Rethinking the Inception Architecture for Computer Vision
https://arxiv.org/pdf/1512.00567v3
Author:
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens

이 논문에서 모바일 비전 및 빅데이터 시나리오와 같은 다양한 환경에서 연산 효율성 과 적은 파라미터를 유지하면서 성능을 극대화하는 방법을 탐구했다고 한다.
여러 벤치마크에서 성능이 크게 향상되었으나, 모델의 크기와 연산 비용이 증가하는 것은 대부분의 작업에서 즉각적인 성능 향상을 가져오지만, 특정 사용 사례에서는 제한이 될 수 있다고 한다.
이 연구에서는 적절한 인수분해된 합성곱과 강력한 정규화 기법을 통해 네트워크를 효율적으로 확장하는 방법을 제시한다.
Introduction
VGGNet은 단순한 아키텍처의 장점을 가지면서도 높은 연산 비용을 요구하는 반면, GoogLeNet의 Inception 아키텍처는 메모리 및 연산 예산이 제한된 상황에서도 잘 작동하도록 설계되었다고 한다.
Inception 구조는 병렬적 구조와 차원 축소를 통해 효율적인 연산을 지원하지만, 구조의 복잡성 때문에 단순히 네트워크 크기를 증가시키는 것이 연산 효율성을 유지하기 어렵게 만들 수 있다.
본 논문에서는 Inception 아키텍처를 포함한 CNN을 효율적으로 확장하는 최적화 원칙과 아이디어를 제안하며, 이를 통해 구조 변경에 따른 성능 손실을 최소화할 수 있는 방향을 제시한다고 한다.
General Design Principles
[1] Avoid Representational bottleneck
네트워크 초반부에 representational bottleneck을 피한다.
Representational bottleneck: CNN에서 주로 사용되는 Pooling으로 인해 feature map의 size가 줄어들면서 정보량이 줄어드는것을 의미
[2] Higher dimensional representations are easier to process locally within a network
고차원을 가진 표현은 네트워크 내에서 로컬로 처리하기가 더 쉽고 이는 특징을 더 잘 분리하고 학습 속도를 높일 수 있다.
[3] Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power
예) 3x3 합성곱을 수행하기 전에 입력 표현의 차원을 줄이더라도 큰 정보 손실이 발생하지 않고 인접 유닛 간의 강한 상관관계가 정보 압축에 도움이 되며, 차원 축소가 학습 속도를 높이는 데 기여하기 때문이다.
[4] Balance the width and depth of the network.
네트워크의 성능은 필터 수(폭)와 층의 깊이 간의 균형을 맞출 때 최적화가 되고, . 연산 예산이 한정된 경우, 폭과 깊이를 동시에 증가시키는 것이 최적의 개선을 가져온다.
Factorizing Convolutions with Large Filter Size
[1] (더 작은 합성곱으로 분해)Factorization into smaller convolutions
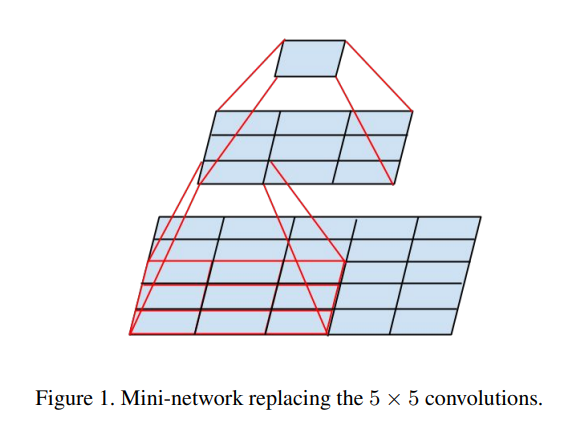
5x5 convoulution, 7x7 convoulition을 3x3 convolution으로 분해하면 연산량과 파라미터가 감소한다.
위 그림처럼 5x5 convolution은 3x3 convolution 두 개로 분해할 수 있다.
VGG논문에서도 5X5 Convolution 연산을 1번 수행하는 것보다 3x3 convolution 연산을 2번 수행하는 것의 계산량이 더 적다.
