JPA를 활용하면 연관된 엔티티를 어떤 시점에 DB에서 가져올지 설정할 수 있다. 전역으로 설정하는 방법으로 즉시 로딩(EAGER), 지연 로딩(LAZY)가 있다.
이 둘을 통해 SQL 최적화를 어느정도 할 순 있지만 이들은 흔히 말하는 N + 1 문제에 매우 취약하다. 이에 대한 해결책이 Fetch Join이라 봐도 무방하다.
이에 대해 공부를 하면서 헷갈렸던 부분을 중점적으로 설명하려고 한다. 시작하기 앞서 개념마다 예시를 들면서 정리를 했는데 이에 사용되는 테이블 연관관계는 아래와 같다.
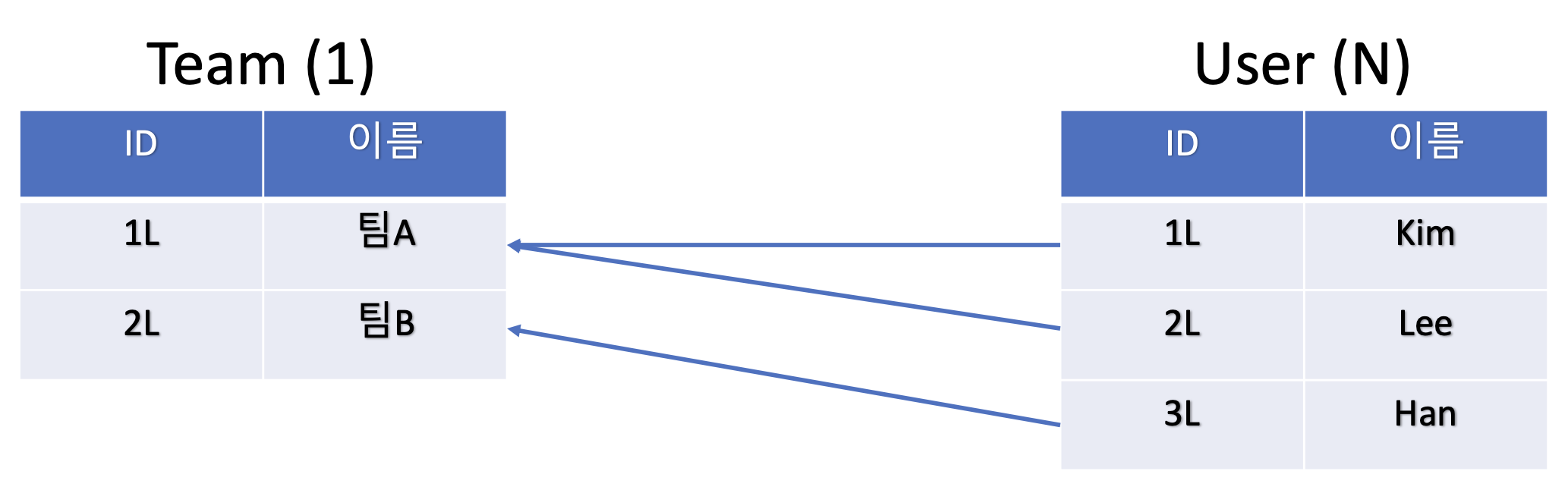
- Team과 User는 일대다 관계이다.
- Team에는
teamA,teamB2개가 저장되있다. - User에는 총 3명(
Kim,Lee,Han)이 저장되있다.
N+1 문제
대상 엔티티 조회(1) 시 연관된 엔티티들(N)에 대해 SQL이 발생하는 문제다. 나는 N+1을 다대일 관계처럼 해석했지만 이는 명백히 틀렸다.
대상 엔티티가 연관된 엔티티와 일대다 관계든 다대일 관계든 대상 엔티티를 불러오는 SQL을 1로 간주한다. 여기에 연관된 엔티티를 일일히 가져오면서 발생하는 SQL이 N이다.
지금 상황에선 모든 회원(users)에 대한 SQL이 1이라 하면 각각에 대한 팀(teamA, teamB)을 조회하면서 발생하는 SQL이 N이다.
즉시/지연 로딩 전략 모두 이 문제가 발생할 수 있다. 아래에서 자세히 살펴보자.
즉시 로딩(Eager)
대상 엔티티를 조회할 때 연관된 엔티티들도 함께 가져오는 것 전략이다. 나는 연관된 엔티티를 가져온다는 의미를 아래와 같이 해석했다.
연관된 엔티티를 가져와서 영속성 컨텍스트에 저장(영속화, Persist)한다. 따라서, 이후 이들이 조회되는 경우 DB에 SQL을 날리지 않고 값을 바로 가져올 수 있다.
연관된 엔티티를 가져올 때 어떻게 SQL을 날릴까? 이를 정확히 이해해야 Fetch Join의 장점을 알 수 있다고 생각한다.
final List<User> users = em.createQuery("select u from User u", User.class)
.getResultList();이는 총 3번의 SQL이 실행된다.
- 모든
User를 가져오는 SQL - 팀A를 가져오는 SQL
- 팀B를 가져오는 SQL
핵심은 연관된 엔티티를 하나 가져올 때 마다 하나의 SQL이 실행된다는 것이다.
즉시 로딩에서 N+1 문제
즉시 로딩에서 N + 1 문제는 위와같은 상황을 말한다. 연관된 엔티티 N개를 1개의 SQL로 처리하는 것이 아니라 N개의 SQL로 처리하기 때문이다.
