Going deeper with convolutions
https://arxiv.org/pdf/1409.4842v1
Author:
Christian Szegedy [1],Wei Liu[2],Yangqing Jia [1],Pierre Sermanet [1],Scott Reed[3],Dragomir Anguelov [1],Dumitru Erhan [1],Vincent Vanhoucke [1],Andrew Rabinovich[1]
1.Google Inc
2.University of North Carolina, Chapel Hill
3.University of Michigan

이 논문은 Code Name "Inception"이라는 deep CNN 아키텍처를 제안한다.
이 아키텍처에서 제일 중요한 달성 사항은 네트워크 내의 계산해야할 리소스들을 더 나은 방법으로 사용했다는 점이다. 또한 이 논문에서 언급되는 GoogLeNet으로 ILSVRC14에서 1등을 했다.
Introduction
2012 ~ 2015 CNN 분야는 급속도로 발전해 왔다. 이러한 발전은 하드웨어 발전이나 더 많은 데이터의 집합 덕분이기보다는 새로운 아이디어, 알고리즘, 발전한 네트워크 아키텍처 덕분이라고 한다.
GoogLeNet에서 주목할 만한 점은 본 논문에서는 전력과 메모리 사용을 효율적으로 설계하여 모바일이나 임베디드 환경에 적용시킬 수 있게 한 것이다.
이 논문에서 deep은 두 가지 의미를 가진다고 한다.
첫번째는 Inception 모듈이라는 새로운 형태의 구성을 제안하고, 두번째는 매우 깊은 network를 의미한다.
Motivation and High Level Considerations
DNN의 성능을 높이는 가장 단순하면서 정확한 방법은 depth(layer 수), width(사이즈)을 늘리는 것이라고한다. 그러나 이러한 접근은 두 결점이 존재한다고 한다.
첫번째는 사이즈를 키운다는것은 Overfitting을 야기하고 두번째는 데이터의 수를 늘리면 해결될 문제이지만 비용측면에서 다소 무리가 있다.
두번째는 균등하게 증가된 network는 컴퓨팅 자원을 더 많이 잡아먹는다.
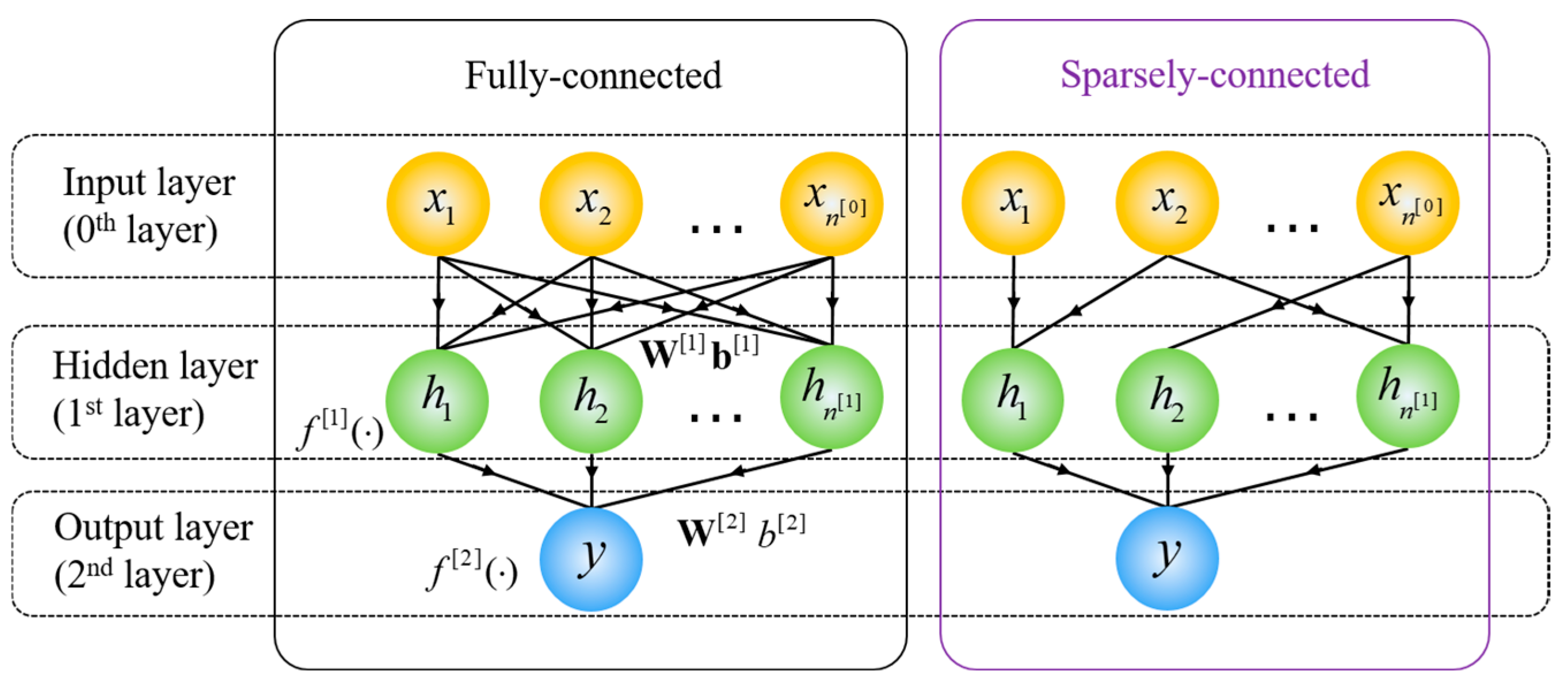
