1. Pandas란
- 정형 데이터 분석에 최적화된 Python 라이브러리
2. DataFrame 및 Series
- DataFrame : pandas의 2차원 표 형식 데이터(index, columns, values로 구성)
- Series : pandas의 1차원 표 형식 데이터(index, values로 구성)
3. Pandas 사용방법
1) 설치
!pip install pandas==1.5.32) 불러오기
import pandas as pd3) 버전 확인
pd.__version__
4. DataFrame 및 Series 생성
1) pd.DataFrame(2차원 리스트) / pd.Series(1차원 리스트)
pd.Series([90, 80], index=['Julie', 'Tom'])2) pd.DataFrame(2차원 numpy array) / pd.Series(1차원 numpy array)
# 12x4 행렬에 1부터 48까지의 숫자를 원소를 가지고,
# index는 2023-08-01부터 시작하고,
# coulmns은 순서대로 X1, X2, X3, X4로 하는 DataFrame 생성
df = pd.DataFrame(data=np.arange(1, 49).reshape(12, 4),
index=pd.date_range(start='20230801',
end='20230812', freq='D'),
columns=["X1", "X2", "X3", "X4"])3) pd.DataFrame(Series 담고 있는 리스트)
4) pd.DataFrame(파이썬 dictionary)
-
DataFrame의 경우
- key : columns명
- value : columns의 값 담은 리스트 또는 numpy array 또는 seriesdict_data = {'name':['Tom', 'Julie'], 'score':[50, 80]} df = pd.DataFrame(dict_data) -
Series의 경우
- key : index
- value : index에 매칭되는 데이터 값dict_data = {'a':1,'b':2,'c':3} series_data = pd.Series(dict_data)
5) pd.DataFrame(dictionary 담긴 리스트)
list1 = [{'name':'Tom', 'score':50}, {'name':'Julie', 'score':80}]
5. Pandas 데이터 입출력
- 데이터 입출력 함수
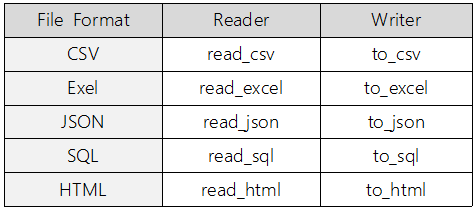
- [pandas] read_csv
: csv파일을 데이터프레임으로 불러오는 함수
- filepath_or_buffer
: 파일의 경로명
- sep (인수는 문자열 / 기본값은 ',')
: 구분자를 지정하는 인자
- header (인수는 정수, 정수의 리스트 / 기본값은 'infer')
: columns를 지정하는 인자지정하지 않으면 대부분 맨 윗줄이 columns가 된다.(기본 값이 0인것과 비슷하다) 리스트로 지정하면 멀티 인덱스인 columns가 된다.
- index_col (인수는 정수, 정수의 리스트 / 기본값은 None)
: index를 지정하는 인자지정하지 않으면 RangeIndex가 index로 부여된다. 리스트로 지정하면 멀티 인덱스인 index가 된다.
- nrows(인수는 정수, 기본값은 전부)
: 불러오는 행의 수를 지정하는 인자
- usecols(인자는 컬러몀을 담은 리스트)
: 불러오는 컬럼명을 지정하는 인자pd.read_csv('test.csv', header=None, index_col=0) # csv파일 불러와 DataFrame 리턴 df.to_csv('titanic.csv') # DataFrame을 csv 파일로 저장
🔥 TIP) 대용량 데이터 불러오기
# 1. nrows 매개변수를 활용하여 일부의 데이터만 불어와 필요한 컬럼 확인 pd.read_csv(url, nrows=2) # 2. usecols 매개변수를 활용하여 필요한 컬럼만 불어와 사용하기 pd.read_csv(url, usecols=['title', 'author'])
- [pandas] read_excel
: 엑셀파일을 데이터프레임으로 불러오는 함수
- io
: 파일의 경로명
- sheet_name(인수는 문자열, 정수, 리스트 / 기본값은 0)
: 불러 올 시트 지정하는 인자예) - 지정하지 않을 때: 첫번째 시트를 불러온다 - 1: 2번째 시트를 불러온다 - "Sheet1": 문자열을 입력하면 해당 이름을 가진 시트를 불러온다. 여기서는 "Sheet1"이라는 이름의 시트를 불러온다 - [0, 1, "Sheet5"]: 첫번째 시트와 두번째 시트 그리고 "Sheet5"라는 이름의 시트 세개를 딕셔너리로 통합해 가져온다. - None: 모든 시트를 딕셔너리로 통합해 가져온다.
- header (인수는 정수, 정수의 리스트 / 기본값은 0)
: columns를 지정하는 인자. 지정하지 않으면 맨 윗줄이 columns가 된다. 리스트로 지정하면 멀티 인덱스인 columns가 된다.
- index_col (인수는 정수, 정수의 리스트 / 기본값은 None)
: index를 지정하는 인자지정하지 않으면 RangeIndex가 index로 부여된다. 리스트로 지정하면 멀티 인덱스인 index가 된다.pd.read_excel(url, sheet_name=3, header=2, index_col=0)
- [pandas] read_html
: 웹페이지의 테이블을 데이터프레임으로 불러오는 함수
(리스트에 데이터프레임을 담아준다)
- io
: 웹페이지의 경로명
- match (인수는 문자열 혹은 정규표현식 / 기본값은 ‘.+’ )
: 테이블 중에서 특정 문자열을 포함한 테이블을 지정하는 인자.
(기본값은 빈 문자열을 제외한 모든 문자열이다.)
(지정하지 않으면 문자열이 포함된 모든 테이블을 가져온다)
- header (인수는 정수, 정수의 리스트 / 기본값은 None)
: columns를 지정하는 인자
(리스트로 지정하면 멀티 인덱스인 columns가 된다.)
