Microarchitecture : Single-Cycle Processor
Microarchitecture
마이크로아키텍처(Microarchitecture)는 아키텍처를 하드웨어로 구현하는 방법이 기술된 설계도와 같다.
마이크로아키텍처의 프로세서(processor)는 데이터를 처리하는 회로 구성요소들의 집합인 Datapath와 control signal을 이용해서 프로세서의 작동을 제어하는 Control로 이루어져있다.
프로세서의 성능은 실행 시간으로 평가된다.
Execution Time = (#instructions)(cycles/instruction)(seconds/cycle)
- CPI : Cycles/instruction
- clock period : seconds/cycle
- IPC : instructions/cycle
비용, 전력, 성능의 제약을 고려하여 설계해야한다.
현재 나의 지식으로 완전한 마이크로아키텍처를 구현하는 것에는 무리가 있으므로 일부 명령어만 가지고 single-cycle 프로세서를 구현해보겠다.
- R-type ALU 명령 :
add,sub,and,or,slt - 메모리 명령 :
lw,sw - 분기 명령 :
beq
프로세서에서 state 처리를 하기 위해 32개의 레지스터(PC 포함)와 메모리를 사용할 것이고,
여기에 연산 처리를 위해 ALU를 사용할 것이다.
Single-Cycle RISC-V Processor
하나의 사이클로 모든 명령어를 수행시키는 방식으로, 수행 시간이 가장 긴 명령어를 기준으로 사이클을 설정한다.
Datapath 설계
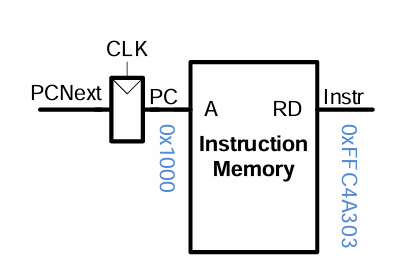
lw fetch :

먼저 instruction memory를 통해 PC에 위치한 명령어를 받는다.
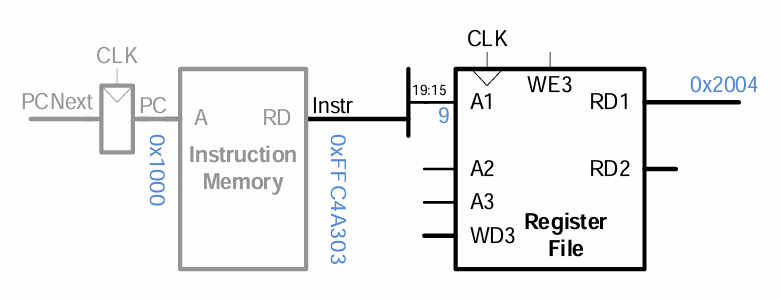
레지스터 파일에서 rs1에 저장된 값을 읽는다.
imm에 저장된 12-bit를 32-bit로 sign-extend 한다.
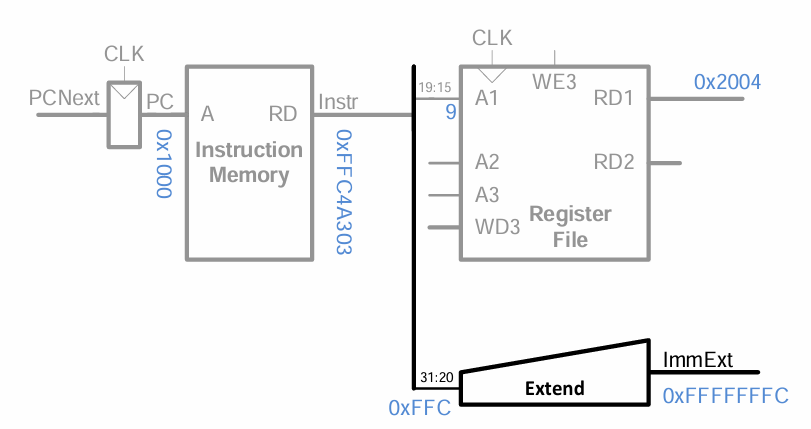
rs1에 저장된 값과 imm 값을 이용해 메모리 주소를 계산한다.
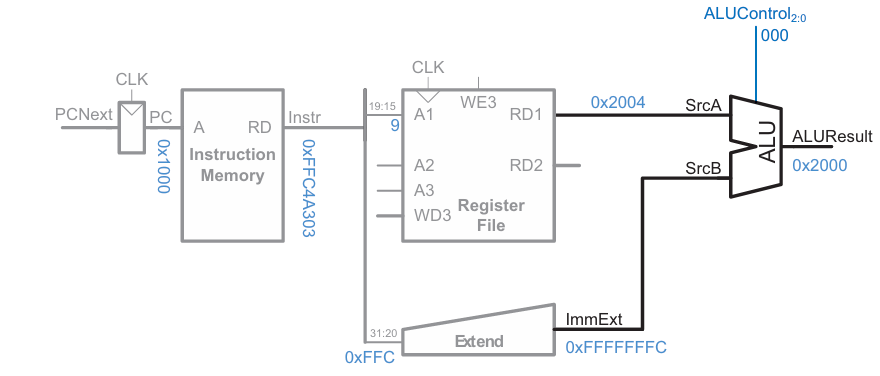
(32-bit이므로 엄밀히 따지면 주소는 0x00002000일 것임)
해당 메모리 주소에서 값을 읽고(read) 레지스터 파일에 쓴다(write).
