
- DST를 강화학습(RL)에 적용한 최초 연구
- 기존 supervised 환경을 넘어 새로운 영역에 DST 확장
🔸 Evci et al. [99]
- DST의 이론적 타당성 분석
- 초기 sparse 네트워크는 gradient 흐름이 약하지만,
DST를 통해 gradient 흐름이 개선됨 → 학습 효율 증가 입증
정리
- DST는 단순한 pruning 기법을 넘어서,
학습 효율, 구조 최적화, 적응적 재설계까지 고려하는 핵심적인 경량화 전략이다. - 특히 최근 연구들은 생물학적 뉴런 연결, 신경 재생, gradient 흐름 개선 등
다양한 관점에서 DST를 확장·이해하려는 노력이 계속되고 있다.
4.2.3 Score-based Methods (점수 기반 가지치기 방법)
✅ 개요
- Score-based Pruning은 각 가중치, 필터, 채널 등의 중요도를 수치화(score) 하여
학습 중에 가지치기(pruning)를 수행하는 방법이다. - 중요도 계산 기준은 다양하지만, 주로 L1/L2 norm, 중심거리, scaling 계수 등을 사용한다.
🔹 1. Soft Filter Pruning (SFP) — He et al. [83]
- L2 Norm을 기반으로 각 필터의 중요도를 계산
- 중요도가 낮은 필터의 가중치를 0으로 설정하여 pruning
- pruning된 필터는 이후 학습 과정에서 다시 활성화될 수도 있음
(forward-backward로 weight가 다시 업데이트됨) - 각 레이어별 prune 비율은 수동 설정 필요
🔹 2. FPGM (Filter Pruning via Geometric Median) — He et al. [100]
- 같은 레이어 내의 필터들 중 기하학적 중심(geometric median)에 가장 가까운 필터를 중복된 정보로 간주하고 제거
- SFP와 마찬가지로 레이어별 가지치기 비율을 미리 지정해야 함
🔹 3. Network Slimming — Liu et al. [57]
- 각 채널에 스케일링 계수(scaling factor)를 부여하고
이 계수의 절댓값 크기를 기준으로 중요도 판단 - 손실 함수에 희소성 정규화(sparsity regularization) 추가 → 중요도 낮은 채널 제거
- BN 레이어의 값(스케일링 계수)을 재활용하여 별도 파라미터 없이 pruning 가능
📌 정리
| 방법 | 기준 | 제거 대상 | 특징 |
|---|---|---|---|
| SFP [83] | L2 Norm | 필터 | 학습 중 soft pruning, 다시 살아날 수 있음 |
| FPGM [100] | Geometric Median | 필터 | 중복 필터 제거, 수동 비율 설정 필요 |
| Network Slimming [57] | BN의 γ 값 (scaling factor) | 채널 | BN 재활용, 희소성 정규화 적용 |
4.2.4 Differentiable Pruning
✅ 개요
- Differentiable Pruning은 가지치기 마스크를 연속적(soft) 값으로 표현하여,
전체 학습 과정에서 미분 가능한 방식으로 가지치기를 수행할 수 있게 만든 기법이다. - 최근 Differentiable Neural Architecture Search([27], [28])에서 발전된 개념들이
가지치기에도 적용되고 있다.
🔹 1. Differentiable Sparsity Allocation (DSA) — Ning et al. [85]
- 레이어별 가지치기 비율(prune ratio)을 학습으로 자동 설정
- 확률 분포로부터 마스크를 샘플링하여 하드 가지치기를 부드럽게 표현
- 이 마스크는 미분 가능하므로, 손실 함수에 대한 gradient 계산이 가능
- gradient는 각 레이어의 중요도(민감도)를 나타냄
🔹 2. Differentiable Markov Channel Pruning — Guo et al. [102]
- 채널 가지치기를 미분 가능한 마르코프 과정(Markov Process)으로 모델링
- 각 채널을 상태(state)로 보고, 이전 채널의 유지 여부에 따라 유지 확률 결정
- 상태 전이 확률을 미분 가능하게 설계하여 구조 탐색 가능
🔹 3. Soft Mask Pruning without Extra Parameters — Cho et al. [86]
- CNN과 Transformer를 위한 간단한 Differentiable Pruning 기법 제안
- 추가 파라미터 없이 소프트 마스크를 생성
- 복잡도는 낮추면서도 end-to-end 학습 중 가지치기 가능
📌 핵심 요약
| 방법 | 방식 | 특징 |
|---|---|---|
| DSA [85] | 확률 분포 기반 마스크 | gradient로 layer sensitivity 측정 |
| Guo [102] | Markov 상태 전이 | 채널 유지 확률을 미분 가능하게 모델링 |
| Cho [86] | 소프트 마스크 (추가 파라미터 없음) | CNN/Transformer에 경량 적용 가능 |
✅ 장점
- 하드한 비결정적 제거 대신 학습 가능한 soft mask로 더 유연한 가지치기 가능
- 구조 탐색과 학습을 동시에 수행 (end-to-end)
- 실제 파라미터 감소뿐 아니라 학습 효율, 하드웨어 친화성까지 고려 가능
4.3 Pruning After Training (PAT) — 학습 후 가지치기
✅ 개요
- PAT은 가장 널리 사용되는 가지치기 방법으로,
일반적으로 사전학습(pretraining)된 dense 모델에서 시작하여
가지치기를 수행한 뒤 재학습(fine-tuning)을 통해 성능을 회복한다. - 특히 LLM, Diffusion 모델처럼 큰 모델에서 자주 사용됨
🔹 대표 절차
PAT은 보통 다음 두 가지 파이프라인 중 하나를 따른다:
- Pretrain → Prune → Retrain
(ex: [62], [20]) - Pretrain → Prune (재학습 없이 사용)
(ex: [17], [19])
시각적 구성: 논문 Fig. 5 (c)
🔸 단계별 설명
① Pre-train 단계
- 초기 가중치 로 구성된 dense 모델 을 학습하여
최종 가중치 로 수렴시킴
② Prune 단계
-
성능에 영향이 적은 가중치/필터/뉴런 제거
-
결과:
- : pruning 후 남은 weight
- :pruning 마스크
-
수행 방식:
- One-shot pruning: 한 번에 가지치기
- Iterative pruning: 여러 단계에 걸쳐 점진적으로 가지치기
③ 재학습(Retrain 또는 Fine-tune)
- 두 가지 방식 중 선택:
-
처음부터 다시 학습:
→ 가지치기 구조만 유지하고, weight는 다시 초기화 -
Fine-tuning:
→ 기존 학습된 weight를 유지하면서 성능 회복
- ( W''_t ), ( M'' ): 가지치기 이후 최종 결과
📌 참고 사항
- 가지치기 동안 희소성(sparsity)은
한 번에 적용되기보다는 점진적으로 증가할 수 있음
4.3.1 Lottery Ticket Hypothesis (LTH) 및 그 변형들
✅ 개요
-
LTH (Lottery Ticket Hypothesis) [48, 112]는 신경망 가지치기 분야에서 가장 영향력 있는 가설 중 하나이다.
-
핵심 아이디어는 다음과 같다:
- 사전학습된 네트워크에서 weight의 크기 기준으로 반복적으로 pruning 수행
- 남은 weight는 무작위 초기화가 아닌 원래 초기화 상태로 재설정
- 이후 처음부터 다시 학습 (retrain from scratch) → 원래 성능 회복 가능
-
이 가설은 다음의 기존 통념에 반한다:
"가지치기 후에는 반드시 학습된 weight를 유지해야 한다"는 믿음
- LTH는 dense 모델 안에 독립적으로 학습 가능한 sparse subnetwork가 존재한다고 주장
🔹 주요 연구 분류 (5가지 유형)
① 더 강력한 LTH 가설 제시
- 예: Multi-Prize LTH (MPT) — Diffenderfer & Kailkhura [113]
- winning ticket은 극단적 양자화 (binary weights/activations)에도 견딜 수 있음
- MPT 알고리즘: 이진 신경망에서도 ticket 탐색 가능
② LTH의 전이 가능성 (Transferability)
- 주요 연구: [120, 121, 122, 123]
- 예:
- OneTicket — Morcos et al. [120]: 다양한 데이터셋과 옵티마이저에 범용 적용 가능
- Ticket Transfer Hypothesis — Mehta [121]: 데이터셋 간 winning ticket 전이 실험
③ 다양한 영역으로의 확장
- 이미지 분류 외에도 적용됨:
- GNNs: Graph Lottery Ticket (GLT) — Chen et al. [123]
- Vision-Language 모델 — [122]
- BERT 등 NLP 모델 — Prasanna et al. [117]
④ 이론적 정당성 분석
- 주요 연구: [124, 125, 126]
- 예:
- Zhang et al. [124]: 동역학 시스템 관점에서 수학적 정당성 제시
- Evci et al. [99]: pruning 솔루션을 효과적으로 재학습하는 과정이 핵심
- Zhang et al. [125]: winning ticket의 일반화 성능 향상을 이론적으로 설명
⑤ 가설 재검토 및 반박
- 주요 연구: [110, 127, 128]
- 예:
- Ma et al. [127]: LTH 정의를 엄밀히 재정의하고,
학습률, 에폭 수, 네트워크 구조 등에 따라 winning ticket 탐색 가능성이 달라진다고 주장
- Ma et al. [127]: LTH 정의를 엄밀히 재정의하고,
⚠️ 분류 주의: PBT vs PAT?
- 일부 문헌 [18, 36]에서는 LTH를 PBT (학습 전 가지치기)로 분류하지만,
실제로는 사전학습된 네트워크에서 pruning 마스크를 선택하므로
LTH는 PAT (학습 후 가지치기)로 분류하는 것이 더 적절하다.
