입사 1일차 이번주 카산드라 DB 마이그레이션 업무를 맡게 되어 아파치 카산드라에 대해 공부해보았다.
📚 Apache Cassandra
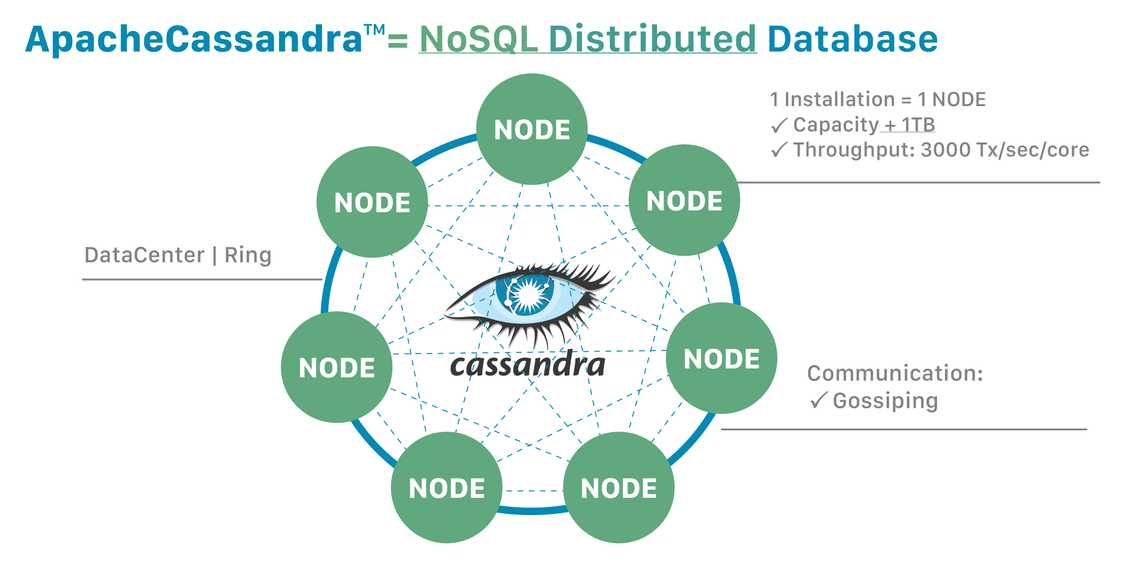
아파치 카산드라는 대규모 데이터를 처리하기 위해 설계된 오픈 소스 분산형 NoSQL 데이터베이스이다. 카산드라는 단일 장애 지점 없이 고가용성과 확장성을 제공한다.
💡 알아두면 좋은!
단일 장애 지점(Single Point of Failure, SPOF)이란 시스템의 특정 구성 요소가 고장날 경우 전체 시스템이 중단되는 현상을 의미한다.
카산드라는 노드들이 링 형태로 연결된 구조를 가지며, 데이터는 해시값에 따라 링의 특정 구간을 담당하는 노드들에 분산 저장된다.
특징
1️⃣ 마스터리스 아키텍처 (Masterless Architecture)
- 기존의 DB(MySQL의 Master-Slave 구조)와 달리, 카산드라는 모든 노드(서버)가 동등한 위치를 가짐
- 이를 P2P(Peer-to-Peer) 방식이라고 하며, 특정 마스터 노드가 죽어도 전체 시스템이 멈추지 않음
2️⃣ 선형적 확장성 (Linear Scalability)
- 데이터 처리가 늘어나면 서버, 즉 노드를 추가하기만 하면 됨
- 노드를 2배로 늘리면 성능도 거의 2배 가까이 증가하는 선형적인 성능 향상을 보장
3️⃣ 고가용성 (High Availability)
- 데이터를 여러 노드에 복제하여 저장
- 한 서버가 고장 나더라도 다른 서버에 복제된 데이터가 있어 서비스 중단 없이 운영 가능
나는 데이터를 여러 노드에 복제하여 저장하는 것이 저장 공간을 낭비하는 것은 아닐까 생각하여 찾아보았다.
