Deformable Convolutional Networks(DCN)
Author:
Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, Yichen Wei
Abstract

Code: https://github.com/msracver/Deformable-ConvNets
이 논문은 CNN의 다양한 변형을 처리하는데 한계가 있어 한계를 개선하기 위해 Deformable Convolution 과 Deoformable RoI 풀링 이라는 두 가지 방법을 제안했다. 이는 Microsoft Research Asia에서 개발한 방법으로, 2017년 ICCV에서 발표 되었다.
CNN은 고정된 구조만을 사용하여 몇 가지 단점이 있다.
1) 스케일 불변성 부족
입력 이미지에 나타나는 패턴이 필터 크기에 맞춰져 있을 때는 잘 작동하지만, 객체가 더 크거나 작은 경우에는 필터가 적절하게 패턴을 인식하지 못합니다.
2) 위치 불변성 부족
고정된 필터는 객체가 이미지 내에서 이동하거나 변형된 경우에도 동일한 방식으로 처리합니다. 따라서 객체가 위치를 약간만 달리해도 필터가 이를 잘 인식하지 못할 수 있습니다.
Deformable Convolution

(a): 기존의 Convolution에서 값을 추출하는 영역
(b),(c),(d)는 Deformable-Convolution으로 값을 추출하는 영역
Deformable Convolution Networks
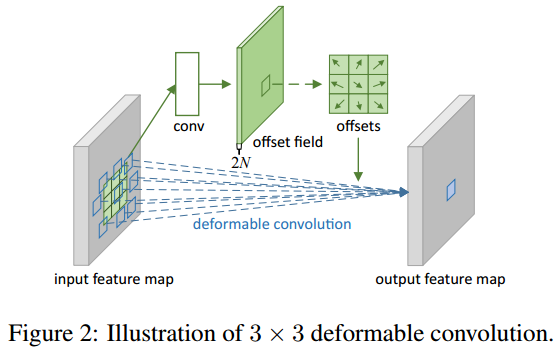
위 그림은 Deformable Convolution을 나타낸 그림이다.
기존의 filter map에 대해 offset을 추가하여 위치가 살짝 변하는 모습을 볼 수 있다.
이것이 본 논문의 핵심 기술이며, 논문의 저자들이 시도한 방법이다.
고정된 image는 정해진 주변 값들만 파악할 수 있는 한계를 적절한 위치로 어느정도 이동할 수 있도록 offset을 추가하여 한계를 해결한 그림이다.
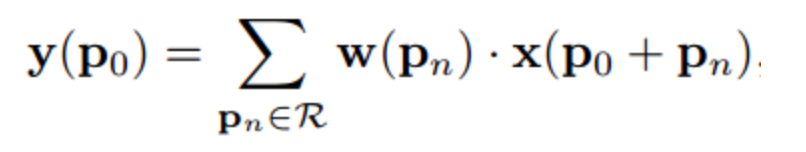
-기존 특징 추출 수식-
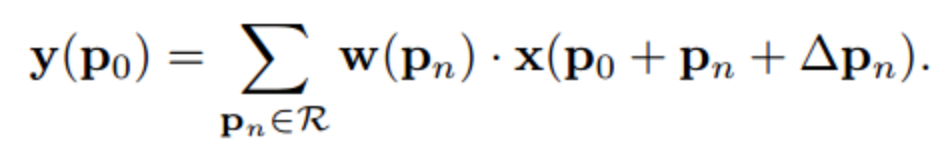
-deformable convolution 수식-
Δp는 추가된 offset을 의미한다.
offset이 추가 되어 좀 더 넓은 범위의 grid 영역에서 특징을 추출한다는 의미이다.
또한 offset은 학습이 가능하고 아주 작은 값이기 때문에 소수점이 될 수 있다.
여기서 디지털로 이루어진 픽셀 사이의 소수점 값은 존재하지 않는다. 본 논문의 저자는 픽셀간 bilinear interploation(선형 보간법)으로 해결했다.
deformable convolution 예 1)
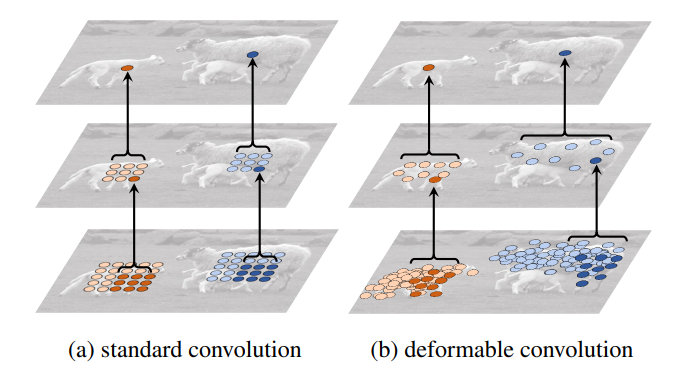
다음은 deformable convolution을 보여주는 사진이다.
standard convoltion은 filter의 위치가 고정되어 있기 때문에 어떤 물체가 들어와도 동일한 위치로 물체의 특징을 파악하지만 deformable convolution은 filter의 위치가 offset으로 인해 filter의 위치가 변하는 것을 볼 수 있다.
deformable convolution 예 2)

