Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads
https://www.usenix.org/system/files/atc19-jeon.pdf
Author: Myeongjae Jeon[†][*], Shivaram Venkataraman[‡][*], Amar Phanishayee[*], Junjie Qian[*], Wencong Xiao[§],Fan Yang[*]
[†]UNIST
[‡]University of Wisconsin
[§]Beihang University
[*]Microsoft Research

이 논문에서 머신러닝의 광범위한 발전으로 많은 대기업이 여러제품에 머신러닝 모델을 통합하기 시작했고 이러한 모델은 일반적으로 공유 멀티테넌트 GPU 클러스터에서 학습된다고 한다.
기존 클러스터 컴퓨팅 워크로드와 유사한 스케줄링 프레임워크는 기존 클러스터 컴퓨팅 워크로드와 마찬가지로 높은 효율성, 리소스 격리, 사용자 간 공정한 공유 등의 기능을 제공하는 것을 목표로 한다고 한다. 그러나 기존의 빅데이터 분석의 워크로드와 GPU에서 학습된 심층 신경만(DNN)기반 워크로드와 두 가지 중요한 점에서 차이가 있다고 한다.
1. 클러스터 활용 관점에서 GPU는 사용자 간에 세밀하게 공유할 수 없는 모놀리식 리소스가 있다.
2. 워크로드 관점에서 딥런닝 프레임워크는 갱 스케줄링을 통해 스케줄링의 유연성을 줄이고 작업 자체를 런타임에 실패에 비탄력적이다.
Gang scheduling이란 Deep Learning 워크로드에 중요한 기능으로, 모든 것 아니면 아무것도 아닌 스케줄링 기능을 가능하게 하고, 대부분의 DL 프레임워크는 모든 작업자가 실행 중이어야 학습 프로세스를 시작할 수 있기 때문이다. Gang Scheduling은 리소스 비효율성과 스케줄링 교착 상태를 때때로 방지합니다.
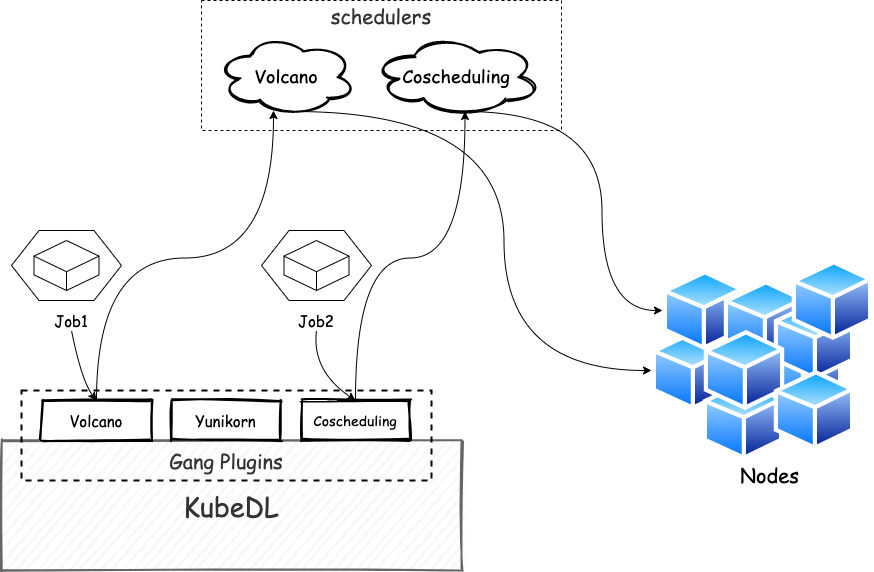
이 논문에서는 Microsoft의 Multi-tenant GPU 클러스터에서 2개월간 추적한 상세한 워크로드 특성화를 제시한다.
Scheduler logs와 individual jobs from logs를 연관시켜 Multi-tenant GPU 클러스터 의 DNN 훈련 워크로드에 대한 클러스터 활용도에 영향을 미치는 세 가지 문제를 연구했다고 한다.
1. 갱 스케줄링 및 로컬 제약이 대기열에 미치는 영향.
2. 로컬 GPU 사용률에 미치는 영향.
3. 훈련 중 일어나는 장애.
