객체지향 프로그래밍의 장점은 코드를 재사용하기 용이하다는 것이다. 전통적인 패러다임과 다르게 코드를 수정하는게 아닌 새로운 코드를 추가함으로써 재사용이 가능하다.
대표적으로 상속을 통해 코드를 재사용한다. 그러나, 이는 많은 문제들을 동반한다.
우선 코드를 재사용하는게 왜 중요한지 살펴보자.
중복 코드
중복 코드가 발생하면 안되는 이유는 간단하다. 변경을 방해하기 때문이다. 새로운 코드를 추가하고 나면 언젠간 변경될 것이라고 생각해야 한다. 이런 상황에서 중복 코드는 코드를 수정하는데 드는 비용을 몇 배 증가시킨다.
중복 코드인지 판단하는 기준은 변경이다.
요구사항이 변경됐을 때 두 코드를 함께 수정해야 한다면 이 코드는 중복이라 볼 수 있다.
신뢰할 수 있고 수정하기 쉬운 소프트웨어를 만들기 위해선 중복을 제거해야 한다. 이를 위해선 DRY(Don't Repeat Yourself) 원칙을 준수해야 한다.
DRY 원칙
모든 지식은 시스템 내에서 단일하고, 애매하지 않고, 정말로 믿을만한 표현 양식을 거쳐야 한다.
DRY는 '반복하지 마라'라는 뜻의 Don't Repeat Yourself 의 첫 글자를 모아 만든 용어로 간단히 말하면 동일한 지식을 중복하지 말자를 뜻한다.
이는 한 번, 단 한 번(Once and Only Once) 또는 단일 지점 제어(Single-Point Control) 원칙이라고도 부른다.
핵심은 코드 안에서 중복이 존재하면 안된다는 것이다.
중복과 변경
e.g. 한 달에 한 번씩 전화 요금을 계산하는 어플리케이션
개별 통화기간을 저장하는 클래스 Call.java
public class Call {
private LocalDateTime from;
private LocalDateTime to;
public Call(LocalDateTime from, LocalDateTime to) {
this.from = from;
this.to = to;
}
public Duration getDuration() {
return Duration.between(from, to);
}
public LocalDateTime getFrom() {
return from;
}
}전체 통화목록을 알 고 있는 클래스 Phone.java
public class Phone {
private Money amount;
private Duration seconds;
private List<Call> calls = new ArrayList<>();
public Phone(Money amount, Duration seconds) {
this.amount = amount;
this.seconds = seconds;
}
public void call(Call call) {
calls.add(call);
}
public List<Call> getCalls() {
return calls;
}
public Money getAmount() {
return amount;
}
public Duration getSeconds() {
return seconds;
}
public Money calculateFee() {
Money result = Money.ZERO;
for(Call call : calls) {
result = result.plus(amount.times(call.getDuration().getSeconds() / seconds.getSeconds()));
}
return result;
}
}심야 할인 요금을 계산하는 클래스 NightlyDiscountPhone.java
public class NightlyDiscountPhone {
private static final int LATE_NIGHT_HOUR = 22;
private Money nightlyAmount;
private Money regularAmount;
private Duration seconds;
private List<Call> calls = new ArrayList<>();
public NightlyDiscountPhone(Money nightlyAmount, Money regularAmount, Duration seconds) {
this.nightlyAmount = nightlyAmount;
this.regularAmount = regularAmount;
this.seconds = seconds;
}
public Money calculateFee() {
Money result = Money.ZERO;
for(Call call : calls) {
if (call.getFrom().getHour() >= LATE_NIGHT_HOUR) {
result = result.plus(nightlyAmount.times(call.getDuration().getSeconds() / seconds.getSeconds()));
} else {
result = result.plus(regularAmount.times(call.getDuration().getSeconds() / seconds.getSeconds()));
}
}
return result;
}
}NightlyDiscountPhone 클래스는 Phone 클래스 코드 일부를 복사해서 만들었다. 요구사항을 짧은 시간에 구현을 했으나 언젠간 변경이 발생할 때 리스크가 존재한다.
