합성 또한 상속과 마찬가지로 객체지향에서 가장 널리 사용되는 코드 재사용 기법이다. 합성은 재사용 객체를 인스턴스로 포함하여 해당 객체의 코드를 사용한다.
상속과 합성
기존 상속의 문제점
상속은 구현에 의존하며 컴파일 시점에 의존성이 해결된다. 대부분의 경우 구현보단 인터페이스에 의존하는게 좋다.
확장을 쉽게할 수 있다는 장점이 있지만 부모 클래스 내부를 상세히 알아야 하므로 부모/자식 클래스간 결합도가 높아진다.
이는 조합의 결과를 개별 클래스 안으로 밀어넣는 방식이라 볼 수 있다.
합성
합성은 두 객체 사이의 의존성이 런타임 시점에 해결된다. 정확히 재사용하려는 코드만 가져올 수 있으므로 상속이 야기하는 문제들을 해결할 수 있다.
참고 상속이 야기하는 문제들
e.g. 동시 수정, 오버라이딩 문제, 자식 클래스 내부 규칙 와해
조합을 구성하는 요소들을 실행 시점에 조립하는 방식이라 볼 수 있다. 상속에 비해 높은 안정성과 유연성을 가진다.
상속은 extends 키워드를 통해 컴파일 시점에 부모 클래스를 명시한다. 결국 구현에 결합이 되므로 좋지 못한 설계가 된다.
반면, 합성은 추상체를 필드로 둠으로써 퍼블릭 인터페이스에 의존할 수 있다. 덕분에 변경의 여파를 최소화할 수 있다.
상속이 야기하는 문제을 합성으로 해결
자식 클래스 내부 규칙 와해
기존 Stack<E>의 부모 클래스가 Vector<E> 이면서 스택의 LIFO 특성이 지켜지지 않는 문제가 있었다.
합성으로 구현한다면 자식 클래스(Stack<E>)에서 부모 클래스의 모든 메서드를 제공하지 않아도 되므로 LIFO 특성을 정확히 지킬 수 있다.
public class Stack<E> {
private final Vector<E> vector;
public boolean push(E element) { ... }
public E pop() { ... }
public boolean contain(E element) {
return vector.contains(element);
}
...
}메서드 오버라이딩 문제
오버라이딩된 메서드에서 또 다른 오버라이딩된 메서드를 호출하는 경우가 빈번하다면 동적 바인딩의 결과를 예측하기 힘들다. 이로 인해 해결하기 힘든 버그가 발생할 수 있다. 아래 예시를 보자.
HashSet<E> 에서 개수를 세는 자식 클래스를 만들었다.
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0;
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
}아래 코드를 시행한다면 개수가 6이 된다.
InstrumentedHashSet<String> set = new InstrumentedHashSet();
set.addAll(Arrays.asList("Java", "Python", "C++");addAll() 메서드가 호출되면서 내부적으로 add() 메서드가 호출될 때 자식 클래스의 add()가 호출되어 addCount 값이 증가하게 된다.
예측할 수 없는 동적 바인딩 과정으로 인해 코드의 결과를 예측하기 힘들어진다.
아래와 같이 합성을 사용한다면 이 문제를 쉽게 해결할 수 있다.
public class InstrumentedHashSet<E> {
private int addCount = 0;
private Set<E> set;
public InstrumentedHashSet(Set<E> set) {
this.set = set;
}
@Override
public boolean add(E e) {
addCount++;
return set.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return set.addAll(c);
}
}그러나, 위 클래스는 HashSet<E>의 모든 메서드를 포함해야 한다. Set<E> 인터페이스를 구현하므로써 이 문제를 해결할 수 있다.
