DAKD: Data Augmentation and Knowledge Distillation using Diffusion Models for SAR Oil Spill Segmentation
https://arxiv.org/pdf/2412.08116
Abstract

본 논문에서는 해양에서 발생하는 유출 사고는 심각한 환경적 위험을 초래하므로 조기 탐지가 필수적이라고 말합니다.
SAR(Synthetic aperture radar)기반으로 한 오일 유출 분할(oil spill segmentation)은 다양한 조건에서 강력한 모니터링을 제공하지만, 라벨이 지정된 데이터의 부족과 SAR 이미지의 고유한 스펙클 노이즈로 인해 어려움에 직면한다고 합니다.
이러한 문제를 해결하기 위해, 본 논문에서는
확산 기반 데이터 증강 및 지식종류(DAKD)파이프라인 제안
새로운 SAR oil spill segmentation 네트워크인 SAROSS-Net을 제안합니다.
DAKD 파이프라인에서, 저자들은 현실적인 SAR 이미지와 세그멘테이션 라벨을 생성하기 위해 두 가지 모달리티 간의 균형을 효과적으로 조정하여 합동 분포를 학습하는 확산 기반 SAR-JointNet을 소개합니다.
또한 파이프라인은 학습 데이터를 증강하고 SAR-JointNet에서 생성된 소프트 라벨(픽셀 단위 확률 맵)을 활용하여 SAROSS-Net 학습을 지도합니다.
SARoss-Net은 노이즈가 많은 SAR 이미지에서 고주파 특성을 선택적으로 전송하도록 설계되었으며, 이는 새로운 Context-Aware Feature Transfter(CAFT)블록을 스킵 연결에 적용함으로써 가능하다고 합니다.
본 논문에서는 SAR-JointNet이 현실감 있는 SAR 이미지와 정렬된 세그멘테이션 라벨을 생성할 수 있음을 입증하며, 이를 통해 증강된 데이터로 SAROSS-Net의 일반화 성능을 향상시킬수 있음을 보여줍니다. DAKD 파이프라인으로 학습된 SAROSS-Net은 기존의 SAR oil spill segmentation 방법들보다 큰 폭으로 우수한 성능을 보여줍니다.
Introduction
해양 유출 사고는 해상 석유 시추, 선박 사고, 자연적인 누출로 인해 발생하며, 대량의 석유가 해양으로 유출되어 해양 생태계와 연안 경제에 심각하고 종종 되돌릴 수 없는 위협을 초래한다고 합니다.
따라서 조기 탐지와 정확한 피해 평가가 필요합니다.
SAR는 마이크로파 신호를 방출하고 지표에서 반사된 산란 시호를 측정하여 모든 날씨와 조명 조건에서 데이터를 수집할 수 있어 원격 감지 방식 중 두드러지는 기술입니다. SAR 이미지를 분석하면 해양에서 유출된 석유 영역을 탐지하고 추정하는 데 매우 중요합니다. 또한, 유출된 석유는 표면 거칠기를 감소시켜 영향을 받은 영역을 SAR이미지에서 어두운 점으로 나타나게 만듭니다. 이러한 어두운 영역을 탐지함으로써, SAR기반 방법은 유출된 석유의 범위를 정확히 식별하고 분할 할 수있습니다.
그러나 SAR 기반 oil spill segmentation에는 두 가지 주요 문제가 있습니다.
-
오일 유출 데이터와 정확한 라벨의 부족: SAR오일 유출 데이터는 사고 발생 빈도가 낮고 라벨 주석이 복잡하기 때문에 제한적입니다.
-
SAR이미지의 고유한 스펙클 노이즈: 이는 기본 반사체 간의 무작위 간섭에 의해 발생하며, 주요 특징을 가리고 목표와 배경을 구분하는 데 어려움을 줍니다.
이 논문에서는 라벨이 지정된 SAR oil spill segmentation의 부족 문제를 해결하기 위해 확산 기반 데이터증강 및 지식 증류(DAKD) 기법을 제안합니다.