- index_col (인수는 정수, 정수의 리스트 / 기본값은 None)
: index를 지정하는 인자
(지정하지 않으면 RangeIndex가 index로 부여된다)
(리스트로 지정하면 멀티 인덱스인 index가 된다)# 소수점 세자리까지 출력옵션 pd.options.display.float_format = '{:.2f}'.format # 해당 웹사이트의 모든 표를 데이터프레임으로 만들어 리스트에 담아준다 dfs = pd.read_html(url)
6. Pandas 데이터 내용 확인
df.head() # 데이터의 상단 5개 행 출력
df.tail() # 데이터의 하단 5개 행 출력
df.shape # 행, 열 크기 확인
df.info() # 데이터에 대한 전반적인 정보
# 행과 열 크기, 컬럼명, 컬럼별 결측치, 컬럼별 데이터 타입
type(df) # 데이터 타입 확인 - pandas.core.frame.DataFrame
df.columns # 칼럼명 확인
df.index # DataFrame 인덱스 확인
s.index # Series 인덱스 확인
df.values # 데이터 확인(Numpy array return)
s.values # Series 데이터 확인
df.dtypes # 각 칼럼마다의 데이터 타입 확인
df['Name'].unique() # 열(Series)의 고유값들 반환
# 각 학점당 개수 그래프(간단 그래프)
df['학점'].value_counts().sort_index(ascending=False).plot(kind='bar')
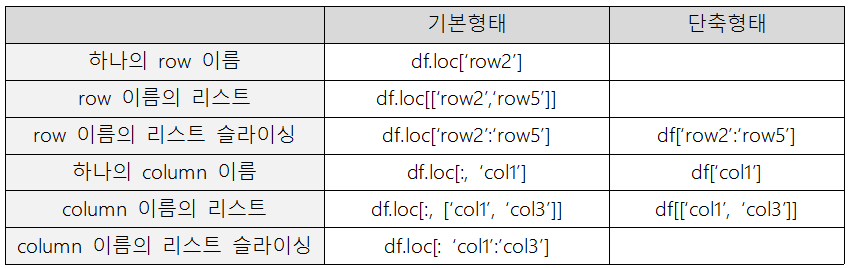
7. Pandas 인덱싱/슬라이싱
1) 이름으로 인덱싱
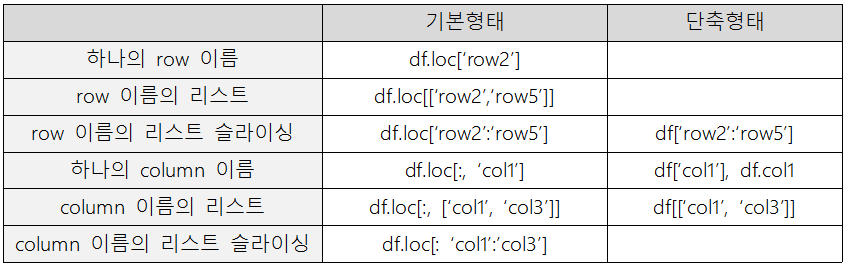
df['Name'] # Series 리턴
df[['Name']] # DataFrame 리턴
df.loc[df["Age"] > 35, ["Name", "Age"]] # 나이 35세 초과한 사람의 이름, 나이 출력2) 위치로 인덱싱
df.iloc[[1,2,3], 0] = "No" # 1~3번째행, 0번째 열의 값을 "No"로 변경 df.iloc[1:4, 0] = "No" # 위와 동일
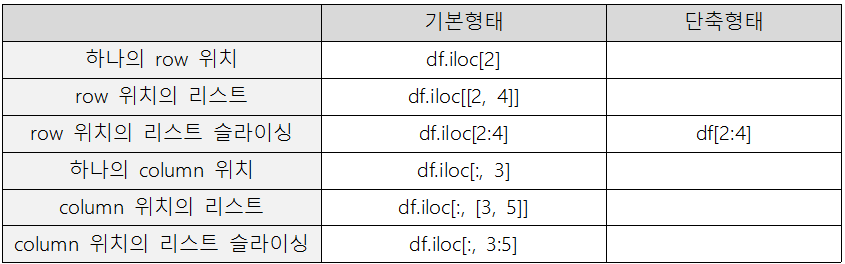
3) boolean 인덱싱
df.loc[(df['X1'] > 25) & (df['X1'] < df['X2']), df.loc['2023-08-12'] > 46]
df[(df['X1'] > 25) & (df['X1'] < df['X2'])] # row에 대한 조건만 가능
df.iloc[df.X2 > 20, 1] # iloc : boolean 인덱싱 불가
df[df['X2'].isin(np.arange(20, 41))] # X2 값 중 20~40 범위에 있는 데이터만 추출
df[df['X1'].isin([1]) # X1 값이 1인 데이터만 추출
df[df["X1"].isna()] # X1 값이 결측치인 데이터 추출
df[df['X1'].notna()] # X1 값이 결측치가 아닌 데이터 추출4) 다중요건 boolean 인덱싱
- 조건이 복수인 경우, 논리연산을 활용
- Pandas는 논리 연산 시, 반드시 논리연산자 사용 필수
- and의 논리 연산자 : &
- or의 논리 연산자 : |
- not의 논리 연산자 : ~🚩 인덱싱 정리
- 대괄호 인덱싱
- 레이블(이름)로 인덱싱
- 열만 인덱싱 가능
- 행만 슬라이싱 가능
- 행과 열 동시 적용 불가능
- loc 인덱싱
- 레이블(이름)로 인덱싱
- 행과 열 모두 인덱싱과 슬라이싱 가능
- 행과 열 동시에 적용 가능
- iloc 인덱싱
- 로케이션으로 인덱싱
- 행과 열 모두 인덱싱과 슬라이싱 가능
- 행과 열 동시에 적용 가능
- [pandas] filter
: 인덱스(index, columns)의 레이블로 데이터프레임이나 시리즈를 필터링하는 함수
- items
: 필터링때 정확하게 일치하는 문자열을 지정하는 인자
- like
: 필터링때 포함하는 문자열을 지정하는 인자
- regex (regular expression)
: 필터링때 정규 표현식을 지정하는 인자
- axis (0 or 1 / 기본값은 1)
: index를 필터링(axis=0)하는지, columns를 필터링(axis=1)하는지 결정하는 인자
# 레이블에 A가 포함되는 열 필터링
df.filter(like='A')
# 레이블이 A로 시작되는 열 필터링
df.filter(regex=r'^A')
# 레이블이 B 또는 C를 포함하는 열 필터링
df.filter(regex=r'B|C')
- 정규표현식
^ : 시작 $ : 끝 | : 또는
8. Pandas 결측치 제거
- [pandas] dropna
: 결측값(null)이 있는 열이나 행을 삭제하는 함수
- axis (인수는 0 or 1 / 기본값은 0)
:열을 삭제할 것인지 행을 삭제할 것인지 지정하는 인자기본값은 0이고 행을 삭제한다
- how (‘any’ or ‘all’ / 기본값은 ‘any’)
: NaN을 보유한 열이나 행을 어떻게 삭제할 것인지 결정하는 인자- ‘any’ : 하나라도 NaN이면 삭제(기본값) - ‘all’ : 모두 NaN인 열이나 행을 삭제- subset (열의 레이블): 삭제할 NaN이 있는 열을 결정하는 인자
df.dropna(axis=0, inplace=True) # 결측 값이 들어있는 행 전체 삭제
df.dropna(axis=1) # 결측 값이 들어있는 열 전체 삭제된 DataFrame 리턴
# 결측치를 하나라도 포함하고 있는 데이터가 확인
df.loc[df.isnull().any(axis=1)] 🌟🌟🌟
- [pandas] fillna
: 결측값 null(대표적으로 NaN)을 지정한 값으로 채우는 함수
- value (scalar, 딕셔너리, 시리즈, 데이터 프레임)
: NaN을 채울 값- scalar를 입력하면 동일한 값으로 채운다 - 딕셔너리나 시리즈를 입력하면 key에 맞는 열마다 다른 값을 채운다 - 데이터 프레임은 인덱스가 동일한 값을 채운다
- method (인수는 ‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None / 기본값은 None)
: 근접한 값으로 NaN을 채울 때 사용하는 인자- ffill / pad : 이전 값으로 채운다 - bfill / backfill: 이후의 값으로 채운다
- axis (인수는 0 또는 1 / 기본값은 0)
: method로 근접한 값을 채울 때 축을 지정하는 인자0이면 열에서 근접한 값을 채운다
9. Pandas 데이터 통계
🔥 TIP) 작은 데이터로 실습 후 큰 데이터에 적용해 볼 것!!!
- 처음부터 빅데이터에 적용하는 것 비추!!