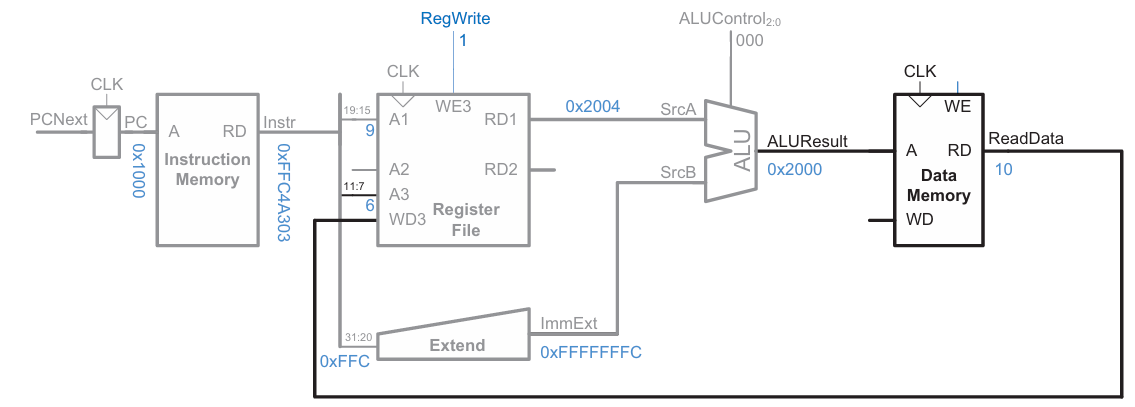
다음 명령의 주소를 정한다.
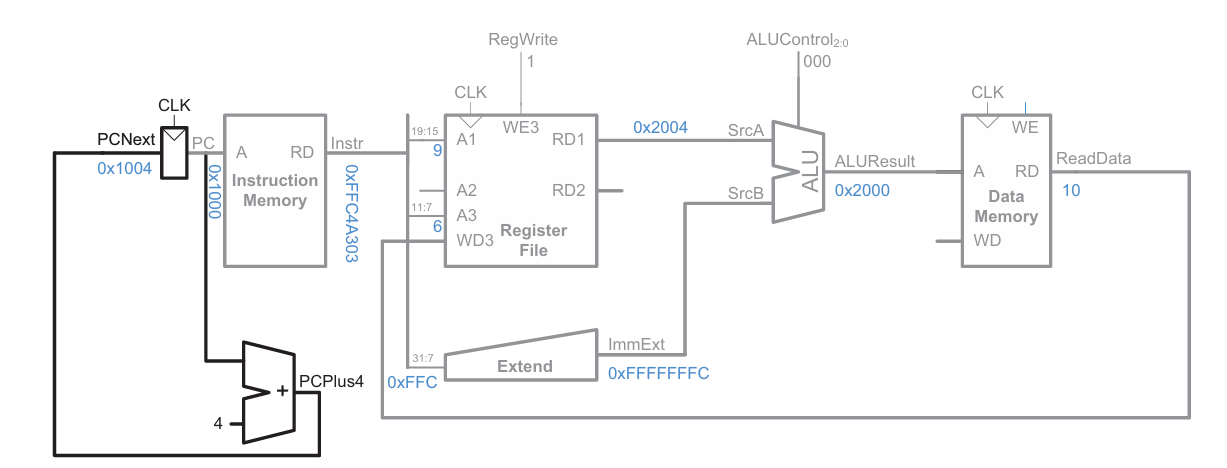
이렇게 lw를 위한 datapath가 설계되었다. 여기에 다른 명령들의 datapath도 덧붙여보자.
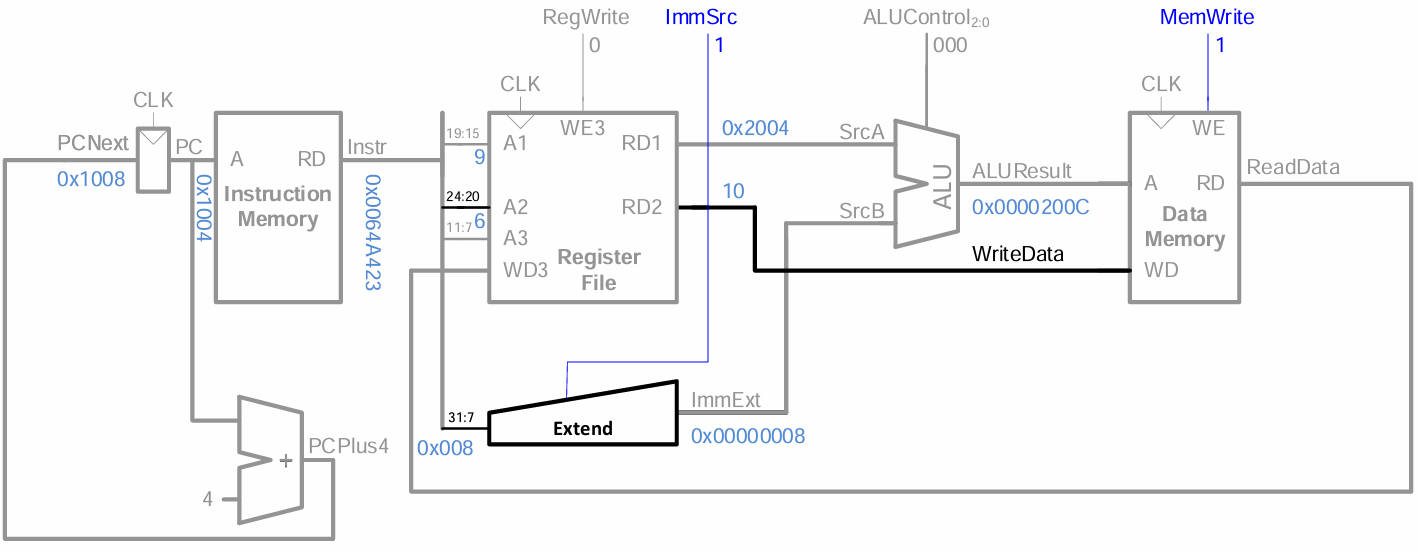
sw fetch :

앞서 설계했던 datapath에서 rs2를 위한 path를 추가하고, memory write와 imm 인코딩을 위한 control signal을 추가한다.
