JPA
1.JPA를 왜 사용해야 하는가?
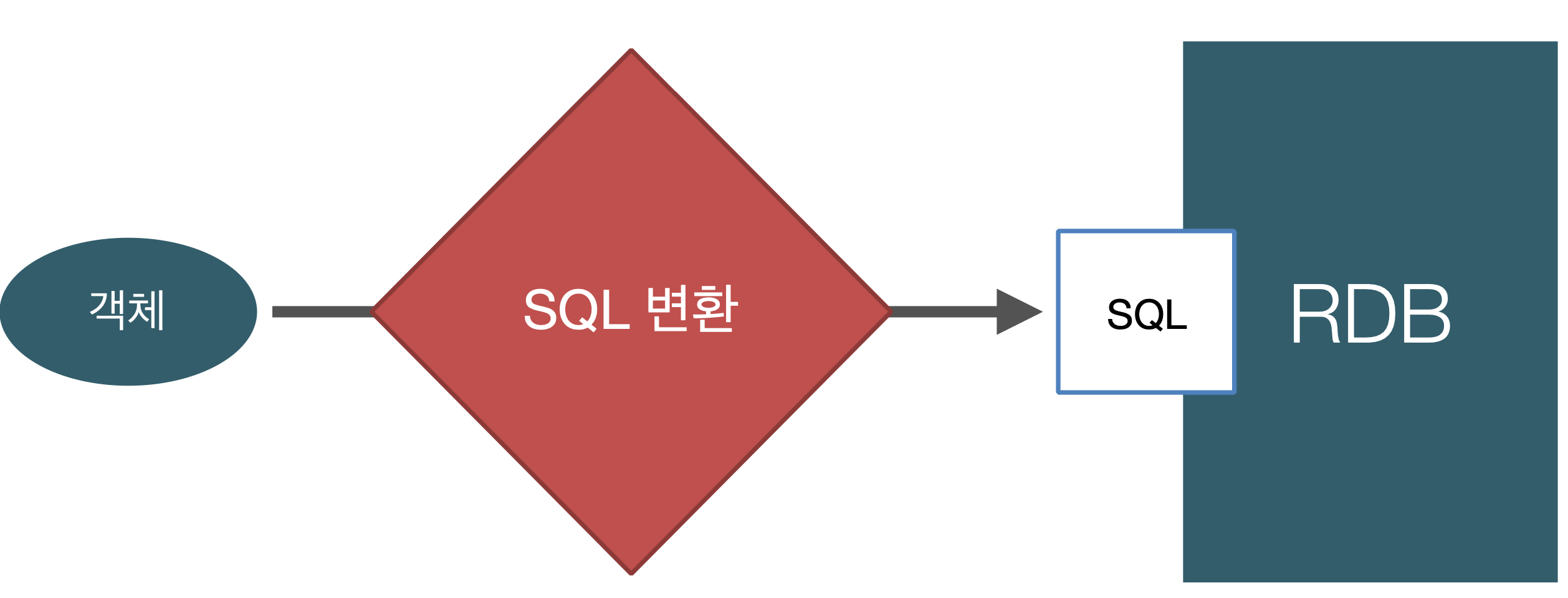
우리가 무언가를 공부하기에 앞서서 왜 공부를 해야하는지, 이게 정확히 어떤 것을 하는지를 알아야 한다.이러한 관점에서 우리는 왜 JPA를 사용해야 하는지 알아보자.현대적인 어플리케이션을 개발한다 하면 대부분은 OOP 언어를 사용한다.데이터를 저장하기 위해 관계형 데이터
2.영속성 관리
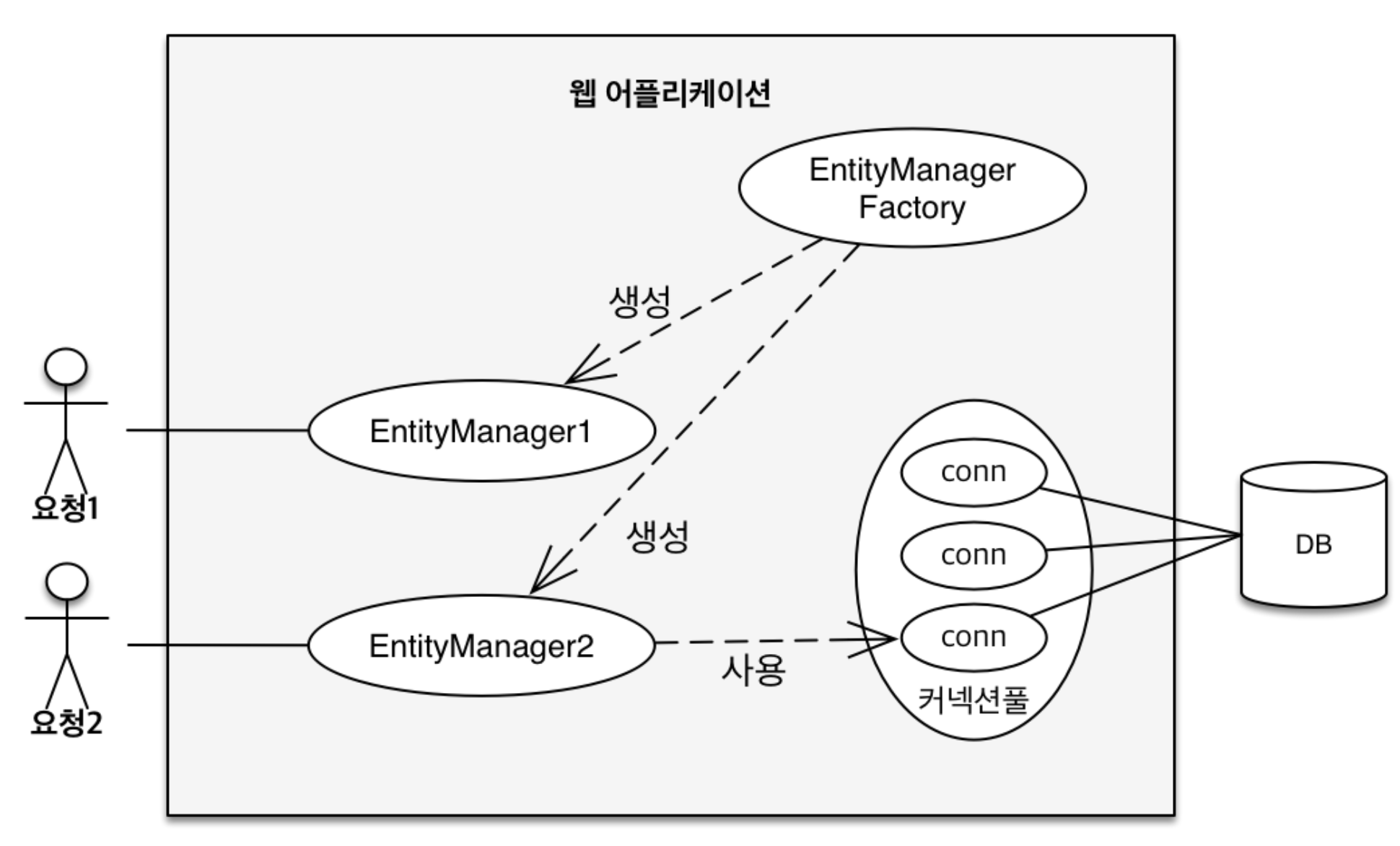