4.3.2 기타 점수 기반 가지치기 기법 (Other Score-based Methods)
✅ 핵심 개요
- 점수 기반(score-based) 가지치기의 가장 기본적인 방식은 Norm 기반 평가
- 이후 발전된 방식들은 손실 변화량 또는 새로운 메트릭을 도입하여 더욱 정교하게 중요도 측정
🔹 1. Norm 기반 평가
- Han et al. [13]: 가중치의 절댓값 (Magnitude)을 기준으로 pruning 수행
🔹 2. 손실 변화량(Loss Change) 기반 평가
🧠 Second-order
- SOSP (Second-order Structured Pruning) — Nonnenmacher et al. [67]
→ 필터 제거 시 손실 변화량을 최소화하도록 필터 마스크 조정
🧠 First-order (Taylor Approximation)
-
LLM-Pruner — Ma et al. [20]
→ 중요하지 않은 채널과 어텐션 헤드를 제거
→ 1차 테일러 전개로 손실 변화 근사
→ 가지치기 후 LoRA로 파인튜닝 -
Diff-Pruning — Fang et al. [39]
→ diffusion 모델에서 timestep 별 pruning 중요도 계산 -
UPop — Shi et al. [130]
→ 멀티모달 모델에서 마스크 gradient 누적값 기반으로 중요도 평가
🔹 3. 새롭게 설계된 평가 메트릭
-
Block Influence (BI) — Men et al. [65]
→ 특정 레이어가 히든 상태를 얼마나 변화시키는지 기반으로 평가 -
Perplexity 변화 기반 메트릭 — Kim et al. [133]
→ LLM에서 특정 레이어 제거 시 PPL 변화량으로 중요도 측정
✅ 정리
| 연구 | 기준 | 적용 대상 | 주요 아이디어 |
|---|---|---|---|
| Han et al. [13] | 절댓값 (L1) | weight | 가장 기본적인 norm 기반 |
| Nonnenmacher et al. [67] | 2차 손실 변화 | CNN 필터 | SOSP 방식 |
| Ma et al. [20] | 1차 테일러 + LoRA | LLM | coupled 채널 & attention head 제거 |
| Fang et al. [39] | timestep별 중요도 | Diffusion | Taylor 기반 score |
| Shi et al. [130] | 마스크 gradient | 멀티모달 모델 | UPop 방식 |
| Men et al. [65] | Block Influence | LLM | 히든 상태 변화량 기준 |
| Kim et al. [133] | PPL 변화 | LLM | 레이어 중요도 평가 |
4.3.2 기타 점수 기반 가지치기 기법 (Other Score-based Methods)
✅ 개요
- 어떤 weight, 필터, 채널, 레이어를 가지치기할지를 결정할 때,
그 중요도(score)를 평가하는 다양한 방식이 존재한다. - 여기서는 대표적인 Norm 기반, 손실 변화 기반, 특정 메트릭 기반 방식들을 다룬다.
🔹 1. Norm 기반 가지치기
- Han et al. [13]:
→ 가중치의 절댓값 이 작을수록 중요도가 낮다고 판단
→ 가장 단순하고 널리 쓰이는 방식 (L1 norm 기반)
🔹 2. 손실 변화 기반 가지치기
🧠 1차 테일러 전개 기반
-
LLM-Pruner — Ma et al. [20]
→ 중요하지 않은 채널과 어텐션 헤드 제거
→ 손실 변화 추정:
-
Diff-Pruning — Fang et al. [39]
→ diffusion 모델에서 timestep 별 중요도 평가
→ 역시 1차 테일러 근사 사용
🧠 2차 미분 (Hessian) 기반
- SOSP — Nonnenmacher et al. [67]
→ structured pruning 시 필터 제거의 손실 영향을 더 정밀하게 측정
→ 수식:
→ 여기서 는 손실 함수의 헤시안 행렬 (2차 도함수)
🧠 Gradient 누적 기반
- UPop — Shi et al. [130]
→ 마스크에 학습 가능한 gradient를 누적하여 덜 중요한 부분을 제거
→ 대형 멀티모달 모델에도 적용 가능
🔹 3. 커스텀 메트릭 기반 가지치기
-
Block Influence (BI) — Men et al. [65]
→ 특정 레이어가 hidden state를 얼마나 바꾸는지로 중요도 측정 -
PPL 변화 기반 메트릭 — Kim et al. [133]
→ 레이어를 제거했을 때 모델의 perplexity(PPL)가 얼마나 바뀌는지 측정
✅ 핵심 정리
| 방식 구분 | 주요 연구 | 핵심 아이디어 |
|---|---|---|
| Norm 기반 | Han et al. [13] | 절댓값 작으면 제거 |
| 1차 테일러 | Ma et al., Fang et al. | $\left |
| 2차 테일러 | SOSP [67] | |
| Gradient 누적 | UPop [130] | 마스크 gradient 누적 기반 중요도 |
| Hidden state 변화 | BI [65] | 레이어가 내부 상태에 미치는 영향 |
| PPL 변화 | Kim et al. [133] | 레이어 제거 시 perplexity 변화 |
4.3.3 Sparsity Regularization 기반 가지치기 기법
✅ 개요
- 희소성 정규화(Sparsity Regularization)는 손실 함수에
", , 마스크 패널티" 등을 추가하여
덜 중요한 weight나 채널을 제거하도록 유도하는 가지치기 방식이다. - CNN부터 LLM, GNN, 멀티모달 모델까지 다양한 네트워크에 적용된다.
🔹 1. He et al. [134] — LASSO 기반 채널 선택
- 각 채널에 스칼라 마스크 를 부여
- LASSO (L1 정규화 회귀)로 중요도 계산 후 가지치기
- 남은 채널은 선형 최소제곱법으로 출력 보정
✅ CNN 대상 / Pre-trained 네트워크 기반
🔹 2. ECC (Energy-Constrained Compression) — [139]
- 에너지 예측 모델을 bilinear regression으로 학습
- 가지치기 과정에서 에너지 소비량을 제한 조건으로 추가
✅ 실제 디바이스 에너지 효율 고려
→ 모바일, IoT 등에 적합
🔹 3. NPPM — [140]
- 성능 예측 네트워크를 학습 (structure → accuracy 예측)
- 성능을 직접 측정하지 않고도 가지치기 방향 탐색 가능
✅ 탐색 비용 감소 / 신속한 구조 최적화
🔹 4. DepGraph — Fang et al. [38]
- CNN, RNN, GNN, Transformer 등 구조 전체의
종속성(Dependency)을 그래프로 표현 - 구조적 희소성 정규화와 결합해 범용 structured pruning 수행
✅ 다양한 네트워크에 범용적으로 적용 가능
🔹 5. Xia et al. [137] — L0 정규화 + Min-Max 최적화
- L0 정규화 기반 pruning 마스크 학습
- Weight와 마스크를 동시에 Min-Max 구조로 최적화
- 타겟 구조와 희소성 비율을 정확히 맞추는 방식
✅ 특히 LLMs에 적합
→ 희소 구조 제어 + 성능 보장
🔹 6. Norm + Regularization 혼합 기법
- 일부 연구들([38], [53], [105], [108])은
Norm 기준(L1, L2) + 정규화 penalty를 조합
예:
✅ 빠르고 직관적인 기준 + 이론 기반 제약을 함께 사용하여
→ 더 정교한 가지치기 가능
📌 요약 표
| 방법 | 핵심 기법 | 적용 대상 | 특징 |
|---|---|---|---|
| He et al. [134] | LASSO + 최소제곱 보정 | CNN | 채널 기반, post-hoc pruning |
| ECC [139] | 에너지 정규화 | CNN 등 | 에너지 효율 고려 |
| NPPM [140] | 성능 예측기 기반 정규화 | 범용 | 정확도 예측으로 빠른 탐색 |
| DepGraph [38] | 종속성 기반 구조 분석 | CNN, RNN, GNN, Transformer | 구조적 pruning, 범용성 |
| Xia et al. [137] | L0 + Min-Max 최적화 | LLM | 정확한 sparsity 제어 |
| 혼합 방식 | Norm + Regularization | 범용 | 정밀도 향상 가능 |
4.3.4 Pruning in Early Training
✅ 개요
- 이 접근법은 전체 학습을 마치기 전에,
초기 학습 단계 ()에서 가지치기를 수행하는 방법이다. - 초기 weight 상태 에서 pruning → 전체 학습 비용을 줄이고 효율성 증가
🔹 주요 연구 및 방법
🔸 Early-Bird (EB) Ticket — You et al. [141]
- 초기 학습 단계에서 winning ticket을 탐색
- 다음과 같은 저비용 학습 조건에서도 가능:
- Early stopping
- Low-precision training
- Large learning rate
- Dense 모델과 유사한 성능 달성
🔸 EarlyBERT — Chen et al. [142]
- EB 개념을 BERT에 확장
- 사전학습 초기에 구조적 winning ticket 식별
- 구조적 pruning 가능
🔸 Frankle et al. [144]
- ResNet-50, Inception-v3 (ImageNet)
- 초기 학습 중 SGD 노이즈에 안정적인 서브네트워크는
→ 전체 학습 완료 후에도 높은 정확도 도달 가능
✅ 요약 포인트
- 초기 학습만으로도 효과적인 pruning 가능
- 전체 학습 없이 winning ticket 식별
- 학습 시간/자원/탐색 비용 절약
4.3.5 Post-Training Pruning
✅ 개요
- 전통적인 PAT 방식:
Pretrain → Prune → Retrain - Post-Training Pruning은 재학습 없이
Pretrain → Prune으로 단순화 - 보상 메커니즘을 통해 정확도 손실 최소화
- 특히 수십억 개 파라미터 모델(LLM 등)에서 매우 유리
🔹 주요 방법들
🔸 Kwon et al. [145]
- Transformer용 구조적 pruning 프레임워크
- Fisher 정보 기반 마스크 탐색
- 1 GPU에서 3분 내 pruning 가능, 재학습 불필요
🔸 SparseGPT [17]
- LLM 대상 비구조적 post-training pruning
- pruning을 희소성 재구성 문제로 접근
- 재학습 없이도 50% sparsity + 정확도 유지
🔸 Wanda [49]