R-type fetch :

R-type 명령들은 rs1과 rs2에서 값을 읽어 rd에 값을 쓴다.
메모리를 거치지 않기 때문에 추가적인 path가 필요하다.
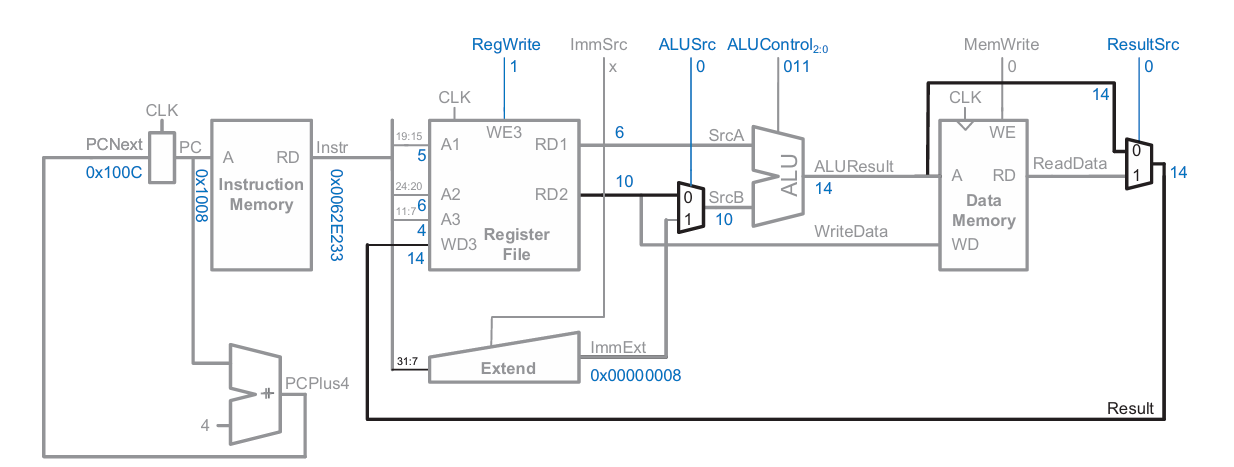
beq fetch :

조건 판별을 위한 block과 별도의 PCNext 계산 path가 필요하다.
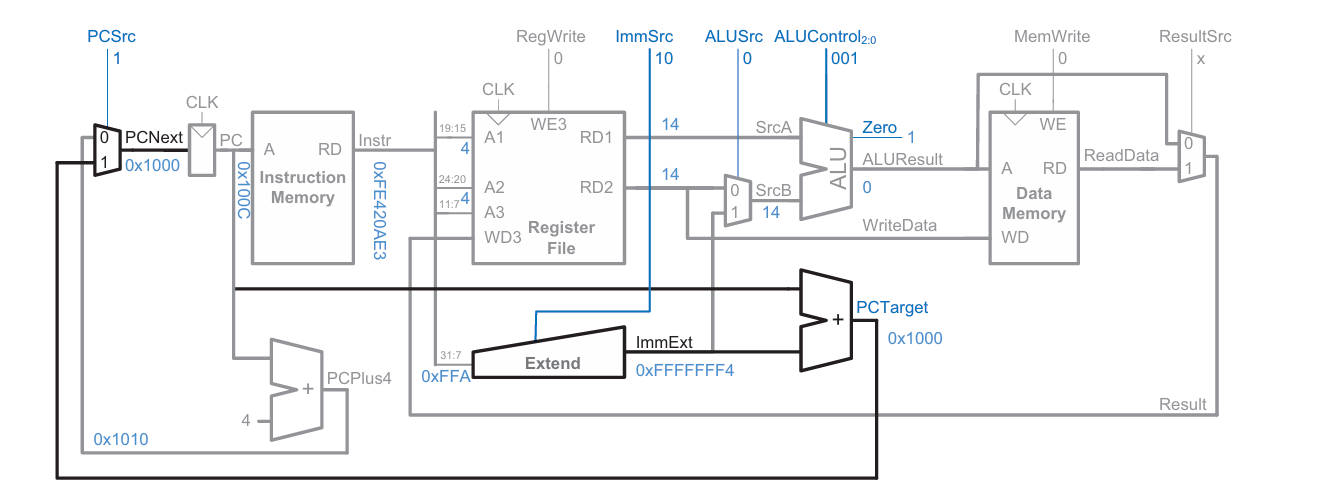
위 datapath에서 ImmSrc encoding은 다음과 같다.

