Introduction
Semantic Segmentation
- 의미론적 세분화는 컴퓨터 비전에서 핵심 과제로, 이미지의 각 픽셀을 특정 범주로 분류하는 작업
- 이는 이미지 수준의 예측을 수행하는 이미지 분류(Image Classification)와 유사하지만, 픽셀 단위의 예측을 요구한다.
ViT의 한계
- ViT(Vision Transformer)는 이미지 분류에서 인상적인 성능을 보여주었지만, 단일 스케일 저해상도 특징 출력과 높은 계산 비용이라는 한계가 있습니다.
SegFormer의 등장
- SegFormer : 효율성, 정확성 및 강건성을 동시에 고려하는 새로운 의미론적 세분화 프레임워크
- 기존 모델이 인코더 설계에 집중한 것과 달리, SegFormer는 인코더와 디코더를 모두 새롭게 설계
Related Work
1. 의미론적 세분화(Semantic Segmentation)
- 이미지 분류를 픽셀 수준으로 확장한 작업이며 FCN이 기초연구로 픽셀 단위로 엔드 투엔드 학습을 수행하였다.
- FCN의 발전을 위해 다양한 기술들이 나왔찌만 현재는 트랜스포머 기반 모델이 더욱 효율적임이 입증이 되었다.
2. 트랜스포머 백본 (Transformer Backbones)
- ViT (Vision Transformer)는 트랜스포머만으로도 이미지 분류에서 최고 성능(SOTA)을 달성한 최초의 연구이다.
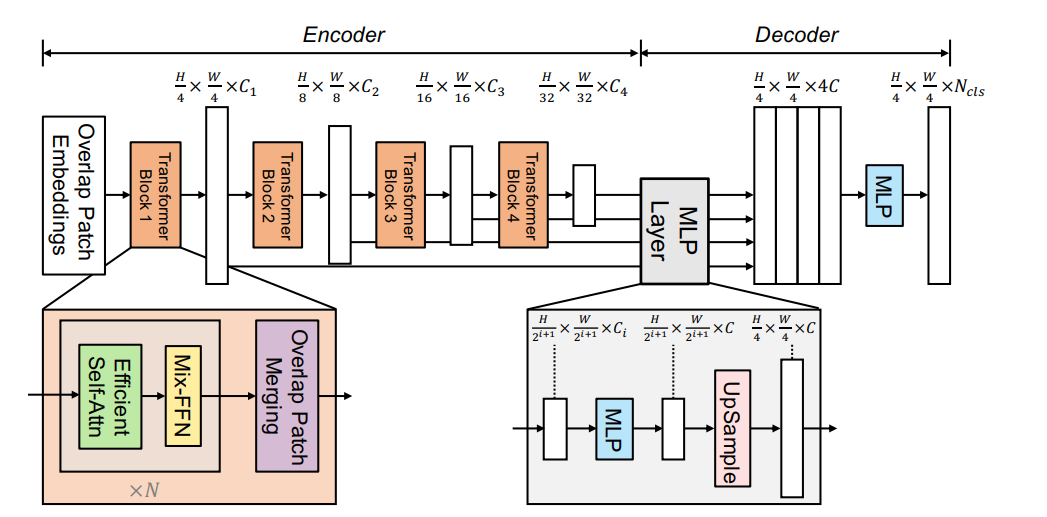
Method
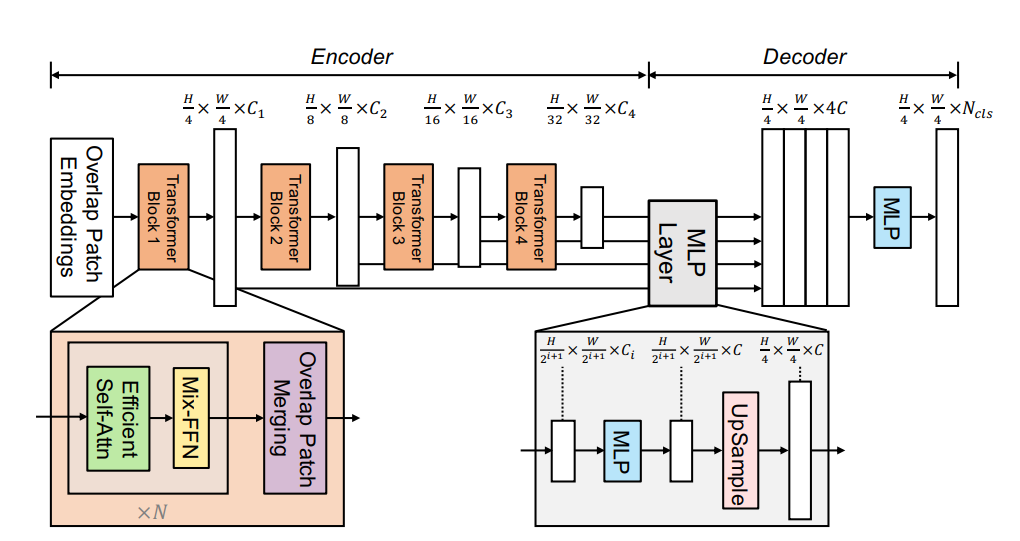
SegFormer는 두가지 주요 모듈로 구성된다.