본 논문에서는 대규모 운영 경험을 바탕으로 DNN 훈련을 위한 차세대 클러스터 스케줄러와 관련된 설계 지침을 제공한다고 나왔다.
Introduce
이 논문의 Introduce를 요약하자면 Multi-tenant로 인해 발생하는 자원 경쟁 문제와 GPU 활용 패턴을 살펴보았고, 클러스터의 효율성을 향상시키기 위한 최적화 방안을 제안한다고 했다. 논문은 실제 데이터 기반의 심층적인 분석을 제공하고, 클러스터 관리와 스케줄링 효율성을 개선할 가능성을 제시한다고 나왔다.
Workloads
본 논문의 Workloads 세션에서는 대규모 멀티테넌트 GPU 클러스터에서 실행되는 딥러닝 훈련 작업의 특성과 패턴을 분석한다고 나왔다.
1. 워크로드의 구성
- 딥러닝 훈련 워크로드는 다양한 딥러닝 모델을 포함하며, GPU 클러스터에서 실행된다.
- 워크로드는 크기, 모델, 구조, 실행 시간, 자원 요구 사항등에서 매우 다양하다.
2. 작업 유형
- 짧은 작업(Short Jobs): 빠르게 완료되는 작은 규모의 훈련 작업, 대개 테스트나 실험적 훈련 작업에 해당
- 긴 작업(Long Jobs): 대규모 데이터와 복잡한 모델을 훈련 시키는 작업, 대부분의 GPU 자원을 장시간 사용하는 특징
3. GPU 자원 사용 특성
- GPU 자원의 사용 패턴
- 자원 사용률이 높은 작업은 클러스터의 효율성을 결정짓는 중요한 요인.
- 일부 작업은 과잉 할당을 받는 반면, 일부 GPU는 미사용 상태로 남는 경우도 존재.
- 워크로드는 스케줄링 자원 분배의 비효율성을 드러낸다.
4. 스케줄링의 문제
- GPU 클러스터에서 동일한 GPU에 배치되어야 하는 작업이 많은 경우, 로컬리티(Locality)제약으로 인해 자원 활용이 어려워지는 현상이 발생한다.
- 짧은 작업은 긴 작업과 함께 스케줄링될 때 종종 지연되거나 대기 시간이 길어진다.
5. 작업 실패 분석
- 워크로드의 실행 중, 다양한 실패 요인이 존재:
- 사용자 코드 오류: 잘못된 설정이나 코딩 실수.
- 인프라 문제: GPU 오작동, 네트워크 병목 및 클러스터 과부화.
- 이러한 실패는 클러스터의 전반적인 효율성과 신뢰성을 저하시키는 주요 요인.
6. 데이터 기반 워크로드 패턴
- 본 논문은 Microsoft GPU 클러스터에서 수집된 2개월간의 데이터를 활용하여 워크로드의 상세한 패턴을 분석:
- 특정 시간대에 집중되는 워크로드.
- 특정 GPU가 지나치게 사용되거나 덜 사용되는 불균형.
- 다양한 DNN 모델 훈련에 따른 자원 사용 패턴 차이.
Cluster Architecture
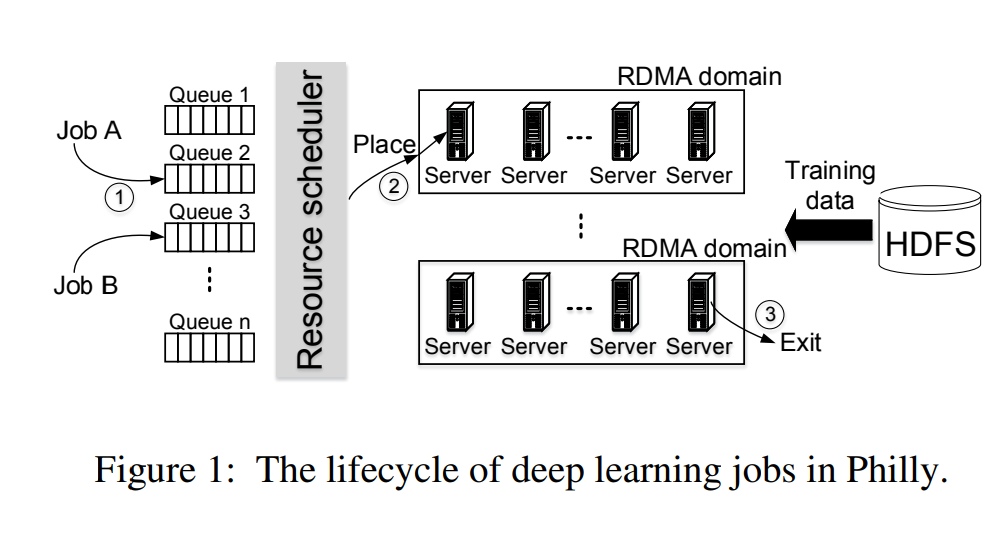
1.클러스터 구성
-
GPU 클러스터는 수천 개의 GPU로 구성된 대규모 인프라로, 멀티테넌트 환경에서 다양한 사용자가 공유.