붉은 점 : deformable convolution filter에서 학습한 offset을 반영
초록색 사각형 : filter의 output 위치
일정하게 샘플링 패턴이 고정되어 있지 않고, 큰 object에 대해서는 receptive field가 더 커진 것을 확인할 수 있다.
Deformable RoI Pooling

deformable convolution 과의 차이점은 offse값을 convolution이 아닌, fully-connected 연산을 통해 구했다.
fully-connected란?
Fully Connected Layer(=Dense layer)은 한 층(layer)의 모든 뉴런이 다음 층(layer)의 모든 뉴런과 연결된 상태의 층(layer)에서 1차원 배열의 형태로 이미지를 정의된 라벨로 분류하는 계층을 말한다.
Deformable RoI Pooling 예

Deformable RoI pooling을 사용했을 때, 좀 더 중요한 정보를 갖고 있는 RoI를 이용한다는 것을 확인할 수 있고, 붉은 사각형의 모양이 object 형태에 따라 다양한 형태로 변형되는 것을 볼 수 있다.
Performance
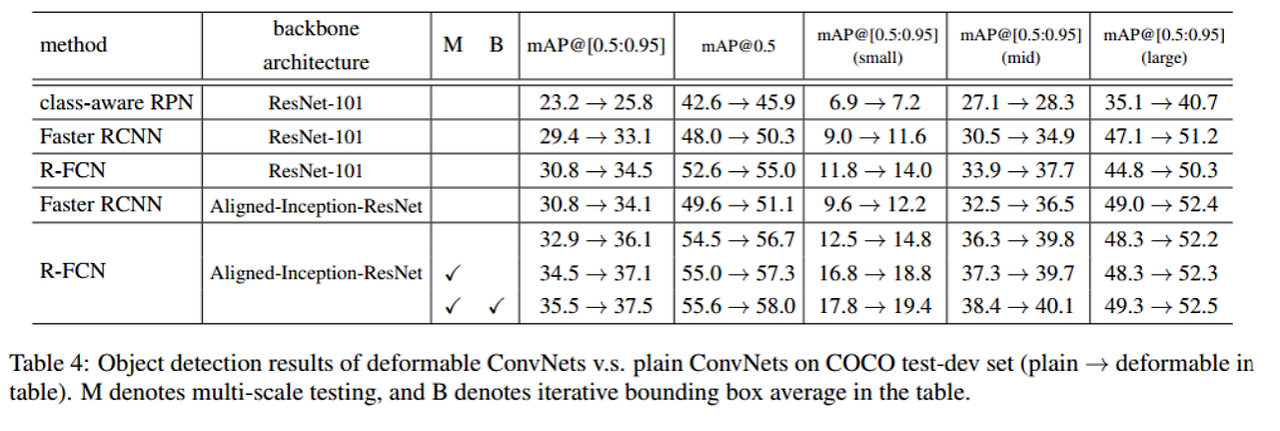
Backbone 모델
1) ResNet-101
2) Inception-ResNet
deformable 방법을 사용하니 성능이 향상되었음을 알 수 있다.