두 가지 문제를 해결하는 근본적인 방법은 fully connected에서 sparsely connected 구조로 변경하는 것이다.
Fully Connected
정의: 모든 노드(뉴런)가 이전 레이어의 모든 노드와 연결된 상태
특징:
각 노드가 모든 입력 정보를 받아들일 수 있으므로 정보 전달이 매우 풍부하고연산량과 메모리 사용량이 많아지며, 큰 네트워크에서는 계산 비용이 증가
장점: 모델이 고차원의 복잡한 데이터를 학습하기에 적합하며, 주로 마지막 분류 레이어에서 많이 사용됩니다.
단점: 연산 비용이 매우 높고, 파라미터 수가 급격히 증가하여 오버피팅 가능성이 커집니다.
Sparsely Connected
정의: 일부 노드들만 서로 연결된 상태로, 모든 노드가 연결된 것은 아닙니다.
특징:연결 수가 제한되므로 연산량과 메모리 사용량이 줄어듭니다.
ConvNet의 합성곱 레이어나 RNN의 연결 구조가 대표적인 예입니다.
장점: 계산 비용이 절약되고 파라미터 수가 줄어들어 오버피팅 위험이 낮아집니다. 주로 특정 영역(지역적 특징)에서 유용한 정보를 추출하는 데 효과적입니다.
단점: Fully Connected에 비해 연결 밀도가 낮아, 학습할 수 있는 정보의 범위가 좁아질 수 있습니다.
Architectural Details
Inception의 주요 아이디어는 convolutional vision network에서 최적의 local sparse 구조를 어떻게 하면 현재 사용 가능한 dense component로 구성할지에서 기반을 했고 본 논문의 Inception에서는 편의를 위해 filter size를 1x1, 3x3, 5x5로 제한했으며 Pooling이 CNN의 성공에 있어 필수 요소기 때문에, 1x1, 3x3, 5x5 conv layer에 이어 pooling도 추가했다고 한다.3✕3, 5✕5 비율의 convolution이 높은 계층으로 갈 수록 증가하는데 5✕5 convolution의 수가 많지 않더라도 이 convolution은 수많은 필터를 갖는 convolution 위에 추가하기엔 상당히 연상량이 높아서 안좋다. 또한 Pooling 계층의 출력을 convolution 계층의 출력과 합치는 것은 단계별로 출력의 개수를 늘릴 수 밖에 없기에 이 아키텍처는 최적의 sparse 구조에 매우 비효율적이라고 한다.