이제 이 datapath에 control unit을 연결하면 간단한 single-cycle 프로세서가 설계된다.
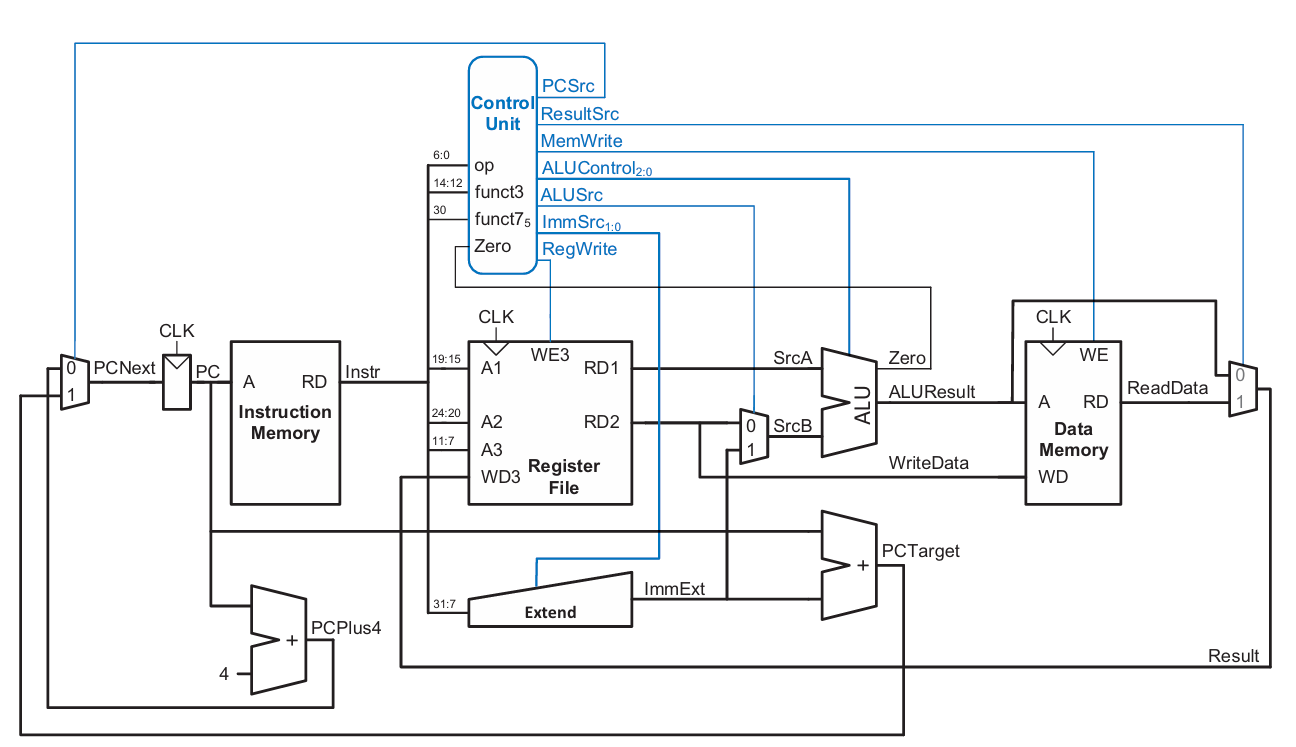
Control Unit 설계
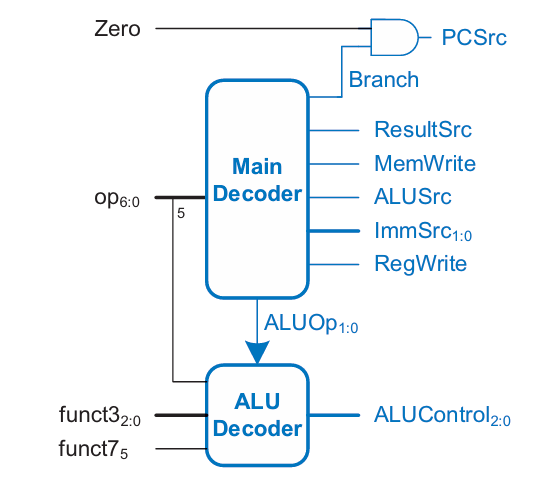
위 프로세서의 Control unit은 위와 같은 구조를 가지고 있고, 인코딩 방식은 아래를 따른다.
- RegWrite
| signal | control |
|---|---|
| 0 | 레지스터에 값 안씀 |
| 1 | 레지스터에 값 씀 |
- ImmSrc
| signal | control |
|---|---|
| 00 | I-Type |
| 01 | S-Type |
| 10 | B-Type |
- ALUSrc
| signal | control |
|---|---|
| 0 | 레지스터 값을 src로 씀 |
| 1 | imm 값을 src로 씀 |
- MemWrite
| signal | control |
|---|---|
| 0 | 메모리에 값 안씀 |
| 1 | 메모리에 값 씀 |
- ResultSrc
| signal | control |
|---|---|
| 0 | 결과에 메모리 값 안씀 |
| 1 | 결과에 메모리 값 씀 |
- Branch
| signal | control |
|---|---|
| 0 | 분기 안됨 -> PC+4 사용 |
| 1 | 분기 됨 -> PC+imm 사용 |
- ALUControl
| signal | control |
|---|---|
| 000 | add |
| 001 | subtract |
| 010 | and |
| 011 | or |
| 101 | SLT |
ALUControl은 ALUOp와 funct3, funct7에 의해서 결정된다.