JPA에서 가장 중요한 2가지를 알아보자.객체와 관계형 데이터베이스 매핑하기(Object Relational Mapping)영속성 컨텍스트EntityManagerFactory 를 미리 생성해 놓고 고객의 요청이 올 때 마다 EntityManager 을 생성한다.Enti
3.엔티티 매핑
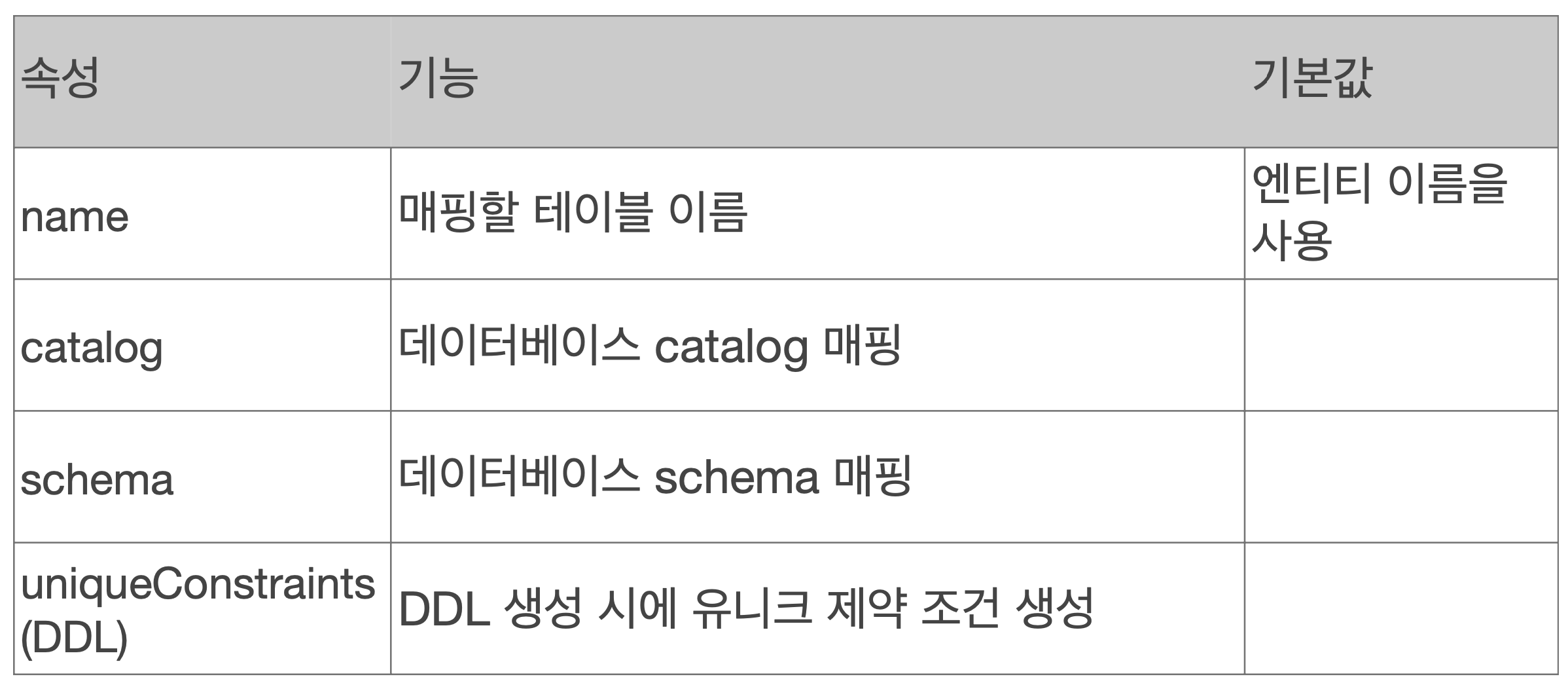
저번에도 언급했던 JPA에서 가장 중요한 2가지를 다시 알아보자.객체와 관계형 데이터베이스 매핑하기(Object Relational Mapping)영속성 컨텍스트이번에는 객체와 관계형 데이터베이스 매핑을 설계적인 측면에서 자세히 알아보자.엔티티 매핑은 크게 4가지가 있