- 집계함수(aggregate function)
- 그룹의 값을 하나로 리턴해주는 차원 축소 함수가 넓은 의미에서 모두 집계 함수(각종 통계 함수)
- [pandas] value_counts
: 데이터 프레임이나 시리즈의 고유값의 개수를 파악하는 함수# Series 적용 예시 s.value_counts(normalize=False, sort=True, ascending=False)
- normalize (인수는 bool / 기본값은 False)True일때는 표준화해서 비율로 보여준다
- sort (인수는 bool / 기본값은 True)
: 빈도에 따라 정렬할지 여부 지정하는 인자
- ascending (인수는 bool / 기본값은 False)
: 정렬 방식을 결정하는 인자(기본값은 내림차순)
# DataFrame 적용 예시 df.value_counts(subset=None, normalize=False, sort=True, ascending=False)
- subset (인수는 레이블 또는 레이블 담은 리스트/ 기본값은 None)
: 고유값의 개수를 파악할 열을 지정하는 인자그 외 인자는 시리즈에 적용할 때와 동일하다# 데이터프레임에 value_counts 함수를 적용해 col1과 col2의 조합 파악 df.value_counts(['col1', 'col2']) # subset에 모든 열을 담는다면 기본값으로도 가능 df.value_counts()
df.sum() # 각 열의 합(행 기준 합)
df.sum(axis=1) # 각 행의 합(열 기준 합)
df.cumsum() # 행 기준 누적합
df.mean() # 각 열의 평균(행 기준 평균)
df["Age"].mean() # Age 칼럼의 평균
df["Age"].median() # Age 칼럼의 중앙값
df.describe() # 숫자 컬럼들의 통계 정보(count, mean, std, min, max, 4분위수)
df['Pclass'].value_counts() # 값의 개수
# agg()를 통해 여러 개의 열에 다양한 함수를 적용
# 각 열마다 다른 함수를 매핑 : group객체.agg({‘열1’: 함수1, ‘열2’: 함수2, …})
df.agg({'Age':['min', 'max'],'Fare':['mean', 'median']})
# 모든 열에 여러 함수를 매핑 : group객체.agg([함수1, 함수2, 함수3,…])
df.agg(['mean', 'max'])
- [pandas] pivot_table
: 원시(raw) 데이터를 피벗 테이블로 바꾸는 함수
- Pivot Table
: 기존 테이블 구조를 특정 column을 기준으로 재구조화한 테이블
(주로 어떤 column을 기준으로 데이터를 해석하고 싶을 때 사용)
- values
: 집계할 대상 열
- index (열, 또는 grouper)
: 피벗 테이블의 index로 구분될 특성(열)
- columns (열, 또는 grouper)
: 피벗 테이블의 columns로 구분될 특성(열)
- aggfunc (집계 함수)
: 그룹의 차원을 축소시킬 함수(기본값은 'mean')
# 사회 계급 및 성별을 기준으로 생존률 파악
pd.pivot_table(data=titanic, index=['Pclass', 'Sex'], values='Survived', aggfunc=['count', 'sum', 'mean'])# 반 / 성별과 비고로 나눠서 인원수 구하기
df.pivot_table('점수', index='반', columns=['성별', '비고'], aggfunc='count')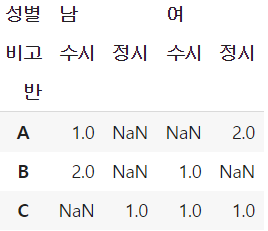
# 반과 성별로 나누어 평균점수와 인원수 동시에 구하기
df.pivot_table('점수', index='반', columns='성별', aggfunc=['mean', 'count'])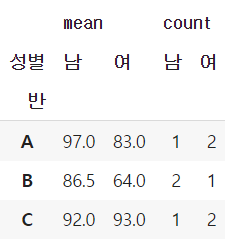
- [pandas] pivot
: 원시(raw) 데이터를 피벗 테이블로 바꾸는 함수
- index (열, 또는 grouper)
: 피벗 테이블의 index로 구분될 특성(열)
- columns (열, 또는 grouper)
: 피벗 테이블의 columns로 구분될 특성(열)
- values
: 집계할 대상 열
# pivot 함수는 집계함수가 필요 없으므로 문자열을 피벗팅하기에 편리하다
df.pivot(values='이름', index='반', columns='반등수')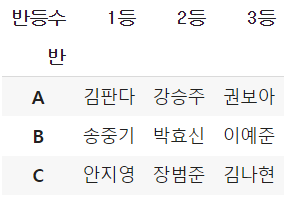
- 피벗테이블에 lambda함수 적용 🌟🌟🌟
# 선실 등급별 최고령자 이름의 피벗테이블로 만들기 df.pivot_table('Age', index='Pclass', columns='Sex', aggfunc=lambda x: df .loc[x.idxmax(), 'Name'])
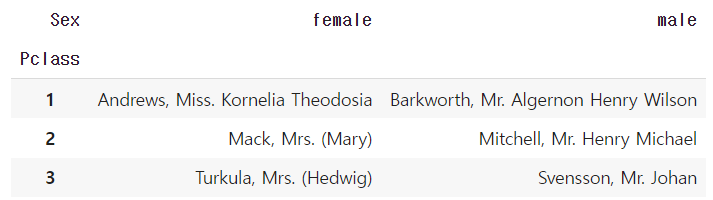
- [pandas] groupby 🌟🌟🌟🌟🌟
: 그룹 내에서 함수를 적용하게 해주는 함수
- by
: 그룹을 나누는 기준(복수라면 리스트로 입력)
- axis (0 or 1)
: 그룹해서 함수를 행에 적용할 것인지 열에 적용할 것인지 지정하는 인자(기본값은 열)
- level
: 인덱스로 그룹을 나눌 때 사용하는 인자
- as_index (bool / 기본값은 True)
: groupby로 집계 함수를 사용할 때 그룹이 인덱스가 될지 지정하는 인자
- sort (bool / 기본값은 True)
: 그룹의 key로 정렬을 할 것인지 지정하는 인자# data도 복수로 지정이 가능 (사실 data는 대괄호 인덱싱) df.groupby(['반', '성별'])[['국어', '수학']].mean() # 성별과 클래스로 그룹 나눠 나이와 요금의 평균 구하기 df.groupby(["Sex", "Pclass"])[['Age', 'Fare']].mean() # groupby를 통해 성별을 묶은 다음, 생존율의 평균 구하기 df.groupby("Sex")['Survived'].mean() # 인덱싱을 하지 않으면 전체에 적용한다 (단 by에 지정된 열은 제외) df.groupby(['반', '성별']).mean() # 반으로 그룹화 해서 rank 함수 적용하기 df['학급내등수'] = df.groupby('반')['점수'].rank(ascending=False) # 반과 성별로 그룹화 해서 rank 함수 적용하기 df['등수2'] = df.groupby(['반', '성별'])['점수'].rank(ascending=False)
# 적용할 함수로 집계함수 적용하기 df.groupby(['반', '성별'])['점수'].mean()
# groupby로 shift 함수 적용하기 df2['전일입금'] = df2.groupby('이름')['입금'].shift()
- 집계함수가 아닐때 : 기존 열의 index를 그대로 유지한 시리즈 반환
