https://arxiv.org/pdf/1411.4038
Author: Jonathan Long∗, Evan Shelhamer∗, Trevor Darrell
Abstract
-
CNN을 end-to-end방식, pixel-to-pixel방식으로 학습하여 semantic segmentation 분야에서 SOTA 달성.
-
AlexNet, VGG, GoogLeNet 등 기존 분류모델을 FCN으로 변환하고 이를 segmentation task에 맞춰 파인튜닝 진행.
-
Dense Prediction문제를 해결
End-to-End방식이란: 입력에서 출력까지의 전체 과정을 하나의 학습 가능한 모델로 연결하여 중간단계의 명시적인 feature추출, 별도의 하위 모듈처리 없이 직접적으로 학습하고 예측하는 방식
Dense Prediction문제: 공간 정보를 유지한 채로 모든 위치에 대한 출력을 생성해야 하는 문제
ex) Semanic Segmentation(의미론적 분할), Instance Segmentation(인스턴스 분할), Depth Estimation(깊이 추정), Optical Flow(광학흐름)
Introduction
-
ConvNets는 객체 인식분야의 발전을 이끌고 있으며, classification, object detation, Part and Keypoint Prediction 등 작업에 발전됨.
-
이러한 작업은 정확도와 세밀함, 픽셀 단위의 예측을 수행하는것이 자연스러운 발전 단계라고 함.
-
기존 연구에서는 Semantic Segmentation에 적용하여 객체 또는 영역의 클래스를 할당하는 작업을 수행했지만, 여러 한계가 존재한다고 언급.
-
본 연구에서는 픽셀 단위 예측을 위해 Supervised Pre-training을 기반으로 진행.
-
기존 연구들은 임의 크기의 이미지에 Dense output을 수행했지만 본 연구에서는 학습과 추론은 이미지전체를 한번에 처리.
-
network내에 Upsampling 계층을 통해 pixelwise prediction과 subsampled pooling된 네트워크 학습을 가능.
기존 연구의 한계: 패치기반 학습의 비효율성, 복잡한 전처리 및 후처리 과정, 사전학습 부족, 공간 해상도 손실, local 및 global 정보 통합의 부족
본 논문에서의 개선점: 전체 이미지 학습, Upsampling, Skip Architecture 도입
Fully convolutional networks
3.1 Adapting classifiers for dense prediction
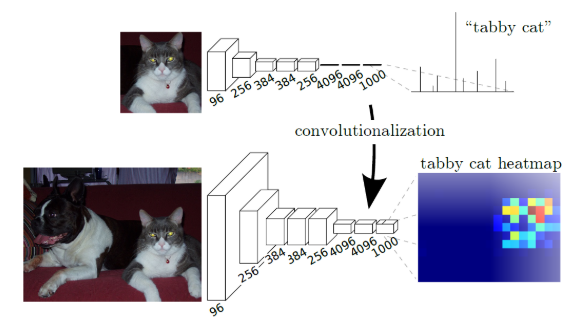
-
LeNet, AlexNet, VGG, GoogLeNet 과 같은 전형적인 네트워크 모델은 고정된 크기의 입력을 받고 비 공간적인(Non-Spatial) 출력을 생성.
-
본 논문에서는 fully connected Layer를 전체 입력을 가지는 Convolutional Layer로 변환. 이를 통해 임의 크기 입력을 처리할 수 있게 되고, 공간적 출력 맵(Spatial Output Map)을 생성.
-
효율성으로 변환된 네트워크는 각 입력 패치에 대한 예측을 수행할 수 있지만, 계산 과정에서 중첩된 부분을 공유함으로써 연산량을 줄임.
3.2 Shift-and-Stitch is filter rarefaction
Shift-and-Stitch란 Interpolation 없이 Dense Prediction을 위해 Coarse 출력으로부터 세밀한 출력을 생성하는 방법.