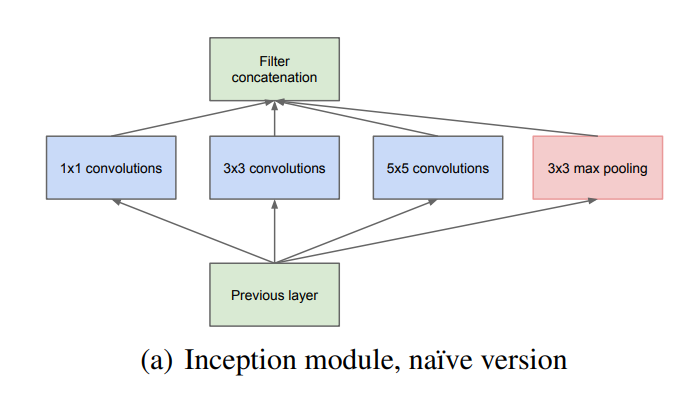
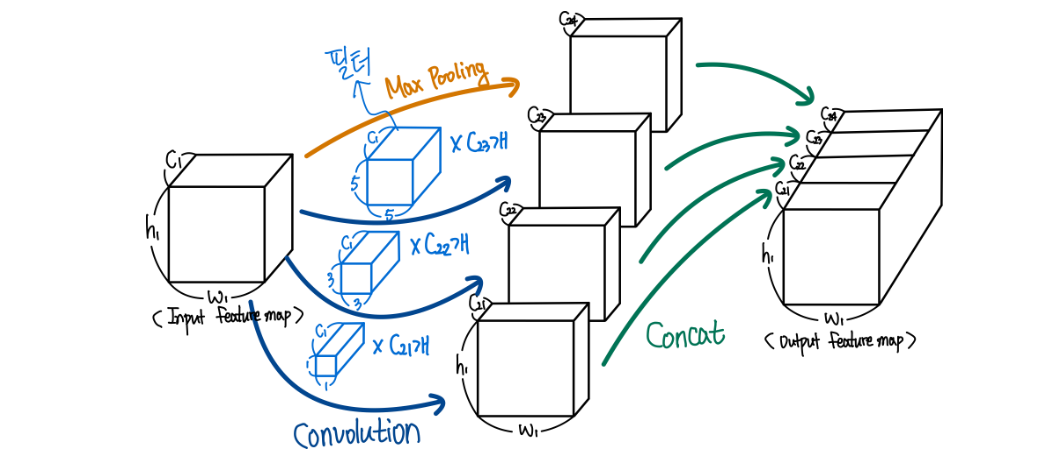
Inception module
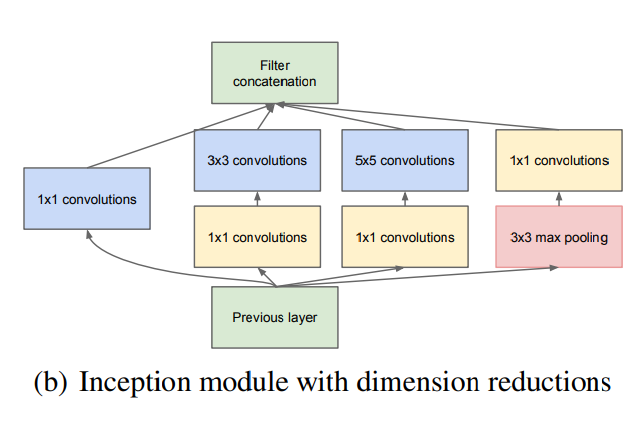
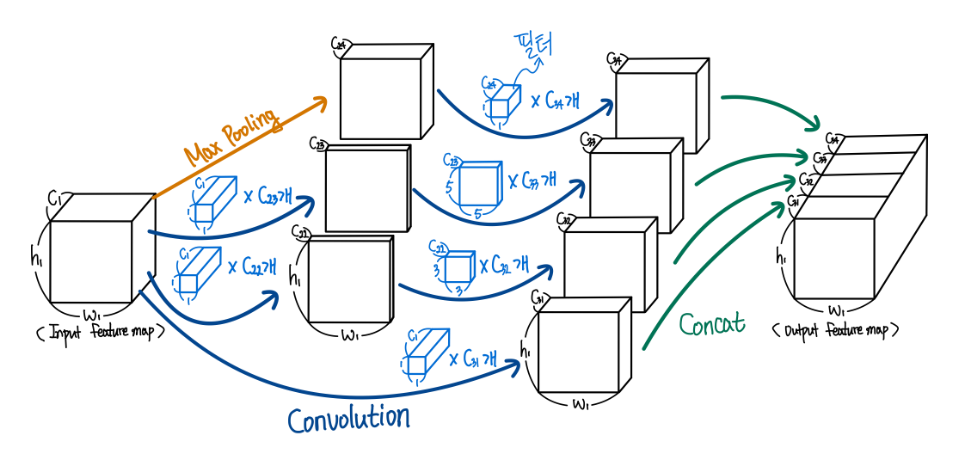
새로운 버전의 Inception 모듈은 1x1 conv를 제외한 각각의 conv layer 앞에, pooling layer에는 뒤에 1x1 conv를 적용시켜 dimension reduction(차원축소) 효과를 보게 했다.