-
각 클러스터는 다음과 같은 주요 컴포넌트로 이루어져있다.
- GPU 서버: 여러 GPU가 탑재된 물리적 노드로, 주요 컴퓨팅 작업이 실행되는 장소.
- 네트워크: GPU 서버 간, 그리고 사용자와 클러스터 간 데이터를 전달하기 위한 고속 네트워크.
- 스토리지: 훈련 데이터와 모델 가중치를 저장하는 공간.
2.GPU 서버의 구성
- 하나의 GPU서버는 4 ~ 8개의 GPU를 포함하며, 각각은 고속 네트워크를 통해 상호 연결.
- GPU는 NVIDIA의 CUDA 기반 기술을 사용하여 병렬 처리를 수행.
- GPU 서버는 CPU, 메모리, 네트워크 자원과 함께 통합적으로 수행.
3.네트워크 구조
- 클러스터는 고속 네트워크를 사용하여 데이터 전송 속도를 최적화 한다.
- 특히, DNN 훈련 작업은 대규모 데이터 전송이 필요하기 때문에 네트워크 병목을 방지하는 것이 중요하다.
- 로컬 네트워크: 같은 서버 내 GPU 간 데이터 전송.
- 글로벌 네트워크: 서버 간 또는 클러스터 외부와의 데이터 전송.
4. 작업 관리 시스템
-
클러스터는 작업 스캐줄러를 사용하여 GPU 자원을 할당하고, 여러 테넌트의 작업을 조율한다.
-
주요기능:
- 직업의 대기열 관리.
- GPU 자원 최적 분배.
- 사용자의 로컬리티 제약 사항 충족.
5. 멀티테넌트 환경
- 클러스터는 여러 사용자가 동시에 자원을 사용할 수 있도록 설계되었다.
- 테넌트 간 자원 사용의 격리가 이루어지며, 각 사용자는 자신의 훈련 작업을 독립적으로 실행할 수 있다.
- 하지만, 자원 경쟁이 심화되면 효율성이 저하될 수 있다고 한다.
6. 운영 방식
- GPU 클러스터는 대규모 데이터를 처리하고, 복잡한 DNN 훈련 작업을 실행할 수 있도록 최적화 되어 있다.
- 작업 스케줄링 및 GPU 자원 할당은 클러스터 관리 시스템에 의해 자동화 된다고 한다.
Data Collection and Analysis
1. 데이터 수집
-
수집 대상:
- Microsoft의 대규모 GPU 클러스터에서 실행된 2개월간의 작업 데이터를 기반으로 분석.
- 103,750개의 GPU 작업과 9,000개의 GPU 서버가 포함된 데이터.
- 데이터는 사용자 정의된 작업 로그와 시스템 상태 로그에서 추출.
-
수집 정보:
- 작업 메타데이터: 시작 시간, 종료 시간, 작업 길이.
- GPU 자원 사용률: GPU 메모리 사용량, 계산 작업량.
- 작업 실패 정보: 실패 이유 및 영향.
- 네트워크 대역폭 사용량.
-
목적:
- 클러스터의 자원 활용률, 작업 대기 시간, 실패율과 같은 성능지표를 평가.