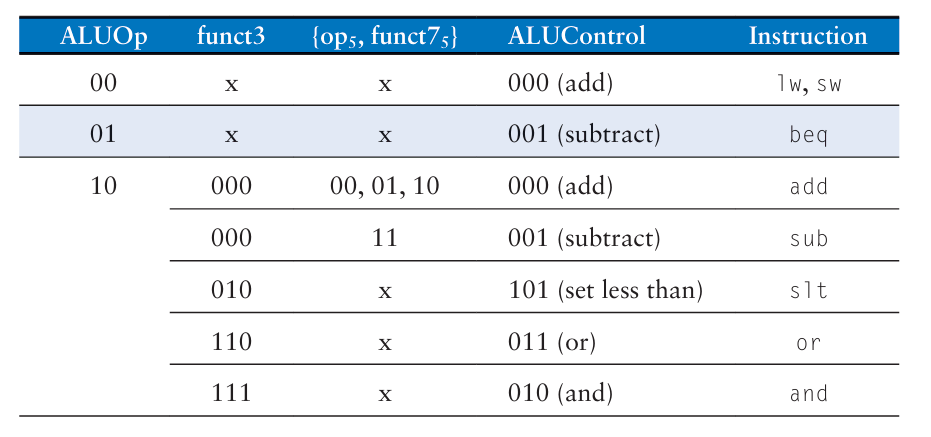
위 encoding table들을 이용한 명령별 decoding 결과는 다음과 같다.
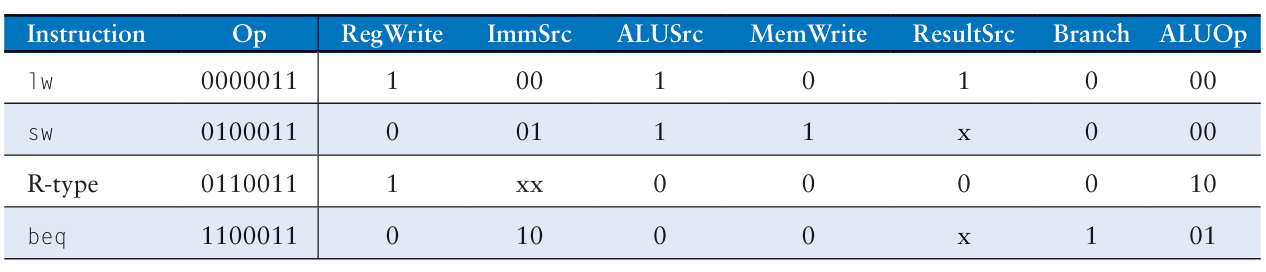
lw는 I-type이고(ImmSrc=00) rs1의 값과 imm 값을 더하여(ALUSrc=1, ALUOp=00, ALUControl=000) 메모리 주소를 구한 후 메모리의 값을 결과(ResultSrc=1)로 레지스터에 써야(RegWrite=1)한다. 분기는 일어나지 않는다(Branch=0).
sw는 S-type이고(ImmSrc=01) rs1의 값과 imm 값을 더하여(ALUSrc=1, ALUOp=00, ALUControl=000) 메모리 주소를 구한 후 rs2의 값을 메모리에 쓰고(MemWrite=1) 동작이 끝나기 때문에 Result는 don't care(ResultSrc=x)다. 분기는 일어나지 않는다(Branch=0).
R-type 명령어는 imm 필드가 없고(ImmSrc=xx, don't care) rs1값과 rs2값을 이용해 ALU 연산을 수행(ALUSrc=0, ALUOp=10)한 후 그 결과를 메모리를 거치지 않고(ResultSrc=0, MemWrite=0) rd에 저장(RegWrite=1)한다. 분기는 일어나지 않는다(Branch=0).
beq는 B-type이고(ImmSrc=10), rs1과 rs2 값을 빼서(ALUSrc=0, ALUOp=01, ALUControl=001) 결과를 zero와 비교하여(Branch=1) 조건에 맞을 경우 PCNext를 PC+imm으로 설정한다.
프로세서 확장
I-type ALU fetch :
addi, andi같은 ALU 연산을 추가한다.
R-type 명령과 비슷하게 처리되지만 ALUSrc와 ImmSrc에서 차이가 난다.