public class InstrumentedHashSet<E> implements Set<E> {
private int addCount = 0;
private Set<E> set;
public InstrumentedHashSet(Set<E> set) {
this.set = set;
}
@Override
public boolean add(E e) {
addCount++;
return set.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return set.addAll(c);
}
public int getAddCount() {
return addCount;
}
@Override public boolean remove(Object o) {
return set.remove(o);
}
@Override public void clear() {
set.clear();
}
@Override public boolean equals(Object o) {
return set.equals(o);
}
@Override public int hashCode() {
return set.hashCode();
}
@Override public Spliterator<E> spliterator() {
return set.spliterator();
}
@Override public int size() {
return set.size();
}
@Override public boolean isEmpty() {
return set.isEmpty();
}
@Override public boolean contains(Object o) {
return set.contains(o);
}
@Override public Iterator<E> iterator() {
return set.iterator();
}
@Override public Object[] toArray() {
return set.toArray();
}
@Override public <T> T[] toArray(T[] a) {
return set.toArray(a);
}
@Override public boolean containsAll(Collection<?> c) {
return set.containsAll(c);
}
@Override public boolean retainAll(Collection<?> c) {
return set.retainAll(c);
}
@Override public boolean removeAll(Collection<?> c) {
return set.removeAll(c);
}
}덕분에 InstrumentedHashSet 클래스는 Set 인터페이스를 구현하면서 HashSet에 한 구현 결합도는 제거됐다.
참고 포워딩
위처럼 기존 클래스의 인터페이슬르 그대로 외부에 제공하면서 구현에 대한 결합없이 일부 작동 방식을 변경하는 것을 포워딩이라 한다.Java에서는 인터페이스 구현 + 합성을 통해 포워딩을 구현할 수 있다.
합성으로 해결하기 힘들어도 합성을 사용하자
앞서 상속에서 발생하는 동시 수정 문제는 합성으로도 해결하기 힘들다.
Playlist.java
public class Playlist {
private List<Song> tracks = new ArrayList<>();
private Map<String, String> singers = new HashMap<>();
public void append(Song song) {
tracks.add(song);
singers.put(song.getSinger(), song.getTitle());
}
public List<Song> getTracks() {
return tracks;
}
public Map<String, String> getSingers() {
return singers;
}
}PersonalPlaylist.java
public class PersonalPlaylist {
private Playlist playlist = new Playlist();
public void append(Song song) {
playlist.append(song);
}
public void remove(Song song) {
playlist.getTracks().remove(song);
playlist.getSingers().remove(song.getSinger());
}
}가수별 노래 목록을 유지하기 위해선 Playlist와 PersonalPlaylist 모두 수정해야 한다.
그래도 상속보단 합성을 사용하는게 낫다. 합성은 캡슐화를 통해 Playlist의 내부 구현의 파급 효과를 최대한 낮출 수 있기 때문이다.
참고 몽키 패치
현재 실행중인 환경에만 영향을 미치도록 지역적으로 코드를 수정하거나 확장하는 것
e.g. Java의 바이트코드 직접 변환, AOP(Aspect-Oriented Programming)
조합에서 상속 vs 합성
작은 기능들을 조합해 큰 기능을 만들어야 하는 경우 상속은 더더욱 부적합하다. 이 경우 상속이 야기하는 문제점들은 아래와 같다.
- 하나의 기능 추가/수정 비용이 비싸다
- 단일 상속의 경우 중복 코드가 오히려 많아진다.
휴대폰 요금제 계산 로직을 통해 이를 구체적으로 알아보자.
기본 정책과 부가 정책 조합하기

- 기본 정책은 반드시 1개만 적용하며 계산 결과에 적용된다.
- 부가 정책은 선택적으로 적용할 수 있으며 기본 정책 계산 후 반영된다.
- 부가 정책은 임의의 순서대로 적용 가능하다.
이러한 요구 사항을 만족하는 조합의 수는 아래와 같다.