보통 카산드라에서는 복제 계수를 3으로 설정하는 것이 표준이다. 즉, 1TB의 데이터를 저장하려면 실제로는 3TB의 디스크 공간이 필요한 것이다. 그럼에도 데이터를 여러 노드에 저장하는 것은 다음과 같은 트레이드오프 때문이다.
-
디스크 값 < 서비스 중단 비용
- 하드웨어의 가격은 계속 저렴해지고 있지만, 서버가 죽어서 서비스가 멈췄을 때 발생하는 기업의 손실은 막대하다. 카산드라는 저장 공간을 3배 써서라도 서버 한 두 대가 죽었을 때 서비스가 절대 멈추지 않도록 한다.
-
압축 기술
- 카산드라는 디스크에 저장할 때 데이터를 효율적으로 압축한다. 내부적으로 구글의 Snappy나 LZ4 같은 알고리즘을 사용하여, 원본 데이터보다 훨씬 적은 용량으로 저장한 덕분에 복제로 늘어난 용량 부담을 어느 정도 상쇄할 수 있다.
-
읽기 성능 향상
- 데이터가 여러 노드에 퍼져 있으면, 수천 명의 사용자가 동시에 조회를 요청했을 때 여러 노드가 부하를 나눠서 처리할 수 있어 읽기 속도도 빨라진다.
결국 데이터 복제로 인해 용량을 3배 정도 더 사용하는 것은 맞지만, 압축 기술로 이를 보완하는 것이다.
데이터 모델
카산드라는 Wide-Column Store 모델을 따른다. 관계형 데이터베이스와 비슷해 보이지만 내부 동작은 완전히 다르다.
구조는 Keyspace(RDBMS의 Database) -> Table -> Row -> Column으로 구성된다.
💡 Wide-Column Store란?
NoSQL 데이터베이스의 한 종류로, 행마다 컬럼의 이름이나 개수가 달라도 되는 거대한 2차원 맵 구조를 가진 데이터베이스다. 형태가 일정하지 않은 대량의 데이터를 아주 빠르게 저장하고 조회해야 할 때 사용하는 유연한 대용량 저장소라고 할 수 있다.
- 기존 방식인 RDBMS는 모든 행이 똑같은 컬럼을 가져야 하지만, Wide-Column Store는 각 행이 자신만의 컬럼을 가질 수 있다. (최신 버전에서는 스키마 정의를 권장한다.)
- 내부적으로 Multi-dimensional Key-Value Store처럼 동작한다.
- Row Key : 데이터를 찾는 유일한 열쇠 (RDBMS의 Primary Key 역할)
- Column Family : 연관된 컬럼들의 집합 (RDBMS의 Table)
- Column : 이름(Name), 값(Value), 타임스탬프로 구성
- 데이터 구조가 자주 바뀌거나, 비정형 데이터(로그, IoT 센서 데이터 등)를 저장할 때 스키마를 미리 정의할 필요가 없다.
- Row Key만 알면 수억 건의 데이터 중에서도 해당 행의 데이터를 순식간에 찾아오거나 쓸 수 있다.
- 값이 없는 컬럼은 아예 저장하지 않으므로(NULL 없음) 희소한 데이터를 저장할 때 공간 낭비가 없다.
CQL (Cassandra Query Language)
SQL과 매우 유사한 문법을 제공하여 RDBMS에 익숙한 개발자가 쉽게 접근할 수 있다.
예시
# 데이터 복제 방식(전략) 변경 쿼리문
ALTER KEYSPACE thingsboard
WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter1': '1'
};내부 동작 원리
카산드라는 내부적으로 LSM Tree(Log-Structured Merge-tree)를 사용한다. LSM Tree는 쓰기 작업이 매우 빈번한 시스템을 위해 설계된 자료구조로, 내용을 수정할 때 이전 페이지를 찾아가서 지우고 다시 쓰는 것이 아니라 새로운 내용을 그냥 덧붙여 쓰는 방식이다.
1️⃣ 데이터가 들어오면 Commit Log(디스크)에 기록하여 유실 방지
2️⃣ 동시에 메모리 상의 Memtable에 데이터를 씀
3️⃣ Memtable이 가득 차면, 디스크에 SSTable(Sorted String Table)이라는 불변 파일로 플러시
4️⃣ 디스크에 파일이 너무 많이 쌓이면, 백그라운드에서 이들을 병합하고 관리 = Compaction
💡 Memtable이란?