Interpolation 뜻: https://ko.wikipedia.org/wiki/%EB%B3%B4%EA%B0%84%EB%B2%95
Shift-and-Stitch 방법
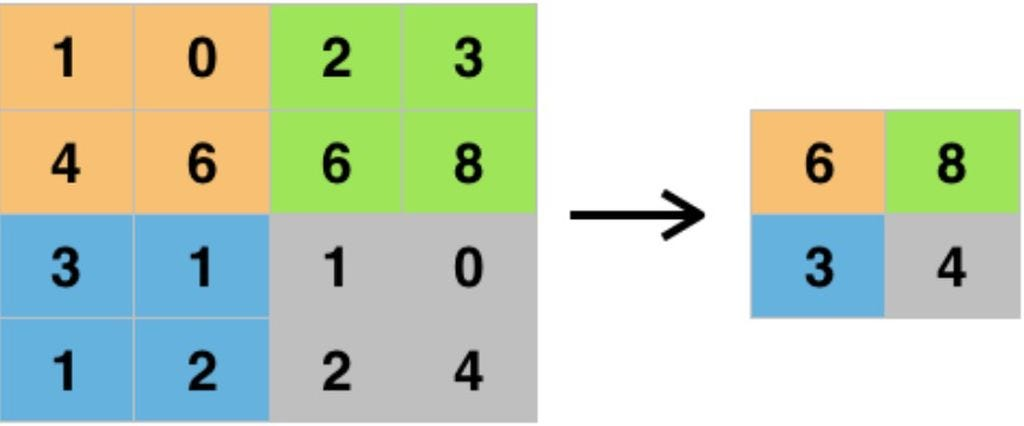
max pooling을 하고 위치 정보를 저장하여 원래의 이미지 크기로 upscaling하는 방식이지만 계산 비용이 매우크다.
- 입력값이 conv + pooling을 통과하면 크기가 감소한다. 이를 복원하는 방법으로 shift-and-stich 방법을 검토하는데, 이보다 skip connection을 사용한 upsampling이 더 효과적으로 판단하여 shift-and-stich 방법은 사용하지 않았다.
Upsampling is backwards strided convolution
논문에서 언급되는 Deconvolution은 Transposed Convolution과 동일한 말.
- Upsampling(factor f)은 1/f의 부분 stride를 사용하는 Convolution과 같은 역할.
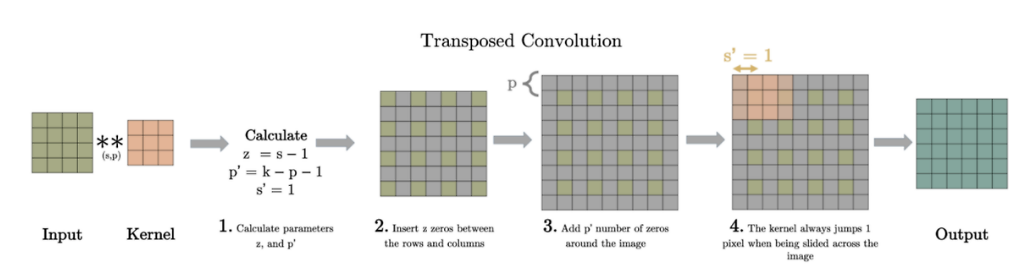
-
위와 같이 사이를 띄워주고 padding 해준 Input을 convolution하면 원하는 사이즈의 Output을 얻는다.
-
upsampling은 pixelwise loss로부터 backpropagation을 통해 end-to-end 학습을 위해 네트워크 내에서 수행된다.
Patchwise training is loss sampling
Patchwise training란 하나의 이미지에서 객체가 존재하는 위치 또는 주변 위치를 crop하여 하나의 patch로 만든 뒤 모델에 입력하는 training 방식.
-
Patchwise training을 사용하는 이유는 이미지에 필요 없는 정보들이 존재할 수 있고, 하나의 이미지에서 서로 다른 객체가 존재하는 경우 redundancy가 발생(고양이에 관련된 feature를 추출해야하는데, 필요 없는 배경까지 모두 봐야 하는 문제).
-
이미지에서 patch 이미지를 뽑아내서 필요한 부분을 위주로 training 시킬 수 있으며, class imbalance 문제를 완화할 수 있지만 공간적 상관 관계가 부족해진다는 단점.
-
patchwise training을 통해 하나의 이미지를 100개의 patch로 분할해 각 patch마다의 loss 값을 구하게 된다. 이 때, 모든 loss를 사용하는 것이 아니라 중요한 patch들의 loss만 사용하거나 가중치를 주어 loss 값을 샘플링해 사용할 수 있다고 함.