- SparseGPT의 비용 이슈 보완
- weight 크기 + 입력 norm으로 pruning 수행
- weight 업데이트 없이 가지치기 가능
🔸 SliceGPT [19]
- 구조적 pruning 적용
- 정사각 행렬 변환 + PCA로 weight 행렬 row/column 제거
🔸 FLAP [146]
- LLM의 출력 변동성을 측정 (fluctuation metric)
- Bias compensation으로 정확도 손실 보정
✅ 요약 포인트
| 방법 | 유형 | 특징 |
|---|---|---|
| Kwon et al. | 구조적 | Fisher 기반 마스크, 빠른 수행 |
| SparseGPT | 비구조적 | 희소성 재구성, 고정확도 유지 |
| Wanda | 비구조적 | 경량 방식, weight 미업데이트 |
| SliceGPT | 구조적 | PCA 기반 행/열 제거 |
| FLAP | 보정 메커니즘 | Bias compensation 활용 |
4.4 Run-time Pruning
✅ 개요
- 기존 가지치기는 한 번 pruning된 모델을 모든 입력에 재사용 (Static pruning)
- Run-time pruning은 입력에 따라 동적으로 pruning 수행
- 입력 난이도에 따라 필요한 모델 용량이 다르다는 가정에 기반
🔹 주요 기법 및 연구
🔸 RNR — Rao et al. [147]
- Runtime Network Routing
- 입력 이미지 + feature map 기반으로
최적 경로 subset 동적 선택
🔸 Tang et al. [64]
- 채널 중요도는 입력별로 달라진다
- 입력마다 다른 subnet 사용
- 중요도가 낮은 채널은 스킵 → 연산 감소
🔸 CGNets — Hua et al. [148]
- 일부 채널만 사용해 convolution 수행
- 출력 활성값의 부분 합(partial sum)으로 중요 영역 예측
🔸 FBS — Gao et al. [149]
- Feature Boosting and Suppression
- 채널 기여도(saliency) 예측
→ 덜 중요한 채널은 runtime에서 제거
🔸 Self-supervised 방식들
-
Elkerdawy et al. [150]: dynamic pruning을
self-supervised binary classification으로 재정의 -
CDG (Contrastive Dual Gating) — Meng et al. [151]:
contrastive learning 기반 self-supervised pruning
🔸 DynaTran — Tuli and Jha [153]
- Transformer용 runtime pruning
- 입력 행렬의 크기(magnitude)를 기반으로
activation pruning 수행
✅ 요약 포인트
| 연구 | 방식 | 핵심 아이디어 |
|---|---|---|
| RNR [147] | 동적 경로 선택 | Feature map 기반 경로 최적화 |
| Tang et al. [64] | 입력별 채널 pruning | 채널별 중요도 달라짐 |
| CGNets [148] | 부분 합 기반 예측 | 일부 채널만 사용 |
| FBS [149] | 기여도 예측 | 덜 중요한 채널 제거 |
| CDG [151] | Self-supervised | contrastive learning 기반 |
| DynaTran [153] | Transformer 최적화 | 입력 크기 기반 activation pruning |
5. Pruning Criteria (가지치기 기준)
✅ 개요
- Pruning을 수행할 때,
어떤 weight/filter/neuron을 제거할지 결정하는 기준이 필요함 - 이 절에서는 일반적으로 사용되는 가지치기 기준들을 소개
🔹 주요 기준 (Types of Criteria)
1. Magnitude 기반 ([12, 154–156])
- weight의 절댓값 크기에 따라 가지치기
- 작을수록 덜 중요하다고 판단 → 제거
2. Norm 기반 ([63, 83])
- weight 집합의 L1, L2 노름(norm)을 사용
- 예: 필터의 L2 norm이 작으면 제거 대상
3. Saliency / Sensitivity 기반 ([82, 157])
- 입력 또는 출력에 대해 얼마나 민감하게 반응하는지 평가
- 중요한 정보 흐름을 유지하기 위해 Saliency 높은 weight는 보존
4. Loss Change 기반 ([15, 62, 67, 157, 158])
- weight 제거 전/후의 손실 함수 변화량 측정
- 손실에 거의 영향이 없는 weight는 제거 가능
✅ 참고
- 이 기준들 간에는 엄격한 구분이 없다
- 목적과 적용 대상에 따라 중요도를 다르게 해석할 수 있음
5.1 Magnitude-based Pruning
✅ 개요
- 가지치기 기준으로 가장 직관적이고 널리 쓰이는 방법
- weight의 절댓값 크기(magnitude)가 작을수록 중요도가 낮다고 가정
- 해당 weight를 제거함으로써 성능 손실을 최소화
🔹 공식 표현
- : 가지치기 마스크
- : 기준 임계값
🔹 확장된 기준
🔸 Wanda [49] — Weight + Activation 크기
→ 활성값의 크기도 고려하여 가지치기 수행
🔸 Dery et al. [132] — LLM Module Pruning
- “module relevance” 절댓값이 가장 큰 모듈부터 제거
- pruning constraint 만족될 때까지 반복
🔹 구조별 적용
- Unstructured: 단일 weight 단위 ([48], [49], [154])
- Structured: 필터/채널 단위 ([63], [94], [132])
🔹 적용 방식
- One-shot pruning
- Iterative pruning ([160], [161])
🔹 성능 특성
- Lubana & Dick [155]:
→ Magnitude 기반 pruning이 더 빠른 수렴을 보임
5.2 ℓₚ Norm 기반 Pruning
✅ 개요
- 필터, weight, 뉴런 등의 전체적인 크기(노름)를 기반으로 가지치기 중요도를 평가
- ℓₚ norm 값이 작을수록 덜 중요하다고 판단되어 pruning 대상이 됨
🔹 핵심 공식 (He et al. [83])
🔹 수식 구성 설명
| 기호 | 의미 |
|---|---|
| i번째 layer의 j번째 필터 | |
| 입력 채널 수 | |
| 필터 커널 크기 (예: 3x3 이면 ) | |
| 노름 차수 (L1: , L2: ) |
- 필터의 weight를 절댓값 → 제곱 → 합산 → 루트 형태로 정리
- ℓₚ norm 값이 작을수록 중요도가 낮음
🔹 특징
- Structured pruning (필터/채널 단위)에서 자주 사용됨
- L1, L2 norm 모두 가능
- 종종 정규화 기반 sparsity regularization과 함께 사용됨 (→ 6.1절 참고)
🔹 관련 문헌
- [49], [63], [83] 등에서 ℓₚ norm을 pruning 기준으로 사용
5.3 Sensitivity and/or Saliency 기반 Pruning
✅ 개요
- weight, filter, neuron 등의 민감도(Sensitivity) 또는 살리언시(Saliency)를 이용하여 중요도를 측정
- 일반적으로 "제거 시 손실에 얼마나 영향을 주는가?"를 기반으로 가지치기 수행
🔹 방법별 정리
1. LeCun et al. [162] — 손실 변화 기반 Saliency
- weight를 제거했을 때 손실 함수의 변화량으로 중요도를 평가
- 손실 변화가 클수록 → 더 중요한 weight로 간주 → 유지
- → Saliency = 제거로 인한 loss 증가 정도
2. Lee et al. [54] — Connection Sensitivity Criterion
- 손실 함수의 gradient를 정규화하여 민감도(sensitivity)를 계산
-
설명:
- : weight 의 민감도 (중요도 점수)
- : 손실 함수 을 마스크 에 대해 미분한 값
- : 전체 마스크 개수
-
해석:
- gradient가 클수록 → 해당 weight 제거 시 영향이 큼
- → 중요 weight로 간주
3. Zhao et al. [82] — BN 재정의 + 채널 살리언시
- Batch Normalization 레이어를 활용하여 채널 중요도를 정의
-
설명:
- : BN의 scale 파라미터
- : BN의 shift 파라미터
- : 채널 중요도를 나타내는 새로운 항
-
해석:
- 가 작거나 의 분포가 편중된 채널 → 중요도 낮음
- 값이 아닌 분포 기반으로 채널 제거 여부 판단
✅ 특징 요약
| 논문 | 기준 | 방식 |
|---|---|---|
| LeCun et al. [162] | 손실 변화량 | 제거 후 손실 증가 |
| Lee et al. [54] | Gradient 민감도 | 마스크에 대한 미분값 정규화 |
| Zhao et al. [82] | BN 재정의 | 기반 채널 평가 |
5.4 Loss Change 기반 Pruning
✅ 개요
Loss Change는 weight나 filter 등을 제거했을 때 손실 함수가 얼마나 변화하는지를 기준으로
해당 요소의 중요도를 계산하는 대표적인 가지치기(pruning) 방법이다.
🔹 1차 테일러 근사 (First-order Taylor Approximation)
손실 함수의 변화량을 아래와 같이 근사한다:
가지치기로 weight를 0으로 만든다면:
→ 따라서 가지치기 점수는 다음과 같이 계산된다:
🔹 예시: BatchNorm Scaling Factor 기반 (You et al. [15])
BatchNorm의 scaling factor ( \lambda )를 제거한다고 가정할 때 손실 변화:
📌 필터 단위로 적용하는 경우:
🔹 2차 테일러 근사 (Second-order Taylor Approximation)
보다 정밀하게 손실 변화를 근사할 경우 2차 테일러 전개를 사용한다:
- ( H ): Hessian (손실 함수의 2차 미분)
🔹 예시: 채널 제거 시 손실 변화 (Liu et al. [62])
채널 제거를 one-hot 마스크 ( e_i )로 표현했을 때 손실 변화는 다음과 같다:
- ( g_i ): i번째 채널에 대한 gradient
- ( H_{ii} ): Hessian의 대각 성분
6. Learn to Prune (학습 기반 가지치기)
🔹 개요
기존의 기준 기반 프루닝과 달리, 학습 기반 가지치기는
모델 스스로 pruning 전략을 학습하여 최적의 희소 구조를 찾아간다.
