들어가기에 앞서
이전시간에 다층 신경망의 활성화 함수로 다뤘던 시그모이드 함수는 2가지 문제점이 있었다. 이번 글에는 이러한 문제점을 해결하기 위한 다양한 활성화 함수들을 소개할 것이다.
시그모이드 함수의 문제점
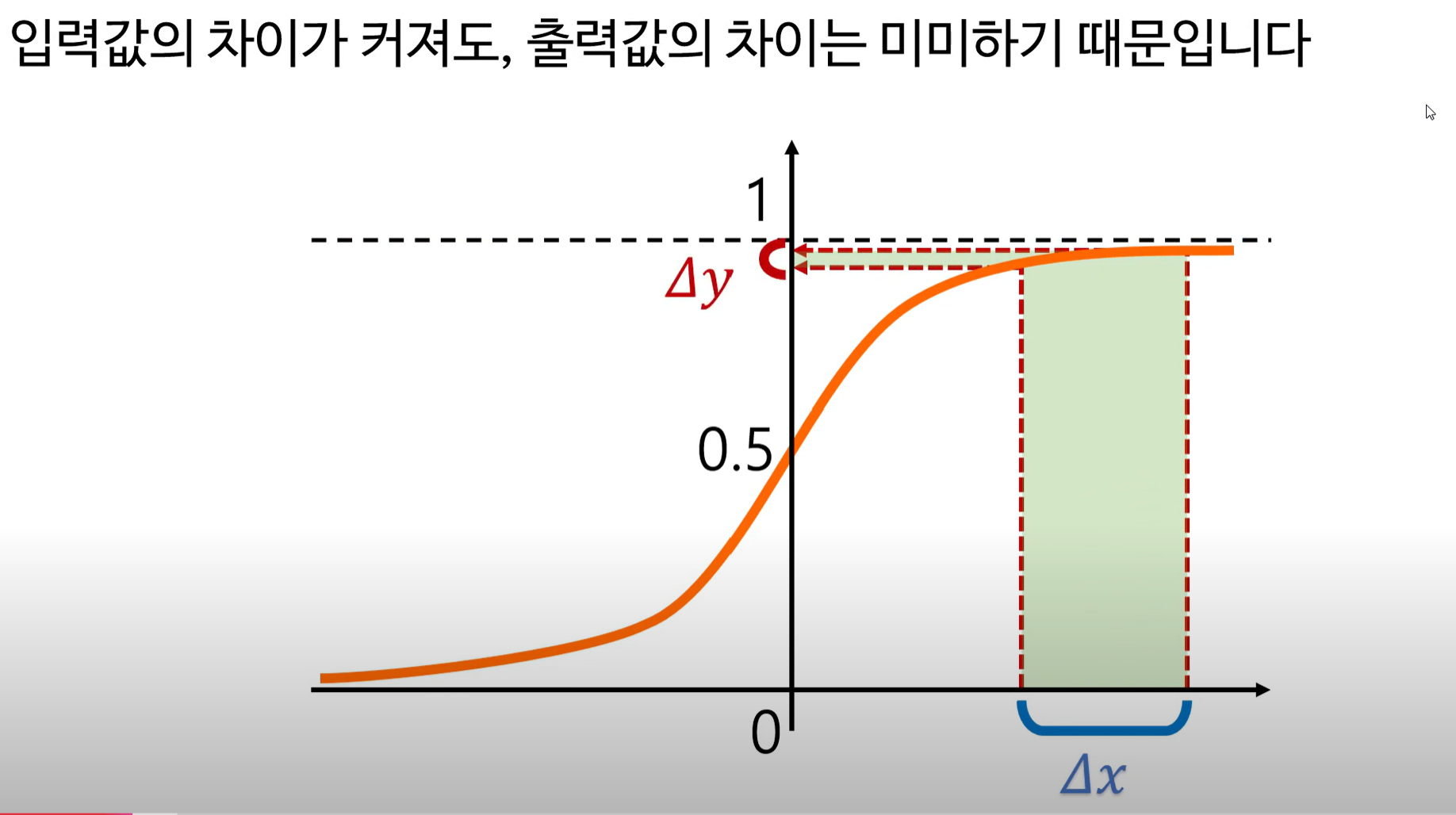
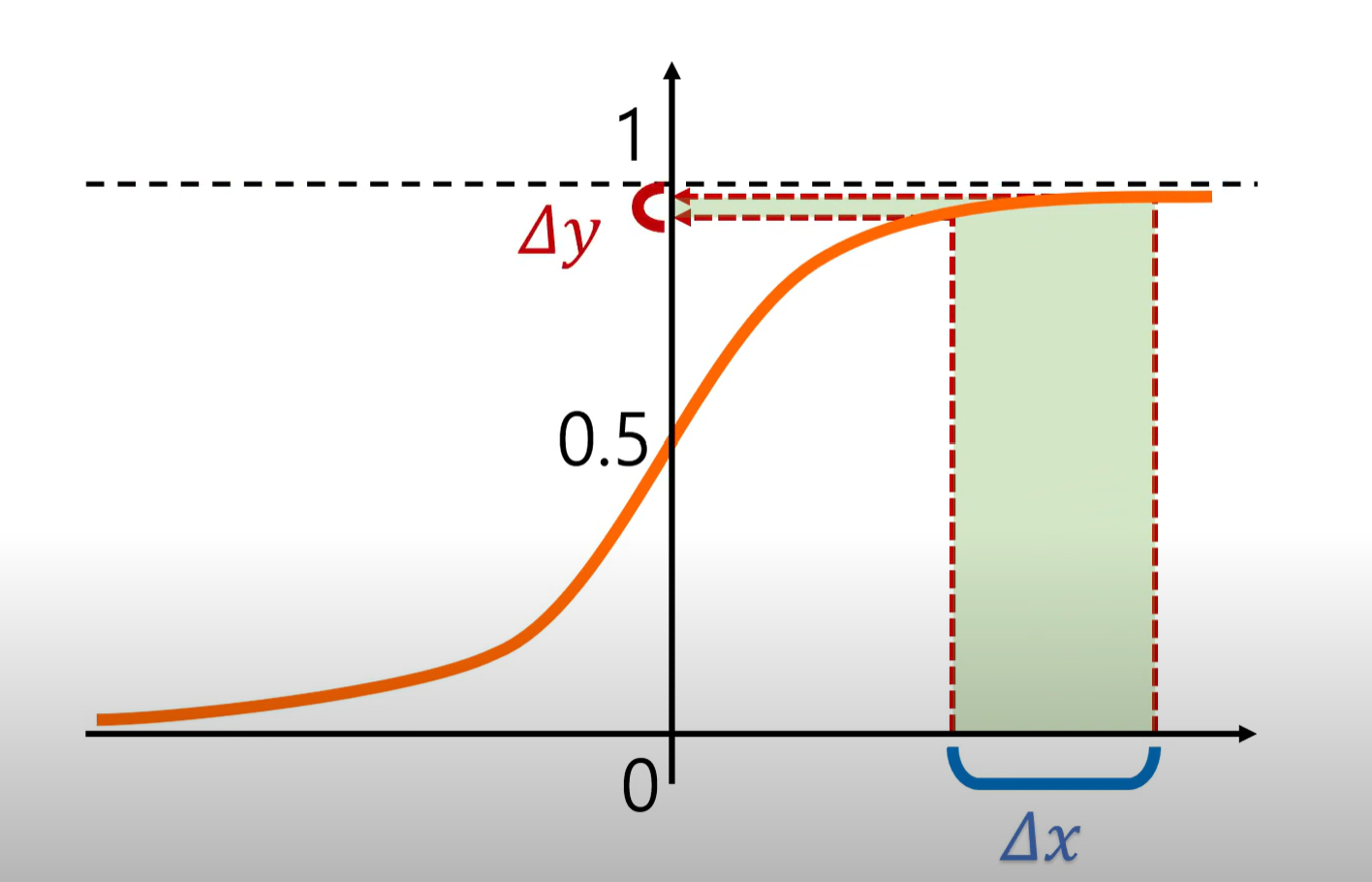
1. 기울기의 값이 0이 되는 구간이 있다.
>> 기울기의 값이 0이 되는 지점에서는 입력값의 변화가 크더라도 출력값의 변화가 작아 좋은 예측을 하기 어렵다!
다층신경망은 상위 노드의 입력값은 하위 노드의 출력값의 합이되고 시그모이드 함수를 활성화 함수로 사용할 경우 입력값은 양수이므로 상위 노드로 갈 수록 입력값이 증가하여 기울기가 0에 가까워지는 문제를 맞이하게 된다.