4.연관관계 매핑 기초
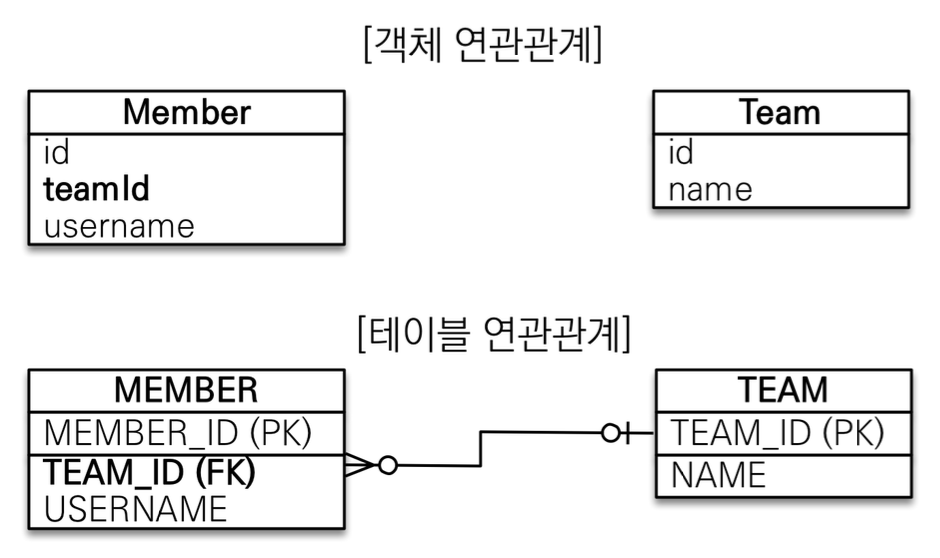
저번 시간에 했던 테이블에 맞춰서 FK키를 그대로 가져오면서 설계하는 방식에서 벗어나 연관관계를 맺어서 어떤식으로 설계하는지 (좀 더 객체지향적으로 설계하는) 알아보자.궁극적인 목표는 객체와 RDB의 패러다임 차이를 극복하는데에 있다. 이 부분이 굉장히 중요하다. 객체
5.다양한 연관관계 매핑
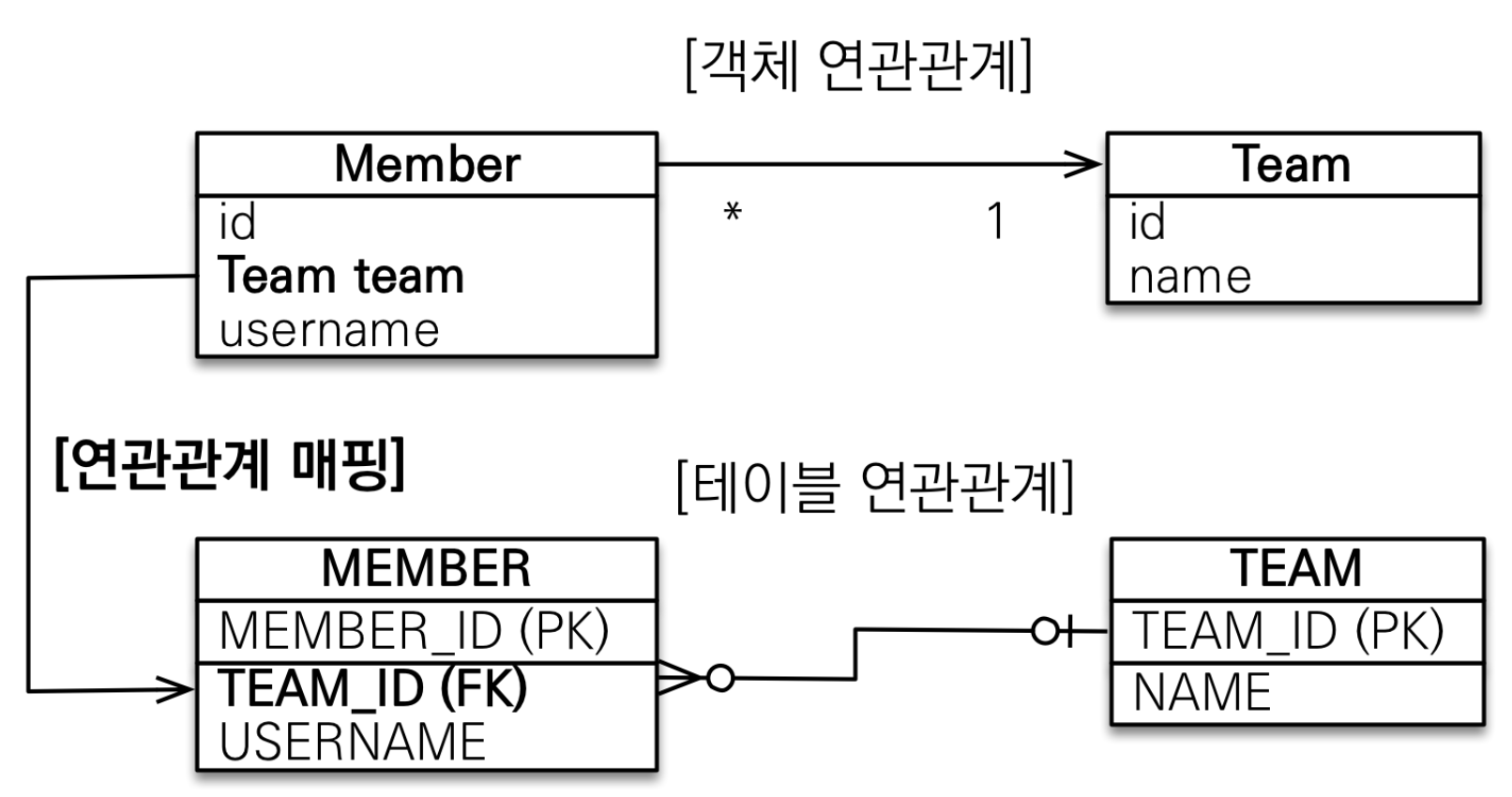