🔸 1. Sparsity Regularization (희소성 정규화)
- 손실 함수에 정규화 항을 추가하여 자연스러운 희소 구조를 유도
- L1, L0, Group LASSO 등 다양한 방식 존재
- 관련 논문: [57, 59, 134, 168, 169]
🔸 2. Meta-learning 기반 Pruning
- pruning 전략 자체를 학습하는 메타러너를 활용
- 데이터와 태스크에 따라 최적의 pruning 방식 자동 탐색
- 관련 논문: [84, 168]
🔸 3. GNN(Graph Neural Network) 기반
- 신경망을 그래프로 해석하고,
GNN을 통해 노드(필터, weight 등)의 중요도 학습 - 관련 논문: [170]
🔸 4. 강화학습 기반 Pruning
- pruning을 의사결정 문제로 보고,
보상에 따라 pruning 정책 학습 - 특히 입력 의존 동적 pruning(runtime)과 결합 시 효과적
- 관련 논문: [147, 171]
6.1 Sparsity Regularization 기반 Pruning
✅ 개요
Sparsity Regularization 기반 가지치기 방법은
가중치 ( W )와 마스크 ( M )를 함께 학습하면서
모델이 스스로 희소성을 갖도록 유도한다.
손실 함수는 다음과 같이 구성된다:
- : 일반적인 예측 손실 (예: MSE 등)
- : 희소성을 유도하는 정규화 항 (예: L1, Group LASSO)
- : 정규화 항의 중요도 조절 파라미터
🔹 Scaling Factor 기반 학습
채널, 필터 등에 스케일링 계수 를 부여하고,
정규화 항을 에 적용하여 중요도를 학습한다.
손실 함수 예시:
- 가 작아질수록 중요도가 낮은 것으로 간주되어 pruning 대상이 된다.

🔹 예시: He et al. (2017) - Channel Pruning via LASSO
He 등은 채널 가지치기를 다음과 같은 형태로 최적화 문제로 정식화하였다:
🔹 제약 조건
🔸 기호 설명
| 기호 | 의미 |
|---|---|
| i번째 채널 중요도 스케일 | |
| i번째 채널의 입력 텐서 | |
| i번째 채널의 weight | |
| Frobenius Norm | |
| 샘플 수 | |
| 전체 채널 수 | |
| 유지할 채널 수 | |
| , | 커널의 높이/너비 |
🔹 해결 방법
- LASSO 회귀로 를 학습하고,
- Greedy 방식으로 중요도가 낮은 채널부터 제거한다.
6.2 Meta-learning 기반 Pruning
✅ 개요
기존의 규칙 기반 가지치기(pruning)와 달리,
Meta-learning 기반 가지치기는 모델이 스스로 pruning 전략을 학습하도록 유도한다.
🔹 대표 방법: PruningNet (Liu et al. [84])
PruningNet은 다양한 가지치기 구조를 입력으로 받아,
해당 구조에 적합한 가중치(weight)를 출력해주는 메타 네트워크이다.
🔸 입력 및 출력 구조
- : 번째 레이어의 채널 수 (네트워크 구조를 정의하는 인코딩)
- : 해당 구조에 맞는 예측된 가중치
🔸 핵심 아이디어
- 다양한 구조에 대한 성능을 모델이 직접 학습
- 실제 학습 없이도 성능 추정이 가능
- 다양한 구조에 대해 빠르게 가지치기 결과를 예측할 수 있음
🔹 최적 구조 탐색 방법
구조 탐색 공간이 매우 크기 때문에,
진화 알고리즘(Evolutionary Search)을 활용해 최적 구조를 찾는다:
- 무작위 구조 벡터를 생성해 PruningNet에 입력
- 예측된 성능을 기반으로 좋은 구조만 선택
- 선택된 구조를 교배/돌연변이 등으로 진화시켜 점점 더 좋은 구조를 탐색
✅ 장점 요약
| 항목 | 설명 |
|---|---|
| 구조 일반화 | 다양한 구조에 대해 빠르게 대응 가능 |
| 계산 효율 | 학습 없이 pruning 결과를 빠르게 예측 |
| 탐색 자동화 | 진화 알고리즘을 통해 구조를 최적화 |
6.3 Graph Neural Network(GNN) 기반 Pruning
✅ 개요
신경망은 그래프(노드와 엣지) 구조로 표현될 수 있으며,
이를 활용하여 Graph Neural Network(GNN) 기반으로 가지치기를 수행할 수 있다.
Zhang et al. [170]은 이를 바탕으로 GraphPruning이라는 GNN 기반 모델 압축 방법을 제안하였다.
🔹 전체 구조 요약
- 각 레이어는 하나의 노드로 표현되고,
임베딩 벡터 를 갖는다. - 그래프 집계기(Graph Aggregator) 는 이 임베딩들을 받아
각 레이어에 대한 고수준 특성 를 출력한다.
- 각 는 해당 레이어의 weight를 생성하는 Fully Connected Layer에 입력된다:
- : 가지치기된 네트워크의 i번째 레이어 가중치
- : GNN 집계기의 학습 파라미터
- : 각 FC 레이어의 파라미터
🔸 Pruned Network 생성 및 학습
- 위 과정을 통해 구성된 Pruned Network는
전통적인 방식으로 완전 학습(full training) 된다.
🔹 최적 구조 탐색 (강화학습 기반)
- 여러 네트워크 구조(레이어별 채널 수 조합 등)를 생성하고,
- 연산량 제약 조건 하에서 가장 성능이 좋은 구조를
강화학습(Reinforcement Learning)을 통해 탐색한다.
이 과정에서는 Graph Aggregator와 FC들은 더 이상 업데이트되지 않는다.
✅ 요약
| 구성 요소 | 역할 |
|---|---|
| Graph Aggregator | 각 레이어의 고수준 피처 생성 |
| FC Layer | 해당 피처로 가지치기된 weight 생성 |
| RL 탐색기 | 최적 네트워크 구조 조합 탐색 |
6.3 Graph Neural Network(GNN) 기반 Pruning
✅ 개요
- 신경망은 본질적으로 레이어(노드)들로 구성된 그래프 구조로 볼 수 있다.
- GraphPruning (Zhang et al. [170])은 이러한 구조를 활용해
GNN(Graph Neural Network)으로 각 레이어의 중요도를 예측하고 가지치기하는 방식이다.
🔹 전체 구조 요약
-
각 레이어 = 노드로 표현
각 노드는 임베딩 벡터 (채널 수, 커널 크기 등 포함)을 가진다. -
Graph Aggregator
모든 노드 임베딩을 입력받아 각 노드의 고수준 피처 를 생성한다: -
FC 레이어를 통한 가중치 생성
각 는 해당 레이어의 FC 레이어를 통해 가지치기된 가중치 로 변환된다:
🔸 구성 요소 설명
| 구성 요소 | 설명 |
|---|---|
| 레이어 의 입력 임베딩 (1x7 크기) | |
| GNN 기반 Graph Aggregator (노드 간 상호작용 반영) | |
| 노드 의 요약 피처 | |
| 노드 의 가중치를 생성하는 Fully Connected 레이어 | |
| 가지치기된 i번째 레이어의 weight | |
| GNN의 학습 가능한 파라미터 | |
| 각 FC 레이어의 학습 파라미터 |
🔹 이후 과정
- 이렇게 생성된 Pruned Network는 전통적인 방식으로 완전 학습된다.
- 이후, 강화학습(Reinforcement Learning)을 통해
연산량 제약 하에서 최적의 구조를 탐색한다.
이 단계에서는 와 의 가중치는 고정된다 (업데이트 X)
✅ 핵심 요약
- "레이어 정보를 그래프화 + GNN으로 요약 + FC로 weight 생성"이라는 흐름
- 레이어 간 상호작용까지 고려한 정교한 pruning 방식
6.4 Reinforcement Learning(RL) 기반 Pruning
✅ 개요
- RL(강화학습)을 이용해 각 레이어의 가지치기 비율을 자동으로 결정하는 방식
- 사람의 수동 설정 없이도 레이어마다 다른 비율로 프루닝이 가능함
- 대표적인 방법: AMC (AutoML for Model Compression) [171]
🔹 전체 동작 흐름
-
에이전트(Agent)가 신경망의 각 레이어 정보를 상태(state)로 입력받음
→ : 번째 레이어의 임베딩 상태 -
각 상태에 대해 가지치기 비율(action)을 출력
→ : 해당 레이어의 프루닝 비율 (예: 0.3) -
해당 레이어를 만큼 가지치기하고, 다음 레이어로 이동
-
마지막 레이어까지 반복 → 전체 네트워크 구조 완성
-
네트워크를 평가하고 보상(reward)을 부여
🔸 Q-Learning 기반 학습 방식
Q-네트워크는 상태-행동 쌍의 가치를 예측한다:
목표값 는 다음과 같이 계산된다:
- : 실제 보상
- : baseline (보상 편향 보정)
- : 미래 보상에 대한 할인율
- : Q 네트워크의 가중치
🔸 보상 함수 설계
정확도를 유지하면서 연산량(FLOPs)이나 파라미터 수를 줄이면
보상이 커지는 구조:
✅ 요약
| 구성 요소 | 설명 |
|---|---|
| 현재 레이어의 상태(정보) | |
| 프루닝 비율 (행동) | |
| Q | 상태-행동의 가치를 평가하는 함수 |
| 정확도 + 경량성 기반의 보상 | |
| 목적 | 레이어별 최적의 프루닝 비율을 자동으로 찾기 |
RL 기반 프루닝은 CNN, ViT, LLM 같은 복잡한 모델을 효율적으로 경량화할 수 있는 강력한 방식이다.