1. 계층적 트랜스포머 인코더(Hierarchical Transformer Encoder)
- 고해상도의 거친(coarse) 특징과 저해상도의 정밀한(fine) 특징을 생성한다.
2. 경량의 MLP 디코더(All-MLP Decoder)
- 여러 수준의 특징을 결합하여 최종 의미론적 세분화 마스크를 생성한다.
전체 흐름
1. 입력 이미지(크기:H×W×3)
- 이미지를 4X4크기의 패치로 나눈다. 이와 같은 작은 패치를 사용하면 Dense prediction작업에 유리하다.
2. 계층적 트랜스포머 인코더
- 패치를 인코더에 입력해, 원본 해상도의 1/4, 1/8, 1/16, 1/32 수준에서 다중 수준 특징을 추출
3. MLP 디코더
- 인코더에서 추출한 다중 수준 특징을 사용해 H/4 x W/4 X Ncls 해상도로 세분화 마스크를 생성
3.1 Hierarchical Transformer Encoder
SegFormer이란?
SegFormer는 Mix Transformer 인코더(MiT)라는 인코더 시리즈(MiT-B0 ~ MiT-B5)를 설계하였다. SegFomer은 이를 통해 CNN과 유사하게 계층적 다중 수준 특징을 생성한다.
- MiT-B0는 빠른 추론을 위한 경량 모델
- MiT-B5는 최고의 성능을 목표로 한 대규모 모델
- 이 인코더는 ViT에서 영감을 받았지만, 의미론적 세분화에 맞게 설계 및 최적화된 구조이다
SegFormer의 동작 방식
- 입력 이미지 : H x W x 3
- 패치 병합을 수행해 계층적 특징 맵 Fi를 생성
- 특징 맵 해상도 :
입력 이미지 해상도는 각 단계에서 절반으로 축소된다. 네트워크의 깊이가 깊어질수록 특징 맵의 채널수 Ci는 커진다. 저해상도에서 더 많은 채널을 통해 복잡한 특징을 인코딩한다.
Overlapped Patch Merging
- Overlapped Patch Merging : 패치들이 서로 겹치도록 병합하는 방식으로 이는 패치 간의 경계에서 정보 손실을 방지하고 더 부드러운 특징 맵을 생성하기 위해 사용된다.
- 기존 VIT는 이미지를 N x N x 3 크기의 패치로 나누고 각 패치를 독립적으로 처리하였다. 이러한 방식은 패치 사이에 정보가 단절되어 객체의 경계가 끊어질 가능성이 있다.