특히, 생성 모델, 확산 모델의 성공은 데이터 증강에서의 사용을 증가시킵니다.
확산 모델의 기능을 확장하여 SAR 이미지와 라벨에 해당하는 로짓 값을 생성함으로써 지식 증류를 수행합니다. 이를 위해 SAR 이미지와 세그멘테이션 맵의 분포를 합동으로 모델링하는 SAR-JointNet을 제안합니다.
또한 로짓으로부터 풍부한 정보를 포함하는 픽셀 단위의 클래스 확률(soft label)을 생성하기 위해 교차 엔트로피 손실을 사용하여 라벨 생성을 최적화 합니다.
SAR-JointNet에서 생성된 소프트라벨은 one-hot 인코딩된 hard label과 비교하여, soft label은 각 클래스에 대한 더 풍부한 확률 정보를 포함하고 있어 SAROSS-Net이 보다 효과적으로 학습하고 분할 성능을 향상시킬 수 있도록 합니다.
자연 이미지와 달리, SAR 이미지는 과도하게 고주파 노이즈를 포함하고 있어, 노이즈가 많은 특징들 중에서 선택적으로 특징을 추출하는 것이 정확한 분할에 매우 중요합니다. 이를 해결하기 위해 우리는 CAFT 블록을 스킵 연결에 도입하여, MambaVision 인코더에서 디코더로 인코딩된 특징을 선택적으로 전송할 수 있도록 합니다. CAFT블록은 의미론적 특징을 효과적으로 참조하여 중요한 고주파 특징에 우선순위를 두어, 노이즈가 많은 조건에서도 분할 정확도를 향상시킵니다.
Introduction 요약
문제 정의:
해양 유출 사고는 심각한 환경적, 경제적 위협을 초래하며 조기 탐지가 필수적이다.
SAR은 모든 날씨와 조명 조건에서 데이터를 수집할 수 있어 oil spill segmentation에 적합하지만, 라벨 부족과 스펙클 노이즈가 주요 도전 과제이다.
제안된 솔루션:
- DAKD 파이프라인: 데이터 증강과 지식 증류를 결합한 새로운 접근법.
- SAR-JointNet: SAR 이미지와 세그멘테이션 라벨의 합동 분포를 학습하여 현실감 있는 데이터를 생성하고 소프트 라벨 제공.
- SARoss-Net: 노이즈 많은 SAR이미지에서 의미 있는 고주파 정보를 선택적으로 추출하는 CAFT블록을 통해 높은 정확도의 분할을 수행.
핵심 기법:
- 소프트 라벨: SAR-JointNet에서 생성된 확률 기반 라벨을 사용해 SARoss-Net의 학습 안정성과 일반화 성능을 향상.
- CAFT 블록: 고주파 특징을 선택적으로 추출해 노이즈가 많은 환경에서도 정확한 분할 수행
Related Work
2.1 Semantic Segmentation on SAR images
딥러닝의 발전으로, 자연 이미지에서의 Semantic Segmentation 기술은 CNN 아키텍처와 Atten-tion 메커니즘을 기반으로 크게 발전하였습니다.
최근에는 SAM과 같은 기초 모델들이 포인트, Bounding Box, Text와 같은 프롬프트를 활용하여 혁신적인 제로샷 semantic Segmentation을 보여주고 있습니다.
또한, Mamba 기반 아키텍처는 로컬 특징을 견고하게 추출하기 위해 CNN을 Structured State Space Models 및 self atten-tion 레이어와 결합하여 짧은 거리와 긴 거리의 의존성을 모두 캡처할 수 있는 새로운 인코더를 도입하였습니다.
그러나 이러한 모델들은 여전히 SAR이미지와 같은 원격 감지 데이터 유형을 처리하는 데 어려움을 겪고 있습니다.
원격 감지 분야에서는 위성의 전자광학 및 SAR 이미지를 대상으로 하는 딥러닝 기반 Semantic Segmentation 모델이 연구되었습니다.