7. A COMPREHENSIVE COMPARATIVE ANALYSIS
(포괄적 비교 분석)
✅ 분석 목적
이 장에서는 다양한 가지치기(Pruning) 기법들을 다음 기준으로 정량 비교함:
-
자주 사용되는 모델에서의 성능 비교
- 예: VGG-16, ResNet, BERT 등
-
8가지 대비 설정 (contrast settings)
- 예: Structured vs. Unstructured, One-shot vs. Iterative 등
-
레이어별 밀도 분포 (Layer-wise densities)
- 일부 레이어만 많이 가지치고, 일부는 덜 가지치기
-
감독 수준 (Supervision level)
- 데이터 유무, 학습 기반 여부 등
🔸 실험 기준
- 가능한 한 동일한 설정 및 함수를 적용해 공정한 비교 진행
- 실험 세부 설정은
Appendix B, 확장 비교 결과는Appendix C에 포함됨
🔎 이어지는 내용
- 7.1절부터는
8가지 대비 기준에 따라 실제 프루닝 성능 비교가 진행됨
7.1 Unstructured vs. Structured Pruning
(비구조적 vs. 구조적 가지치기 비교)
✅ 주요 비교 포인트
| 방식 | 설명 | 특징 |
|---|---|---|
| Unstructured Pruning | 개별 weight 단위로 제거 | 높은 prune 비율 가능, 정확도 손실 적음 |
| Structured Pruning | 필터, 채널, 레이어 단위로 구조적으로 제거 | 추론 속도 향상, 정확도 손실 상대적으로 큼 |
🔹 왜 Unstructured가 더 정확도가 높을까?
- Unstructured Pruning은 개별 weight 중요도만 보고 제거 → 세밀하게 조정 가능
- Structured Pruning은 필터, 채널, 레이어 단위로 묶어서 제거
→ 여러 레이어 간 구조적 연관성(Structural Coupling)을 고려해야 해서
→ "모든 제거 대상 weight가 일관되게 중요하지 않아야" 함
→ 실제 적용 시 Noise 발생이 더 큼
Amersfoort et al. [173]은 SNIP-Structured, GraSP-Structured가
비구조적 버전보다 노이즈가 더 많다고 주장함
🔸 실험 결과 요약
| 실험 모델 | 내용 |
|---|---|
| VGG-16 | Table 5: Unstructured vs. Structured 성능 비교 (3회 평균) |
| OPT (LLM) | Table 6: Unstructured > Semi-structured > Structured |
- 동일한 prune ratio일 경우:
- Unstructured > Semi-Structured > Structured
- 성능 측면에서 일반적으로 위 순서대로 좋음
✅ 요약
- 구조적 가지치기는 하드웨어 가속에 적합하지만,
정확도 손실이 생길 가능성 높음 - 비구조적 가지치기는 정확도 보존 측면에서 우수하지만,
특수 하드웨어가 필요할 수 있음
7.2 One-shot vs. Iterative Pruning
(원샷 vs. 반복 가지치기 비교)
✅ 개념 정리
| 구분 | One-shot Pruning | Iterative Pruning |
|---|---|---|
| 방식 | 한 번만 스코어링 후 전체 가지치기 | 여러 단계에 걸쳐 반복적으로 Score → Prune → Update 수행 |
| 장점 | 속도 빠름, 비용 낮음 | 정확도 높음, 안정적 |
| 단점 | 초기 스코어에 의존 → 주요 weight 제거 위험 | 계산 비용 증가, 반복 학습 필요 |
| 주요 이슈 | Layer Collapse 위험 존재 | 상대적으로 안정적 pruning 가능 |
🔸 기술적 분석
- One-shot pruning은 초기 모델의 스코어만으로 pruning을 수행하기 때문에
중요도가 늦게 드러나는 weight를 놓칠 수 있음 ([120]) - 반복형 방법은 압축된 모델에 맞는 gradient를 반영하며 훈련하므로
실제로 성능이 더 안정적 ([15], [63], [121], [176]) - Lin et al. [96]:
- One-shot → "Dense 모델 기준"으로 경사 하강
- Iterative → "Pruned 모델 기준"으로 학습 방향 선택
- Taylor 기반 surrogate loss landscape는 local 성질이 강하므로
iterative pruning이 더 합리적이라는 이론적 근거 존재 ([164])
🧪 실험 결과 (Fig. 7)
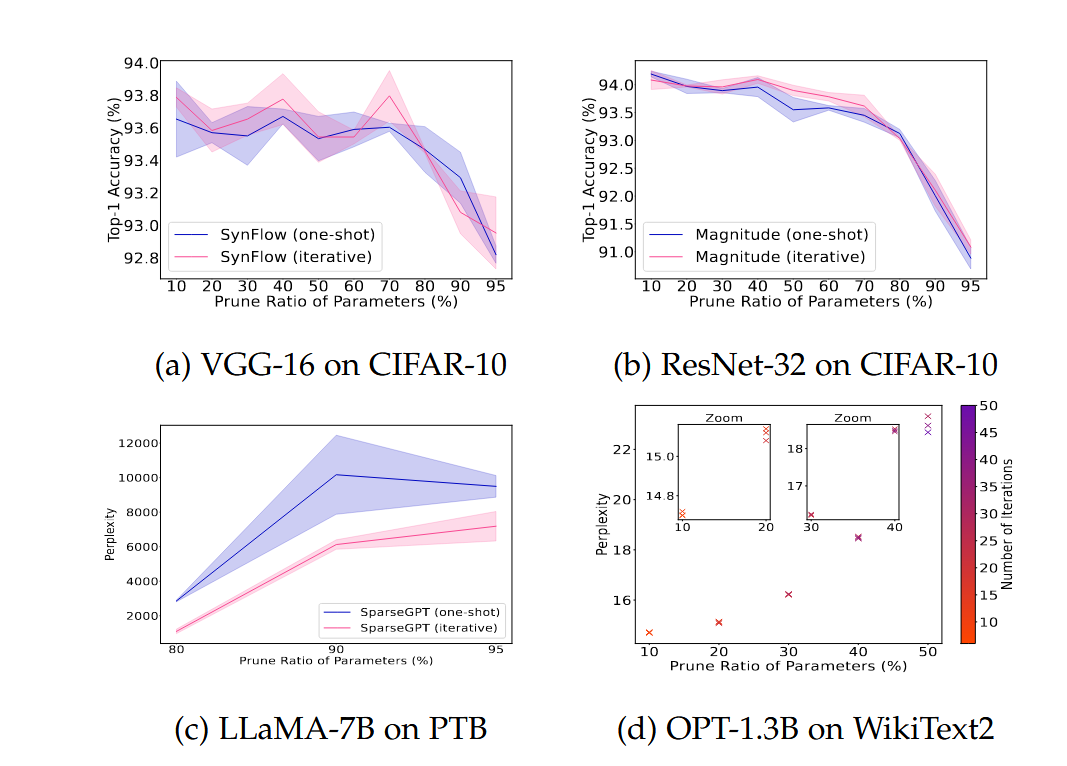
| 모델 | 기법 | 주요 결과 |
|---|---|---|
| (a) VGG-16 on CIFAR-10 | SynFlow | Iterative 방식이 전반적으로 정확도 우위 |
| (b) ResNet-32 on CIFAR-10 | Magnitude | 반복 방식이 layer collapse 방지 및 성능 우세 |
| (c) LLaMA-7B on PTB | SparseGPT | 반복 방식에서 Perplexity 더 낮음 (성능 우수) |
| (d) OPT-1.3B on WikiText2 | Iteration 수 변화 | Iteration 수가 많을수록 Perplexity 감소 (더 나은 결과) |
도표 해석 팁: 색이 짙을수록 iteration 수가 많음을 의미하며,
상자형 점은 성능 측정값 (Top-1 Accuracy or Perplexity)을 나타냄.
✅ 핵심 요약
- Iterative Pruning이 대부분의 상황에서 One-shot Pruning보다 성능이 뛰어남
- 특히 대규모 모델(LLM)에서도 반복 기반 pruning이 더 적은 성능 손실로 고효율 pruning 가능
- 계산 비용이 허용된다면 반복 기반 pruning을 추천
🔍 7.3 Data-free vs. Data-driven Pruning
✅ 핵심 구분
-
Data-free Pruning
→ 학습 데이터 없이 가지치기 수행
→ 대표 기법: Random, Magnitude, SynFlow [50] -
Data-driven Pruning
→ 학습 데이터를 활용하여 가지치기
→ 대표 기법: SNIP [54], GraSP [56], Wanda [49], LLM-Pruner [20], LoRA-Pruner [182]
🔸 실험 분석: PBT 방식 (Pruning Before Training)
-
적용 모델:
- VGG-16 (CIFAR-10)
- ResNet-32 (CIFAR-100)
- ResNet-50 (ImageNet)
-
비교 메서드:
- Data-free: Random, Magnitude, SynFlow
- Data-driven: SNIP, GraSP
📊 Table 7
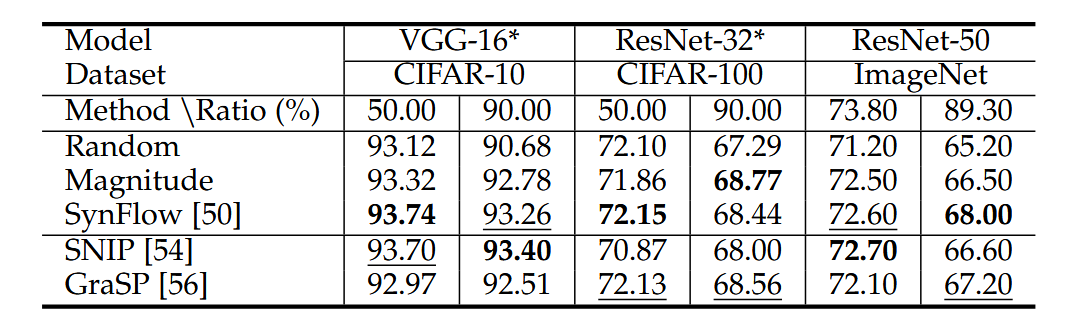
✅ SynFlow는 데이터 없이도 SNIP, GraSP와 유사하거나 더 좋은 성능 달성
→ 데이터가 없더라도 성능 저하가 크지 않음을 보여줌
🔸 실험 분석: PAT 방식 (Pruning After Training)
- 적용 모델:
- LLaMA-7B
- 테스트 데이터셋: BoolQ, PIQA, HellaSwag, WinoGrande
Table 8
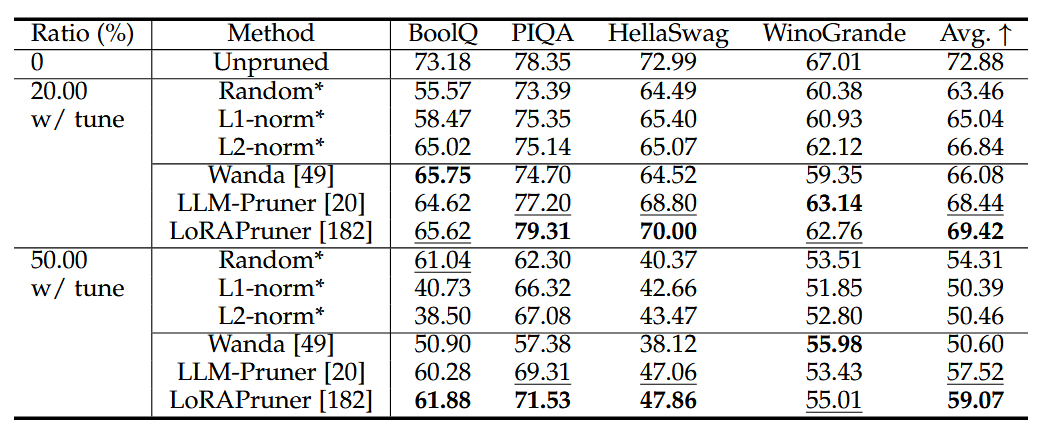
🔍 데이터 기반 방식(Wanda, LoRA-Pruner)가 항상 무작위 방식(Random, Norms)보다 좋은 결과
🔎 결론 정리
- PBT 방식에서는 데이터가 없어도 좋은 성능 가능
→ SynFlow는 GraSP보다 낫고 SNIP와 유사 - PAT 방식에서는 데이터가 필수적
→ 데이터 기반 접근이 성능 면에서 확실히 우위
🧠 핵심 요약:
- PBT에서는 데이터 없어도 괜찮을 수 있음
- PAT에서는 데이터 기반이 성능 보장
🔍 7.4 Initialized vs. Pre-trained Weights 기반 가지치기
가지치기는 초기화된 가중치(initialized weights) 또는 사전 학습된 가중치(pre-trained weights)를 기반으로 수행될 수 있습니다. 이 두 접근 방식은 성능과 견고성 측면에서 큰 차이를 보입니다.