2. 데이터 분석
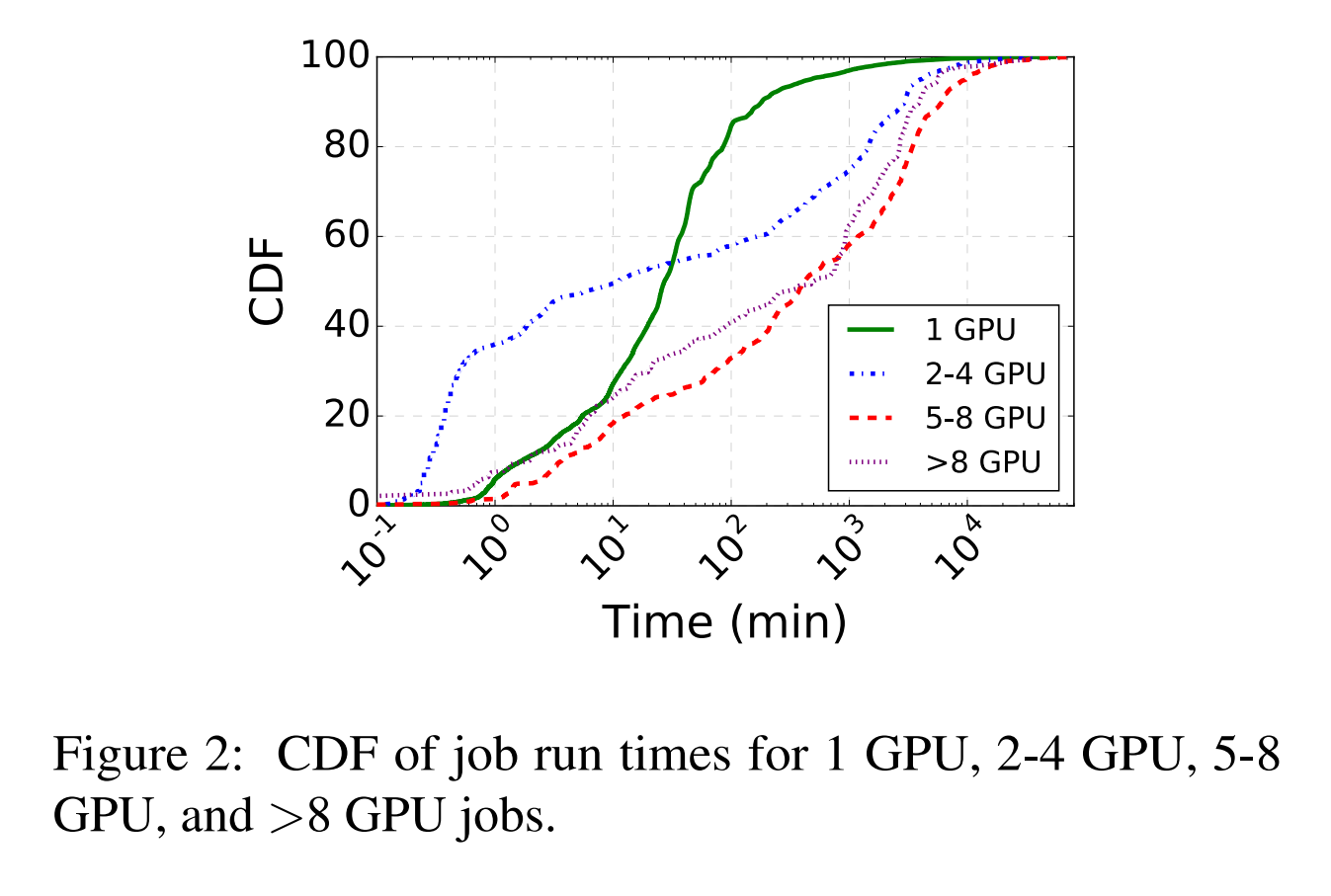
-
작업 길이와 유형
- 워크로드는 크게 짧은 작업(10분 이내)와 긴 작업(수 시간에서 수일까지)로 나뉨.
- 긴 작업이 GPU 사용률에서 상당 부분을 차지하며, 짧은 작업은 대기열에서 우선 순위가 낮아지는 경향이 있다.
-
GPU 자원 활용
- GPU 사용률은 평균 50 ~ 60% 수준으로, 많은 GPU 자원이 최대로 활용되지 못하고 있다.
- 일부 GPU는 과잉 할당으로 인한 병목 현상을 보인다.
-
작업 실패 분석
- 실패율은 약 5%로 관찰되었으며, 주된 이유로는 다음과 같다.
- 사용자 오류: 훈련 코드문제, 잘못된 설정.