메모리에 있는 임시 저장소로, 카산드라가 데이터를 빠르게 쓸 수 있는 비결이다.
1. 쓰기 버퍼 : 데이터가 들어오면 즉시 메모리 공간인 Memtable에 저장된다. 메모리는 디스크보다 훨씬 빠르기 때문에 클라이언트에게 저장 완료 응답을 순식간에 줄 수 있다.
2. 데이터 정렬 : Memtable은 나중에 디스크(SSTable)로 옮길 때 정리된 상태로 쓰기 위해 데이터를 Key 순서대로 정렬해서 가지고 있는다.
3. 플러시 : 메모리의 용량에는 한계가 있기 때문에 설정된 크기에 도달하면, Memtable의 내용을 그대로 디스크에 파일로 저장한다. 이때 생성되는 파일이 SSTable이다.
★ 메모리는 전원이 꺼지면 날라가기 때문에 Commit Log에 어떤 데이터가 들어왔는지 기록한다. 만약 서버가 꺼져 Memtable이 날아가더라도 재부팅 할 때 Commit Log를 보고 Memtable을 복구해낸다.
이러한 과정은 디스크의 랜덤 I/O를 줄이고 순차 쓰기(Sequential Write)를 수행하므로 대량의 데이터 유입을 매우 빠르게 처리할 수 있다.
장단점
| 장점 | 단점 |
|---|---|
| 대용량 로그 데이터 저장에 최적화 | 테이블 간 조인 연산 지원 X |
| 무중단 운영으로 서버 장애 시에도 서비스 지속 가능 | 집계 함수나 복잡한 검색 조건 사용 어려움 |
| 성능과 데이터 정확성 사이 조율 가능 | 읽기 성능을 위해 데이터 여러 테이블에 중복 저장해야 함 |
사용하면 좋은 서비스
- 사물인터넷 : 수만 개의 센서에서 쏟아지는 로그 데이터 수집
- 사용자 활동 로그 : 웹사이트 클릭 스트림, 추천 시스템을 위한 이력 저장
- 메시징 시스템 : 채팅 앱의 대화 기록 저장(예: Discord가 카산드라를 대규모로 사용하다가 ScyllaDB로 마이그레이션함)
- 글로벌 서비스 : 여러 국가(데이터 센터)에 데이터를 실시간으로 복제해야 할 때
카산드라는 이와 같이 엄청난 양의 데이터가 들어오고, 죽으면 안 되는 시스템에 적합하다.
하지만 복잡한 분석 쿼리나 트랜잭션 관리가 필요한 금융 시스템 등에는 적합하지 않을 수 있다.
Cassandra 노드 증설하기
1️⃣ 새 노드 준비 및 설정
먼저 새로운 서버에 카산드라를 설치하고 설정 파일을 수정한다. 이때 기존에 운영 중인 노드의 설정과 맞춰야 한다.
cluster_name: 기존 클러스터와 동일하게seeds: 기존에 운영 중인 Seed 노드의 IP를 적음listen_address: 서버 내부 IP- 서버가 실제로 가지고 있는 내부 IP를 적어야 요청이 왔을 때 내부에서 처리할 수 있음
rpc_address:0.0.0.0- 사용자나 애플리케이션이 접속할 때 사용하는 주소로 모든 접속을 허용하는 것이 실수를 줄일 수 있음
endpoint_snitch: 기존 클러스터와 동일하게auto_bootstrap:true(기본 값이지만 확인 필요. 해당 기능이 켜져 있어야 켜지면서 데이터를 자동으로 당겨옴)
설정 파일 예시는 다음과 같다.