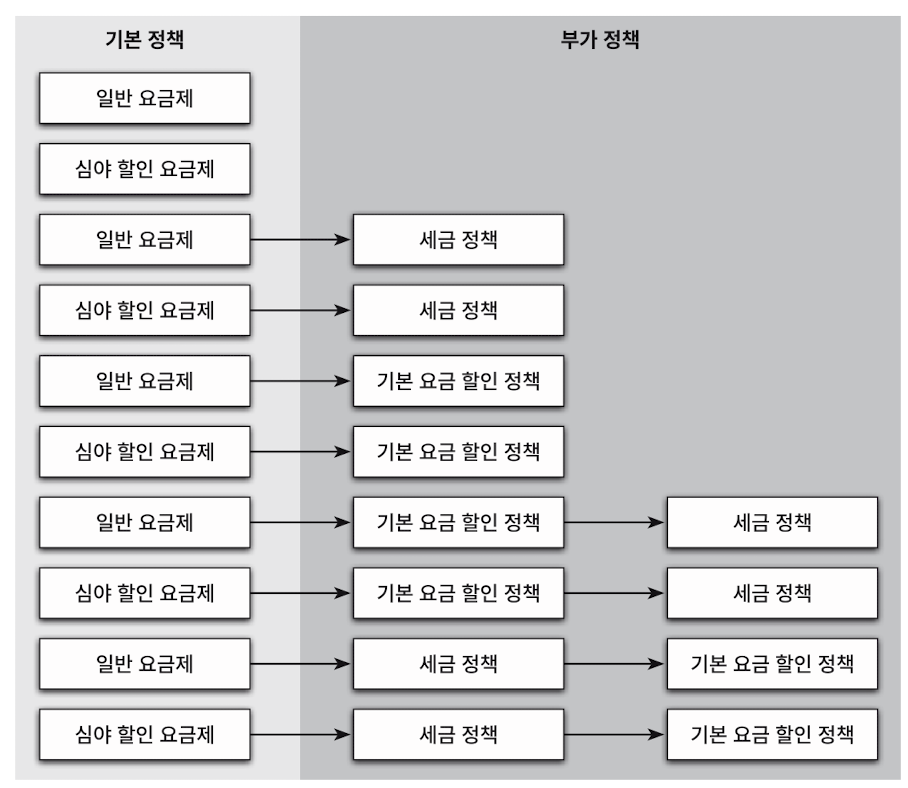
상속을 통해 조합
아래 2가지 경우의 수를 관계도로 나타내면 아래와 같다.
- 기본 정책 -> 세금 정책
- 심야 할인 요금제 -> 세금 정책
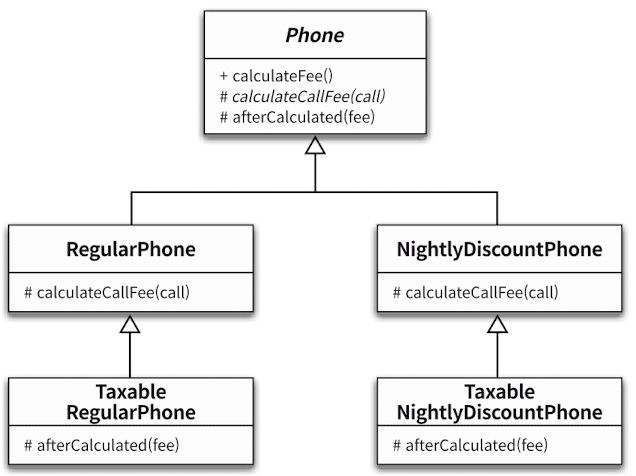
두 경우 모두 부가 정책으로 "세금 정책"이란 공통적 요소를 가지고 있지만 적용되는 기본 정책이 달라 별도의 클래스로 표현해야 한다.
TaxableRegularPhone.java
public class TaxableRegularPhone extends RegularPhone {
private double taxRate;
public TaxableRegularPhone(Money amount, Duration seconds, double taxRate) {
super(amount, seconds);
this.taxRate = taxRate;
}
@Override
protected Money afterCalculated(Money fee) {
return fee.plus(fee.times(taxRate));
}
}TaxableNightlyDiscountPhone.java
public class TaxableNightlyDiscountPhone extends NightlyDiscountPhone {
private double taxRate;
public TaxableNightlyDiscountPhone(Money nightlyAmount, Money regularAmount, Duration seconds, double taxRate) {
super(nightlyAmount, regularAmount, seconds);
this.taxRate = taxRate;
}
@Override
protected Money afterCalculated(Money fee) {
return fee.plus(fee.times(taxRate));
}
}이 둘은 모두 "세금 정책"이라는 공통적인 것을 표현하지만 결합되는 부모 클래스가 달라 별도로 구현했다. 이로 인해 중복 코드가 발생했다.