- 주요 매개 변수
K : 패치크기(Kernel Size)
S : 패치간의 간격(Stride)
P : 경계를 벗어난 부분(Padding)- Overlapped Patch Merging 방식은 패치 경계에서 정보를 보존해 더 정확하고 자연스러운 특징 추출이 가능하다 . SegFormer는 이를 통해 트랜스포머 기반 모델의 의미론적 세분화 성능을 한 단계 높인다.
stage 1: (K=7 , S=4 ,P=3)
stage 2,3,4(K=3, S=2 ,P=1)
+초기 단계에서는 넓은 문맥 정보가 필요하므로 큰 커널을 사용하고,
후반 단계에서는 세밀한 특징을 잡아내기 위해 작은 커널을 사용한다.Efficient Self-Attention
- 인코더의 주요 계산 병목 현상은 Self-Attention에서 발생한다.
이미지 해상도가 커질수록 계산 비용이 기하급수적으로 증가해 비효율적이다.- 기존에는 self-attention시에 모든 픽셀끼리 서로 연관성을 계산하여 N^2의 연산이 필요하였다.
- SequenceReduction은 N^2을 R로 나누어 연산량을 낮추고 정보 손실을 막기위해 채널수를 R x C로 늘린다.
- SegFormer은 이미지의 해상도에 따라 R을 64,16,4,1로 나눈다.
- 선형 변환을 통한 차원 복구 : 축소된 차원 K'는 선형변환을 거쳐 다시 원래 채널 수 C 로 변환된다. 이는 정보 손실을 최소화하면서 필요한 부분만 남기는 방법이다.
Mix-FFN
- 기존 문제 : VIT는 이미지의 위치 정보를 위치 인코딩(PE)를 통해 추가한다. 하지만 PE는 해상도가 고정되어있어, 학습시 해상도와 테스트시 해상도가 다를 경우 위치 인코딩을 interpolation(보강)해야한다. 이 과정에서 accurancy가 떨어지는 문제가 발생한다.
- Mix-FFN의 등장 : Mix - FFN은 3x3합성곱을 사용해 위치 정보를 직접 네트워크에 제공한다. 합성곱(Conv)는 local 특징을 학습할 수 있기 때문에 위치 인코딩 없이도 위치 정보를 자연스럽게 학습할 수 있다.
- 수식
- 결론 Mix-FFN은 위치 인코딩 없이도 트랜스포머가 위치 정보를 학습할 수 있는 방법이다. 이러한 이유는 기존의 위치 인코딩(PE)대신에 3x3 합성곱을 이용해 local특성을 학습할 수 있기때문이다.
또한 해상도가 달라져도 보간이 필요없기 때문에 정확도 저하가 발생하지 않는다.3.2 Lightweight All-MLP Decoder
SegFormer에서 사용된 All-MLP디코더의 작동방식
1단계 : 채널 차원 통일
입력 Fi : MiT(계층 트랜스포머)인코더에서 나오는 다양한 해상도의 특징 맵
의미 : 각 특징 Fi는 서로 다른 채널수 Ci를 가진다. 채널수가 다르면 병합이 불가능하므로, 선형변환을 사용해 모든 특징의 채널을 C로 통일한다.
결과F i^: C차원을 가지는 통일된 특징맵2단계 – 업샘플링 (해상도 맞추기)
입력 Fi^ : 채널이 통일된 특징맵
의미 : 업샘플링을 통해 모든 특징의 공간해상도를 동일하게 만든다. 이는 해상도 차이로 인한 문제를 해결하고 병합을 쉽게 만든다.
결과F i^: 모든 특징이 동일한 해상도를 가지게 됨3단계- 병합 및 융합 (Concatenation + Linear Layer)
입력 Fi^ : 업샘플링된 모든특징 Fi^
의미 : Fi^들은 병합되어 하나의 큰 벡터로 만들어진다. 병합된 벡터의 채널 수는 4C이고 이후 선형변환을 통해 다시 C차원으로 줄인다.
결과F i^: 병합되고, C 차원으로 변환된 단일 특징 F4단계 – 세그멘테이션 마스크 예측 (최종 MLP 레이어)
입력: 병합된 특징 F
의미: 선형 레이어를 통해 C 차원의 특징을 클래스 수 N cl로 변환한다.이는 픽셀당 클래스 확률을 의미한다.