연관관계 매핑시 고려해야할 사항은 크게 3가지이다.다중성단방향, 양방향연관관계의 주인하나씩 알아보자.다중성은 4가지가 있다.다대일: @ManyToOne일대다: @OneToMany일대일: @OneToOne다대다: @ManyToManyDB의 다중성을 기준으로 어노테이션을
6.고급 매핑
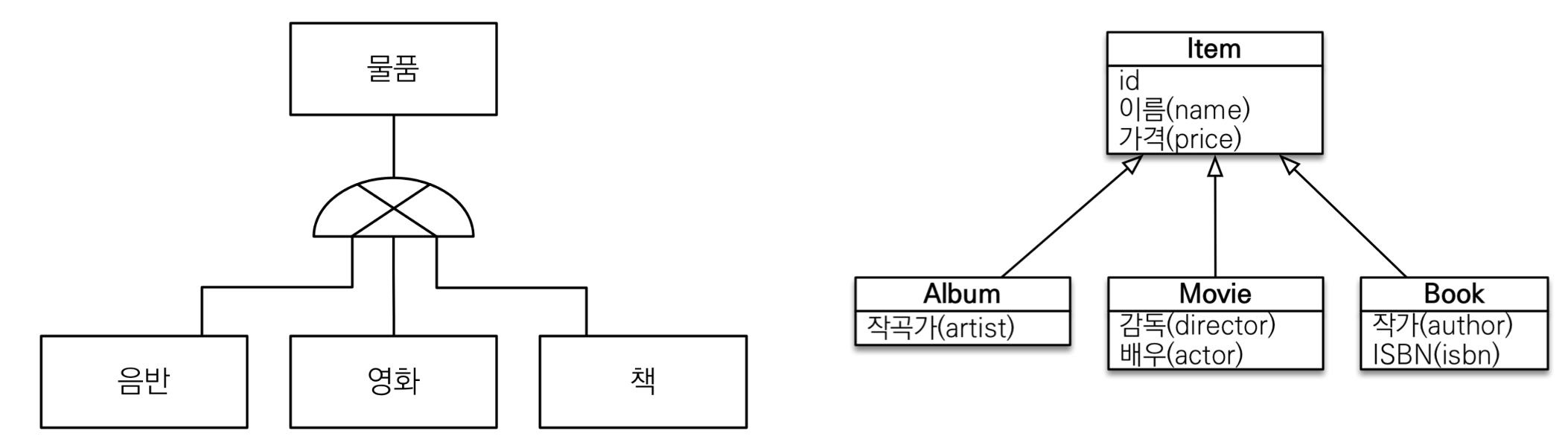
RDB는 상속관계가 없다. 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사하지만 상속이라 볼 수는 없다. 