sigmoid saturate killing gradients 현상
신경망의 깊이가 깊어질수록 학습효과가 떨어지는 현상
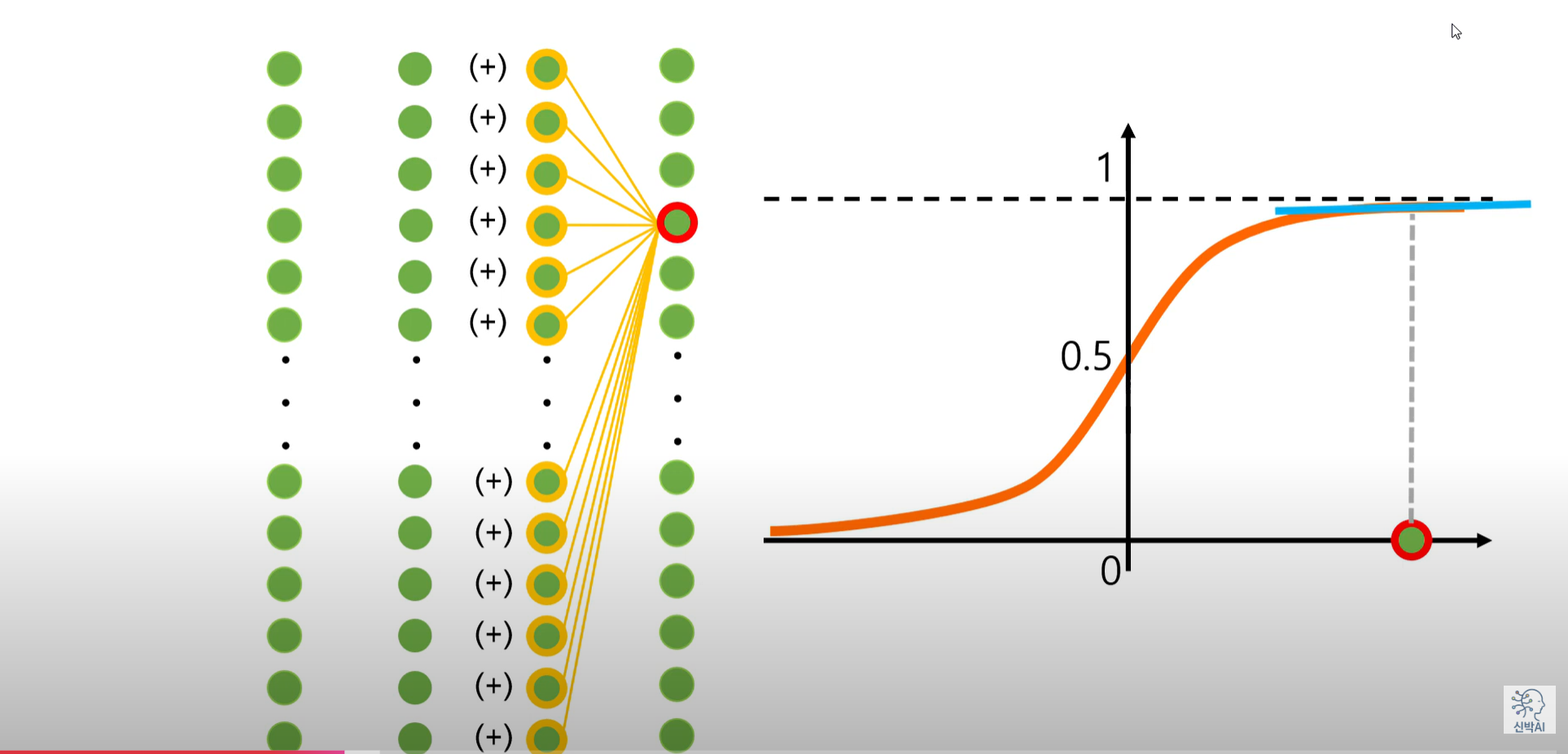
2. 시그모이드의 출력값은 항상 양수이다.
>> 연결가중치 학습과정에서 지그재그 패턴을 보이게 된다.
다층 신경망의 학습방법 :
다층 신경망은 새연결강도의 변화량에 따라 달라진다.
새 연결강도의 변화량은 현입력값 * 오차에 따라 달라지게 된다.지그재그 패턴:
다층 신경망의 오차가 양수 혹은 음수로 나오면 연결강도인 w1, w2는 오차의 부호가 동일하여 연결강도의 변화역시 같은 방향으로 변하게 된다.
