Titanic Data로 생존자 예측을 위한 EDA
DataSet : Titanic(kaggle)
- Jupyter notebook 활용
- Python 활용
1. Setting
# 분석에 필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
2. 데이터 불러오기
# train.csv 파일 불러오기
titanic = pd.read_csv('./data/titanic/train.csv')
3. 데이터 확인
머신러닝을 위한 EDA할 때 무조건 확인 해야 하는 3가지 🌟🌟🌟
1) 결측치가 존재여부 확인titanic[titanic.isnull().any(axis=1)]
2) dtype이 object인 column이 있는지 여부 확인
- 있다면, 버리거나 변환해야 하기 때문
# 방법 1 titanic.info() # 방법 2 titanic.columns[titanic.dtypes == 'object'] # 많이 쓴다 🌟🌟🌟
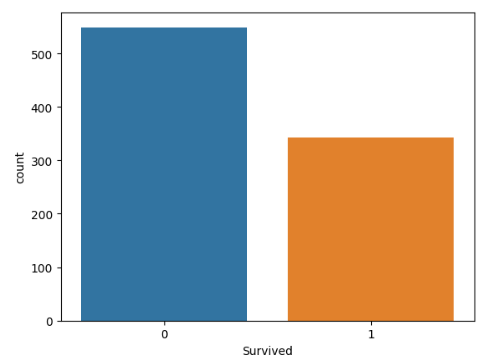
3) target value(예측 값)의 distribution 확인titanic['Survived'].value_counts() sns.countplot(data=titanic, x='Survived', palette='Set3')
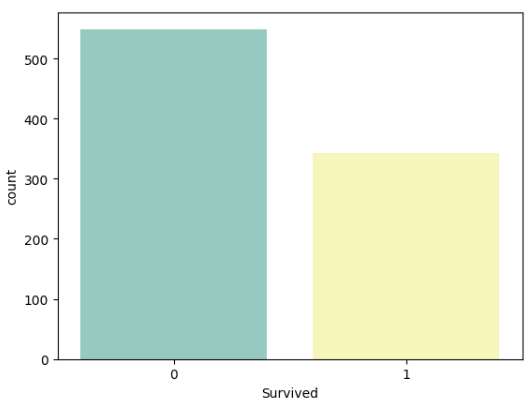
위 3개 외에도 자주 확인하는 것은 아래와 같다.
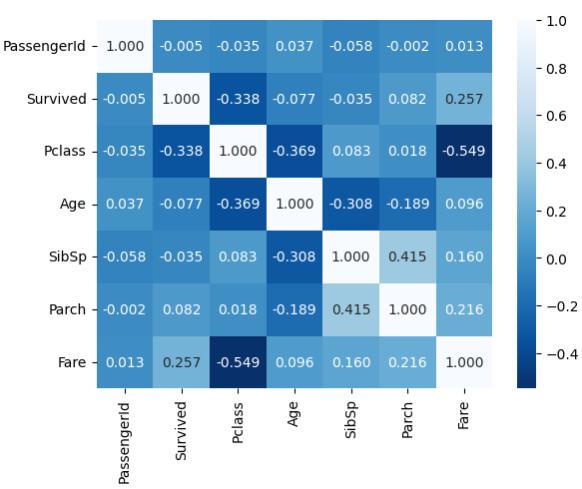
4) correlation matrix heatmap
sns.heatmap(data=titanic.corr(), annot=True, fmt='.3f', cmap='Blues_r')
4. 결측치에 대한 EDA
# Cabin columns에 대한 분석
cond1 = titanic['Cabin'].isnull()
print(len(titanic[cond1])) # 687
print(len(titanic[~cond1])) # 204Cabin의 경우, 많은 데이터가 비어 있어 컬럼 자체를 삭제하기로 결정한다.
그러나 다른 특성을 뽑아 낼 수 있을지 보기 위해 추가 분석을 진행한다.
# Cabin column이 nan이 아닌 데이터들
cabin = titanic[~cond1]
# Cabin column이 nan인 데이터들
cabin_nan = titanic[cond1]
display(cabin.describe()) # display on jupyter notebook
display(cabin_nan.describe())
Cabin 값이 존재하면 생존률이 높은 경향을 보인다.