그러나 이또한 공개적으로 이용 가능한 oil spill data의 부족은 대규모 SAM Inference 방법의 개발과 일반화를 방해하여, 다양한 실제 시나리오에서의 견고성을 제한하고 있습니다.
2.2 Data Augmentation with Diffusion Models
데이터 증강은 제한된 데이터 상황에서 데이터의 다양성과 양을 증가시켜 여러 작업의 성능을 향상시킵니다. 최근 연구들은 diffusion model의 강점을 활용하여 다양한 이미지와 해당 라벨 쌍을 생성함으로써 데이터 증강을 수행하고 있습니다.
이미지 분류에서는 텍스트를 클래스 라벨 및 조건으로 사용하여 이미지-클래스 라벨쌍을 생성하여 성능을 개선한 사례가 있습니다. 이미지 캡셔닝에서는 제한된 예술적 데이터를 이미지-캡션 쌍으로 생성하여 문제를 해결했습니다. 객체 탐지에서는 boundingbox를 기반으로 이미지를 생성하거나, diffusion model의 특징을 활용하여 이미지-경계 상자 쌍을 생성하기도 했습니다. Semantic Segmentation의 경우, 일부 연구는 이미지-스크리블 쌍을 생성하여 스크리블 지도 학습을 강화했으며, 다른 연구는 마스크를 조건으로 사용하여 의료 이미지-segmentation 마스크 쌍을 생성했습니다.
원격 감지 이미지에서는 Sat-Synth 전자광학 이미지와 해당 segmentation 마스크를 합쳐서 diffusion model의 입력으로 사용해 이를 공동으로 생성했습니다.
SAR-JointNet은 라벨이 부족한 SAR oil spill data를 해결하기 위해 SAR 이미지와 Segmentation 마스크를 생성합니다.
2.3 Knowledge Distillation
Knowledge Distillation(KD)는 더 크거나 복잡한 모델(teach model)의 정보를 더 작고 간단한 모델(student model)로 전달하기 위한 주요 기술로 떠올랐습니다.
Hinton 등의 논문에서 KD를 제안했으며, KD는 student model이 teach model의 부드러운 출력 예측(softended output predictions)을 학습하도록 하여, 올바른 클래스뿐만 아니라 다른 클래스들의 상대적 확률까지도 포착할 수 있도록 합니다.
이는 일반화 가능한 특징을 학습하는 데 유용하며, KD는 다양한 컴퓨터 비전 작업에서 적극적으로 연구되고 유용하게 활용되고 있습니다.
제안된 DAKD 파이프라인에서, 논문은 Diffusion 기반 SAR-JoinNet은 훈련 데이터 분포를 모방하는 현실감 있는 SAR 이미지와 해당 라벨을 생성할 뿐만 아니라 teacher's 지식을 포함한 로짓 값을 제공합니다.
이를 통해 student model이 증강된 데이터를 효과적을 학습할 수 있도록 합니다.