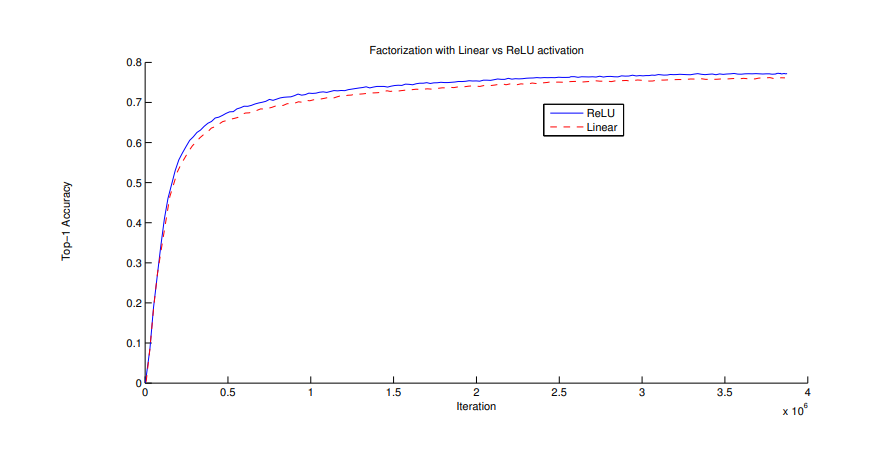
3x3 convolution을 2번 사용하여 5x5 convolution을 분해할 때, 첫 번째 3x3은 linear activation, 두 번째 3x3은 ReLU activation을 사용하는 것과 둘 다 ReLU activation을 사용하는 것을 실험했었고, 두 3x3 convolution에 ReLU를 사용한 것이 정확도가 더 높았습니다. 추가적으로 배치 정규화(Batch normalization)을 사용하면 더 정확도가 높아지게 된다.
3x3 convolution보다 큰 filter는 언제든지 3x3 convolution으로 분해하여 사용하는 것이 좋다.
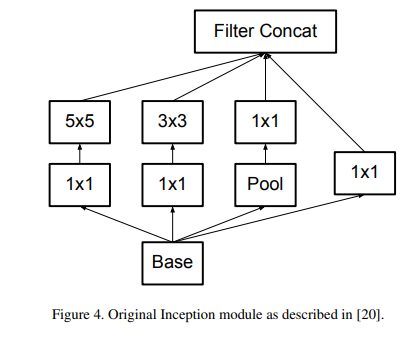
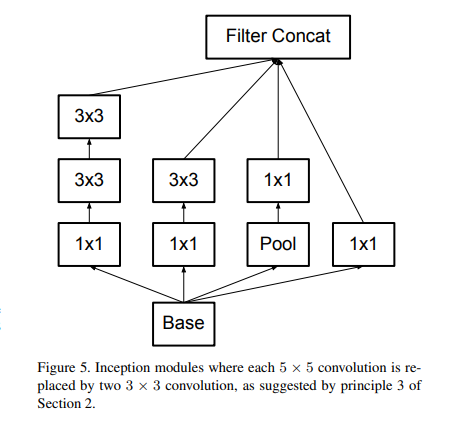
[2] 비대칭 합성곱(Asymmetric Convolutions)분해
본 논문에서 3x3 convolution을 더 작은 convolution으로 분해할 수 있을까라는 실험을 하였고, nx1 비대칭 convolution으로 분해하는 것이 효과가 좋다고 한다.
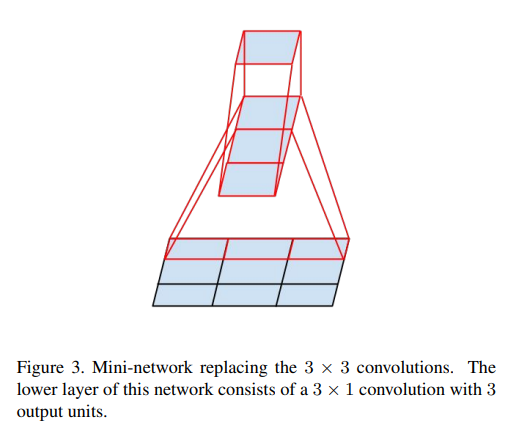
위 그림과 같이 3x3을 1x3, 3x1로 분해하면 33%의 연산량 절감 효과가 있다고 하며, 반면에 2x2 conv로 분해하면 11%의 연산량 감소 효과가 있다.
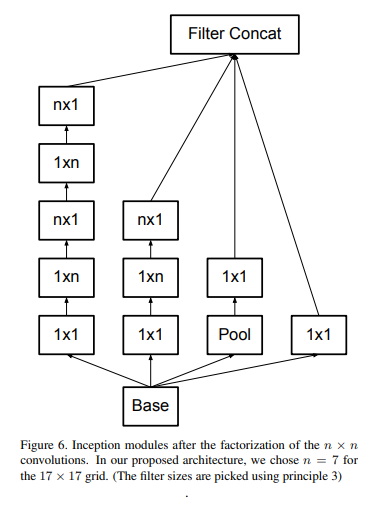
module은 feature map 사이즈가 12~20 사이일 때 효과가 좋았다고 한다.
