https://arxiv.org/pdf/2302.05543
Author: Lvmin Zhang, Anyi Rao, and Maneesh Agrawala
Introduction
-
기존의 text-to-image는 성능이 좋지만 text 하나로만은 복잡한 표현들을 control 할 수 없다.
-
text-to-image를 원하는 condition 조건에서 end-to-end로 학습시키는 것은, 기존의 데이터보다 학습 시키려는 데이터가 매우작아 어려운 일이다.
-
적은 데이터로 기존의 모델을 finetuning하면, 오비피팅이나 치명적인 망각이 일어날 수 있다.
ControlNet
-
ControlNet은 large diffusion model의 weights를 “trainable copy”와 “locked copy”로 복제하여 2개의 모듈이 생긴다.
-
“trainable copy”가 conditional control을 배우기 위해 task-specific 데이터셋에 대해 학습된 것에 반해 “locked copy”는 기존 network의 capability를 보존한다.
-
이 두가지 neural net block은 특별한 종류의 convolution layer인 “zero convolution”와 연결된다.
-
또한 zero convolution이 새로운 노이즈를 더하지 않기 때문에, 학습 역시 diffusion 모델의 fine-tuning만큼 빠르다.
Method

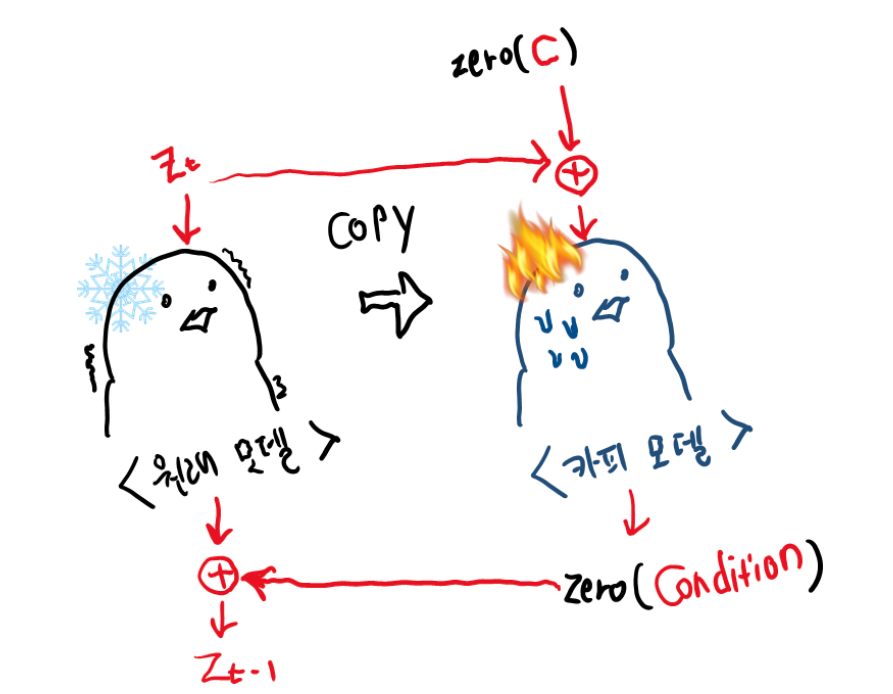
출처:https://junia3.github.io/blog/controlnet
-
가 들어가서 가 나오는 구조는 diffusion process에 접목시키게 되면 특정 시점의 noised latent vector 가 input으로 들어가서 다음 시점의 noised latent vector 를 예측하는 것과 같다.
-
회색으로 된 neural network는 원래의 diffusion model로 파라미터가 고정된 채 변하지 않게끔 하면 사전 학습된 디퓨전 모델의 이미지를 만드는 성능을 해치지 않고 가만히 놔둘 수 있다.
- 기존 weight를 직접적으로 학습시키지 않고 이러한 copies들을 만든 이유는 dataset이 작을 때의 overfitting을 피하고, 수억장의 이미지로 부터 학습된 large model의 퀄리티를 보존하기 위함이다.
Zero Convolution
-
각 neural block의 앞/뒤로 하나씩 붙는다
-
zero-convolution은 feature map의 크기를 변화시키면 안되기 때문에
1×1 크기를 가지는 convolution이며 weight와 bias 모두 zero로 초기화된 상태로 학습이 시작된다.
1x1 Convolution 효과
- 학습 파라미터 감소 (채널수 변경)
- 비선형성 추가
- 객체 정보와 위치 정보의 독립적 연산
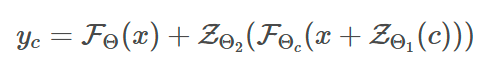
-
Zero-convolution은 weight 및 bias가 모두 0이므로, input에 상관없이 처음엔 모두 0을 output으로 내뱉는다.
-
이렇게 되면 해로운 Noise가 training이 시작될때 학습가능한 copy의 neural network의 hidden state에 영향을 줄 수 없다. 학습가능한 copy또한 x를 input으로 받아 원래 large의 capabilities를 모두 유지하고 있기 때문에, pretrained 모델은 추가 학습을 위한 강력한 백본 역할을 할 수 있다.