메모리 효율 문제로 모델의 초반엔 기존의 CNN의 방식을 따르고 이후엔 Inception 모듈을 쌓아 사용했고, 그 결과 3x3과 5x5와 같이 큰 patch에서의 conv 연산을 진행기 전에 연산량 감소가 이루어졌고, 여러크기의 patch에서 얻은 출력으로 인해 여러 스케일에서 동시의 특징을 추출할 수 있게 되었다.
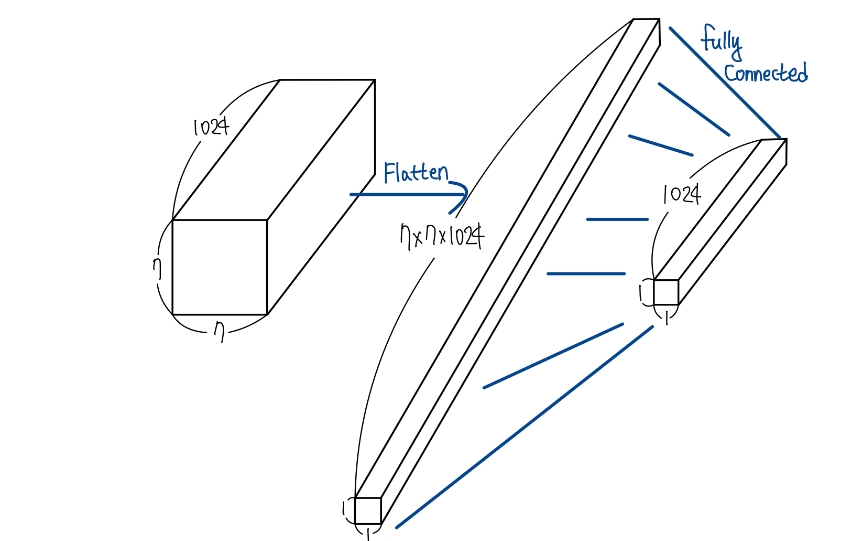
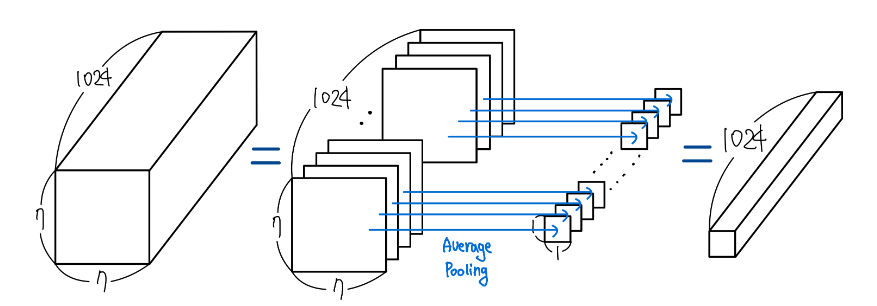
Average Pooling
본 논문에서는 추가적으로 학습 파라미터 수도 줄이고 Overfitting을 방지할 수 있는 방법을 제안한다.