- 집계함수일 때 : index가 없어지고 그룹을 나누는 key가 새로운 index가 된다
- agg의 장점
- agg 와 리스트를 이용하면 튜플로 집계 결과의 열이름을 바꿀 수 있다(set_axis등으로 손쉽게 가능) - 복수의 집계함수 사용가능(pivot_table로도 가능) - 열마다 다른 집계함수 사용가능(pivot_table로도 가능) - lambda 함수 사용가능(pivot_table로도 가능)# 함수를 튜플로 입력해 열 이름을 바꿀 수 있다 df.groupby(['반'])['국어'].agg([('국어평균', 'mean')]) # 복수의 집계함수 적용 df.groupby(['반'])['국어'].agg(['mean', 'std']) # 위 결과는 피벗 테이블로도 가능하다 df.pivot_table('국어', index='반', aggfunc=['mean', 'max']).droplevel(1, axis=1) # 복수의 집계함수 일 때도 열 이름을 바꿀 수 있다 df.groupby(['반'])['국어'].agg([('국어평균', 'mean'), ('표준편차','max')]) # 열마다 다른 집계함수 적용 df.groupby(['반']).agg({'국어': 'mean', '수학': 'count'}) # 열마다 다른 집계함수 적용(pivot_table로도 가능) df.pivot_table(['국어', '수학'], index='반', aggfunc={'국어':'mean', '수학':'count'}) # lambda 함수도 사용 가능하다. 반별 수학 점수가 90 이상인 인원수 df.groupby(['반'])['수학'].agg(lambda x: (x > 80).sum()) # lambda 함수도 사용 가능하다. 반별 수학 점수가 90 이상인 인원수(pivot_table로도 가능) df.pivot_table('수학', index='반', aggfunc=lambda x: (x > 80).sum())
- transform의 장점
- transform과 집계함수를 이용해 집계 결과를 열로 만들수 있다 - 열로 만들수 있으므로 집계 결과로 불리언 인덱싱도 할 수 있다# transform은 집계함수의 적용 결과를 원본 df와 같은 길이의 시리즈로 반환한다 df.groupby('반')['수학'].transform('mean') # 반평균보다 점수가 높은 학생들의 데이터만 필터링 cond1 = df['수학'] > df.groupby('반')['수학'].transform('mean') df[cond1]
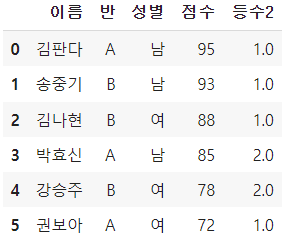
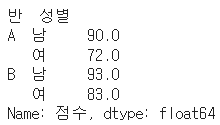
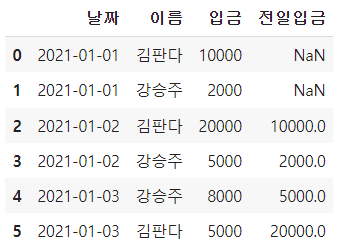
10. Pandas 행/열 추가 및 삭제
df.loc['Tommy'] = new_row # 행 추가
df['Region'] = df['Address'].split()[0] # 열 추가
df['Region'] = ['서울, '부산', '대구'] # 열 수정
df['Region'] = s1 # Series 배정
df[['과학', '사회']] = 'pass' # 복수의 열 한번에 추가
- [pandas] drop
: 데이터 프레임의 행이나 열을 삭제하는 함수
- labels (인수는 레이블 혹은 리스트)
: 드롭할 행의 레이블(이름)이나 열의 레이블복수라면 리스트로 묶어서 입력한다.
- axis (인수는 0 또는 1/기본값은 0)
: 삭제할 부분이 행인지 열인지를 지정하는 인자기본값은 0이고 행을 삭제한다
- level (멀티 인덱스의 레벨 / 기본값은 None)
: 멀티인덱스일 때 삭제할 레벨을 지정하는 인자# D열만 빼고 모두 가져오기 df.drop('D', axis=1) # 삭제가 더 편리 # 행은 나와 다 그리고 열은 C열만 빼고 다 가져오기 df.loc[['나', '다']].drop('C', axis=1) df.drop(np.arange(10, 20), axis=0) # 10~19행 삭제
11. [Pandas 함수] TIP
🔥 TIP) Pandas에서는 대부분의 함수 적용 결과가 원본을 덮어쓰지 않는다
- 덮어 쓰기 위한 방법 : inplace=True 사용 (또는) 기존 변수에 다시 지정
12. 문자열 다루는 Pandas 함수
- 특징
- str 접근자 사용
- 시리즈에만 적용 가능
- 대체로 기본값으로 정규표현식 사용 가능# A열의 문자열의 길이 df['A'].str.len() # df['A'].apply(len)와 결과 동일 # B열에서 각 셀마다 앞의 세글자만 슬라이싱 df['B'].str[:3] # df['B'].apply(lambda x: x[:3])와 결과 동일 # C열에서 각 셀마다 - 앞 부분을 가져오기 df['C'].str.split('-').str[0] # str 접근자 2번 사용 # df['C'].apply(lambda x: x.split('-')[0])와 결과 동일 # D열에서 cat 또는 dog 포함여부를 bool로 만들기 # 기본 설정이 정규 표현식이기 때문에 'r'을 빼도 같은 결과 나온다 df['D'].str.contains(r'cat|dog') df['Name'].str.contains('Mr.', regex=False) # regex = False : exact matching # regex = True(기본값) : 글자, 숫자, 특수 문자 따로 매칭(substring matching) # str.extract 함수는 반드시 문자열 안에 소괄호로 그룹핑(grouping) 필수 # E열에서 cat을 가지고 있다면 cat을 추출하기 df['E'].str.extract('(cat)') # E열에서 cat 또는 dog를 가지고 있다면 해당 문자열을 추출하기 - 정규표현식 # 기본 설정이 정규 표현식이기 때문에 'r'을 빼도 같은 결과 나온다 df['E'].str.extract(r'(cat|dog)')
13. 데이터 합치는 Pandas 함수
- [pandas] merge
: Pandas에서 엑셀의 VLOOKUP과 같이 병합하는 함수
(VLOOKUP : 두 데이터프레임을 기준 열의 내용에 따라 병합하는 함수)
- right (인수는 데이터프레임 혹은 시리즈)
: 병합할 객체
- how (인수는 ‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’ / 기본값은 ‘inner’)
: 병합할 방식을 결정하는 인자- left: 왼쪽 데이터프레임의 키(key)만을 병합에 사용한다.(엑셀의 vlookup과 유사) - right: 오른쪽 데이터프레임의 키(key)만을 병합에 사용한다. - outer: 양쪽 데이터프레임의 키(key)들의 합집합을 병합에 사용한다. - inner: 양쪽 데이터프레임의 키(key)들의 교집합을 병합에 사용한다. - cross: 양쪽 데이터프레임의 곱집합(cartesian product)을 생성한다.