# 1. 클러스터 이름 (가장 중요: 기존 노드와 글자 하나도 틀리면 안 됨)
cluster_name: 'My_Cluster'
# 2. 토큰 설정 (자동 배정의 핵심)
# 기존 노드도 같은지 꼭 확인
# 이 값이 있으면 initial_token 값은 비워둬야 함
num_tokens: 256
# 3. 시드 노드 (기존에 이미 살아있는 노드 IP를 적기)
# *절대* 부트스트랩이 안 될 수 있기 때문에 새 노드 자신의 IP를 여기에 넣으면 안됨
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.0.1,192.168.0.2" # 기존 운영 중인 노드 IP
# 4. 네트워크 설정 (새 노드의 IP)
listen_address: 192.168.0.100 # 새 노드 내부 IP
rpc_address: 0.0.0.0 # 모든 클라이언트, 애플리케이션에서의 요청 허용
# 5. 스니치 설정 (기존 노드와 동일하게)
# AWS면 Ec2Snitch, 일반 서버면 GossipingPropertyFileSnitch 등을 씀
endpoint_snitch: GossipingPropertyFileSnitch
# 6. 데이터 저장 경로 (기존 노드와 동일한 구조 권장)
data_file_directories:
- /var/lib/cassandra/data
# 7. 부트스트랩 자동화 (기본값이 true지만 명시적으로 확인)
# true여야 켜질 때 시드 노드에게 데이터 요청 가능
auto_bootstrap: true2️⃣ 서비스 시작 및 데이터 스트리밍
# 서비스 시작
sudo service cassandra start새 노드는 Join 상태가 되며 기존 노드들로부터 자신의 토큰 범위에 해당하는 데이터를 받아온다.
이때 토큰은 자동으로 배정되는데, cassandra.yaml 파일에서 num_tokens가 256이 설정되어 있으면 이는 새 노드가 실행될 때 전체 토큰 링에서 무작위로 256개 범위를 자동으로 선택해서 가져간다는 뜻이다.
nodetool status기존 노드나 새 노드에서 위 명령어로 상태를 볼 수 있다. UJ(Up Joining) 상태로 보이다가 완료되면 UN(Up Normal) 상태로 바뀐다.
nodetool netstats참고로 데이터가 얼마나 넘어오고 있는지 확인하려면 위 명령어를 사용하면 된다.
3️⃣ 디스크 용량 확보
새 노드가 UN 상태가 되면, 이제 읽기/쓰기 요청을 처리하기 시작한다. 하지만 아직 기존 노드의 디스크 용량을 줄어들지 않는다. 카산드라는 데이터를 새 노드에 복사해줬을 뿐, 기존 노드에 있는 데이터를 아직 지우지 않았기 때문이다.
새 노드가 들어오면서 기존 노드가 담당하던 데이터의 일부(토큰)을 새 노드가 가져갔기 때문에 기존 노드에서는 담당하지 않는 데이터가 디스크에 남아있는 상태이다.
nodetool cleanup새 노드를 제외한 기존 노드들에 접속해서 위 명령어를 실행하면, 현재 노드가 담당하지 않는 키(데이터)를 디스크에서 삭제한다.
실전! Cassandra 마이그레이션하기 🗃️
현재 상황
- DB 서버에 Cassandra + PostgreSQL 설치되어 있음
- 서버 용량이 84%
(불과 하루 전엔 81%였음)까지 차서 빠르게 조치를 해야 하는 상황 - HDD 디스크가 서버에 연결되어 있지만 현재 사용하지 않는 중
=> 결론은 카산드라만 HDD에 옮기기!
PostgreSQL는 옮기지 않고 Cassandra만 옮기는 이유는 다음과 같다.
- SSD와 달리 HDD는 물리적인 헤드가 움직여 Random I/O에 취약하다.
- PostgreSQL과 같은 RDBMS는 Random I/O가 많기 때문에 SSD에 저장하고 이용하는 것이 성능적으로 훨씬 좋다.
- Cassandra는 NoSQL로, 데이터가 들어오면 순차적으로 쓰기 작업(Sequential Write)을 하기 때문에 HDD더라도 성능 저하가 심각하지 않다.
- LSM Tree는 Append-only 방식으로 작동하여 데이터를 수정하거나 지울 때, 기존 위치를 찾지 않고 로그를 파일 끝에 추가하기 때문이다.
- 다만 데이터가 Memtable에 없으면 디스크에 있는 여러 SSTable 파일을 다 뒤져야 하기 때문에 읽기는 SSD보다 느릴 수 있는데, Bloom Filter를 사용해서 데이터 존재 여부를 빠르게 알 수 있다. (Bloom Filter에 대한 내용은 여기에 자세히 정리해두겠다.)