Method
3.1 DAKD Pipeline

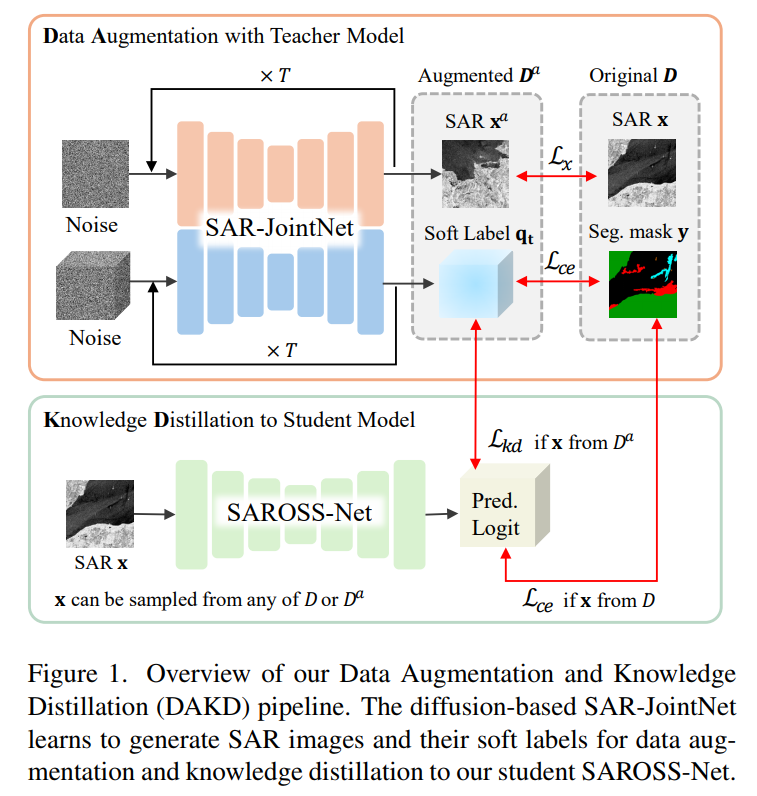
SAR oil spill segmentation을 위한 라벨이 지정된 데이터 부족 문제를 효과적으로 해결하기 위해 제안된 DAKD 프레임워크는 Figure1에 설명이 되어 있습니다.
DAKD 파이프라인은 두 단계로 구성됩니다.
1단계
DAKD 파이프라인의 첫 번째 단계에서, SAR-JointNet이 증강 데이터셋 를 생성하도록 훈련됩니다. 여기에는 SAR 이미지와 해당 로짓(logits)이 포함이 됩니다 one-hot segmentation 맵(hard-labels)과 달리, logits(soft-labels)은 클래스 예측을 포함하는 확률 정보를 제공합니다.
이러한 supervision은 픽셀 단위의 확실성을 활용하여 student model의 안정적인 학습을 가능하게 하며, 정확한 분할과 훈련 중 모델의 일반화 성능을 강화합니다.
SAR-JoinNet은 생성된 SAR 이미지와 라벨이 기존 데이터 분포를 가깝게 모방하도록 훈련되어, 기존 데이터셋을 효과적으로 보완할 수 있도록 합니다.
2단계
두 번째 단계에서는 SAR oil spill segmentation 네트워크인 SAROSS-Net은 SAR-JoinNet이 생성한 증강 데이터셋 와 원래 훈련 데이터셋 를 결합하여 학습됩니다.
Knowledge distillation의 관점에서 에 포함된 soft-labels은 hard-labels과 비교하여 훈련 안정성을 향상시키고 견고한 분할 학습을 유도합니다.
3.2 SAR-JointNet
SAR-JointNet은 JointNet의 개념을 활용하여 두 가지 모달리티(SAR 이미지와 Segementation mask)를 각각의 네트워크로 diffusion 합니다.
-
두 가지 모달리티를 위한 별도의 네트워크를 사용하면 label(segmentation mask)이 없어도 단일 모달리티(SAR 이미지)의 생성 능력을 향상시킬 수 있습니다.
-
두 네트워크가 각각의 모달리티에 집중하도록 함으로써 각 네트워크가 고유한 특징을 학습할 수 있습니다.
SAR-JointNet은 SAR 이미지 생성을 위한 SAR-Net과 logits 생성을 위한 Label-Net이라는 두 네트워크를 구현합니다. 이 두 네트워크는 서로 상호작용하며 필수적인 특징을 교환하여, 모달리티 간의 보강과 SAR 과 logits 쌍의 정렬된 생성을 가능하게 합니다.
3.2.1 Balancing Diffusion between Two Modalities
자연이미지와 픽셀단위의label diffusion-기반 합동 생성은 연구되어왔지만, 모달리티 간의 특성 차이는 간과되어 왔습니다.