- on (인수는 열의 레이블 또는 리스트 / 기본값은 None)
: 병합의 기준이 되는 열을 지정하는 인자- 기본 값은 양쪽 데이터프레임에서 이름이 공통인 열들이 지정된다. - 리스트로 입력하면 복수의 열을 기준으로 병합한다. * None의 의미 : 규칙은 있는데 실제 값은 상황에 따라 달라진다.pd.options.display.max_rows = 6 # 판다스 출력옵션 조절 df3 = df1.merge(df2, how='left', on='제품') df3.to_excel('result.xlsx', index=False) # 결과를 엑셀 파일로 저장 # 다중요건 VLOOKUP : 복수의 열을 기준으로 vlookup df4 = df1.merge(df2, how='left', on=['업체', '음료']) df4 = df1.merge(df2, how='left') # 위와 결과 동일
- [pandas] merge_asof
- left (인수는 데이터프레임 혹은 시리즈)
: 병합할 객체1
- right (인수는 데이터프레임 혹은 시리즈)
: 병합할 객체2
- on (인수는 열의 레이블)
: 유사일치로 병합할 기준이 되는 열의 레이블- 반드시 하나의 열만 지정해야 한다. - 숫자나 datetime 같이 유사일치가 가능한 자료형의 열이어야 한다. - 오름차순으로 정렬되어 있어야 한다.🌟🌟🌟- by (인수는 열의 레이블 또는 열의 레이블의 리스트): 정확히 일치시킬 열을 지정하는 인자
- direction (인수는 ‘backward’, ‘forward’, ‘nearest’ / 기본값은 ‘backward’)
: 경계를 기준으로 유사일치 시킬 방향을 결정하는 인자- ‘backward’, ‘forward’는 아래 그림 참고 - ‘nearest’는 가장 가까운 값을 찾아 병합한다.
- 출처 : 파이썬으로 할 수 있는 모든 것 with 47개 프로젝트 초격차 패키지df1 = df1.sort_values('수량') df2 = df2.sort_values('수량') # 사이즈와 종류는 정확히 일치시키고 수량은 범위로 병합 pd.merge_asof(df1, df2, on='수량', by=['사이즈', '종류'])
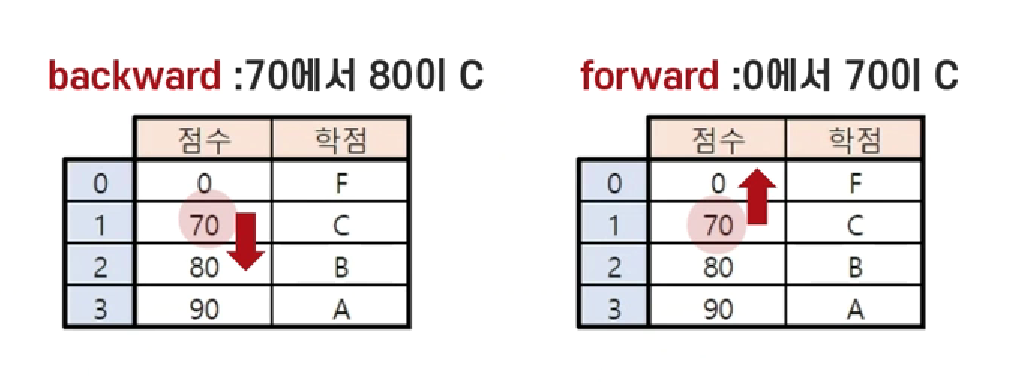
- [pandas] concat
- objs (인수는 시리즈 혹은 데이터프레임의 배열)
: 결합할 시리즈나 데이터프레임들을 리스트로 지정하는 인자
- axis (인수는 0 또는 1 / 기본값은 0)
: 결합할 축 방향을 지정하는 인자- axis=0일때는 행이 증가하는 방향으로 결합 - axis=1일때는 열이 증가하는 방향으로 결합
- join (인수는 ‘inner’, ‘outer’ / 기본값은 ‘outer’)
: 결합방식을 지정하는 인자- inner는 columns가 교집합으로 결합한다 (axis=1일때는 index가 교집합) - outer는 columns가 합집합으로 결합한다. (axis=1일때는 index가 합집합)
- keys (인수는 배열 / 기본값은 None)
: 결합하는 각 데이터프레임에 레벨을 부여하는 인자pd.concat([df1, df2]) # 세로, outer join으로 결합 pd.concat([df1, df2], axis=1, join='inner') # 가로, inner join으로 결합 pd.concat([df1, df2, df3]) # 3개의 데이터 세로로 병합 # 엑셀파일의 모든 시트를 병합 pd.concat(pd.read_excel(url, sheet_name=None).values())
14. 타입 변경 Pandas 함수
- [pandas] astype
: 데이터 프레임이나 시리즈의 자료형을 바꾸는 함수
- dtype
: 자료형을 지정하는 인자- str : 문자열 - int : 정수 - float : 실수 - category : 카테고리(특화된 다른 함수 사용하여 형 변환) - bool : True 또는 False - datetime : 날짜나 시간(특화된 다른 함수 사용하여 형 변환) * 특정 열에만 적용하고 싶을 경우 열의 레이블과 자료형을 딕셔너리로 넣으면 된다 ex) A열은 문자열로 B열은 정수로 바꾸고 싶을 경우 dtype인자에 {'A':'str', 'B':'int'}을 인수로 입력하면 된다df1.astype('str') # 데이터 프레임의 자료형을 문자열로 변경 df1['C'] = df1['C'].astype('int') # 특정열의 자료형 바꾸기1 df.astype({'C':'int'}) # 특정열의 자료형 바꾸기2
- [pandas] to_numeric
: 숫자 자료형으로 바꾸는 함수(시리즈에만 사용가능한 함수)# to_numeric의 errors='coerce'는 숫자로 바꿀 수 없으면 NaN으로 변환 pd.to_numeric(s1, errors='coerce') # errors='ignore'는 숫자로 바꿀 수 없으면 모두 바꾸지 않고 그대로 돌려준다 pd.to_numeric(s1, errors='ignore')
- [pandas] Categorical
<category 자료형 사용하는 이유> - 메모리 절약 - 순서 부여해 원하는 순서로 정렬s = pd.Series(['S', 'M', 'XL']*10000000) s1 = pd.Series(pd.Categorical(s, categories=['S', 'M', 'XL'], ordered=True)) s1.sort_values() # s1을 S와 M, XL 순서로 정렬가능
15. 정렬 Pandas 함수
- [pandas] sort_values
- by (인수는 label 또는 label의 리스트)
: 정렬의 기준이 될 배열(주로 정렬의 기준인 열)을 지정하는 인자
- ascending (인수는 bool 또는 bool의 리스트(0 또는 1을 담은 리스트 가능) / 기본값은 True)
:정렬 순서를 오름차순으로 정렬할지 내림차순으로 정렬할지 지정하는 인자df.sort_values('영어', ascending=False) # 영어 열 기준 내림차순 정렬 # 수학으로 정렬하되 수학이 동점이면 과학으로 정렬 (모두 내림차순) df.sort_values(['수학', '과학'], ascending=False) # 수학으로 내림차순으로 정렬하되 수학이 동점이면 과학으로 오름차순 정렬 # ascending의 인자로 bool자료형이 와야 하나, sort_valuse는 특이하게 0 또는 1이 담긴 리스트 넣을 수 있음 df.sort_values(['수학', '과학'], ascending=[0, 1])# A부터 F 순서로 정렬(category라서 내림차순) df['학점'].value_counts().sort_index(ascending=False)
16. 인덱스(index, columns) 관련 함수
- [pandas] rename
- index (인수는 mapper)
: index의 이름을 바꾸는 인자mapper란? 딕셔너리/시리즈/함수와 같이, 하나의 값을 리턴하기에 맵핑을 할 수 있는 매개체
- columns (인수는 mapper)
: columns의 이름을 바꾸는 인자
- level (인수는 level의 로케이션 혹은 레이블 / 기본값은 None)