- 시스템 문제: GPU 오작동, 네트워크 병목
- 사용자 오류: 훈련 코드문제, 잘못된 설정.
- 실패 작업은 클러스터 전체 효율성을 저하시킨다.
- 실패율은 약 5%로 관찰되었으며, 주된 이유로는 다음과 같다.
-
대기 시간
- 긴 작업은 대기 시간이 상대적으로 길며, 자원 경쟁이 주요 원인.
- 짧은 작업은 긴 작업에 비해 대기 시간이 짧지만, 스케줄링 문제로 인해 지연되는 경우도 있다.
-
멀티테넌시와 자원 경쟁
- 멀티테넌트 환경에서 자원 경쟁으로 인해 작업 우선순위와 배치가 비효율적일 수 있다.- 특정 테넌트가 클러스터 자원의 큰 부분을 독점하는 경우도 관찰된다.
Impact of Locality Awareness
Locality Awareness란?
- 정의:
- 작업의 GPU 배치가 데이터 전송 효율성, 모델 병렬성 등을 위해 특정 노드나 GPU에서 실행이 되어야 하는 조건.
- 필요성:
- 딥러닝 모델 훈련은 큰 데이터를 빠르게 주고받아야 하기 때문에 GPU 간 네트워크 대역폭의 효율적 사용이 중요.
- 로컬리티를 준수하면 네트워크 병목을 줄이고 데이터 전송 시간을 단축 가능.
로컬리티 인식의 긍정적 영향
- 데이터 전송 효율성 증가:
- 작업이 특정 GPU에 가까운 위치에서 실행되면 네트워크 병목 현상이 감소.
- 이를 통해 작업 속도 향상.
- 작업 병렬성 최적화:
- 모델 병렬 훈련이 더 원활히 수행되어 GPU 활용도가 향상됨.
로컬리티 인식의 부정적 영향
- 스케줄링 지연:
- 로컬리티 제약으로 인해 특정 GPU가 가용하지 않으면 작업 대기 시간이 길어질 수 있다.
- 자원 활용도 감소:
- 특정 노드나 GPU가 과부화되거나, 다른 GPU는 활용되지 않아 자원 활용 불균형이 발생.
실험 및 분석 결과
- GPU 활용도:
- 로컬리티를 강하게 준수할수록 GPU 활용도가 낮아질 가능성이 높음.
- 작업 대기 시간:
- 로컬리티를 준수하지 않을 경우 대기 시간이 줄어들지만, 데이터 전송 비용이 증가.
- 네트워크 병목:
- 로컬리티를 무시하면 네트워크 병목이 발생해 작업 완료 시간이 길어질 수 있다.
결론
- 균형 필요성:
- 로컬리티 인식의 장점(데이터 전송 효율)과 단점(대기 시간 증가, 자원 불균형)을 고려해 균형 잡힌 스케줄링 정책이 필요.
- 추천 방안:
- 상황에 따라 로컬리티를 유연하게 적용할 수 있는 스케줄링 알고리즘을 개발할 필요성.
논문의 주요 논점 요약
1. GPU 클러스터의 효율성 분석
- 대규모 멀티테넌트 GPU 클러스터에서 DNN 훈련 워크로드를 실행하는 효율성을 심층적으로 분석.
- GPU 자원 사용률과 클러스터의 자원 활용 패턴을 구체적으로 측정.
2. 워크로드 특성 파악
- 클러스터에서 실행되는 다양한 DNN 워크로드의 특성을 분석하여 모델 유형, 훈련 크기, 자원 사용 방식 등에서 차이를 규명.
3. 멀티테넌시 문제
- 다양한 테넌트 간 자원 경쟁이 클러스터 효율성과 워크로드 성능에 미치는 영향을 연구.
- 자원 과잉 할당, 불균형 사용 패턴 등 문제점 도출.
4. 스케줄링의 한계와 최적화 필요성
- 기존 스케줄링 알고리즘의 한계를 분석하고, GPU 클러스터 성능을 개선할 수 있는 최적화 가능성을 제안.
- 워크로드 기반 스케줄링 접근법이 효율성을 향상시킬 수 있음을 보여줌.
5. 시뮬레이션 및 실제 데이터 활용
- 대규모 GPU 클러스터에서의 실제 데이터와 시뮬레이션을 통해 실질적인 결과를 도출.