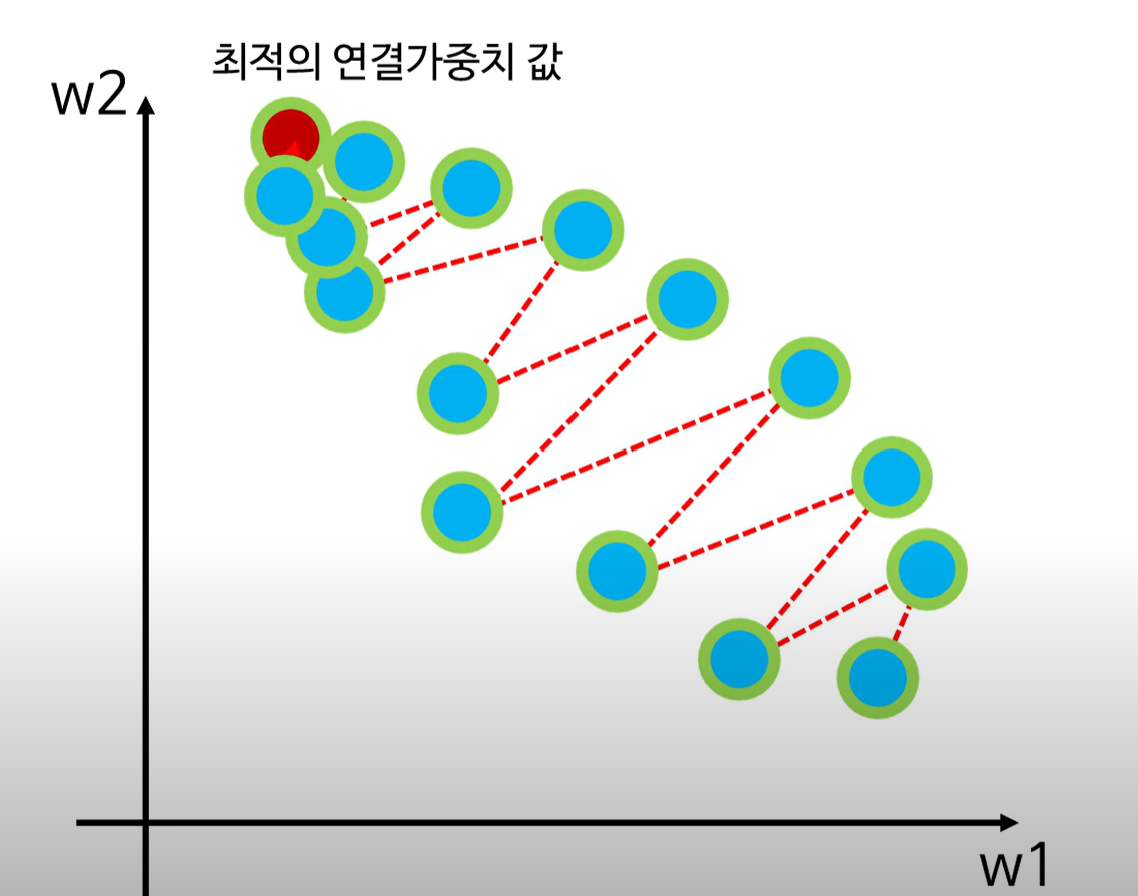
시그모이드 함수를 활성화 함수로 사용하여 최초의 연결가중치에서 학습을 통해 가중치 값을 변경시키며 최적의 연결가중치에 도달하는 과정은 밑의 그래프와 같다.
(blob:https://velog.io/b2cb7532-a46e-40d2-b726-7e38f3e03d6b)
>> 위처럼 연결가중치가 최적의 연결가중치를 찾아가는 과정에서 나타나는 형태를 지그재그 패턴이라 하며 이는 최적의 연결가중치를 찾아가는데 비효율적인 모습을 보여준다.