그렇다면 연관된 엔티티들을 1개의 SQL로 처리하면 괜찮지 않을까? 더 나아가 이를 대상 엔티티를 조회하면서 같이 가져온다면 SQL은 1개로 충분할 것이다.
지연 로딩(Lazy)
대상 엔티티를 조회할 때 연관된 엔티티 필드를 프록시 객체로 대체하고 실제 사용(.을 통한 객체 참조가 발생)되는 시점에 DB에 SQL을 날려 데이터를 가져오는 전략이다.
이를 활용하면 무분별한 SQL이 발생하는 상황을 대비할 수 있으며, 프록시 객체를 통해 SQL 최적화가 가능하다.
아래 코드 실행시 SQL이 1번 나가므로 즉시 로딩에 비해 성능이 좋다고 할 수 있다.
final List<User> users = em.createQuery("select u from User u", User.class)
.getResultList();이 후 users에 대해 team 필드를 참조하지 않는다면 이 전략은 최선이라고 볼 수 있다. 그러나, 이후 team 필드를 참조한다면 동일한 문제가 발생한다.
for (User user : users) {
System.out.println("team name : " + user.getTeam().getName());
}이 코드는 총 2개의 SQL이 실행된다.
- 팀A를 가져오는 SQL
- 팀B를 가져오는 SQL
지연 로딩에서 N+1 문제
결국 연관된 엔티티가 사용되는 순간 N개의 추가 SQL이 발생하는 상황을 말한다. 특정 상황에선 지금과 같이 연관된 엔티티가 모두 사용될 수 있다.
특히, 지연 로딩 전략에선 N+1 문제를 해결하긴 더욱 힘들다 생각한다. 연관된 엔티티를 한 번에 하나의 SQL로 가져와야 할텐데 연관된 데이터들은 각각 사용 시점이 다른데 이를 기준으로 가져오므로 N개의 추가 SQL은 어쩔 수 없다.
Fetch Join
즉시 로딩 전략에서 N+1 문제의 해결책에 대해 잠깐 언급했으며 지연 로딩 전략에선 N+1 문제 해결이 더욱 힘들다.
이러한 이유로 Fetch Join은 즉시 로딩과 같은 느낌으로 연관된 데이터를 가져온다. 차이점은 연관된 엔티티들을 대상 엔티티를 가져오면서 모두 가져온다는 점이다.
final String sql = "select u from User u " +
"join fetch u.team";
final List<User> users = em.createQuery(sql, User.class)
.getResultList();
for (User user : users) {
System.out.println("team name : " + user.getTeam().getName());
}위 코드는 Fetch Join을 통하여 연관된 엔티티를 가져왔으며 총 1개의 SQL이 실행된다.
- 모든 회원(
users)와 회원들이 속한 모든 팀(teamA,teamB)를 가져오는 SQL
덕분에 N + 1 문제를 해결할 수 있다.
단점
그렇다면 모든 상황에서 Fetch Join을 써야 될까? 당연히 아니다. 연관된 엔티티를 조회하지 않는 다면 지연 로딩이 더욱 좋을 것이고, 연관된 엔티티의 컬럼 중 일부만 사용된다면 Fetch Join은 성능이 안좋을 것이다.
왜 연관된 엔티티 일부를 조회하는 경우엔 성능이 안좋을까?? 이를 모른다면 Fetch Join을 완벽히 이해하지 못한 것이다.
다시 한번 언급하지만 Fetch Join은 연관된 엔티티의 모든 컬럼(필드)을 가져 온다. 만약 연관된 엔티티의 필드가 100개인데 이 중 2개만 필요하다면?? 2개만 가져오면되지 100개를 다 가져올 필요는 없다.
이외에 메모리에서 페이징을 진행하여 OOM(Out Of Memory) 발생 가능성 등 다양한 이슈들이 존재한다. 이를 해결하기 위한 방법들을 추후 정리해볼 예정이다.
최선책
DB에서 데이터를 가져오는 상황은 크게 3가지로 보자.
- 특정 엔티티만 조회
- 특정 엔티티 + 연관된 엔티티의 대부분 조회
- 특정 엔티티 + 연관된 엔티티 일부 컬럼들만 조회
상황 1.
지연 로딩이 최선책이라 볼 수 있다. 굳이 Join을 사용하여 연관된 엔티티를 가져올 필요가 없다.
상황 2.
Fetch Join이 최선책이라 볼 수 있다. 즉시/지연 로딩 모두 연관된 엔티티를 가져오면서 N+1 문제가 발생하기 때문이다.
상황 3.
지금 상황에선 Fetch Join 일 것 같다. 그러나, N+1 문제는 발생하지 않지만 일부 데이터만 필요한 상황에서 모든 데이터를 가져오기에 성능이 좋진 않을 것이다.
기본 로딩 전략은 지연 로딩으로 하되 상황에 따라 Fetch Join을 사용하자. 즉시 로딩은 연관된 엔티티가 많아질수록 예상치 못한 SQL이 발생할 수 있어 성능 이슈가 우려된다.
참고
3번째 상황(특정 엔티티 + 연관된 엔티티 일부 컬럼들만 조회)에선NEW연산자 + DTO + 일반 Join을 활용하면 성능 이득을 볼 수 있다.final String sql = "select NEW com.example.demo.jpa.application.dto.response.OrderResponse(o.delivery.address.city, o.member.name, o.orderDate) from Order o"; final OrderResponse orderResponse = em.createQuery(sql, OrderResponse.class) .getSingleResult();추가로, 조회 대상이 DTO인 경우 Fetch Join은 사용할 수 없다.