아래와 같이 경우의 수가 많아진다면 중복 코드가 매우 많아질 것 이다.
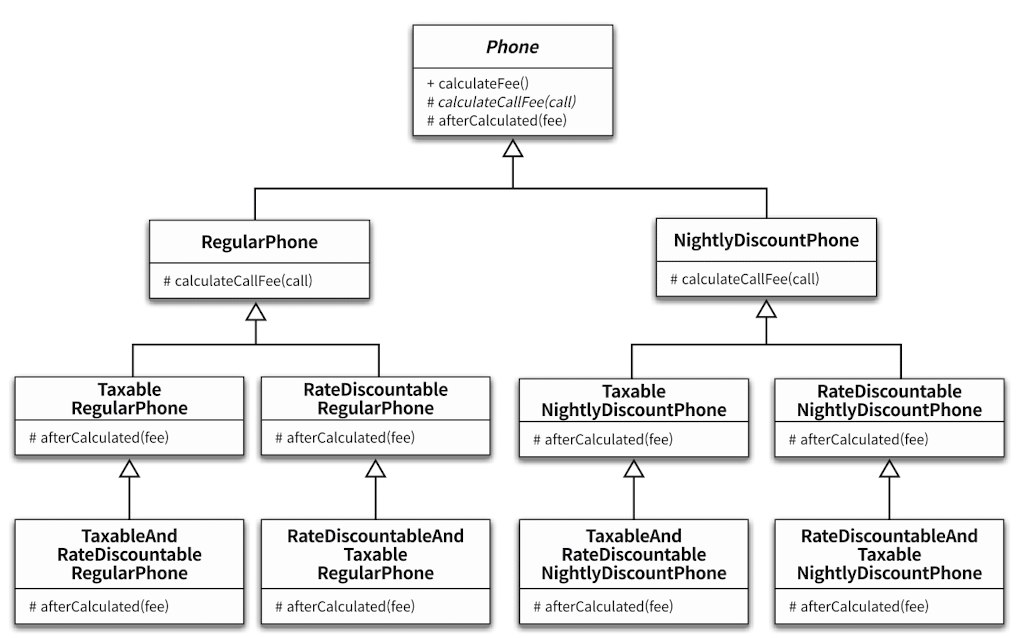
더불어 상위 정책 추가시 하위 클래스를 재사용하지 못하므로 무수히 많은 중복 코드가 발생한다. (e.g. 기본 정책에 고정 요금제 정책 추가)
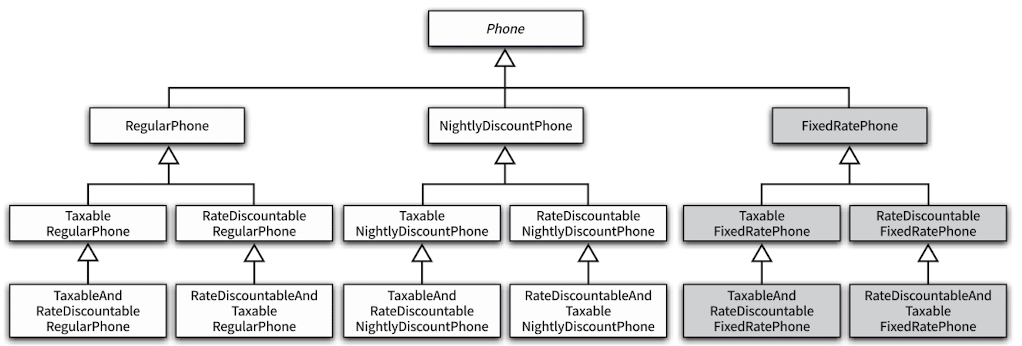
이처럼 상속의 남용으로 하나의 기능을 추가하기 위해 필요 이상으로 수많은 클래스를 만들어야 하는 경우를 클래스 폭발 문제라고 한다. 원인은 부모/자식 강한 결합도를 강요하는 상속의 근본적인 문제때문이다.