- LSM Tree는 Append-only 방식으로 작동하여 데이터를 수정하거나 지울 때, 기존 위치를 찾지 않고 로그를 파일 끝에 추가하기 때문이다.
처음에는 카산드라 설정에 HDD 경로를 추가하여 나누어 저장할까 했지만, 이 경우 SSD에도 데이터가 계속 쌓이므로 언젠가는 지금과 같은 용량 문제가 발생할 것이라 생각했다. 따라서 현재 SSD에 저장된 카산드라 데이터를 모두 HDD에 옮길 것이다.
팀장님께서 최대한 무중단으로 진행하면 좋을 것 같다고 하셔서 다운타임을 최소화 할 방법을 찾아보았다.
1️⃣ 1차 복사
서버가 돌아가는 상태에서 데이터를 HDD로 복사한다. 이때 데이터가 조금 깨져도 나중에 맞추기 때문에 상관없다.
# rsync 명령어로 SSD 데이터를 HDD로 복사 (옵션 -av: 권한 유지하며 복사)
# 시간은 오래 걸리지만, 서비스는 계속 돌아감
sudo rsync -av /var/lib/cassandra/data/ /data_hdd/cassandra/data/이 과정은 데이터 양에 따라 30분~몇 시간이 걸릴 수 있다고 한다.
2️⃣ 카산드라 종료
sudo systemctl stop cassandra3️⃣ 2차 복사 (동기화)
아까 진행한 1차 복사 이후에 새로 들어온 데이터만 긁어서 HDD에 덮어쓴다. 이때 --delete 옵션을 통해 원본에서 삭제된 파일은 HDD에서도 삭제하며 이 과정은 오래 걸리지 않는다.
# --delete 옵션: 원본에서 지워진 파일은 HDD에서도 지움
sudo rsync -av --delete /var/lib/cassandra/data/ /data_hdd/cassandra/data/4️⃣ 설정 변경 및 재시작
카산드라의 설정 파일을 수정한 뒤 재시작한다.
# 설정 파일 수정 (/data_hdd 경로로 변경)
sudo vi /etc/cassandra/cassandra.yaml
# 시작
sudo systemctl start cassandra5️⃣ 확인 및 SSD 비우기
카산드라가 잘 작동되는지 확인한 후, SSD에 있는 예전 데이터를 지워서 용량을 확보한다.
sudo rm -rf /var/lib/cassandra/data/*그리고 Cassandra 미러링까지 🪞
현재 카산드라 DB가 우리 센터에 있고, 다른 센터에서 이를 미러링하여 같은 데이터를 가져가려고 한다. 미러링은 노드 증설과 비슷하지만 조금 다른 점이 있다.
미러링을 위해서 필요한 데이터들은 다음과 같으며, 다른 센터의 카산드라 미러링 담당자분께 다음 정보들을 전달드렸다.
1. Cassandra 버전
2. 사용 중인 JDK 버전
3. cluster name
4. seed node IP 정보
5. Data Center / Rack 이름
6. 사용 중인 포트 정보(CQL, intra-node, JMX 등)
7. Keyspace별 Replication 설정(DC별 포함 여부)
8. Cassandra 인증 사용 여부 및 CQL 계정 필요 여부
9. Cassandra 노드들의 IP 목록 또는 사용 중인 IP 대역 정보
10. Cassandra 클러스터의 전체 구성(노드수, DC 구성 등)도
11. num_tokens 값그런데 우리쪽 카산드라 서버를 확인해보니 다음과 같은 문제가 있었다.
-
Address가
127.0.0.1로 카산드라가 자기 자신하고만 통신하고 있음 -
cassandra.yaml파일 설정에 Snitch 설정이SimpleSnitch로 되어 있어 다른 센터 서버랑 통신이 되지 않음 -
Replication Strategy은
SimpleStrategy로 되어 있어 Multi-DC 복제가 불가능
따라서 다음과 같이 설정 변경이 필요했고, 이를 위해서는 카산드라 재시작이 필요했다.