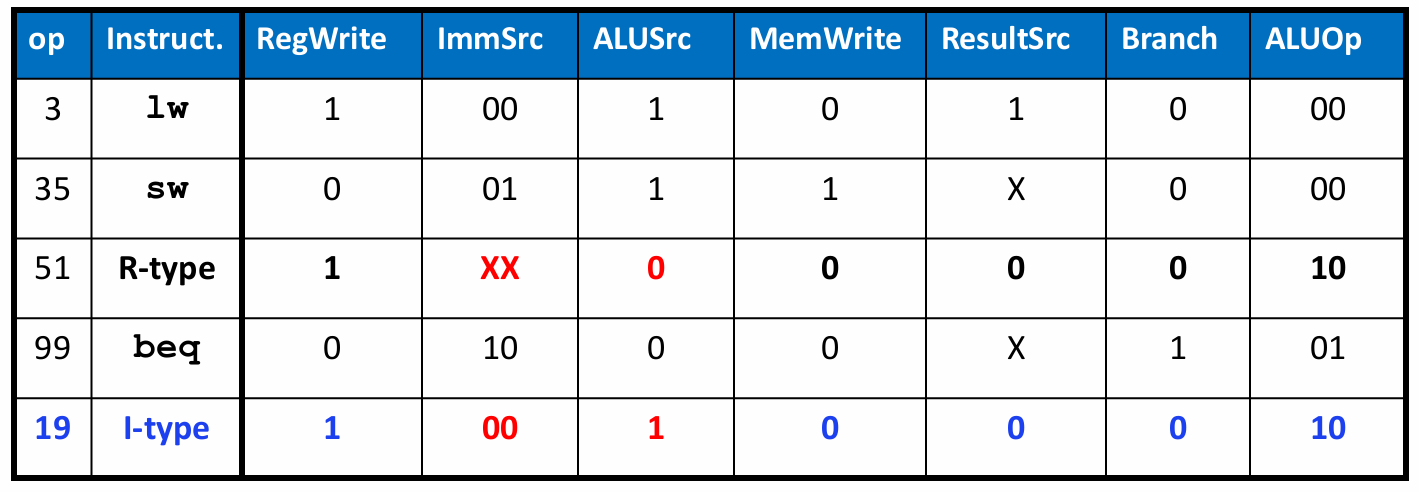
위 표를 보면 R-type에서는 don't care이던 ImmSrc signal이 00이고, ALUSrc를 1로 주어 ALU 연산 소스를 imm으로 바꾸었다. 이후에는 동일하다.
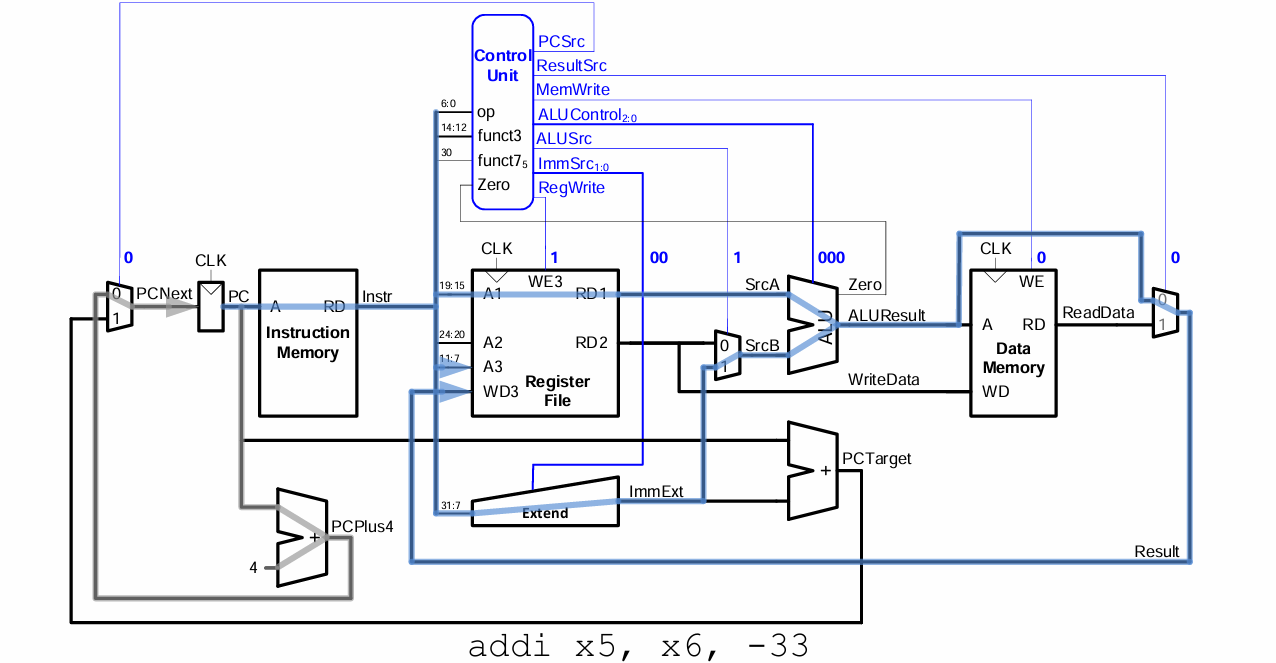
datapath의 흐름을 보면 이렇다.
jal(무조건 jump) fetch :
J-type 명령의 immediate를 인코딩하기 위해 ImmSrc를 추가해야 한다.

또한 jal명령은 jump하기 전에 PC+4를 계산하여 rd 레지스터에 저장을 해야한다. 따라서 result mux 역시 수정이 필요하다.
정리하면 아래와 같다.