결과: 세그멘테이션 마스크MMLP디코더를 통해 트랜스포머 인코더에서 나온 다양한 해상도 특징맵을 동일한 채널 차원으로 변환하고 특징을 업샘플링하고 MLP를 사용해 공간 정보와 채널 정보를 융합하고 세그멘테이션 마스크를 생성한다.
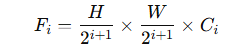
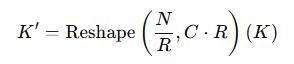
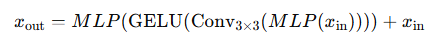

Experiments
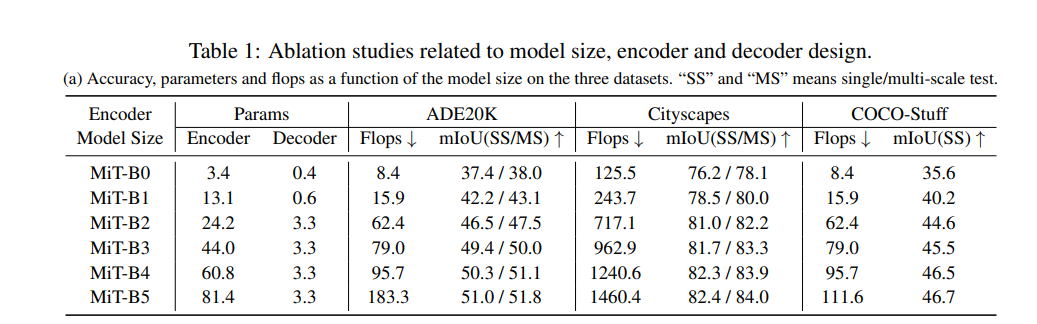
Table 1: Ablation Studies – 모델 크기, 인코더 및 디코더 설계 관련 실험 결과
(a) 모델 크기와 성능 (Model Size and Performance)
- 데이터셋: ADE20K, Cityscapes, COCO-Stuff
- 결과 : MiT-B0에서 MiT-B5로 갈수록 모델 크기(Params)와 FLOPs가 증가하지만, mIoU도 상승한다.
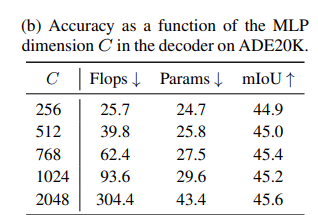
(b) MLP 디코더의 채널 크기(C)에 따른 성능 변화
- 목적: MLP 디코더의 채널 크기( C )가 ADE20K에서 성능에 미치는 영향을 분석.
- 결과 512~1024 범위에서 성능이 크게 향상되며, C=1024에서 45.2% mIoU를 기록한다.
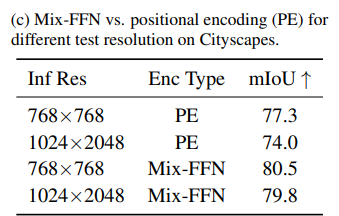
(c) Mix-FFN vs. 위치 인코딩(Positional Encoding, PE)의 비교 (해상도 변화에 따른 영향)
- 목적: Mix-FFN과 PE(Position Encoding)이 해상도 변화에 따른 성능에 미치는 영향을 평가.
- 결론: Mix-FFN은 다양한 해상도에서 위치 인코딩 없이도 위치 정보를 잘 학습하며, 해상도 변화에 덜 민감하다.
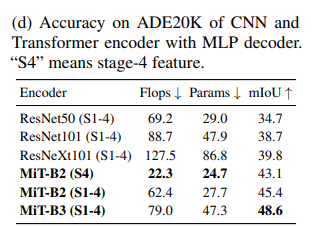
(d) CNN vs. Transformer 인코더의 비교 (ADE20K에서의 성능 차이)
- 목적: CNN 인코더(ResNet)와 트랜스포머 인코더(SegFormer MiT)의 성능 비교.
- 결과 : SegFormer는 CNN 기반 인코더보다 뛰어난 성능을 보이며, 딥러닝 기반 세그멘테이션에서 트랜스포머가 우수함을 입증한다.