1️⃣ IP 변경(cassandra.yaml) : 127.0.0.1 ➡️ 내부 IP
2️⃣ Snitch 변경(cassandra.yaml) : SimpleSnitch ➡️ GossipingPropertyFileSnitch
3️⃣ 데이터 전략 변경(cqlsh) : SimpleStrategy ➡️ NetworkTopologyStrategy
카산드라 설정 변경 및 재시작
1️⃣ 카산드라 중지
sudo service cassandra stop
# 또는
sudo systemctl stop cassandra2️⃣ DataCenter, Rack 설정 파일 수정
sudo vi /etc/cassandra/cassandra-rackdc.propertiesdc=datacenter1 # 미러링 할 카산드라 dc 이름은 다르게 설정해주어야 한다
rack=rack3️⃣ cassandra.yaml 파일 수정
sudo vi /etc/cassandra/cassandra.yamlseeds: 공인 IPlisten_address: 내부 IPbroadcast_address: 공인 IP (이 값은 따로 추가해주어야 한다)rpc_address:0.0.0.0endpoint_snitch:GossipingPropertyFileSnitch
4️⃣ 카산드라 시작 및 확인
sudo service cassandra startnodetool status5️⃣ Keyspace 전략 변경
cqlsh 10.10.130.15 9042-- 기존 SimpleStrategy를 NetworkTopologyStrategy로 변경
-- 추가 카산드라 서버 연결 후 다른 센터의 dc 이름과 데이터 복사본 개수를 추가적으로 설정해주어야 함
ALTER KEYSPACE thingsboard
WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter1': '1'
};
-- 변경 확인
DESCRIBE KEYSPACE thingsboard;
-- 빠져나오기
exit;설정 파일 백업
참고로 이미 카산드라에 많은 데이터가 저장되어 있었기 때문에, 재시작 및 설정 전 혹시 모르는 상황을 대비해 백업을 해두었다.
# cassandra.yaml 백업
sudo cp /etc/cassandra/cassandra.yaml /etc/cassandra/cassandra.yaml.bak
# rackdc.properties 백업
sudo cp /etc/cassandra/cassandra-rackdc.properties /etc/cassandra/cassandra-rackdc.properties.bak데이터 스냅샷
nodetool snapshot -t pre_mirroring_backup★ 필수! 네트워크 설정하기
본격적으로 미러링하기 전 (우리 센터) <-> (다른 센터) 간의 카산드라 클러스터 미러링을 위해 양방향 네트워크 통신 환경을 구성해주어야 한다.
- Inbound (외부 -> 내부) : 다른 센터에서 우리 센터의 노드에 접근할 수 있도록 우리 센터의 공인 IP의 TCP 7000번 포트를 내부 카산드라 서버 IP로 포트포워딩 설정
- Outbound (내부 -> 외부) : 우리 센터 내부 서버에서 다른 센터의 공인 IP 및 포트로의 연결을 허용하여 서버 간의 데이터 복제 및 상태 공유를 가능하게 함
7000번 포트는 카산드라 노드 간의 데이터 동기화 및 클러스터 관리에 사용되는 기본 포트로, 보안을 위해 특정 외부 IP에 대해서만 접근을 허용하는 방식을 적용했다.
아직 네트워크 부분은 모르는 점이 많아 이 부분에서 살짝 애를 먹었다 😅 따로 공부를 진행해봐야겠다.
미러링하기
이제 본격적으로 미러링을 진행할 차례다. 미러링을 할 서버(=다른 센터)에서 아래와 같은 과정을 진행해주면 된다.
1️⃣ 카산드라 서비스 시작
sudo systemctl start cassandra2️⃣ 클러스터 합류 확인
nodetool status로 미러링해 갈 서버와 본인 서버가 모두 UN 상태로 뜨는지 확인한다.
이때 cqlsh에서 DESCRIBE KEYSPACE 키스페이스명; 했을 때 데이터가 실제로 양쪽 데이터센터에 저장되도록 설정되어 있는지 확인해야 한다.
CREATE KEYSPACE my_keyspace WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter1': '1', /* datacenter1에 복제본 1개 */
'datacenter2': '1' /* datacenter2에 복제본 1개 */
};처음에는 아마 다음과 같이 설정되어 있을 것이다.