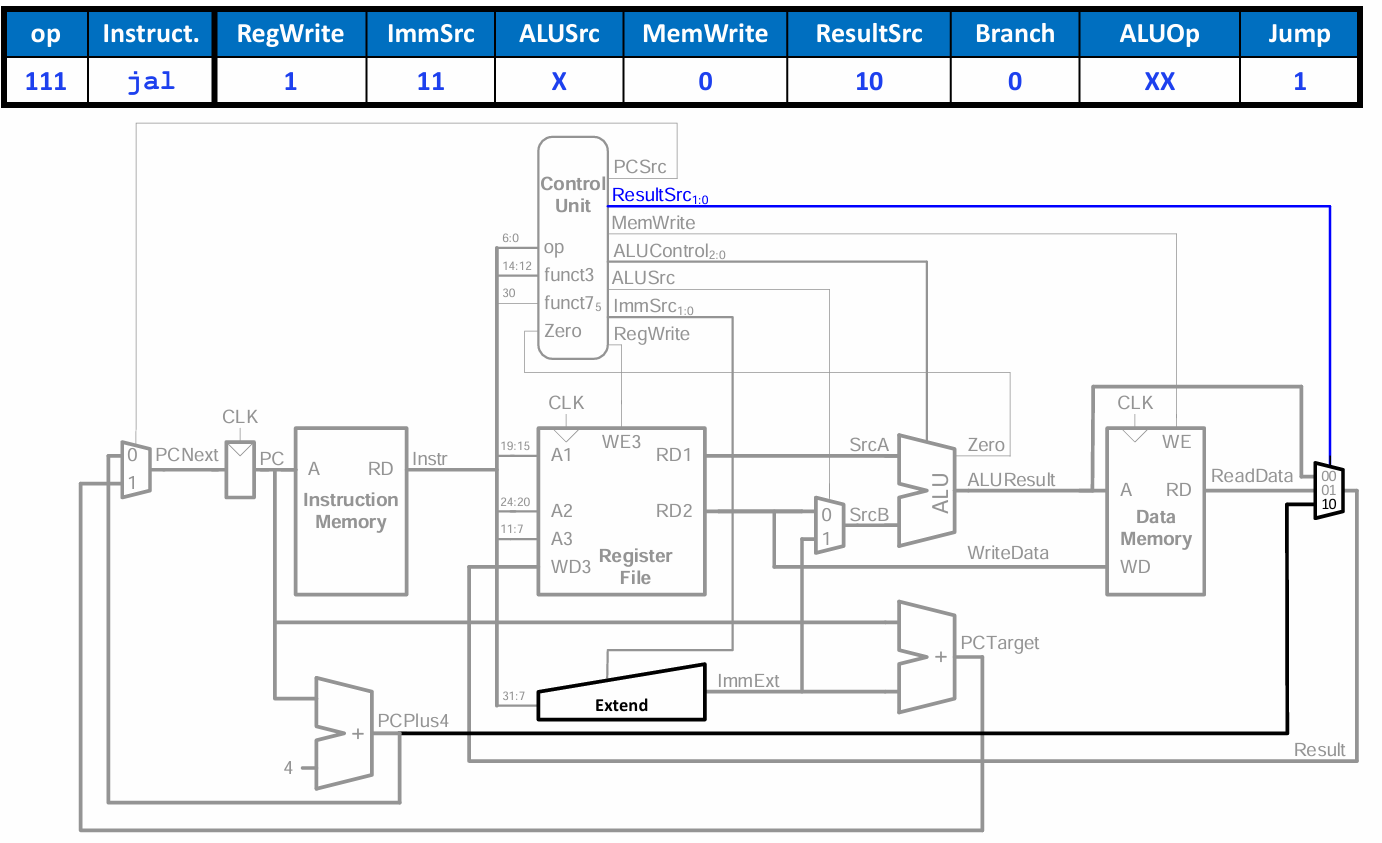
RegWrite : rd에 PC+4 저장 (1)
ImmSrc : J-type 인코딩 설정 (11)
ALUSrc : ALU 사용하지 않음 (don't care)
MemWrite : 메모리 사용하지 않음 (0)
ResultSrc : PC+4를 결과로 전달 (10)
Branch : 조건 확인 없음 (0)
ALUOp : ALU 사용하지 않음 (don't care)
Jump : jump 함 (1)
Single-Cycle Performance
프로세서의 성능은 프로그램 실행 시간으로 평가한다.
Program Execution Time
= (#instructions)(cycles/instruction)(seconds/cycle)
= # instructions × CPI ×
single-cycle에서 는 critical path에 의해 정해지는데, 위 프로세서에서 critical path는 lw이다.