: 멀티인덱스에서 이름을 바꿀 레벨을 지정하는 인자기본값은 모든 level에서 이름을 바꾼다.df2.rename(columns={'제품':'음료'})
- [pandas] reset_index
기존 index를 index에서 제거하는 함수- index에서만 제거하고 데이터 프레임의 열로 만들기 가능 - index 제거만도 가능하다 - 모든 index가 제거되어 index가 없다면 새로운 RangeIndex가 생성된다 - 필터링 후 새로운 RangeIndex를 부여할 때 사용하면 된다 🌟🌟🌟
- level (인덱스의 레벨 / 로케이션 혹은 레이블 모두 가능하다 / 기본값은 모든 레벨)
: 멀티 인덱스에서 리셋할 인덱스의 레벨을 결정한다
- drop (인수는 bool / 기본값은 False)
: index에서만 삭제하고 데이터는 데이터프레임의 열로 만들 것인지
열로도 만들지 않고 데이터를 삭제할 것인지 지정하는 인자.기본값은 열로 만든다 (drop 하지 않는다)# df2의 index를 열로 만들자 df2.reset_index() # 필터링 후 새로운 RangeIndex를 부여할 때 사용 df1[df1['점수'] > 90].reset_index(drop=True)
- [pandas] stack
: 인덱스의 구조를 바꾸는(columns를 index로 보내는) 함수
- level (level의 레이블 혹은 로케이션, 또는 그것들의 리스트/기본값은 -1)
: index로 보낼 columns의 level을 지정하는 인자기본값은 -1이라서 맨 마지막 columns를 보낸다
- dropna (인수는 bool / 기본값은 True)
: 값이 NaN인 행은 생성하지 않고 삭제하는 인자# stack으로 df1의 구조 바꾸기 df1.stack() # stack으로 level을 지정해 df1의 구조 바꾸기 df1.stack(0) # stack으로 level을 복수로 지정하기 df1.stack([0, 1])
- [pandas] unstack
- level (level의 레이블 혹은 로케이션, 또는 그것들의 리스트 / 기본값은 -1)
: columns로 보낼 index의 level을 지정하는 인자기본값은 -1이라서 맨 마지막 index를 보낸다
- fill_value
: NaN을 대체할 값을 지정하는 인자
- [pandas] set_axis
: 주어진 축에 원하는 인덱스를 할당하는 함수df.index 나 df.columns에 원하는 인덱스를 배정하는 것과 동일하나, 함수이기 때문에 원본을 덮어쓰지 않는다
- labels (배열이나 인덱스)
: 새로운 인덱스로 만들고 싶은 데이터
- axis (0 or 1 / 기본값은 0)
: index를 바꿀 것인지 columns를 바꿀 것인지 지정하는 인자기본값은 0이고 index를 할당한다# df1의 columns를 영어로 바꾸기 df1.set_axis(['name', 'score', 'class'], axis=1) # df.columns = ['name', 'score', 'class']와 동일(덮어쓰냐 아니냐의 차이)
17. 기타 Pandas 함수
- [pandas] rank
: 데이터 프레임이나 시리즈의 순위를 매기는 함수
- method (인수는 ‘average’, ‘min’, ‘max’, ‘first’, ‘dense’ / 기본 값은 ‘average’)
: 동점자 처리방식을 지정하는 인자- average: 평균 순위 - min: 최소 순위 - max: 최대 순위 - first: 출현 순서에 따라 순위 부여 # # 정렬 기준에 영향을 받아 순위 매김 - dense: ‘min’과 같지만 동점자가 여러명 있어도 다음 순위는 1을 더해부여 ex. 90, 89, 89, 88에 각각 1, 2, 2, 3 부여(88점에 4위가 아닌 3위 부여)
- ascending (인수는 bool / 기본 값은 True)
: 오름차순과 내림차순을 결정하는 인자기본값은 오름차순df['영어'].rank(ascending=False) # 영어열 기준 내림차순으로 등수 매기기 df1['국어'].rank(method='min')
- [pandas] mask
: True or False(bool)에 따라 값을 씌우는(masking) 함수
(즉 불리언 마스킹을 하는 함수 (boolean masking))
- cond (인수는 bool 시리즈, 데이터프레임)
조건문처럼 작동하는 True 또는 False의 배열을 입력받는 인자- mask 함수는 True일 때의 값을 바꾼다. - 변수로 지정 가능하다
- other (인수는 스칼라 , 시리즈, 데이터프레임, 함수 / 기본값은 nan)
조건문이 True일 때 바꿀 값을 지정하는 인자. 기본값은 NaN이다cond1 = df > 80 df.mask(cond1, '합격').mask(~cond1, '불합격') cond2 = df1['국어'] <= 80 df1['국어성적'] = df1['국어'].mask(cond2, '불합격').mask(~cond2, '합격') df1['국어성적'] = np.where(cond2, '불합격','합격') # 위와 동일 cond3 = df1['영어'] > df1['국어'] df1['국어'] = df1['국어'].mask(cond3, df1['영어']) #other 매개변수에 Series 가능
- [pandas] cut
: 숫자와 같은 데이터를 구간별로 나눠서 범주화(categorization)하는 함수
- x (인수는 배열)
: 구간을 나눌 배열을 입력받는 인자반드시 1차원이어야 한다
- bins (인수는 정수, 순서의 배열)
: 구간을 나누는 기준을 입력받는 인자- 정수 : 정수만큼의 균등한 구간으로 분할한다 - 순서의 배열 : ex1) [0, 20, 40, 60] 이라면 0 ~ 20, 20 ~ 40, 40 ~ 60 까지의 3개의 구간으로 분할한다
- right (인수는 bool / 기본값은 True)
: 구간에서 우측 경계를 포함할지 여부를 결정하는 인자예를 들어, right=True면 0초과 20이하, 20초과 40이하, 40초과 60이하로 분할한다
- labels (인수는 배열 또는 False / 기본값은 None)
: 구간의 레이블을 지정하는 인자- False는 가장 왼쪽 구간부터 0, 1, 2, 3... 으로 레이블을 부여한다 - 기본값은 구간의 경계를 구간의 레이블로 부여한다 - 예를 들어, (0, 20], (20, 40], (40. 60] 으로 부여한다 - 반드시 bins 인자로 나누어진 구간수와 같아야 한다s = pd.Series([71, 92, 77, 70]) # 구간 분류해 레이블을 코드화 하기 pd.cut(s, [0, 70, 80, 90, 100], labels=False) # 구간 분류해 지정한 레이블을 부여하기 pd.cut(s, [0, 70, 80, 90, 100], labels=['F', 'C', 'B', 'A'])
- [pandas] apply
: 데이터 프레임이나 시리즈의 개별 요소 각각에 함수를 적용해주는 함수- 데이터 프레임은 시리즈 단위로 함수 적용 - 시리즈는 셀단위로 함수 적용
- func (인수는 함수)
: 개별 요소에 적용할 함수를 입력하는 인자