추가로, 요금제에 세금을 추가한다고 생각해보자. Phone, NightlyDiscountPhone 모두 수정해야 될 것이다. 이처럼 중복 코드는 변경 포인트가 같으므로 하나라도 빠뜨린다면 버그로 이어진다.
중복 코드를 제거하지 않은 상태에서 코드 수정을 한다면 또 다른 중복 코드가 발생한다. 이러한 중복 코드가 많아질수록 변경에 취약해져 버그 발생 가능성이 높아진다.
우리는 코드를 DRY 하게 만들기 위해 노력해야한다.
타입 코드(구분자) 사용하기
Phone.java
public class Phone {
private static final int LATE_NIGHT_HOUR = 22;
enum PhoneType { REGULAR, NIGHTLY }
private PhoneType type;
private Money amount;
private Money regularAmount;
private Money nightlyAmount;
private Duration seconds;
private List<Call> calls = new ArrayList<>();
public Phone(Money amount, Duration seconds) {
this(PhoneType.REGULAR, amount, Money.ZERO, Money.ZERO, seconds);
}
public Phone(Money nightlyAmount, Money regularAmount,
Duration seconds) {
this(PhoneType.NIGHTLY, Money.ZERO, nightlyAmount, regularAmount,
seconds);
}
public Phone(PhoneType type, Money amount, Money nightlyAmount,
Money regularAmount, Duration seconds) {
this.type = type;
this.amount = amount;
this.regularAmount = regularAmount;
this.nightlyAmount = nightlyAmount;
this.seconds = seconds;
}
public Money calculateFee() {
Money result = Money.ZERO;
for(Call call : calls) {
if (type == PhoneType.REGULAR) {
result = result.plus(amount.times(call.getDuration().getSeconds() / seconds.getSeconds()));
} else {
if (call.getFrom().getHour() >= LATE_NIGHT_HOUR) {
result = result.plus(nightlyAmount.times(call.getDuration().getSeconds() / seconds.getSeconds()));
} else {
result = result.plus(regularAmount.times(call.getDuration().getSeconds() / seconds.getSeconds()));
}
}
}
return result;
}
}별도의 구분자 필드(PhoneType)를 두고 이 값에 따라 로직을 분리시키는 방법이다. 이는 낮은 응집도와 높은 결합도를 유발하므로 사용하지 말자.
상속
상속은 객체지향에서 대표적인 코드 재사용 기법이다. 그러나, 이는 많은 문제들은 야기한다.
취약한 기반 클래스 문제
상속 관계로 연결된 자식 클래스가 부모 클래스의 변경에 취약해지는 현상을 뜻한다. 위 예시처럼 코드 재사용을 목적으로 상속을 사용하는 경우에 발생한다. 구체적인 문제점들은 아래와 같다.
상속을 염두해두고 설계되지 않은 클래스를 생각하는건 어렵다.
상속은 결국 부모 메서드를 오버라이딩하면서 많은 가정들을 하게 된다. 이 과정에서 코드의 가독성이 떨어지게 된다.
이러한 가정들이 쌓일수록 상속 계층간 결합도가 높아진다. 이는 코드 수정을 어렵게 만든다.
부모 클래스의 변경의 여파가 자식 클래스까지 전파된다.
부모 클래스에 필드가 추가되는 경우 자식 클래스까지 변경이 전파된다. 이를 수정하면서 부모/자식 클래스간 중복 코드가 발생하게 된다.
코드 중복을 없애기 위해 상속을 사용했으나 기능 추가 시 중복 코드가 발생하는 아이러니한 상황이다.
참고 super는 지양하자
자식 클래스에서super키워드를 통해 부모 인스턴스를 참조한다면 부모/자식 간 결합도가 높아지게 된다.
참고 상속으로 인한 2가지 선택지
상속을 사용하면 다음 2가지 중 하나를 반드시 선택해야 한다.