CREATE KEYSPACE my_keyspace WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter1': '1'
};ALTER KEYSPACE thingsboard
WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter1': '1',
'datacenter2': '1'
};위 명령어를 사용해서 새 데이터센터인 datacenter2에도 데이터를 저장하도록 한다.
3️⃣ 데이터 전송 시작
복제 전략을 변경한 후, 새로운 데이터 센터인 datacenter2의 서버에서 기존 데이터를 전송받는 작업을 수행해야 한다.
# datacenter1 데이터센터에서 데이터를 복사해온다는 뜻
nodetool rebuild datacenter1진행률을 확인하고 싶다면 nodetool netstats, 용량이 증가되었는지 확인하고 싶다면 nodetool status를 입력하면 된다.
전송 속도 및 용량 이슈 💥
클러스터 합류와 데이터 전송이 성공적으로 진행되는 줄 알았는데 3일 후에도 진행의 큰 진전이 없었다. 기존 카산드라의 용량이 412.12 GiB였기 때문에 이 속도로는 미러링이 한달은 걸릴 것 같아서 (😅) 전송 속도 제한을 수정하기로 했다.
전송 속도 제한 해제 및 조정
카산드라는 기본적으로 노드 간 데이터 전송 속도에 제한이 걸려 있다.
처음엔 속도를 최대로 높이기 위해 nodetool setstreamingthroughput 0로 설정했으나, 한꺼번에 너무 많은 데이터가 몰리면서 Java Heap Memory 부하가 발생했다.
ERROR [StreamReceiveTask:1] 2026-01-12 15:40:30,123 CassandraDaemon.java:228 - Exception in thread Thread[StreamReceiveTask:1,5,main]
java.lang.OutOfMemoryError: Java heap space
at java.nio.HeapByteBuffer.(HeapByteBuffer.java:57) ~[na:1.8.0_292]
at java.nio.ByteBuffer.allocate(ByteBuffer.java:335) ~[na:1.8.0_292]
at org.apache.cassandra.io.util.SafeMemoryWriter.reallocate(SafeMemoryWriter.java:68) ~[apache-cassandra-4.1.x.jar:4.1.x]
메모리 초과 에러 이후, nodetool setstreamingthroughput 500로 서버가 감당할 수 있는 수준인 500Mbps로 다시 조절하여 미러링을 진행했다.
컴팩션 작업 처리 속도 제한 조정
카산드라는 기본적으로 컴팩션 작업이 시스템 리소스를 과도하게 점유하여 서비스 성능에 영향을 주지 않도록 속도를 제한한다.
💡 컴팩션(Compaction)이란?
카산드라의 스토리지 엔진인 LSM Tree 구조의 핵심 유지보수 프로세스이다. 디스크에 존재하는 여러 개의 SSTable 파일을 읽어들여, 중복된 키를 병합하고 삭제된 데이터를 정리한 뒤 단 하나의 새로운 SSTable로 재생성하는 작업을 의미한다.
위에서 말했다시피 카산드라는 쓰기 성능 극대화를 위해 Append-only 방식을 사용하는데, 이때 데이터의 수정이나 삭제가 발생해도 새로운 타임스탬프를 가진 데이터를 새로운 SSTable에 기록한다. 이로 인해 시간이 지날수록 동일한 파티션 키에 대한 데이터 조각이 여러 SSTable 파일에 분산되어 존재하게 되며, 이는 읽기 성능 저하를 유발한다. 이를 해결하기 위해 컴팩션이 필요한 것이다.
컴팩션이 실행되면 시스템 내부적으로 다음과 같이 연산이 수행된다.
- 병합 정렬(Merge Sort) : 여러 SSTable에 흩어진 데이터를 파티션 키 기준으로 정렬하여 하나로 합침
- 최신 데이터 유지 : 동일한 키에 대해 여러 버전의 데이터가 존재할 경우 타임스탬프가 가장 최신인 데이터만 남기고 이전 데이터는 폐기
- 삭제 데이터 정리 : 삭제 명령(
DELETE)으로 인해 톰스톤(Tombstone) 마킹이 된 데이터 중,gc_grace_seconds(기본값 10일)가 지난 데이터를 물리적으로 디스크에서 영구 삭제
nodetool setcompactionthroughput 0를 사용하면 속도 제한을 완전히 해제하여, 시스템이 낼 수 있는 최대 성능으로 컴팩션을 수행하게 된다. nodetool compactionstats를 사용하면 현재 수행 중인 컴팩션 작업의 종류, 진행률, 남은 예상 시간 등을 실시간으로 확인할 수 있다.