시그모이드 함수를 대체할 활성화 함수들
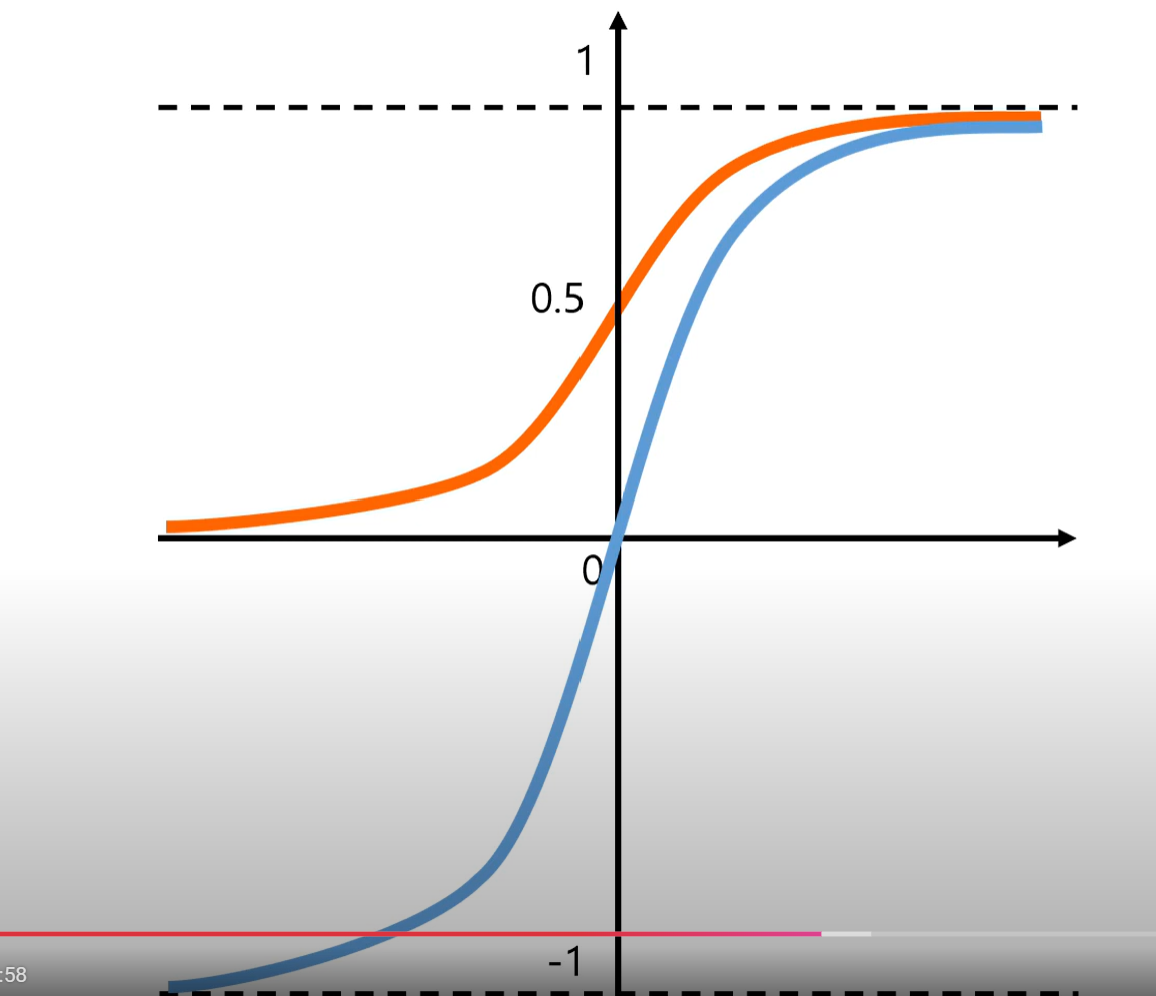
1.tanh함수
- 시그모이드 함수의 출력값이 항상 양수인 문제점을 해결
- 그러나 기울기가 0인 지점이 존재하게되는 killing gradient문제는 해결하지 못한다.