- 부모/자식 클래스의 구현이 영원히 변하지 않아야 한다.
- 부모/자식 클래스의 변경이 동시에 일어나야 한다.
상속은 캡슐화와 코드 재사용성 간의 트레이드 오프다.
상속은 코드 재사용성이 높아지긴 하나 시스템 전체적으로 높은 결합도가 유지된다. 부모/자식간 높은 결합도로 인해 캡슐화를 저해한다.
부모 클래스로 인해 자식 클래스 내부 구조 규칙이 깨질 수 있다.
대표적으로 Java의 Stack<E>, Vector<E> 의 관계를 살펴보자.
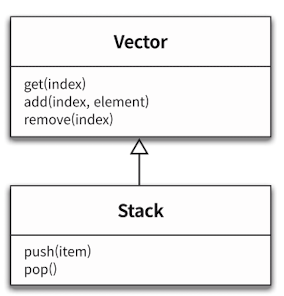
Stack은Vector의 자식 클래스이다.
Stack은 대표적인 LIFO 자료구조이다. 그러나, Vector의 모든 퍼블릭 인터페이스를 가져 LIFO라는 규칙을 어길 수 있다.
추상화에 의존하자
상속의 가장 큰 문제는 부모/자식 클래스간 높은 결합도이다. 이를 느슨하게 하려면 부모/자식 모두 추상화에 의존하면 된다.
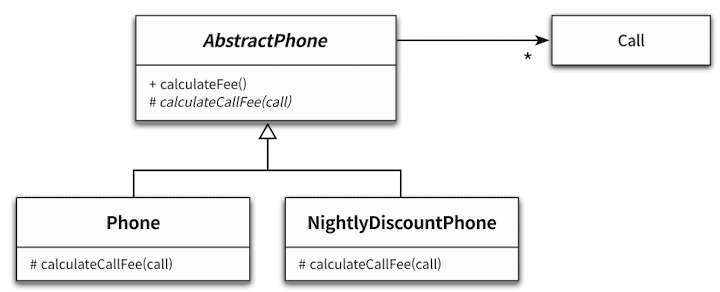
이처럼 차이가 있는 부분을 메서드로 추출하여 추상화하고 공통적인 부분은 모두 부모 클래스에 올리자.
덕분에 우리는 SRP, DIP, OCP를 모두 준수하는 코드를 얻게 된다.
SRP를 준수한다.
위 클래스들은 각각 하나의 변경 이유를 가지므로 응집도가 높다.
DIP를 준수한다.
세부적인 정책이 상위 수준 정책을 의존하고 있다.
OCP를 준수한다.
기능 추가시 새로운 클래스를 추가하면 된다.
상속은 트레이드 오프의 산물
필드 목록이 변하지 않는 상황에서 객체의 행동만 변경된다면 상속 계층에 속한 클래스들을 독립적으로 진화시킬 수 있다.
그러나, 필드가 추가되는 경우는 다르다. 자식 클래스 초기화 로직에 영향을 준다.
이는 트레이드 오프다. 핵심은 초기화 로직을 변경하는게 핵심 로직을 중복시키는 것보다 낫다. 핵심 로직은 한 곳에 모아두고 조심스럽게 캡슐화하자. 공통적인 핵심 로직은 최대한 추상화하자.
상속은 결합도를 높인다. 우리는 이를 완벽히 해결할 순 없다. 최선은 행동을 변경하기 위해 필드를 추가하더라도 상속 계층 전체에 부작용이 퍼지지 않게 막는 것이다.
차이에 의한 프로그래밍
기존 코드와 다른 부분만 추가함으로써 어플리케이션 기능을 추가하는 것을 뜻한다. 중복 코드를 제거하고 코드를 재사용하는 것을 목표로 한다.
이를 위해 우리는 "상속"을 사용해야 한다. 그러나, 상속은 필연적으로 결합도를 높이는 등 다양한 문제점들을 야기한다.
추상화를 통해 최대한 결합도를 낮추자.