- axis (인수는 0 or 1 / 기본값은 0)
: (DataFrame에 apply 적용하여 Series별로 함수를 적용할 때)
개별 Series를 결정하는 축을 지정하는 인자- 0 : 열마다 함수 적용(행 기준) - 1 : 행마다 함수 적용(열 기준)df['역순'] = df['답안'].apply(lambda x: x[::-1]) # 시리즈에만 적용되는 pd.to_numeric을 데이터프레임에 적용하려면 apply 필요 df.apply(pd.to_numeric, errors='coerce') # 데이터 프레임에 apply를 적용할 때 축에 따라 다르게 적용된다 df2.apply(lambda x: x[:2]) # 행 슬라이싱 df2.apply(lambda x: x[:2], axis=1) # 열 슬라이싱 # 둘 이상의 열에 대해 행단위로 함수를 적용할 때도 데이터프레임에 apply를 적용할 수 있다 df3['가격'] = df3.apply(lambda x: df4.loc[x['제품'], x['할인여부']], axis=1)
- apply vs. map
# 시리즈에 apply 적용하기 s1.apply(lambda x: int(x[:-1])) # map 함수는 시리즈에 적용할 때 apply와 유사하다 s1.map(lambda x: int(x[:-1])) # map 함수는 함수대신 맵퍼를 입력받을 수 있다 s2.map(s3) # apply는 맵퍼를 입력받지 못하지만 lambda 함수로 유사한 기능 가능 s2.apply(lambda x: s3[x]) print(s2) print(s3)
- apply vs. applymap
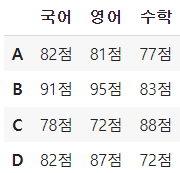
df
# applymap은 apply와 달리 데이터 프레임도 셀마다 함수를 적용한다 df.applymap(lambda x: int(x[:-1]))
# 위 결과를 apply로 얻으려면 map 함수를 한번 더 사용해야 한다 df.apply(lambda x: x.map(lambda y: int(y[:-1])))


- [pandas] shift
: 데이터를 정해진 칸만큼 이동시키는 함수
- periods (정수)
: 이동할 칸을 지정하는 인자(기본값은 1)
- freq
: 날짜나 시간 데이터를 shift 할 때 사용하는 인자
- axis (0 or 1)
이동 방향을 지정하는 인자(기본값은 0)# 데이터 프레임에 shift 함수 적용하기 df.shift()
# shift 함수에 음수 입력하기 df.shift(-1)
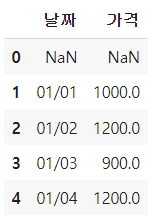
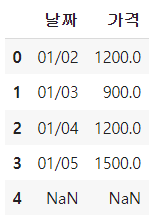
# 시리즈를 shift해서 가격변동 열 만들기 df1['가격변동'] = df1['가격'] - df1['가격'].shift() # diff 함수로 가격변동 열 만들기 df1['가격변동'] = df1['가격'].diff() # 위와 동일 # 시리즈를 shift해서 변동률 열 만들기 df1['변동률'] = (df1['가격'] - df1['가격'].shift()) / df1['가격'].shift() # pct_change 함수로 열 만들기 df1['변동률'] = df1['가격'].pct_change() # 위와 동일
17. 데이터 구조 바꾸기
- [pandas] explode
: 데이터프레임이나 시리즈의 셀안에 있는 리스트의 데이터를 확장하는 함수
- column
: 확장 시킬 열을 지정하는 인자
- ignore_index
: 새로운 index를 부여할지 여부를 지정하는 인자(기본값은 False)ignore_index=True인 경우, 데이터가 확장되면서 인덱스가 중복되는데, 이때 새로운 index 부여df1
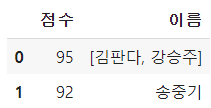
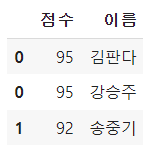
df1.explode('이름') # ignore_index=True로 하거나, reset_index()로 새로운 인덱스 부여 필요
# 이름열의 /를 분리해서 리스트로 만들고 explode를 사용하면 전처리된다 df2['이름'] = df2['이름'].str.split('/') df2.explode('이름') # 작품으로 나열된 네이버 웹툰의 데이터를 이용해 작가 중심으로 해당 작가의 작품을 묶기 df_ex2['author'] = df_ex2['author'].str.split(' / ') df_ex2.explode('author').groupby('author', as_index=False)['title'].agg(' / '.join)
18. 시계열 데이터 관련 함수
- [pandas] to_datetime
: 자료형을 datetime으로 바꿔주는 함수
- arg (datetime으로 변환 가능한 데이터)
: datetime으로 변환할 데이터
- errors (인수는 ‘ignore’, ‘raise’, ‘coerce’ / 기본값 ‘raise’)
: 에러 처리 방식- 'raise' : 변환할 수 없는 객체를 만나면 에러를 일으킨다 - 'coerce' : 변환할 수 없는 객체를 만나면 해당 부분만 NaT으로 바꾸고 변환을 수행한다. - 'ignore' : 변환할 수 없는 객체를 만나면 모두 변환하지 않고 그냥 input을 그대로 반환한다
- format (str, 기본값 None)
: 문자열이 어떤 날짜형을 나타내는지 형식을 지정하는 인자예) 2023년 1월 3일이 '03/01/2023'으로 표현되어 있는 데이터라면 '%d/%m/%Y'로 표현한다
- unit (str, 기본값은 'ns')
: Timestamp가 숫자로 주어질 때 숫자의 기본단위. 기본값은 nano second
- origin (scalar, 기본값 'unix')
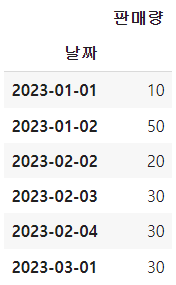
: Timestamp가 숫자로 주어질 때 기준 날짜.- unit에서 정한 단위만큼의 숫자를 기준 날짜에서 더한다 예) origin으로 1970-01-01을 기준으로 정하고 unit가 D라면 숫자1은 기준열부터 1일 지난 후인 1970-01-02를 의미한다 - 'unix' (or POSIX) : origin 은 1970-01-01. - 'julian' : BC 4713년 1월 1일 정오. unit는 'D'여야 한다 - Timestamp 로 변환가능한 문자열을 넣어도 된다# to_datetime 함수로 timestamp로 변경하기 pd.to_datetime(df['날짜']) # astype 함수로 timestamp로 변경하기 (잘 쓰지 않는다) df['날짜'].astype('datetime64[ns]') # to_datetime 함수의 장점 (바꿀 수 없는 데이터는 NaT로 바꾼다) s = pd.Series(['2022-01/03', '김판다']) pd.to_datetime(s, errors='coerce')# df를 복제한 df1으로 날짜열을 datetime으로 바꾸자 df1 = df.copy() df1['날짜'] = pd.to_datetime(df1['날짜']) # 자료형을 바꾼 날짜열을 index로 지정 df1 = df1.set_index('날짜')