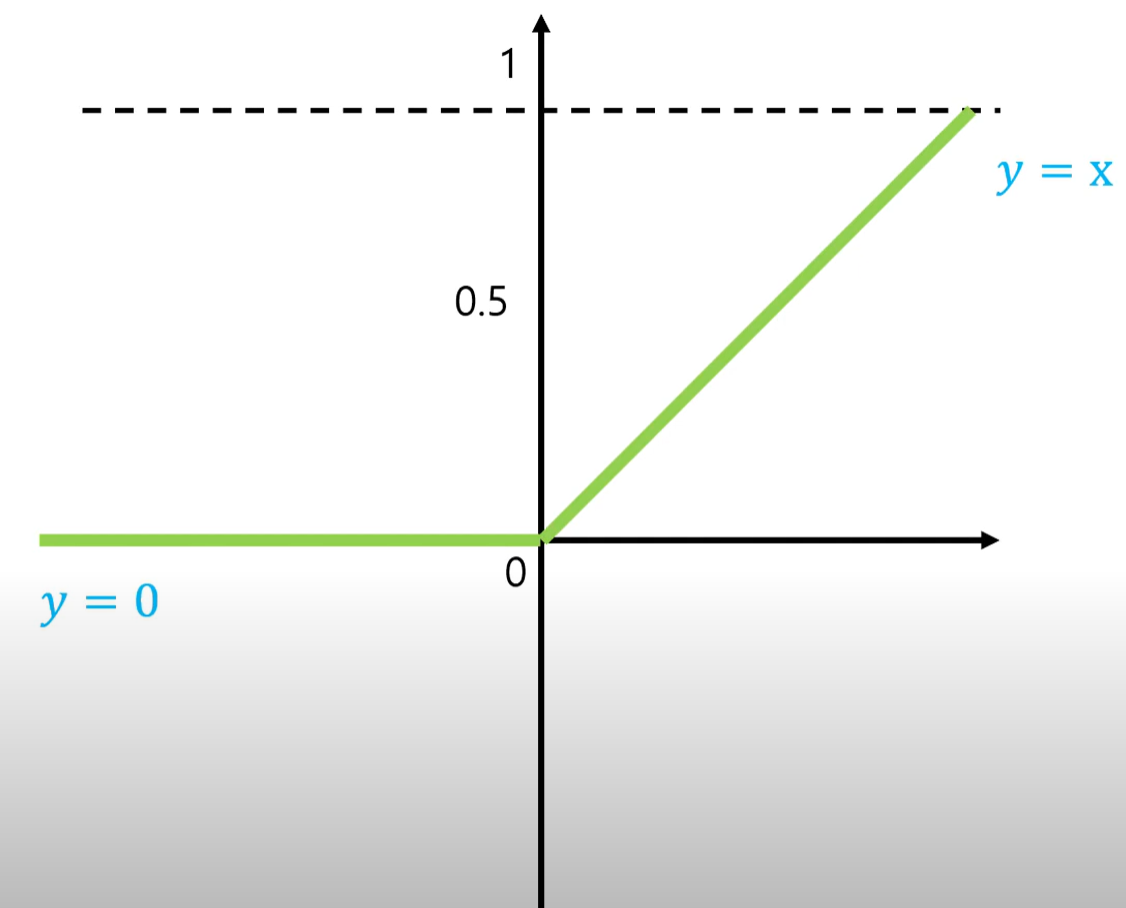
2. Relu 함수
- 입력값이 양수인 경우 기울기가 항상 1이기때문에 killing gradient 문제를 해결할 수 있어 신경망의 깊은 층까지 오류역전파를 통한 학습이 가능
- 그러나 입력값이 음수인 경우 기울기가 0이되어서 신경망의 학습이 이루어지지 않는 Dying Relu현상이 일어난다