새로운 feature인 is_cabin(결측치인지 아닌지 여부)을 만들기로 결정한다.
5. 전처리
1) 결측치에 대한 전처리
- 'is_cabin' column 추가(0 또는 1)
- 'Age'의 결측값 : Age의 평균값으로 대체
- 'Embarked' 결측치 있는 행 삭제(2개)
2) 예측에 불필요한 columns 삭제
- 'PassengerId', 'Name', 'Ticket', 'Cabin' columns 삭제
3) dtype이 object인 columns에 대한 전처리 : Ordinal Encoding(숫자로 변환)
- Ordinal Encoding : 주어져 있는 문자열들을 순서대로 수치 값으로 변환
'is_cabin' column 추가
titanic['is_cabin'] = ~titanic['Cabin'].isnull() * 1
# titanic['is_cabin'] = titanic['Cabin'].mask(cond1, 0).mask(~cond1, 1) # 위와 동일
# 'Age'의 결측값을 Age의 평균값으로 대체
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].mean())
예측에 불필요한 columns 삭제
titanic = titanic.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'])
# 'Embarked' 결측치 있는 행 삭제
titanic = titanic.dropna()
titanic
# Ordinal Encoding
titanic['Sex'] = pd.factorize(titanic['Sex'])[0]
titanic['Embarked'] = pd.factorize(titanic['Embarked'])[0]
6. Machine Learing 간단하게 돌려보기
from sklearn.linear_model import LogisticRegression
X = titanic.drop(columns=['Survived']) # define feature vector
y = titanic['Survived'] # define target value
clf = LogisticRegression() # define model
clf.fit(X, y) # fitting(=training)
clf.score(X, y) # Get Accuracy(=정확도;맞은 개수의 비율) # 0.80427
7. [추가] 데이터 분석 시각화
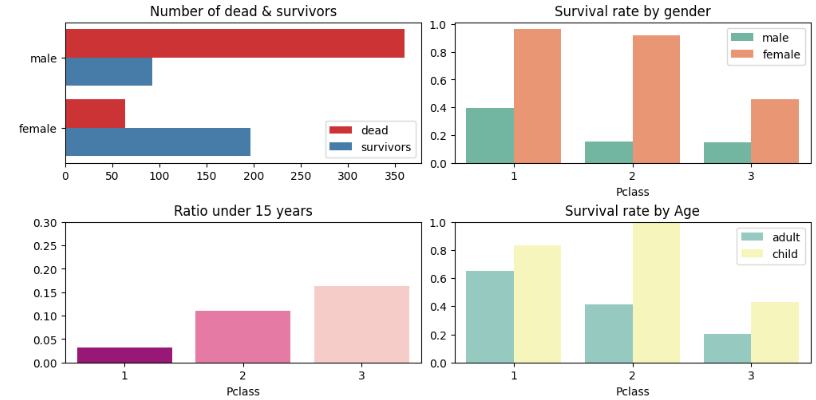
# 타이타닉 생존 분석 결과
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(10, 5), constrained_layout=True)
# 생존자/사망자 수 그래프
sns.countplot(data=df_ex3, y='Sex', hue='Survived', palette='Set1', ax=ax[0][0])
ax[0][0].legend(title='', labels=['dead', 'survivors'])
ax[0][0].set(xlabel='', ylabel='', title='Number of dead & survivors')
# 성별에 따른 생존율 그래프
sns.barplot(data=df_ex3, x='Pclass', y='Survived', hue='Sex', palette='Set2', ax=ax[0][1], ci=False)
ax[0][1].legend(title='')
ax[0][1].set(ylabel='', title='Survival rate by gender')
# 15세 이하의 비율 그래프
sns.barplot(data=df_ex3, x='Pclass', y='Age', palette='RdPu_r', ax=ax[1][0], ci=False, estimator=lambda x: (x <= 15).mean())
ax[1][0].set(ylim=(0, 0.3), ylabel='', title='Ratio under 15 years')
# 아이와 어른의 생존율 비교 그래프
sns.barplot(data=df_ex3, x='Pclass', y='Survived', palette='Set3', hue='A or C', ax=ax[1][1], ci=False)
ax[1][1].set(ylim=(0, 1), ylabel='', title='Survival rate by Age')
ax[1][1].legend(title='', loc='upper right')