객체의 상속을 슈퍼타입 서브타입 관계로 매핑해주는 무언가가 있어야한다.상속 관계 매핑을 통해서 객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑
7.프록시와 연관관계 관리
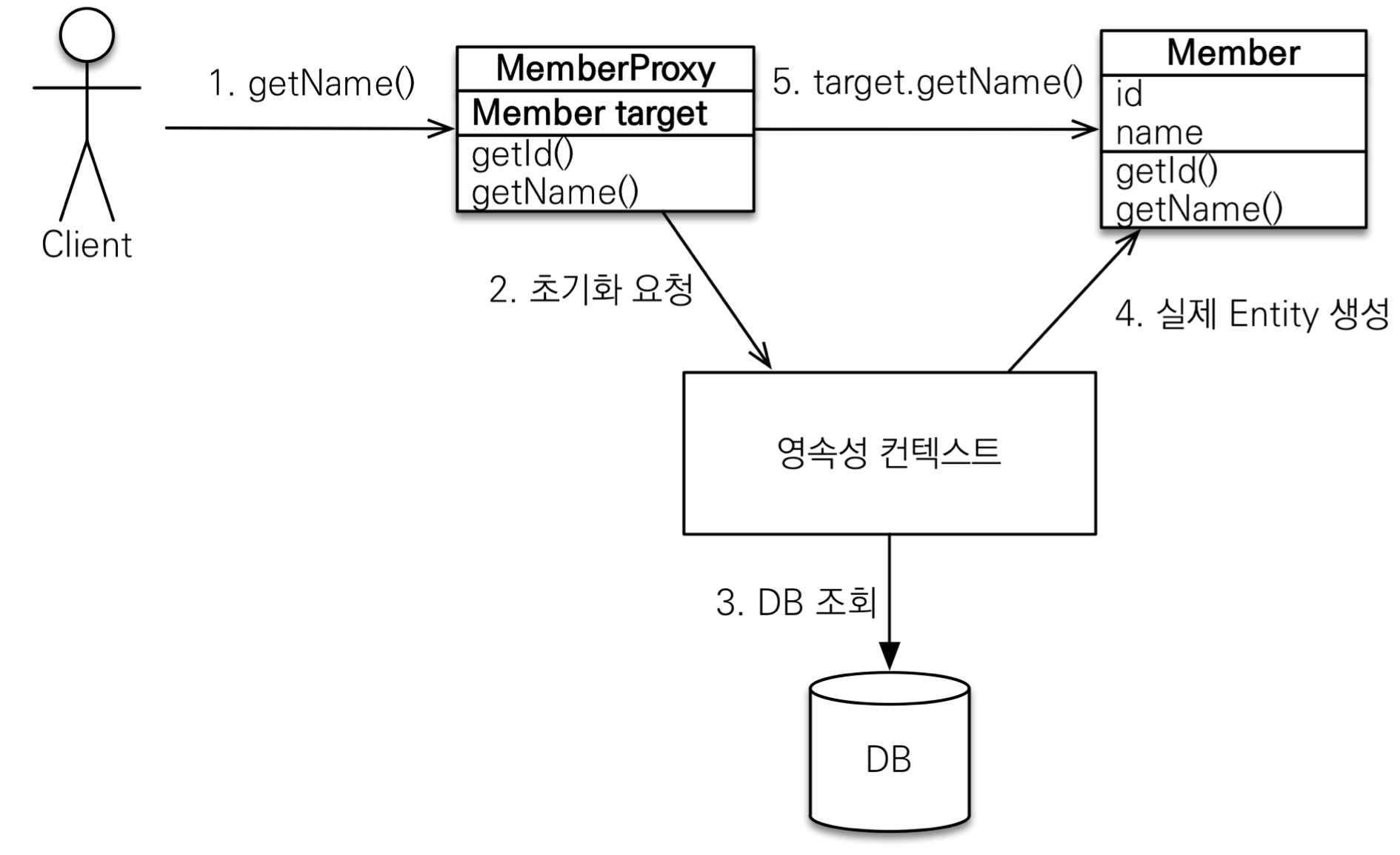
이전에 배웠던 즉시, 지연 로딩을 생각해보자. 이것들이 어떤 방식으로 작동하는 것일까? 그 비밀은 프록시에 있다.JPA에서 프록시는 매우 어려운 개념이다. (C언어의 포인터정도의 개념이라 어떤 느낌인지 알 것이다.) 이제부터 알아보자.다음은 Member 안에 Team