SAR이미지 와 segmentation 를 동시에 생성할 때, 각 모달리티의 정보 수준이 크게 다를 수 있습니다. 따라서 모달리티 간의 정보 수준 균형을 맞추는 것이 안정적인 학습에 필수적입니다.
이러한 문제를 해결하기 위해 Chen 등 diffusion 과정에서 이미지에 미리 정의된 스케일 팩터를 적용하여 서로 다른 이미지 해상도 또는 모달리티 간의 노이즈 손상 이미지의 정보 수준을 조정했습니다.
signal-to-noise ratio(SNR)를 기반으로 하는 균형 요소 를 도입합니다.
입력 SAR와 정규화된 segmentation mask 에 대해 를 에 곱하여 각 시점에서 와 간의 정보 수준을 조정합니다. 이를 통해 모달리티 간 SNR 균형이 유지되며 효과적인 학습이 가능합니다.
정의
는 SAR이미지와 segmentation mask 간의 정보 수준을 조정하는 데 사용됩니다. 에 를 곱하여 스케일링된 마스크 를 생성합니다.
왜 가 필요한가?
SAR 이미지는 노이즈가 많고 복잡한 특징을 가지는 반면, segmentation mask는 단순하고 명확한 구조를 가진다. 이러한 정보 불균형은 학습 중 SAR이미지와 mask간에 비대칭적인 영향을 줄 수 있습니다. 를 통해 segmentation mask의 정보 수준을 조정하여 SAR이미지와의 균형을 맞춥니다.
가 적용되지 않으면 segmentation mask는 SAR이미지보다 더 많은 정보를 포함하거나 반대로 정보가 부족할 수 있기때문에 SNR균형을 유지함으로써 SAR 이미지와 mask가 각각의 역할을 균형 있게 수행할 수 있습니다.
확산 과정
시간 단계 에서 SAR 이미지와 스케일링된 마스크는 , 로 표현됩니다.
- : 노이즈가 추가된 SAR 이미지
- : 노이즈가 추가된 스케일링된 마스크
- : 신호의 강도를 나타내는 계수
- : 노이즈의 강도를 나타내는 계수
- : 정규분포에서 샘플링된 랜덤 노이즈
3.2.2 Training Strategy of SAR-JointNet
SAR-JointNet은 3단계 학습 전략이 구성되어 SAR 이미지와 segmentation mask 생성 능력을 향상시킵니다
1단계: SAR-Net 학습
SAR-Net은 노이즈가 섞인 SAR 이미지 를 디노이즈하여 원본 SAR이미지 을 복원합니다.
1단계 학습에서의 손실함수로 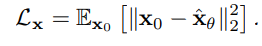
에 원본 SAR 이미지 에 대한 기대값을 계산합니다.
는 SAR-Net이 예측한 복원된 SAR 이미지이며, 노이즈가 섞인 입력 를 디노이즈한 결과입니다.
는 SAR-Net이 예측한 이미지와 원본 이미지 간의 L2손실을 계산하는 수식입니다.
즉 SAR-Net이 복원한 이미지가 실제 SAR이미지와 얼마나 가까운지 평가를 합니다.
2단계: Label-Net 학습
Label-Net은 SAR-Net의 사전 학습된 가중치로 초기화됩니다. 하지만 input 및 output 계층은 segmentation mask 채널에 맞게 초기화됩니다.
또한 Label-Net은 segmentation mask의 logits을 생성하도록 학습됩니다.
손실함수로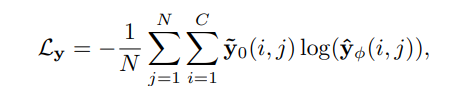
은 실제 segmentation mask의미합니다.
는 Label-Net이 예측한 클래스 의 픽셀 에 대한 확률을 의미합니다.
교차 엔트로피 손실은 예측 확률 분포와 실제 라벨 간의 차이를 최소화합니다.
3단계: SAR-Net과 Label-Net의 합동 학습
SAR-Net과 Label-Net을 함께 미세 조정하여 SAR 이미지와 segmentation mask 간의 일관성을 확보합니다.