[3]보조 분류기의 활용(Utility of Auxiliary Classifiers)
GoogLeNet논문에서 Auxiliary Classifiers를 활용하면 신경망이 수렴하는데 도움을 준다고 소개하지만, 실험 결과 별다른 효과가 없는 것으로 밝혀졌고 drop out이나 batch normalization을 적용했을 때, main classifiers의 성능이 향상된 것으로 보아, auxiliary classifiers는 성능 향상의 효과보다 정규화 효과가 있다고 추측한다고 한다.
[4]효율적인 그리드 크기 축소(Efficient Grid Size Reduction)
일반적인 CNN신경망은 feature map의 사이즈를 줄이기 위해 Pooling 연상을 사용하고 위에 언급하였듯이 represetational bottlenet을 피하기 위해 필터 수를 증가하는 것이 일반적이다.
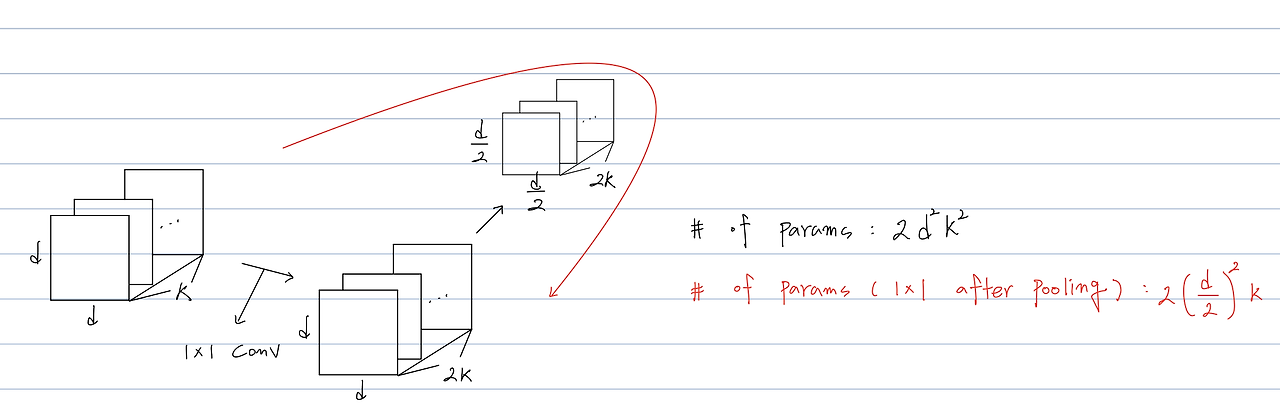
위 그림 처럼 dxd 크기를 가진 k개 feature map은 연산을 거치기 위해 필요한 파라미터 수는 이 된다.
이 계산량을 줄이기 위해 Pooling 이후에 1 x 1 Convolution을 거친다면 요구되는 파라미터의 수는 이 되지만 이러면 representational bottleneck을 방지하지 못한다.
표현력이 감소하는 이유는 pooling 연산을 거치면 정보가 손실되기 때문이다.
본 논문에서는 표현력을 감소시키지 않고, 연산량을 감소시킬 수 있다고 말한다.
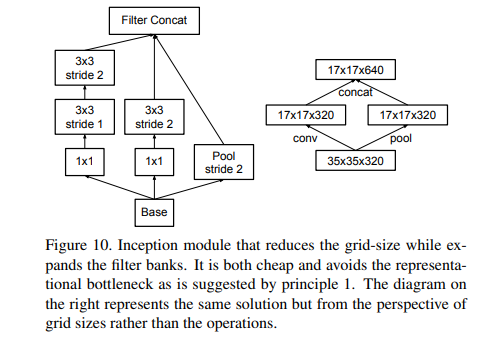
요약하자면 stride 2를 지닌 pooling layer와 conv layer를 병렬로 사용합니다. 그리고 둘을 연결하면 해결할 수 있다고 나와있다.
Inception-v2
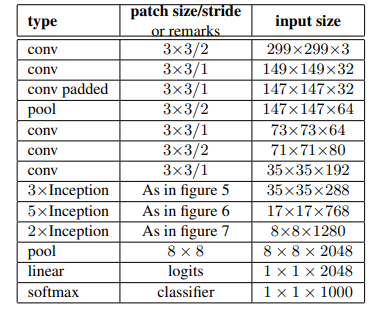
Inception v2는 42개의 레이어를 쌓았음에도 불구하고, GoogLeNet보다 2.5배정도의 computational cost를 가지고 VGGNet보다는 여전히 효율적이다.
Pytorch 코드구현: https://github.com/namduhus/InceptionV2
Pytorch: 2.5.0
IDE: VSCode
GPU: CUDA 12.1