8.값 타입

JPA는 데이터 타입을 크게 두 가지로 구분한다.엔티티 타입 \- @Entity로 정의하는 객체데이터가 변해도 식별자로 지속해서 추적 가능예)회원 엔티티의 키나 나이값을 변경해도 식별자(PK)로 인식 가능값 타입 \- int, Integer, String 처럼 단순
9.JPQL 중급 문법
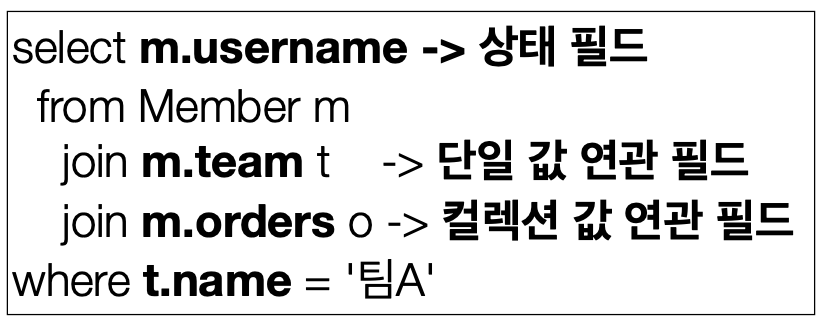
JPQL의 중급 문법을 살펴보자.경로 표현식이란 점(.)을 찍어서 객체 그래프를 탐색하는 것이다. 어떤 필드를 참조하는지에 따라 2가지로 구분된다.