# 2023-02의 자료만 가져오기 df1.loc['2023-02'] # 단수의 문자열이라 df1['2023-02']을 사용하는 것보다 loc사용 # 2023-02 부터 자료를 슬라이싱해서 가져오기 df1.loc['2023-02':]
- 파일에서 데이터 프레임을 불러올 때 datetime 자료형으로 지정하기
: read_csv나 read_excel의 parse_dates 인자에 해당 열을 리스트로 입력한다(단독이어도 리스트로 입력)# csv파일에서 부를때 datetime으로 지정하고 index로 지정하기 df_ex1 = pd.read_csv(url, parse_dates=['시간'], index_col=0) # 2022년 6월 1일 데이터만 인덱싱 df_ex1.loc['2022-06-01'] # 2022년 6월 1일 23시의 데이터만 인덱싱 df_ex1.loc['2022-06-01 23'] # 2022년 6월 1일 23시 00분의 데이터만 인덱싱 df_ex1.loc['2022-06-01 23:00'] # 2022-06-02 부터 2022-06-04까지 슬라이싱 df_ex1.loc['2022-06-02':'2022-06-04']
- [pandas] date_range
: 특정 주기의 DatetimeIndex를 만드는 함수
- start
: 배열의 시작
- end
: 배열의 끝
- periods (int, optional)
: 생성할 배열의 개수
- freq (주기 / 기본값 ‘D’)
: 생성할 데이터의 주기
# 시작일과 끝일 사이의 모든 날짜 pd.date_range('2022-01-03', '2022-01-10') # 시작일부터 지정된 개수의 배열 (날짜) pd.date_range('2022-01-03', periods=3) # 결과가 index인 시리즈 만들기 idx = pd.date_range('2022-01-03', periods=3) pd.Series([0, 1, 2], index=idx) # DatetimeIndex이지만 시리즈로 만들 수 있고 데이터프레임의 열로 만들 수도 있다 pd.Series(pd.date_range('2022-01-03', periods=3)) # 주기 바꾸기 (월의 마지막날) pd.date_range('2022-01-03', periods=3, freq='M') # 주기 바꾸기 (월의 첫날) pd.date_range('2022-01-03', periods=3, freq='MS') # 주기 바꾸기 (2개월 주기의 마지막날) pd.date_range('2022-01-03', periods=3, freq='2M') # 주기 바꾸기 (년도별 마지막날) pd.date_range('2022-01-03', periods=3, freq='Y') # 주기 바꾸기 (10분)) pd.date_range('2022-01-03', periods=10, freq='10T')

- dt 접근자
dt 접근자와 사용해서 datetime의 특정 데이터를 가져오는 속성과 함수들
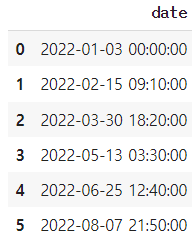
df1
df1['date'].dt.year # 연도 df1['date'].dt.quarter # 쿼터 df1['date'].dt.month # 월 df1['date'].dt.day # 일 df1['date'].dt.hour # 시각 df1['date'].dt.minute # 분 df1['date'].dt.second # 초 # df1의 date열의 시간만 추출 (결과는 object) df1['date'].dt.time # df1의 date열의 날짜만 추출 (결과는 object) df1['date'].dt.date # 날짜만 표시 (datetime의 시간을 00:00:00으로 만든다) df1['date'].dt.normalize() # 연도 주 요일을 데이터 프레임으로(주로 주를 추출할 때 쓴다) df1['date'].dt.isocalendar()
df2
# df2의 index(DatetimeIndex)에서 연도만 추출 (dt접근자가 필요 없다) df2.index.year

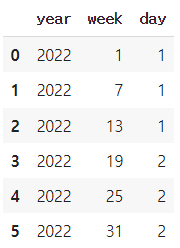
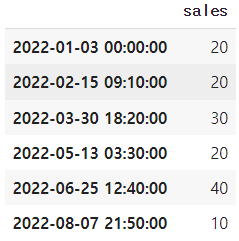
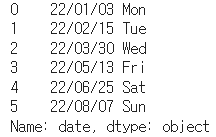
# 표기형식 바꾸기 df1['date'].dt.strftime('%y/%m/%d [%a]')
# 연도와 합쳐진 월의 데이터를 가져올 때도 strftime을 쓴다 df1['date'].dt.strftime('%Y-%m')
# 연도가 포함된 월을 얻고 싶다면 period 자료형을 사용하는 것이 더 정확하다 df1['date'].dt.to_period('M')
# 연도가 포함된 쿼터를 얻을 경우도 시계열을 유지하려면 period 자료형을 쓴다 df1['date'].dt.to_period('Q')


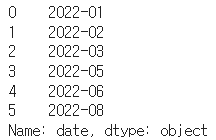
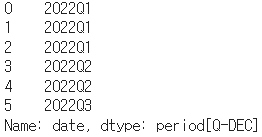
- [pandas] resample
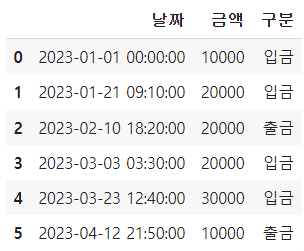
df1
# 월별 집계 df1.resample(rule='M', on='날짜')['금액'].sum()
# timestamp를 월의 첫날로 바꿔보자 df1.resample('MS', on='날짜')['금액'].sum()
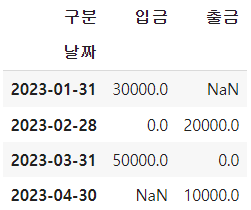
# 시계열 resample과 groupby를 함께 사용할 때 (groupby부터 사용한다) df1.groupby('구분').resample('M', on='날짜')['금액'].sum().unstack(level=0)
# 실습에 쓰일 df2는 인덱스가 DatetimeIndex이다 df2
# DatetimeIndex일 때는 on의 지정이 필요없다 df2.resample('MS')['금액'].sum()
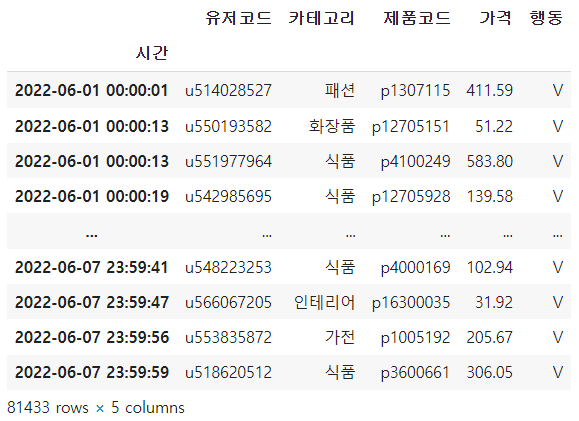
df_ex1
# 일자별 총 행동의 횟수 집계 df_ex1.resample('D')['가격'].count() # null값이 없는 열이라면 '가격' 자리에 다른 열이 들어올 수 있다(함수가 count이기 때문)
# 간단하게 시각화 df_ex1.resample('D')['가격'].count().rename_axis('').plot(kind='bar')# 일자별 행동 유형별로 횟수를 집계 df_ex1.groupby('행동').resample('D')['가격'].count().unstack(level=0)






18. Pandas 연산
- DataFrame이나 Series와 스칼라(상수)의 연산
- 모든 요소에서 각각 연산s1 * 2 df1 == 70
- Series 사이의 연산
- 동일한 index끼리 각각 연산df1['국어'] + df1['영어']
- DataFrame 사이의 연산
- 동일한 index와 columns끼리 각각 연산
- DataFrame과 Series의 연산
- 브로드 캐스팅(broad casting)