네트워크 마지막 부분에 Fully Connected 연결 대신 Average Pooling을 사용하는 방법이다
Auxiliary classifier
-
GoogLeNet에서 처음 도입된 개념(Training을 잘하도록 도와주는 보조 역할)
-
gradient 전달이 잘 되지 않는 하위 layer을 training하기 위해 사용
-
classification의 문제를 해결하는 Neural Network는 softmax를 맨 마지막 layer에 딱 하나만 놓는데, Auxiliary classifier는 중간중간 에 softmax를 두어 중간에서도 역전파를 하게 함
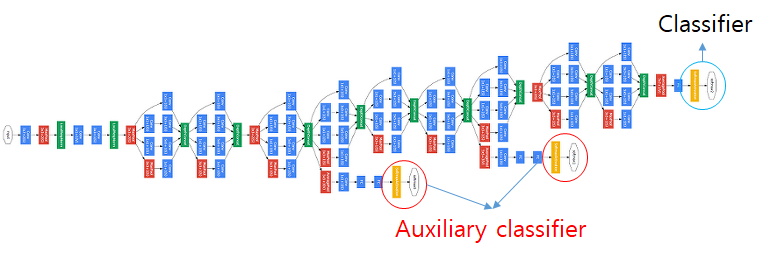
Auxiliary classifier 설명 ->https://technical-support.tistory.com/87
GoogLeNet
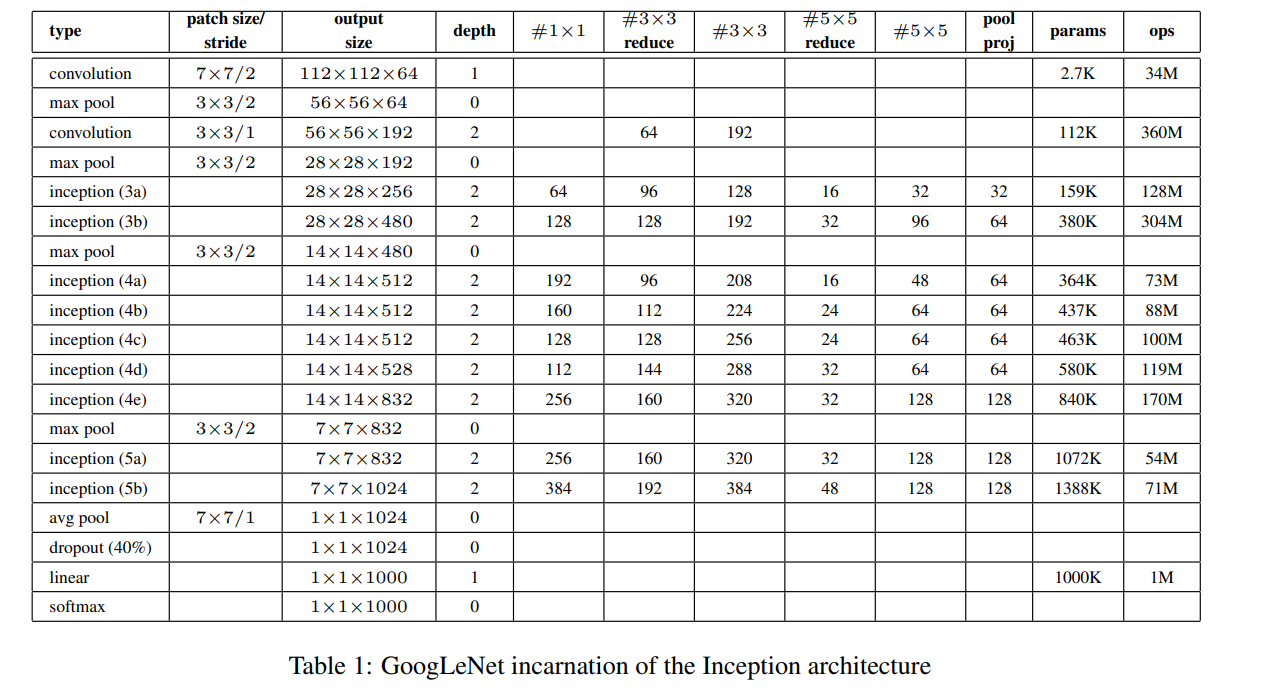
GoogLeNet 구성표
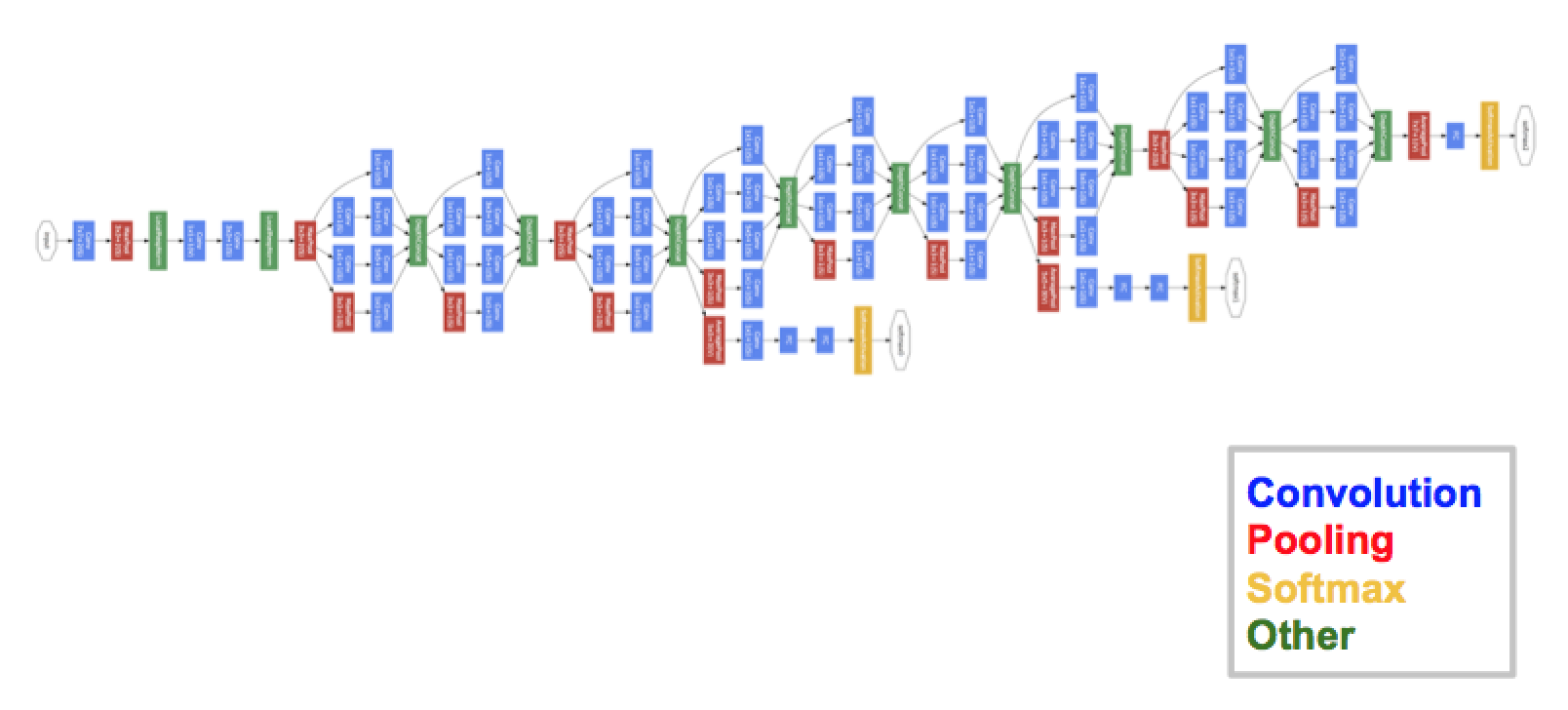
GoogLeNet 전체 네트워크
코드 구현
Inception: https://github.com/namduhus/GoogLeNet/blob/main/src/models/module/Inception.py
GoogLeNet:
https://github.com/namduhus/GoogLeNet/blob/main/src/models/GoogLeNet.py
Pytorch: 2.5.0
IDE: VSCode
CUDA:12.1
주요 논점
Inception Module 설계: GoogLeNet은 다양한 커널 크기를 병렬로 사용하는 Inception 모듈을 통해, 네트워크가 이미지의 다양한 특징을 학습하도록 설계되어있다. 이 구조는 더 깊고 넓은 네트워크를 효과적으로 사용할 수 있도록 한다.
네트워크 깊이의 확장: GoogLeNet은 22층 깊이의 구조로, 당시의 다른 신경망에 비해 매우 깊은 네트워크이며, 이로 인해 더 복잡한 특징을 학습할 수 있으며, 분류 성능을 크게 향상시켰다.
1x1 합성곱의 사용: Inception 모듈에서 1x1 합성곱을 사용하여 차원 축소를 수행하고, 이를 통해 계산 비용을 줄이면서도 모델의 표현력을 유지할 수 있다.
네트워크의 효율성: GoogLeNet은 기존의 다른 모델들에 비해 파라미터 수가 훨씬 적으면서도 높은 성능을 발휘하도록 설계되었고, 이를 통해 효율성과 성능의 균형을 맞춘 모델로 평가받았다.
분류 성능 향상: GoogLeNet은 ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 2014에서 우승했으며, 당시 가장 높은 이미지 분류 정확도를 달성했다.