🔸 CNN에서의 관찰 결과
-
초기화된 가중치 기반 가지치기 (PBT 방식)
-
예: SNIP [54], GraSP [56], SynFlow [50]
-
마스크 섞기(mask shuffle), 가중치 재초기화(weight reinit) 등의 조작에도 강건함
-
➜ 서브네트워크의 성능이 거의 유지됨
-
이유: 남아있는 가중치 분포가 조작 후에도 거의 변하지 않음
(분포 유사성 측정: Wasserstein Distance [183])
-
-
사전 학습된 가중치 기반 가지치기 (예: LTH [48])
- 구조만 유지하고 weight를 재설정하면 성능 저하
- ➜ 학습된 weight 위치 정보가 중요
🔸 이론적 해석
-
Qiu & Suda [184]
- 학습된 가중치는 두 가지 요소로 구성:
- 위치 (mask 위치)
- 정확한 값 (가중치 값)
- 이 중 위치 정보가 더 많은 학습 정보를 담고 있음
- 학습된 가중치는 두 가지 요소로 구성:
-
Wolfe et al. [185]
- 사전 학습 횟수는 데이터셋 크기에 따라 로그 함수처럼 증가
- 성능 좋은 subnet을 만들기 위해 적절한 pretraining 필요
🔸 트랜스포머(Transformers)의 경우
- 사전 학습이 필수적
- 트랜스포머는 자기지도학습 기반 사전학습 없이는 성능이 저조함
- 따라서 대부분 Pre-trained 모델을 기반으로 가지치기 수행
📊 실험 결과 요약 (Fig. 8 기준)
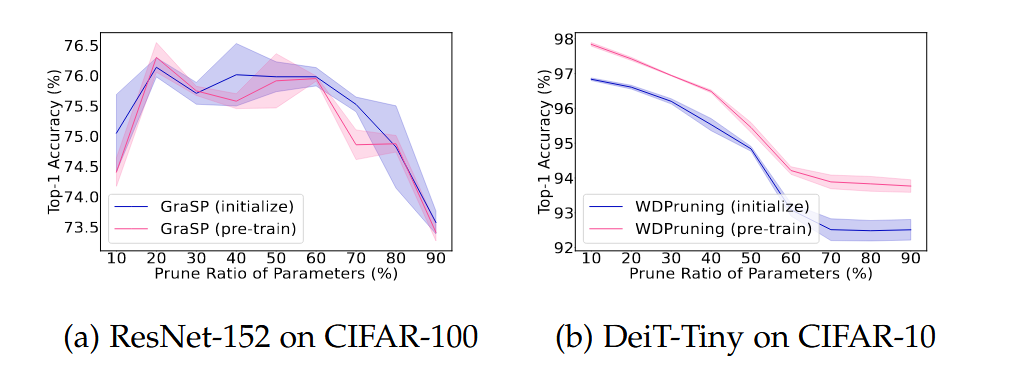
-
(a) GraSP (PBT 방식):
- Pre-trained 가중치를 사용해도 Top-1 정확도가 크게 향상되지 않음
-
(b) WDPruning (PAT 방식):
- Pre-training이 가지치기 성능 향상에 중요한 역할을 함
✅ 정리
| 모델 | 전략 | 특징 |
|---|---|---|
| CNN (초기화 가중치) | PBT | 구조에 강건, 분포 변화 적음 |
| CNN (사전학습 가중치) | PAT | 구조에 민감, weight 위치가 중요 |
| Transformer | 대부분 PAT | Pretraining 없이 가지치기 불가 |
🔍 7.5 Global vs. Local Pruning
📌 용어 정리
| 유형 | 정의 | 특징 |
|---|---|---|
| Local Pruning (로컬 가지치기) | 각 레이어별로 가지치기 수행 | - 레이어별 비율 설정 필요 - 보통 일정 비율 적용 |
| Global Pruning (글로벌 가지치기) | 전체 네트워크에서 중요도 순으로 구조 제거 | - 자동으로 레이어별 비율이 결정됨 - 중요도 기준의 전역 정렬 필요 |
🔸 Local Pruning
- 사전 정의된 레이어별 비율 설정 필요
→ 많은 하이퍼파라미터 수, 비효율적인 희소성(sparsity) 발생 가능 - 일반적으로 전체 레이어에 동일한 prune 비율 적용하여 단순화
- 특히 LLM에서는 Local 방식이 더 우수하다고 보고됨 ([20])
🔸 Global Pruning
- 전체 네트워크 기준으로 pruning score를 정렬 후 절단
- 레이어별 prune 비율이 자동으로 다르게 적용됨
- 하지만 LLM에서는 적용 시 문제가 발생:
- 레이어 간 크기 차이가 큼
→ 일부 feature는 20배 이상 큰 값을 가짐 ([189])
→ 중요도 비교가 어렵고, 잘못된 가지치기로 이어질 수 있음
- 레이어 간 크기 차이가 큼
🔸 연구 예시
| 방법 | 유형 | 설명 |
|---|---|---|
| Ma et al. [20] | Local | LLM에서는 Local pruning이 더 안정적이라고 주장 |
| Bai et al. [190] - SparseLLM | Global | Local pruning이 중간 레이어의 입출력 정렬을 지나치게 제한한다고 비판 → 이를 해결하기 위해 Global 방식 제안 |
✅ 정리 요약
| 항목 | Local Pruning | Global Pruning |
|---|---|---|
| 적용 단위 | 레이어별 | 전체 네트워크 기준 |
| 비율 설정 | 수동 설정 필요 | 자동으로 조정됨 |
| 장점 | 간단하고 안정적 | 유연하고 구조 최적화 가능 |
| 단점 | 비효율적 희소성 | 비교 불가능한 스코어 문제 (특히 LLM) |
| LLM에 적합도 | 비교적 적합 | 최근 일부 global 방식이 등장 중 (예: SparseLLM) |
🧠 7.6 Training from Scratch vs. Fine-tuning
📌 목적:
가지치기 후 성능 회복을 위해 서브네트워크를 다시 학습하는 방법 비교
✅ Fine-tuning (파인튜닝)
- 기존 학습된 가중치 그대로 유지하고 이어서 학습
- 빠른 수렴, 높은 정확도
- 특히 ImageNet 같은 대규모 데이터셋에서 효과적
📚 관련 연구:
- Li et al. [63]: fine-tuning > scratch
- Liu et al. [128]: ADMM 기반 pruning에서 fine-tuning이 더 우수
- Fang et al. [39]: scratch는 수렴까지 더 많은 단계 필요
✅ Training from Scratch (처음부터 학습)
- pruning 이후 가중치 재초기화 후 처음부터 다시 학습
- 더 많은 연산 필요, 수렴 느림
- 일부 경우 성능은 fine-tuning보다 낮음
📚 관련 연구:
- Liu et al. [110]: 일부 네트워크(ResNet 등)에서는 scratch가 더 나을 수도 있음
✅ Weight Rewinding (가중치 되감기)
- 초반 몇 에폭의 가중치를 사용해 pruning 후 재학습
- fine-tuning보다 더 나은 정확도 달성 가능
📚 관련 연구:
- Frankle et al. [111, 144]: rewinding이 fine-tuning보다 성능 좋음
📊 실험 요약 (Fig. 9 기준)
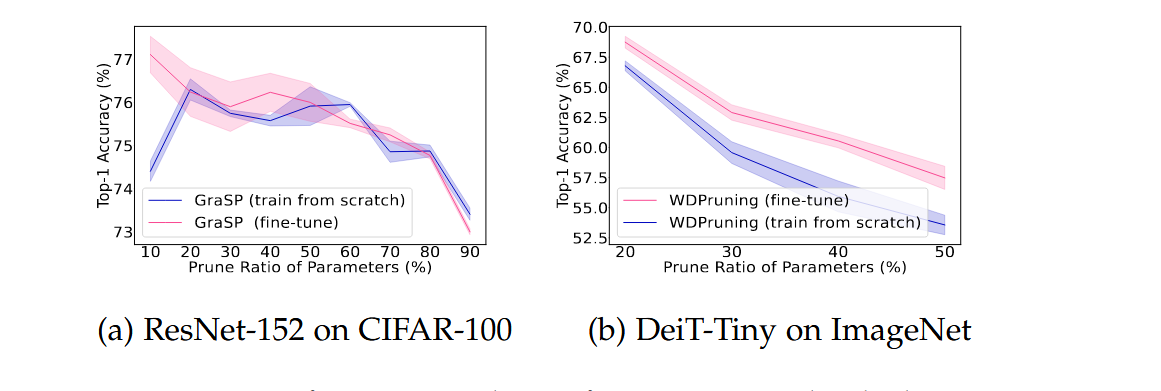
| 모델 | 데이터셋 | 결과 요약 |
|---|---|---|
| ResNet-152 | CIFAR-100 | fine-tuning > scratch |
| DeiT-Tiny | ImageNet | fine-tuning ≫ scratch (현저한 차이) |
🧾 결론
- 대부분의 경우 fine-tuning이 안정적이고 정확도 높음
- scratch는 학습 비용 크고 성능 불안정
- weight rewinding은 최근 각광받는 중간 절충 방법
✅ 7.7 Original Task vs. Transfer Pruning
🔹 요약
-
Original Task Pruning:
가지치기를 그대로 타깃 태스크에서 수행하는 방식
→ ex. CIFAR-100을 위해 학습할 때 pruning도 CIFAR-100에서 수행 -
Transfer Pruning:
다른 태스크/아키텍처에서 pruning 후, 그 결과를 타깃 태스크에 전이(Transfer)
→ 두 가지로 구분됨:- Dataset Transfer: 소스 데이터셋에서 pruning 후, 타깃 데이터셋으로 전이
- Architecture Transfer: 한 모델 구조에서 pruning한 후, 다른 구조로 전이
📚 대표 연구 및 주요 결과
📌 Dataset Transfer
-
S. Morcos et al. [120]:
- ImageNet, Places365와 같은 대규모 데이터셋에서 생성된 winning ticket은
소규모 데이터셋(CIFAR-10, CIFAR-100)에서도 더 잘 transfer됨을 발견 - 즉, 데이터셋의 크기와 클래스 수가 많을수록 winning ticket의 일반화 능력 향상
- ImageNet, Places365와 같은 대규모 데이터셋에서 생성된 winning ticket은
-
Iofinova et al. [198]:
- ImageNet에서 Top-1 정확도가 비슷한 pruning 기법들도
transfer 학습에서는 정확도에 큰 차이를 보임
- ImageNet에서 Top-1 정확도가 비슷한 pruning 기법들도
📌 LLMs에서의 적용
- LLM에서는 Zero-shot transfer pruning보다
직접 해당 task에서 pruning하는 것이 성능이 더 좋음 ([164])
🔁 Architecture Transfer
- Elastic Ticket Transformations (ETTs) [199]:
- ResNet에서 생성한 winning ticket을 더 깊거나 얕은 구조로 유연하게 변환
- ex) ResNet-18의 ticket을 ResNet-34에 적용
✅ 핵심 인사이트
-
Transfer Pruning은
- 사전 학습된 대규모 태스크에서 효과적인 서브네트워크 구조를 찾고,
- 이를 더 빠르고 정확하게 타깃 태스크에 적용할 수 있음
-
하지만, transfer 효과는 pruning 방법, 데이터셋, 구조에 따라 달라질 수 있음
→ 항상 transfer가 좋은 결과를 보장하진 않음
✅ 7.8 Static vs. Dynamic Pruning
🔹 개념 비교
| 구분 | Static Pruning | Dynamic Pruning |
|---|---|---|
| 기준 | 고정된 기준 (Static criteria) | 입력 데이터 기반 동적 기준 (Input-specific) |
| 구조 변화 | 네트워크 구조 자체를 축소 | 전체 네트워크 구조는 유지 |
| 프루닝 방식 | 불필요한 weight, filter 등을 제거 | 덜 중요한 부분은 실행 시점에 건너뜀 |
| 재학습 여부 | 일반적으로 재학습 또는 미세조정 필요 | Run-time 미세조정 없음 |
| 속도 향상 | 압축 + 추론 속도 향상 | 추론 단계에서만 속도 향상 |
| 유연성 | 고정된 구조 → 유연성 낮음 | 입력마다 유연한 구조 적용 가능 |
| 적용 예 | 대부분의 pruning 논문에서 사용 ([14]) | CGNet, FBS, RNR 등 ([64], [148], [149], [200]) |
🧩 주요 차이점
-
Static Pruning (정적 가지치기)
- 학습 전에 가지치기 기준을 정해 네트워크 구성 요소를 제거
- 모델을 실제로 더 작고 가볍게 만듬
- 일반적으로 pruning 후 다시 학습(fine-tuning)을 수행
-
Dynamic Pruning (동적 가지치기)
- 입력(input)에 따라, 실행 시점에 중요하지 않은 구성요소는 생략
- 전체 네트워크 구조는 그대로 유지
- 네트워크는 모든 구성요소를 가지지만, 일부는 실행 시 사용되지 않음
- 연산 최적화에 적합 (예: 이미지에서 복잡한 부분만 고해상도로 처리)
✅ 요약 정리

- Static Pruning: 구조 자체를 줄이며, 추론 속도와 모델 크기 모두 개선
- Dynamic Pruning: 구조는 유지하되, 입력에 따라 연산을 줄여 효율적 추론을 가능하게 함
- Dynamic 방식은 특히 입력 다양성이 높은 실제 환경에서 유용함
✅ 7.9 Layer-wise Weight Density Analysis
🔹 핵심 개념
- Layer-wise Weight Density (레이어별 가중치 밀도):
- 각 레이어에 남아있는 가중치(혹은 채널)의 비율을 의미함.
- 네트워크의 구조적 특성과 가지치기 기법에 따라 각 레이어의 밀도 분포는 크게 달라짐.
🔸 Ambient Layer vs. Critical Layer ([202])
| 구분 | 설명 | 가지치기 전략 |
|---|---|---|
| Ambient Layer | 가중치 변화에 민감하지 않음 | 과감히 가지치기 가능 |
| Critical Layer | 가중치 변화에 민감함 | 보존 필요, 밀도 높게 유지 |
🔸 가지치기 방식에 따른 밀도 분포 유형
| 방식 | 설명 | 대표 연구 |
|---|---|---|
| Uniform Sparsity | 모든 레이어에 동일한 가지치기 비율 적용 | [17], [20], [49] |
| Non-uniform Sparsity | 레이어마다 다른 비율 적용 | [146], [164], [190], [204] |
📌 예시:
- CNN에서 앞 레이어는 정보 손실에 민감 → 더 많은 weight 유지
- Transformer의 deeper layer는 덜 중요한 것으로 판단되어 더 많이 가지치기
🔸 실험 기반 관찰
-
Ma et al. [127]
- VGG 및 ResNet에서 GraSP, SNIP, LTH 적용 →
대부분 레이어별 keep-ratio(보존 비율)가 뒤로 갈수록 낮아짐 - 단, ResNet의 downsampling layer는 예외
- VGG 및 ResNet에서 GraSP, SNIP, LTH 적용 →
-
Liu et al. [62]
- 깊은 레이어일수록 더 높은 비율의 채널을 보존 (이미지 분류 기준)
-
Transformer 기반 분석:
- [201] → global magnitude pruning은 균등 분포,
global first-order pruning은 깊은 레이어를 더 많이 제거 - [60] → ViT block에서 Less-More-Less 패턴 발견
- [164] LLM Surgeon → 앞 레이어를 많이, 중간은 적게 가지치기
- [201] → global magnitude pruning은 균등 분포,
🔸 불필요한 레이어 제거 가능성
- 일부 연구들 ([65], [133], [205], [206])은
불필요하거나 중복된 레이어는 완전히 제거하거나 병합할 수 있음을 주장함
✅ 요약
- 레이어마다 중요도와 민감도가 다르기 때문에, 레이어 특성에 따라 다르게 가지치기하는 것이 효과적
- 단순히 동일한 비율로 가지치기하는 것보다, 비균일 sparsity 할당이 더 높은 성능을 유도할 수 있음
7.10 Pruning with Different Levels of Supervision
신경망 가지치기(Pruning)는 사용되는 감독 수준(supervision level)에 따라 다음과 같이 분류됩니다:
1. Supervised Pruning (지도 가지치기)
- 📌 라벨이 완전한 데이터셋에서 가지치기를 수행.
- 대부분의 기존 가지치기 논문들이 해당.
- ✅ 정확도와 성능은 우수하지만, 라벨링 비용이 많이 든다는 단점이 있음.
2. Semi-supervised Pruning (반지도 가지치기)
- 일부만 라벨이 존재하는 데이터셋에서 수행.
- 라벨 부족 환경에서도 효율적인 가지치기 가능.
- 지도 학습 대비 정확도는 낮지만, 현실적 상황에 적합.
3. Self-supervised Pruning (자기지도 가지치기)
- 라벨이 없이도 스스로 표현 학습을 진행한 후 가지치기 수행.