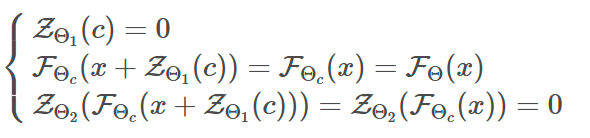
- ControlNet 구조에 의한 input/output 관계가 사전 학습된 diffusion의 input/output과 전혀 차이가 없다는 것이고, 이로 인해 optimization이 진행되기 전까지는 neural network 깊이가 증가함에 따라 영향을 끼치지 않는다는 것을 알 수 있다.
Stable Diffusion + ControlNet
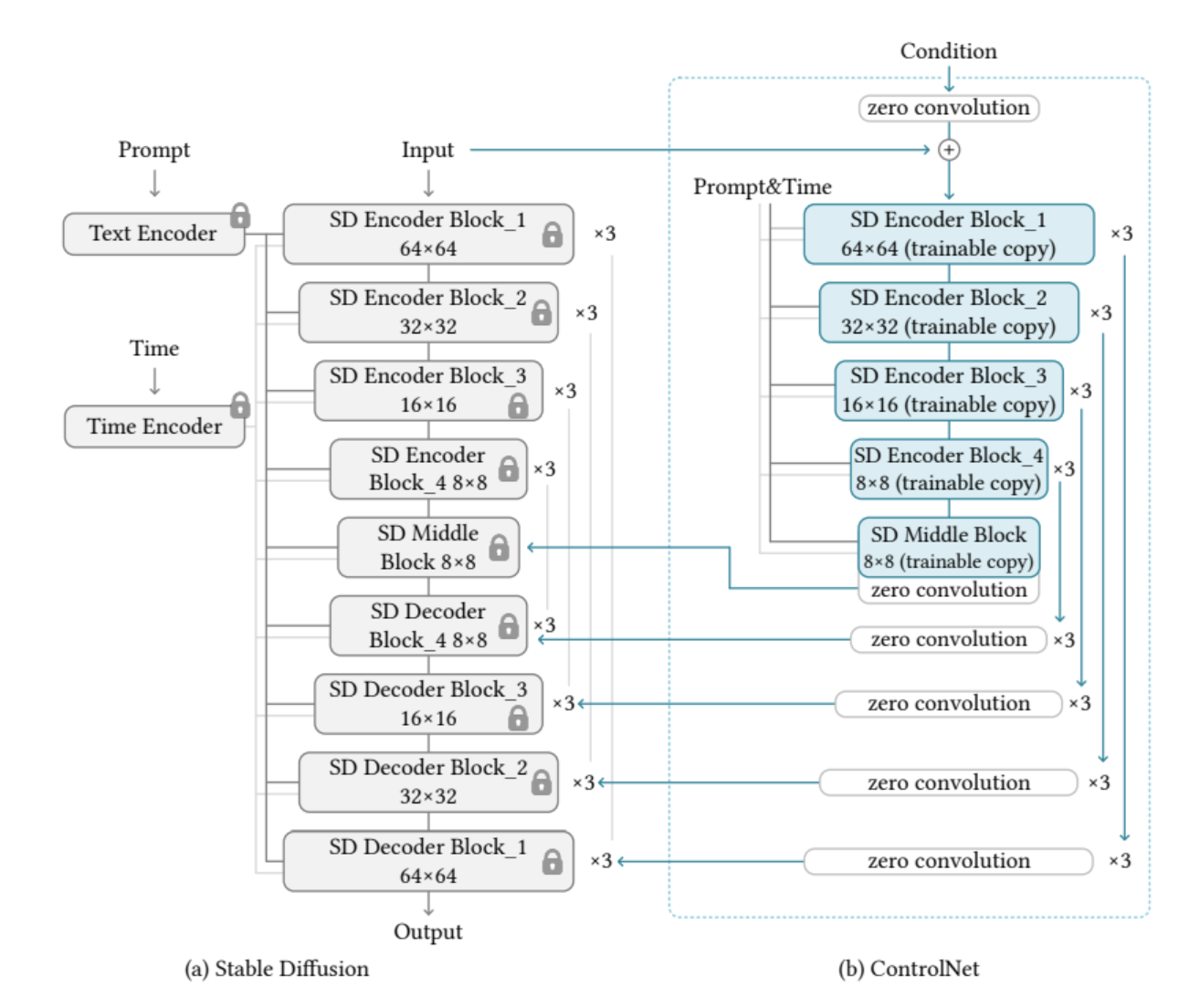
-
SD는 인코더 12, 디코더 12, middle block 1개로 총 25개 블럭으로 구성된다.
-
이때 8개 블럭은 U-Net구조를 이룬다.
-
나머지 17개 블럭은 4개의 resnet layer와 2개의 ViT를 포함하였고, 각 ViT에는 cross-attention, self-attention mechanism이 포함 된다.
-
text는 CLIP으로 embedding화 되고 timstep은 positional encoding을 사용한 time encoder로 encoded 된다.
-
스테이블 디퓨전의 U-Net 중 인코더 블록 12개와 미들 블록 1개에 대해 학습 가능한 복사본을 생성한다.