손실함수로
SAR 이미지 복원 손실값()값과 segmentation mask 예측 손실()을 결합하여 학습합니다.
3.3 SAR Oil Spill Segmentation Network
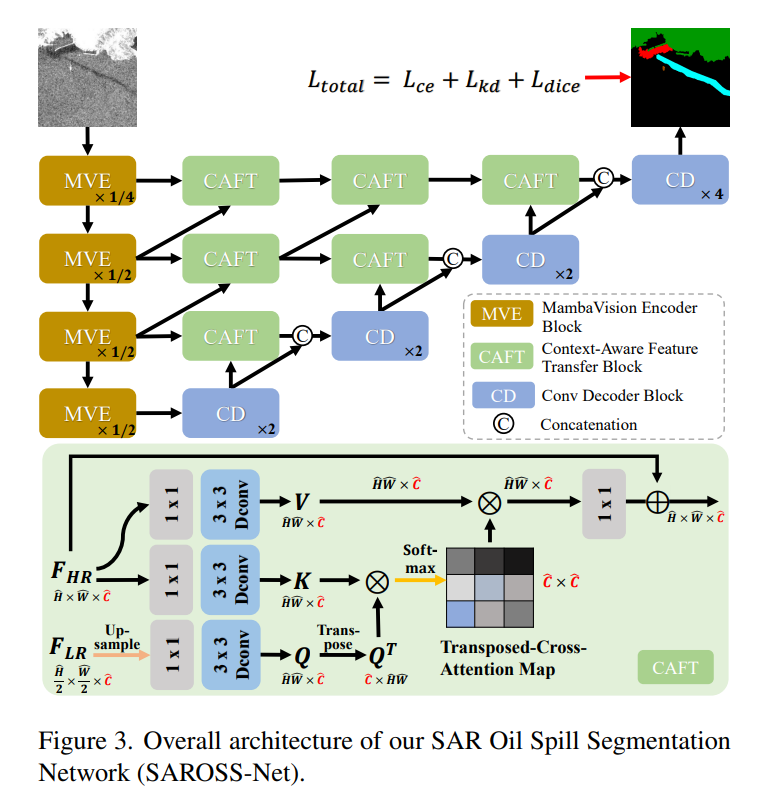
DAKD 파이프라인을 활용하여 SARJointNet은 제안된 SAROSS-Net에 지식을 전달합니다.
MambaVision Encoder 기반으로 한 SAROSS-Net의 아키텍처 입니다.
노이즈가 있는 SAR Oil Spill image에서 정확한 분할을 달성하기 위한 핵심은 분할 경계의 기능을 유지하면서 노이즈 특징을 필터링하는 것입니다.
본 논문에서는 Incoding된 특징에서 Decoder 블록으로 고주파 특징을 선택적으로 전송하기 위해 컨텍스트 인식 특징 전송(CAFT) 블록을 도입합니다. UNet++아키텍처 기반 스킵 연결을 따라 각 CAFT 블록은 저해상도(LR) 특징을 참조하여 고해상도(HR) 특징을 다음 CAFT 블록 또는 conv decoder 블록으로 전송합니다.
3.3.1 Context-Aware Feature Transfer Block
Figure 3에서 제안된 CAFT 블록은 Cross-attention의 핵심 원리를 활용합니다.
LR 특징 맵은 Query로서 semantic information를 포함합니다.
HR 특징 맵은 Key 와 Value로서 사용되며, SAR 이미지에서 중요한 고주파 공간정보를 포함합니다.
이를 통해 CAFT 블록은 노이즈가 많은 SAR이미지에서 필수적인 공간 세부정보만을 효과적으로 추출하고 LR특징의 semantic information 기반으로 전송합니다.
CAFT 블록에서는 기존 attention 메커니즘의 계산 및 메모리 부담을 줄이기 위해 transposed-attention을 사용합니다.