-
결과적으로는 전체 이미지를 한 번에 사용하는 fully-convolutional training은, 각 배치가 모든 수용 영역을 포함하는 패치들로 구성되는 패치별 훈련과 동일한 결과를 얻을 수 있고, whole image training이 dense prediction을 위한 training 속도 측면에서 더 효과적이고 효율적임.
Segmentation Architecture
-
upsampling과 pixelwise loss을 사용하여 dense prediction을 위해 이를 보강한다.
-
여기서 skip connection을 이용해 coarse, semantic 정보와 local, appearance 정보를 합친 개선 된prediction을 구함.
4.1 From classifier to dense FCN
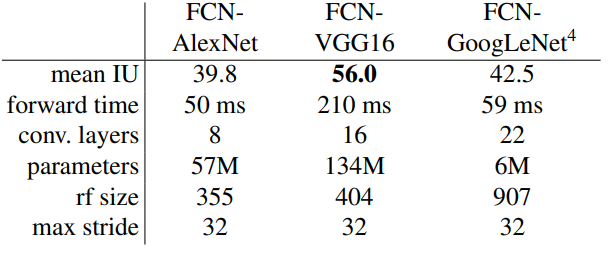
-
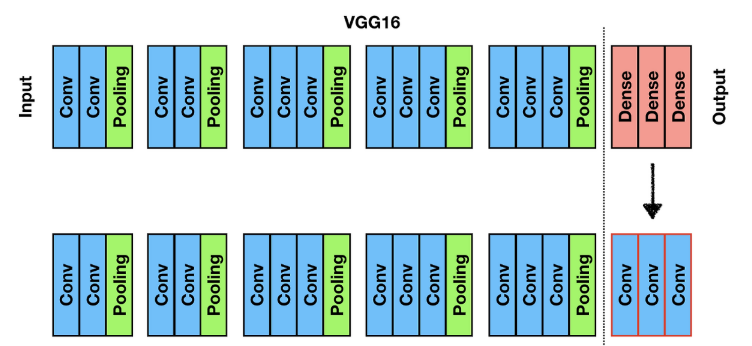
AlexNet, VGG16, GoogLeNet 중 VGG를 선택.
-
classifier layer를 버리고, 모두 fully convolution layer로 변환.
-
4.2 Combining what and where
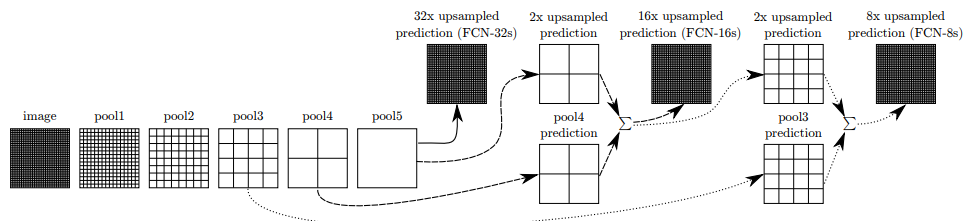
-
깊은 layer의 output일 수록 픽셀의 개수가 줄어들고(activation map)이 줄어들고, upsampling하여 디테일 한 정보까지 얻기에는 한계가 있다.
-
문제를 해결하기 위햏 얇은 layer과 깊은 layer의 activation map을 더하여 한계를 해결
Deep jet
-
1x1인 pool5의 activation map을 32배 한 upsampled prediction이 FCN-32s
-
2x2인 pool4의 activation map과 pool5를 2x upsampled prediction을 더하면 16x upsampled prediction(FCN-16s)
-
4x4 pool3과 앞서 더해주었던 prediction을 합하면 8x upsampled predicton(FCN-8s)
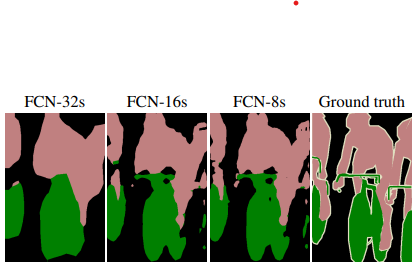
Result
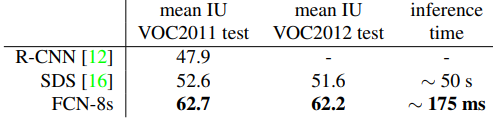
Pytorch 구현:https://github.com/namduhus/FCN-2015
Pytorch: 2.5.0
IDE: Pycharm