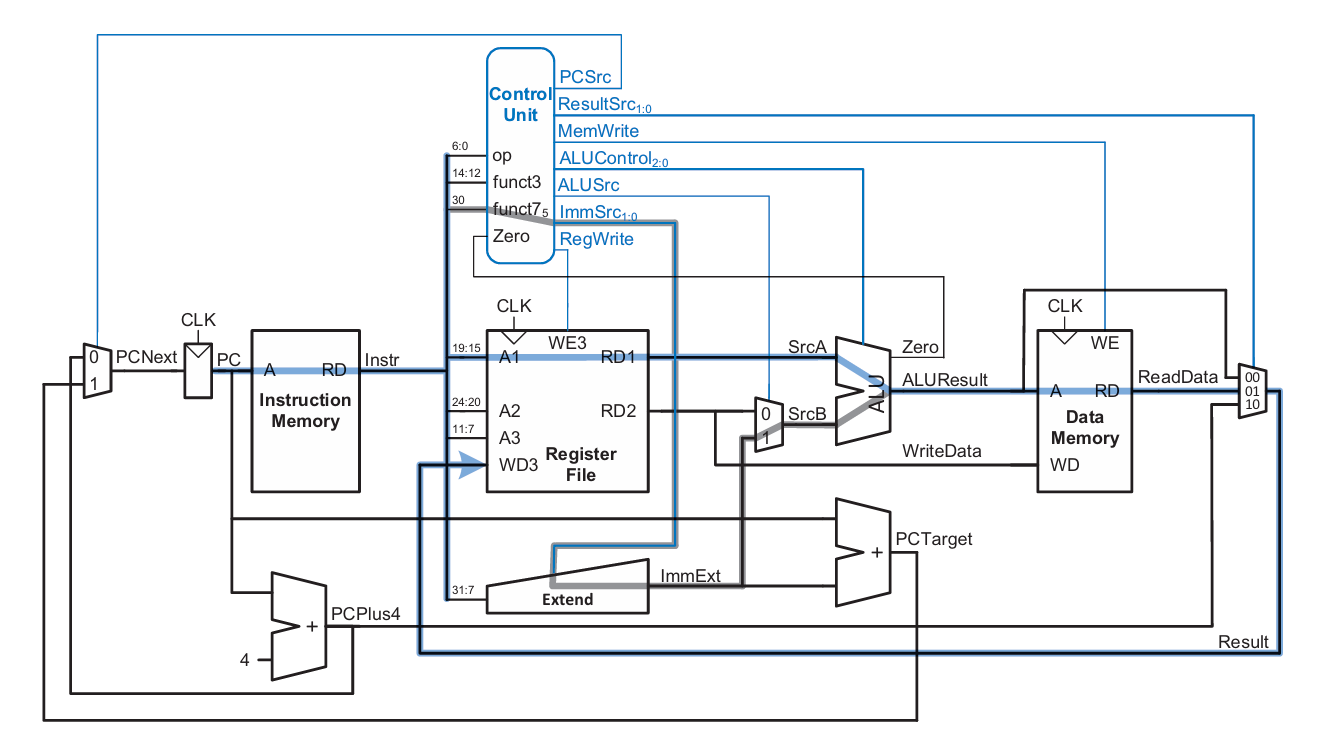
lw가 한번 수행되는데 걸리는 시간은 다음과 같이 계산된다.
그리고 보통 (imm를 ALU 연산에 쓰는 케이스)보다 (레지스터 값을 쓰는 케이스)가 더 오래걸리므로
이다.
각 속도가 다음과 같다면
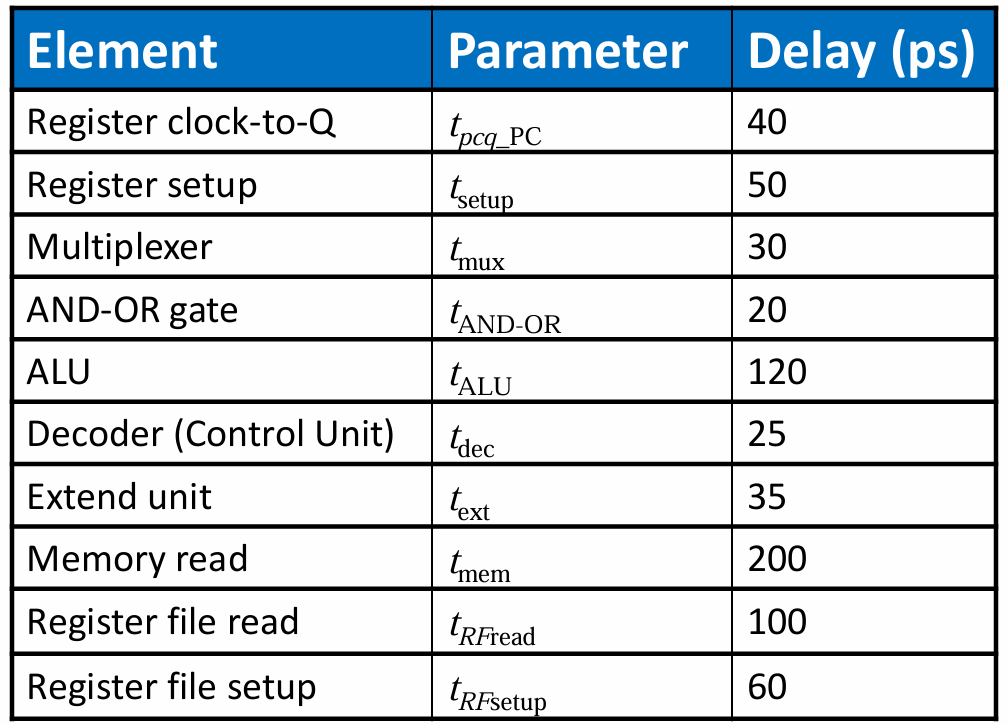
만약 프로그램이 1000억(100 billions)개라고 하면
Execution Time
= # instructions × CPI ×
=
= 75 seconds
<참고자료>
Harris & Harris, Digital Design and Computer Architecture, RISC-V Edition, 2022.