상속의 근본적인 문제
상속은 컴파일 시점에 의존성이 결정되므로 코드를 실행하는 도중엔 변경이 불가능하다. 이로 인해 모든 가능한 경우의 수 마다 클래스를 만들어야 한다.
의존성을 런타임 시점에 결정한다면 문제를 해결할 수 있다. 합성을 사용하면 구현이 아닌 퍼블릭 인터페이스에 의존하므로 런타임에 객체 관계 변경이 가능해진다.
참고
컴파일 시점 의존성과 런타임 의존성의 차이가 클수록 설계가 유연해진다.
물론, 디버깅이 어려워진다는 트레이드 오프가 있지만 설계의 유연성으로 인한 이득이 더 크다.
합성을 통한 조합
상속은 조합의 결과를 클래스로 표현하는 반면 합성은 조합의 구성 요소를 클래스로 구현하여 이들을 조합한다.
일단,기본/부가 정책을 모두 포함하는 최상위 인터페이스를 두자. 이처럼 계층간 인터페이스를 두면 추후 다른 상위 정책 추가가 편해진다.
RatePolicy.java
public interface RatePolicy {
Money calculateFee(Phone phone);
}기본 정책은 크게 일반/심야 할인 요금으로 나뉘므로 이들을 포괄하는 추상 클래스를 두자. 추상 클래스로 두는 이유는 부모 인터페이스를 구현함과 동시에 추상 메서드를 포함해야되기 때문이다.
BasicRatePolicy.java
public abstract class BasicRatePolicy implements RatePolicy {
@Override
public Money calculateFee(Phone phone) {
Money result = Money.ZERO;
for(Call call : phone.getCalls()) {
result.plus(calculateCallFee(call));
}
return result;
}
protected abstract Money calculateCallFee(Call call);
}위에서 작성한 기본 정책을 이용해 요금을 계산하는 클래스는 아래와 같다.
Phone.java
public class Phone {
private RatePolicy ratePolicy;
private List<Call> calls = new ArrayList<>();
public Phone(RatePolicy ratePolicy) {
this.ratePolicy = ratePolicy;
}
public List<Call> getCalls() {
return Collections.unmodifiableList(calls);
}
public Money calculateFee() {
return ratePolicy.calculateFee(this);
}
}덕분에 동적으로 기본 정책을 설정하는게 가능하다.
Phone nightDiscountPolicyPhone = new Phone(new NightDiscountPolicy(...));
Phone regularPolicyPhone = new Phone(new RegularPolicy(...));부가 정책도 마찬가지로 RatePolicy를 구현하며 추상 메서드를 포함한다.
AdditionalRatePolicy.java
public abstract class AdditionalRatePolicy implements RatePolicy {
private RatePolicy next;
public AdditionalRatePolicy(RatePolicy next) {
this.next = next;
}
@Override
public Money calculateFee(Phone phone) {
Money fee = next.calculateFee(phone);
return afterCalculated(fee) ;
}
abstract protected Money afterCalculated(Money fee);
}- 이후 적용될 부가 정책을
next필드로 둬서 여러 부가 정책의 조합이 가능하다.
조합을 사용하여 아래와 같은 계층 구조가 만들어졌다.