상태 필드연관 필드단일 값 연관 필드컬렉션 값 연관 필드하나 씩 알아보자.단순히 값을 저장하기 위한 필드이다. 따라서, 경
10.즉시 로딩, 지연 로딩, Fetch Join
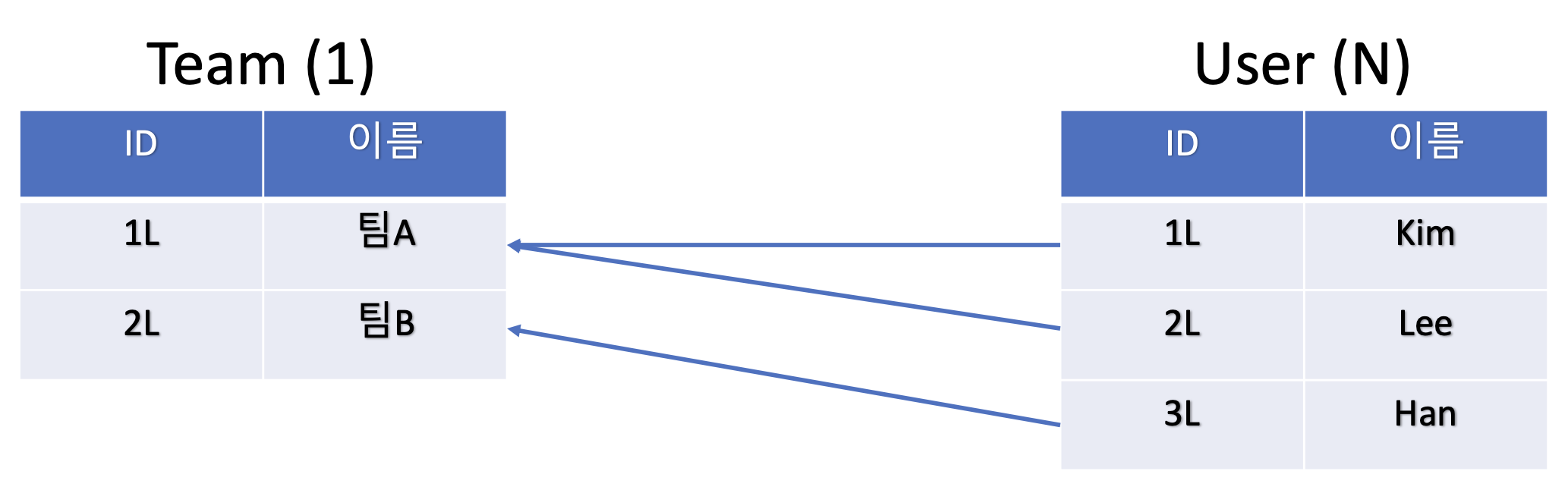
JPA를 활용하면 연관된 엔티티를 어떤 시점에 DB에서 가져올지 설정할 수 있다. 전역으로 설정하는 방법으로 즉시 로딩(EAGER), 지연 로딩(LAZY)가 있다.이 둘을 통해 SQL 최적화를 어느정도 할 순 있지만 이들은 흔히 말하는 N + 1 문제에 매우 취약하다.