- 학습 방식 예시:
- Contrastive Learning: SimCLR [211], MoCo [212]
- Generative 방식
- 사례:
- Chen et al. [197], Jeff Lai et al. [213]: Self-supervised pretrained 모델에 IMP(Iterative Magnitude Pruning) 적용
- Caron et al. [209]:
- 자기지도 방식에서는 winning ticket 초기화 효과가 미미하다고 관측
4. Unsupervised Pruning (비지도 가지치기)
- 📌 라벨 정보 없이 가지치기 수행
- 완전 자동화 가능하나, 일반적으로 정확도 유지가 어려움
- 예시: Pan et al. [210] - 비지도 가지치기는 성능 유지에 실패
📌 참고
- 가지치기 시 사용하는 감독 수준과 학습 감독 수준은 별개일 수 있음
- 예: Self-supervised pretrained model + Supervised Pruning 방식 가능
8. Pruning과 기타 압축 기법의 융합 (Fusion of Pruning and Other Compression Techniques)
Neural Network Pruning은 다음과 같은 다양한 모델 압축 기법들과 결합(fusion)되어 성능과 압축률을 향상시킬 수 있습니다:
🔹 1. Pruning + Quantization
- Quantization: 가중치 및 활성값을 저비트 정밀도로 표현하여 메모리/모델 크기를 줄이는 기법
- 융합 목적: 모델 경량화 및 속도 향상
- 주요 사례:
- Han et al. [13]: pruning + quantization 동시 적용
- CLIP-Q [215]: fine-tuning 과정에서 pruning과 quantization을 동시에 수행
- MPTs [113]: Full-precision 모델에 pruning + quantization 적용해 binary 모델 생성
- Early-Bird [141]: EB ticket 탐색 시 8-bit low precision 학습 적용
🔹 2. Pruning + Tensor Decomposition
- Tensor Decomposition: weight tensor를 저차원 텐서들의 곱으로 분해하여 파라미터 수를 줄이는 기법
- 특징: 차원을 유지하면서도 저랭크 구조를 학습
- 주요 사례:
- CC [158]: channel pruning + low-rank decomposition 융합
- Hinge [216]: filter pruning + decomposition을 group sparsity로 통합
- LoSparse [217]: Transformer에서 pruning + low-rank 압축 적용
🔹 3. Pruning + NAS (Neural Architecture Search)
- NAS: 문제에 적합한 네트워크 아키텍처(depth, width 등)를 자동 탐색
- 융합 목적: pruning과 NAS를 결합하여 최적의 구조 자동 설계
- 주요 사례:
- NPAS [68]: CNN에서 컴파일러 최적화 고려해 filter type, pruning 방식, prune rate 동시 탐색
- TAS [218]: NAS로 depth/width 탐색 + KD로 학습
- Klein et al. [219]: fine-tuned Transformer에 NAS 기반 structured pruning 적용
🔹 4. Pruning + Knowledge Distillation (KD)
- KD: 교사 모델의 지식을 학생 모델에 전이
- 융합 목적: pruning 후 손실된 성능을 KD를 통해 보완
- 적용 방식:
- Prune → KD:
- Liu et al. [220]: 중요 채널만 남겨 관심 영역(distillation region)에 집중
- Park and No [221]: 교사 모델을 먼저 pruning → 전이 용이성 향상
- KD → Pruned 모델 학습:
- FLAP [146], Zou et al. [225] 등: pruned 모델을 teacher와 KD로 학습하여 성능 회복
- AntGMM [226]: structured pruning + KD로 멀티모달 모델 압축
- Prune → KD:
🔹 5. Pruning + 복합 압축 기법 (Multi-compression Techniques)
- 여러 기법을 동시에 융합해 모델 압축 극대화
- 주요 사례:
- GS [229]: pruning + quantization + KD → GAN 압축
- Joint-DetNAS [228]: pruning + NAS + KD → 이미지 변환용 네트워크 압축
- LadaBERT [227]: pruning + matrix factorization + KD → BERT 압축
📌 결론
- 융합 방식은 pruning 단독보다 성능 보존 및 경량화 측면에서 상호 보완적 이점을 제공
- 특히 LLM, CNN, Transformer 등의 대규모 모델 경량화에 핵심적인 전략으로 주목받고 있음
📌 9. 가지치기 기법 선택 및 미래 방향 (Suggestions and Future Directions)
🔹 9.1 가지치기 방법 선택 가이드 (Recommendations on Pruning Method Selection)
현재까지 다양한 pruning 기법이 제안되었지만, "최고의 단일 기준"은 존재하지 않습니다.
하드웨어/소프트웨어 자원, 태스크 특성, 메모리 상황 등을 고려해 적절한 가지치기 기법을 선택해야 합니다.
✅ (1) 하드웨어 및 소프트웨어 자원 없는 경우
- 조건: 특수 하드웨어(FPGA, ASIC)나 sparse 연산 최적화 소프트웨어가 없는 경우
- 추천:
→ Structured pruning
→ 대부분의 프레임워크/하드웨어는 sparse matrix 연산을 가속하지 못함
✅ (2) pruning 단계에서 계산 자원이 충분한 경우
-
조건: pruning 단계에서 계산 자원이 충분함
-
추천:
→ Iterative PAT 방식
→ 성능 저하를 최소화 가능 -
반대 조건: pruning/추론 단계에서 모두 자원이 제한됨
→ One-shot PBT 또는 Post-training Pruning 추천
→ 특히 LLM에서 효과적
✅ (3) 레이블 수에 따른 선택
- 레이블 충분:
→ Supervised pruning 추천 - 레이블 일부만 존재:
→ Semi-supervised 또는 Transfer pruning 고려 - 레이블 없음:
→ Self-supervised, Unsupervised, 또는 Transfer pruning
✅ (4) NLP 모델의 메모리 자원 충분한 경우
- 조건: pruning 단계에서 메모리 여유 있음
- 전략: 작은 모델을 경량화하기보단
→ 큰 모델을 더 강하게 압축하는 것이 더 성능이 좋음 ([230])
✅ (5) 추론 시 flexible한 계산 자원 할당 필요 시
- 조건: 추론 시 입력 크기에 따라 유동적으로 자원 조절 필요
- 추천:
→ Dynamic Pruning
→ 입력 크기가 작을수록 연산량 줄이고, 클수록 연산량 확장
✅ (6) 다차원 가지치기 필요 시
- 고려 요소:
- Layer-wise pruning → 모델 depth 감소
- Channel pruning → 모델 width 축소
- Image resolution pruning → 입력 해상도 축소
- Token pruning → 텍스트 토큰 제거
- 통합 전략: pruning + quantization 병행 시 더욱 메모리 절약 가능
✅ (7) 정확도 ↔ 속도 trade-off 최적화
- 추천 세팅:
- Pre-trained 모델 사용
- pruning/재학습 단계 모두 적절한 learning rate 설정
- pruning 후 몇 에폭 fine-tuning
- KD, NAS, Quantization 등과 병합
- Adversarial training 추가 시 성능 향상 가능 ([122])
✅ (8) Subnetwork 성능 복구 위한 학습 전략
- ResNet 등 residual connection 있음:
→ 작은 learning rate → 정확도 높음 - Residual 없음:
→ 큰 learning rate 사용 → 더 좋은 성능 ([127])
✅ (9) 대규모 pre-training 활용 시 전략
- 결론: FLOPs 감소보다 파라미터 수 증가가 더 중요 ([231])
- 기법 예시:
- Dynamic convolution [232] 활용
- FLOPs 증가 없이 capacity 향상 → 성능 ↑
9.2 Future Directions
신경망 가지치기(Pruning)는 지속적으로 발전 중이며, 다음 4가지 주요 방향에서의 확장이 기대된다:
🔸 (1) 이론 (Theories)
-
가지치기의 이론적 한계에 대한 연구가 미흡:
- 특정 모델 구조에 대해 성능 손실 없이 가능한 최대 프루닝 비율은 존재하는가?
- 레이어 간 상호작용이 복잡하여 이론적으로 분석이 어렵다.
-
가지치기의 해석 가능성도 큰 과제:
- 왜 특정 weight나 구조가 가지치기되는가에 대한 설명 가능한 알고리즘이 필요
- 모델 구조/가중치와 성능의 관계를 이해하고 해석할 수 있는 도구가 요구됨
🔸 (2) 기법 (Techniques)
-
AutoML, NAS 기반 가지치기 기법 확장
- 구조를 자동으로 최적화하는 효율적인 프루닝 알고리즘 개발
-
다양한 학습 문맥과 통합 시도:
- Life-long Learning ([223])
- Continual Learning ([233])
- Contrastive Learning ([234])
- Federated Learning ([235])
-
에너지 인지형 프루닝(Energy-aware Pruning) 중요성 증가:
- 단순 연산량(FLOPs) 감소가 아니라, 실제 에너지 소비 최적화가 핵심
- FPGA 등 하드웨어 친화적 프루닝 연구도 증가 중
예: Sui et al. [236] - FPGA에 배포 가능한 프루닝 기법 제안
🔸 (3) 응용 (Applications)
-
이미지 분류를 넘어 다음 영역으로 가지치기 확대:
- 시각 질문 응답 (VQA)
- 자연어 이해 (NLU)
- 음성 인식
- 콘텐츠 생성
-
거대 기반 모델 (Foundation Models) 적용 필요성 증가:
- GPT-4, LLaMA 등은 너무 커서 실전 배포가 어려움
- 프루닝 기법으로 이들을 경량화하여 실용화 가능성 확보
🔸 (4) 평가 (Evaluation)
-
가지치기 기법이 많아지면서 표준화된 평가 지표와 벤치마크 필요
- 모델 구조, 태스크, 실험 환경이 다르면 결과 비교 불가
- 공정한 비교를 위한 통합 기준 마련이 필수
-
ShrinkBench ([42]):
- 이미지 분류 기준의 초기 벤치마크로 활용 가능
-
앞으로는 다른 태스크들 (예: NLP, 음성) 전용 벤치마크도 마련되어야 함

GPT를 활용한 정리 감사합니다. 제 토큰 아껴주셔서 감사합니다.
🌾 천고마비의 계절처럼 마음은 넓게, 열정은 높게!
건강 지키며 행복 가득한 나날 보내고,
모든 일이 번창하길! 오늘도 화이팅! 💪