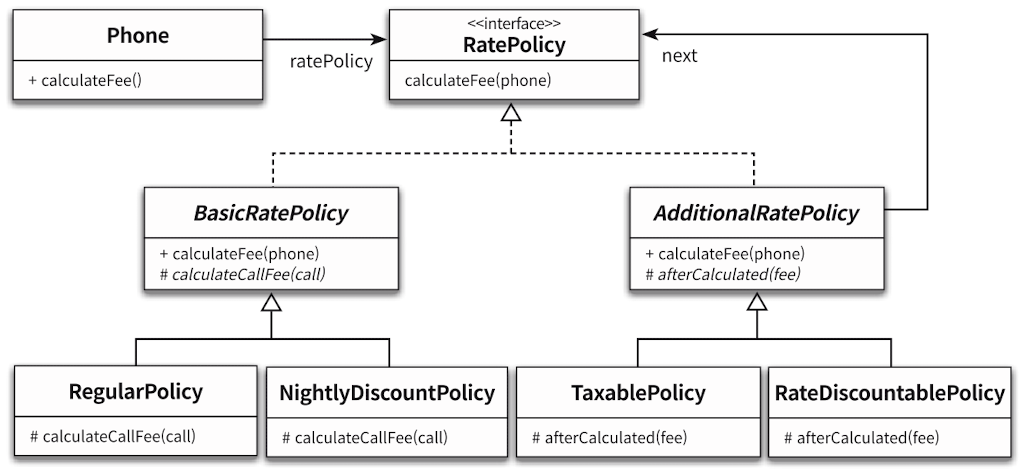
기존 정책 계층마다 클래스를 만들지 않고 기존 클래스를 재사용하는 방법으로 모든 경우의 수를 구현할 수 있게 되었다.
상위 정책 추가 시 해당 단계의 인터페이스를 구현하면 기존 하위 클래스를 재사용할 수 있어 클래스 폭발 문제가 해결된다.
왠만하면 합성을 사용하자
객체지향에서 전통적으로 재사용을 위해 사용되는 기법은 상속이다. 그러나, 시간이 지날수록 상속으로 인한 여러 문제점들이 제기되면서 합성이라는 방법이 나왔다.
합성은 코드를 재사용하면서 건전한 결합도를 유지할 수 있다. 특히, 구현에 의존하지 않고 객체의 인터페이스를 재사용한다.
일반적으로 코드 재사용 시 상속보단 합성이 좋다. 합성을 사용하자.
믹스인
믹스인이란 객체를 생성할 때 코드 일부를 클래스안에 섞어 넣어 재사용하는 기법이다. 이는 합성과 상속의 장점을 모두 가지고 있다.
합성 vs 믹스인
합성은 런타임 시점에 객체를 조합하는 재사용 기법이다. 반면 믹스인은 컴파일 시점에 필요한 코드 조각을 조합하는 재사용 기법이다.
상속 vs 믹스인
상속은 클래스 사이 관계를 고정시킨다. 반면 믹스인은 동적으로 관계를 재구성할 수 있다.
즉, 믹스인은 합성처럼 유연하면서 상속처럼 쉽게 코드 재사용이 가능하다.
참고
Java의 대표적인 믹스인 인터페이스는Comparable<T>가 있다.
이는 해당 클래스끼리 "비교"라는 기능을 혼합한다.
믹스인 객체
Java에서는 별도로 믹스인을 지원하는 명령어가 없다. Scala에선 trait 명령어를 통해 믹스인 객체를 구현할 수 있다.
trait TaxablePolicy extends BasicRatePolicy {
val taxRate: Double
override def calculateFee(phone: Phone): Money = {
val fee = super.calculateFee(phone)
return fee + fee * taxRate
}
}TaxablePolicy의 부모 클래스는BasicRatePolicy이거나BasicRatePolicy의 자식 클래스이다. 이는TaxablePolicy의 문맥을 제한하기 위함이다.super참조는 지양해야 된다고 했지만 믹스인에서는 예외다. 부모 클래스가 런타임 시점에 정해지므로super의 사용이 결합도를 높인다고 볼 수 없다.
객체지향 언어에서 부모 클래스에 자식 클래스를 명시할 필요는 없다. 그러나, 반대의 경우 필수적이다.
믹스인은 부모 클래스에 상속받는 자식 클래스를 명시하는 매커니즘이라 볼 수 있다.
쌓을 수 있는 변경
믹스인은 특정 클래스에 대한 변경 또는 확장을 독립적으로 구현한 후 필요한 시점에 차례대로 추가할 수 있다. 이를 쌓을 수 있는 변경이라 한다.