실제 412.12GiB였던 카산드라의 용량이 212.12GiB까지 줄어들었으며, 미러링이 끝난 후에는 nodetool setcompactionthroughput 16로 다시 컴팩션 작업 처리 속도를 조정해주었다. (그렇지 않으면 실제 서비스의 응답 지연이나 Request Timeout이 발생할 수 있다.)
미러링 완료 👍🏻
nodetool status를 입력하여 datacenter2의 Load 용량이 비슷해질 때까지 늘어나는지 모니터링한다.
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN datacenter1_Public_IP 212.12 GiB 16 100.0% xxxx-xxxx-xxxx-xxxx-xxxx rack1
Datacenter: datacenter2
==================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN datacenter2_Public_IP 212.13 GiB 16 100.0% xxxx-xxxx-xxxx-xxxx-xxxx rack1
실제 우리 카산드라 서버에서 nodetool status를 입력하면 나오는 값이다. 전송 속도와 컴팩션 속도를 조정한 후, 이전보다 훨씬 빠른 속도로 미러링이 진행되었고 대략 3시간 만에 완료되었다.
우리 센터(datacenter1)와 다른 센터(datacenter2) 서버의 용량이 완벽히 일치하지 않는 이유는, 카산드라가 데이터를 물리적 파일인 SSTable로 병합하는 시점이 노드마다 다르기 때문이다. 또한 각 노드에서 생성하는 인덱스 및 메타데이터의 크기 차이로 인해 발생하는 정상적인 오차 범위이며, 데이터 유실이 아닌 분산 시스템의 일반적인 특징이다.
nodetool status에서의 Status와 State란? 🤔
참고로 nodetool status 명령어를 실행했을 때 출력되는 Status와 State는 상태 코드로 각각 노드의 현재 상태와 클러스터 내 멤버십 상태를 의미한다.
| 구분 | 의미 |
|---|---|
| Status | 노드의 네트워크 연결 및 활성화 여부 |
| State | 노드의 클러스터 링 참여 단계 및 데이터 처리 상태 |
Status
- U (Up) : 노드가 정상적으로 실행 중이며, 가십(Gossip) 프로토콜을 통해 통신이 가능한 상태
- D (Down) : 노드가 응답하지 않거나, 네트워크 연결이 끊긴 상태
State
- N (Normal) : 정상적으로 토큰 링에 포함되어 읽기/쓰기 요청을 처리하는 상태
- J (Joining) : 클러스터에 새로 추가되어 데이터를 받아오고 있는 상태 (Bootstrap)
- L (Leaving) : 클러스터에서 제거되는 중이며, 트래픽 처리를 중단하고 데이터를 다른 노드로 이관하는 상태
- M (Moving) : 노드의 토큰 범위를 변경하거나 IP를 변경하여 이동 중인 상태
주요 상태 코드 조합
| 코드 | 상태 명 (Full Name) | 상세 설명 및 조치 필요성 |
|---|---|---|
| UN | Up / Normal | [정상] 노드가 살아있고, 정상적으로 서비스 트래픽을 처리 중임 모든 노드가 이 상태여야 서비스가 안정적임 |
| UJ | Up / Joining | [작업 중] 노드가 부팅되어 클러스터에 합류 중임 다른 노드로부터 데이터를 스트리밍 받는 단계로, 완료되면 UN으로 변경됨 |
| DN | Down / Normal | [장애] 클러스터 멤버로 등록되어 있으나 현재 응답이 없음 프로세스 다운, 서버 장애, 또는 네트워크 단절을 의미하며 즉각적인 확인 필요 |
| UL | Up / Leaving | [작업 중] nodetool decommission 명령 등을 통해 클러스터에서 빠져나가는 중작업이 완료되면 목록에서 사라짐 |
| UM | Up / Moving | [작업 중] 토큰 재분배 등으로 인해 노드 위치가 변경되는 중 완료될 때까지 시스템 부하가 증가할 수 있음 |