- 기존 attention 메커니즘의 복잡도는 , 여기서 x 는 공간 해상도를 나타냅니다.
- transposed-attention은 채널 차원에서 attention 맵을 구성하여 복잡도를 로 낮춥니다. 여기서 는 특징 맵의 채널 수 입니다.
3.3.2 Loss Functions for Training SAROSS-Net
SAROSS-Net의 학습과정에서 SAR-JoinNet이 생성한 증강SAR 이미지와 logits을 활용하기 위해 KD손실을 추가로 사용합니다. 이를 기반으로 SAROSS-Net은 증강 데이터의 정보를 효과적으로 학습하여 일반화 성능을 향상시킵니다.
KD
SAR-JointNet이 제공한 logits으로부터 soft-label을 생성합니다.
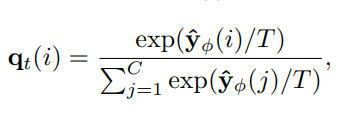
: SAROSS-Net이 예측한 픽셀 의 확률 분포를 나타냅니다.
: Hyperparameter로, 클래스 확률 분포를 부드럽게 조정합니다.
>1이면 확률 분포가 더 부드럽게 되고, 덜 확실한 정보도 강조됩니다.
= 1이면 일반적인 소프트맥스 함수와 동일합니다
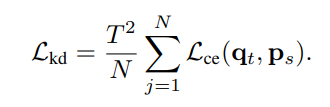
: 소프트라벨 와 SAROSS-Net이 예측한 확률 간의 교차 엔트로피 손실을 의미합니다.
: 소프트 라벨의 스케일링을 보정하기 위한 계수입니다.
: segmentation map의 전체 픽셀 수입니다.
이를 통해 SAROSS-Net이 SAR-JointNet의 더 풍부한 소프트 라벨을 학습하도록 유도합니다. 이는 모델의 일반화 성능을 향상시킵니다.
최종 손실 함수
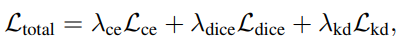
= 1: 교차 엔트로피 손실이 가장 중요하다는것을 의미합니다.
= 0.5: Dice 손실의 기여는 상대적으로 적은것을 의미합니다.
= 0.1: KD 손실의 기여는 낮지만, 모델의 일반화 성능을 개선하는 데 도움을 줍니다.
결론
SAROSS-Net은 이를 결합하여 학습됩니다.
- Cross-Entropy Loss(): 픽셀 단위의 segmentation 정확도를 보장
- Dice Loss(): 클래스 불균형 문제를 해결합니다.
- KD Loss(): SAR-JointNet의 소프트 라벨로부터 추가 정보를 학습하여 일반화 성능을 향상시킵니다.
Conclusion
본 논문에서는 DAKD(Data Augmentation and Knowledge Distillation)파이프라인을 새롭게 제안하여, SAROSS-Net의 성능을 개선하고 데이터 부족 및 제한된 라벨 문제를 해결했습니다.
SAR-JointNet:
- Diffusion 기반 SAR-JointNet은 image-label을 효율적으로 생성합니다.
- balancing factor를 도입하여 diffusion 과정동안 모달리티 간 정보 수준이 효과적으로 조화되도록 보장합니다.
Data Augmentation and Knowledge Distillation:
- SAR-JointNet이 생성한 image-label 쌍은 데이터 증강에 사용되었을뿐만 아니라, KD를 처음으로 통합했습니다.
- SAR-JointNet이 생성한 logit-based labels은 SAROSS-Net으로 효과적으로 지식을 전이할 수 있도록 지원합니다.
SAROSS-Net:
- CAFT 블록을 사용하여, 스펙클 노이즈가 포함된 SAR이미지에서도 segmentation 좋은 성능을 제공합니다.
이 접근법을 통해 SAR기반 Oil Spill Segmentation에서 SOTA을 달성했으며, 기존 기법과 비교하여 크게 향상된 결과를 얻을 수 있었습니다.