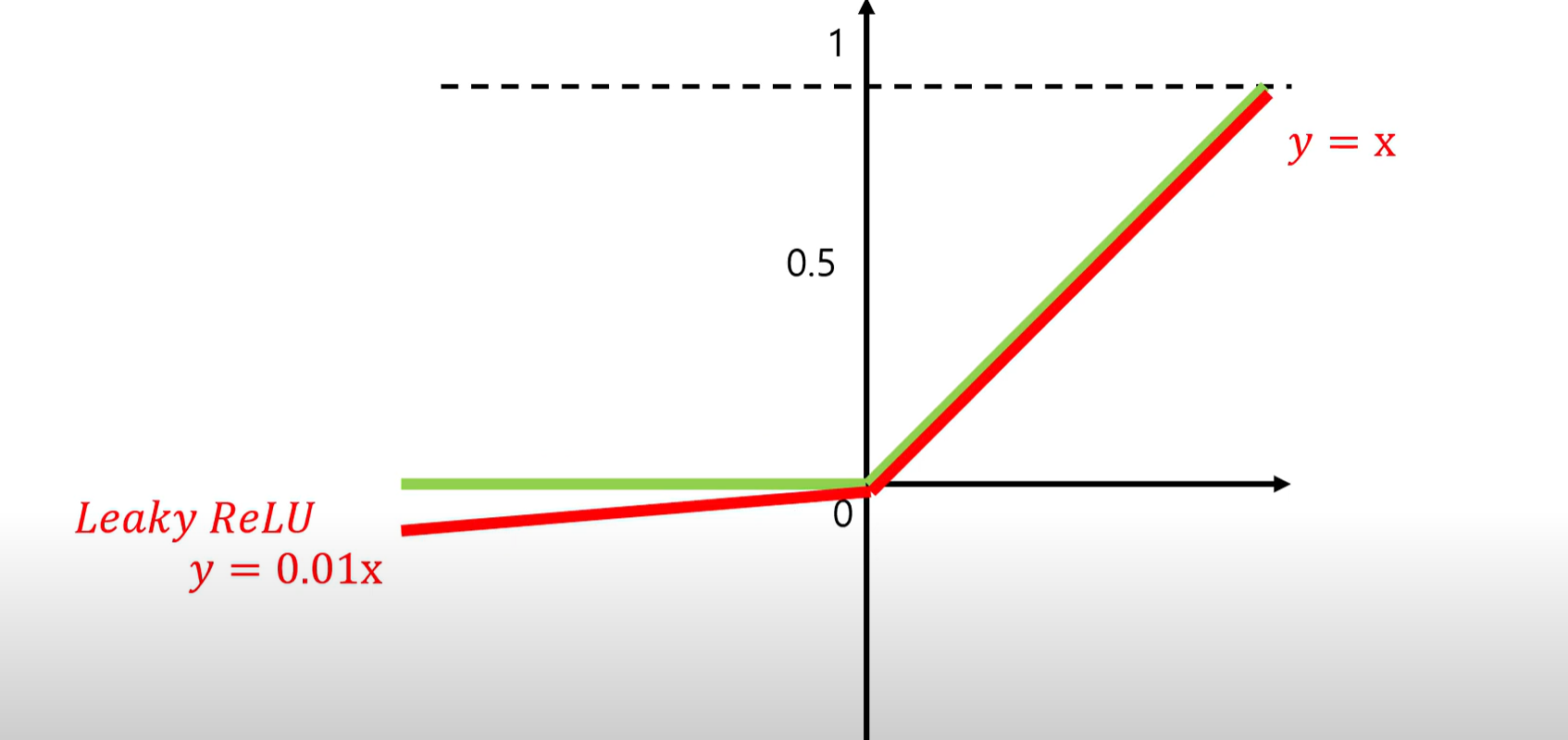
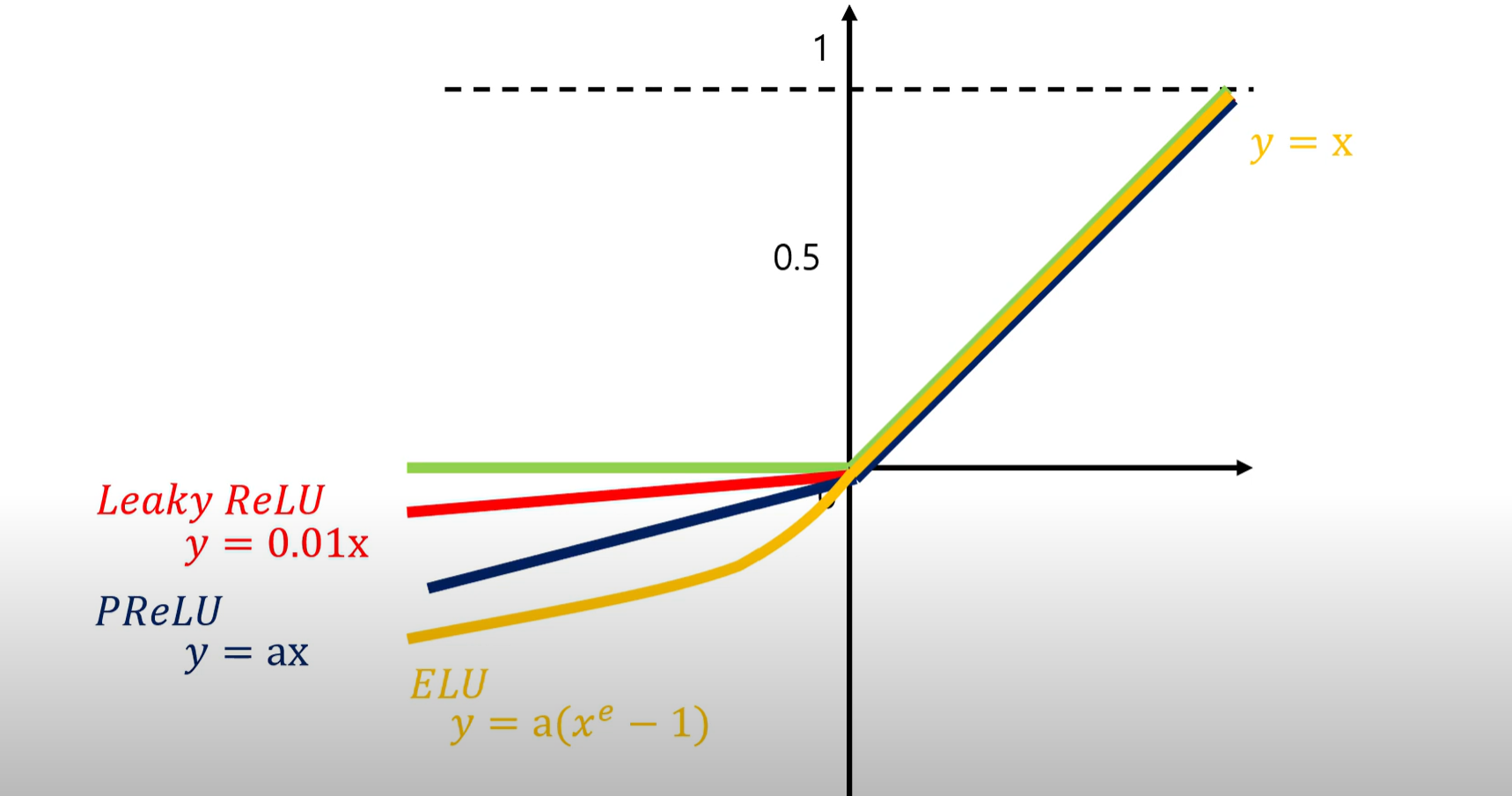
3.Leaky ReLU , PReLU ,ELU 함수
결론
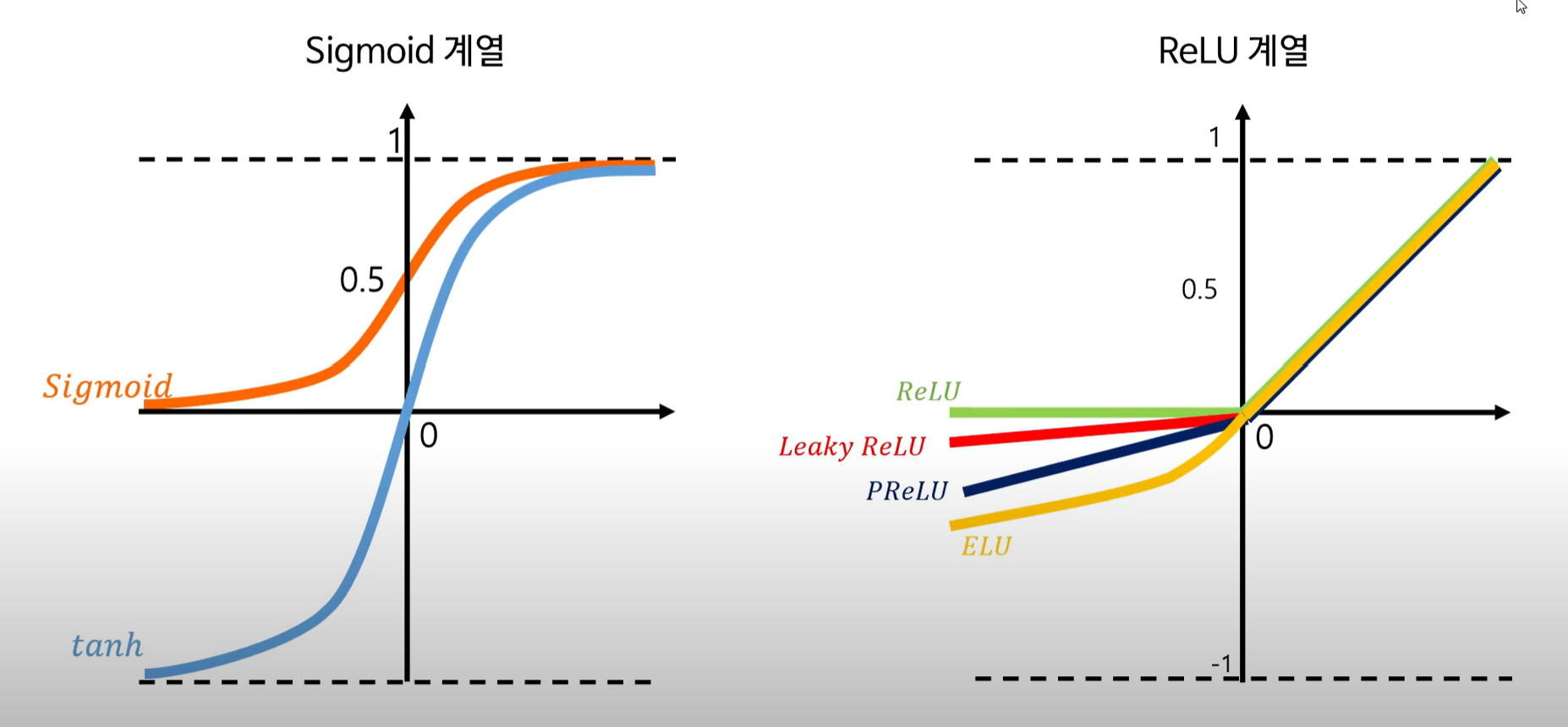
활성화 함수는 Sigmoid 계열과 ReLU계열로 나뉜다. 각각의 특성을 잘 알아서 적절한 상황에 적용하는 것이 중요하다!

이렇게 다양한 activation function들이 있는데 llm transformer나 cv transformer에서 왜 굳이 ReLU를 사용하나요?
최근에 읽으신 Leaky ReLU관련 논문이 있으실까요?