https://arxiv.org/pdf/2006.11239
Author: Jonathan Ho, Ajay Jain, Pieter Abbeel
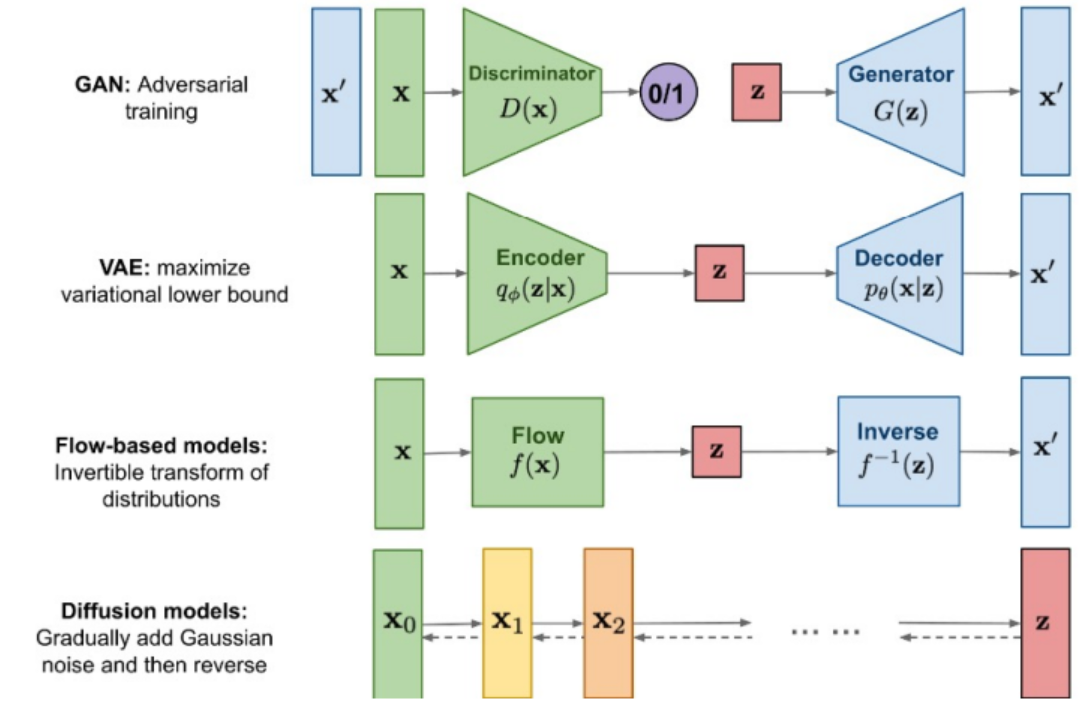
-
GAN(Generative Adversarial Network):Generator 와 Discriminator로 구분되어 가짜 데이터를 만드려는 Generator와 이를 구별하려는 Discriminator를 학습한다.
-
VAE(Variational AutoEncoder): VAE는 확률적인 잠재 변수를 사용하여 데이터를 생성하는 모델이다.
-
Flow-based: 확률적인 데이터분포를 변환하는 것이 주요하며, 입력받은 데이터를 다른 확률 분포로 매핑한다. 가역함수 를 사용하여 입력데이터를 잠재공간으로 압축 후 역함수 를 통해 다시 원본 데이터로 복원하는 과정을 통해 입력 데이터 분포를 학습하여 x를 잘 표현하는 z를 만드는것이 목표다.
-
Diffusion: 물질의 특정분포가 와해되는 것을 의미하며 데이터로 생각한다면 특정 데이터의 패턴이 반복적인 과정을 거치며 와해되는 과정을 의미한다.
Introduction
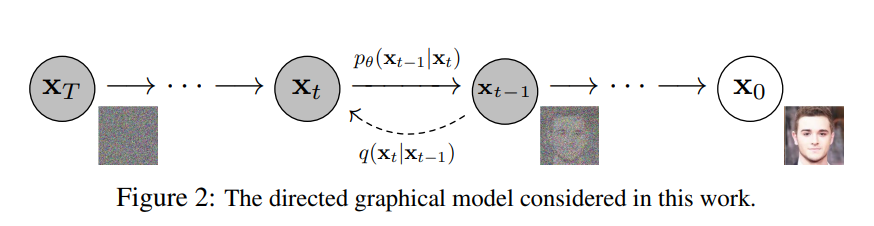
-
Diffusion에서 중요한 개념은 바로 Stochastic Process이다.
-
이것은 time-dependent variables을 통해서 이루어진다.
-
위 그림처럼 Gaussian 노이즈를 만들어 버리는 Forward process와 Gaussian 노이즈에서 확률적으로 이미지를 만들어 버리는 Reverse process가 DDPM의 원리이다.
-
여기서 Reverse process를 학습하는것이 Diffusion Model이다.
Forward process
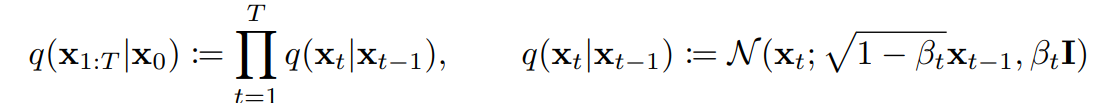
- Forward process는 Diffusion process라고 불린다.
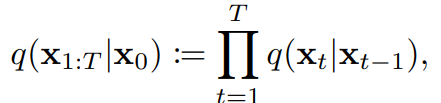
- 이 수식은 likelihood와 같은 식이며, 이는 gaussian distribution에서 값을 뽑아낸다는 것을 알 수 있다.
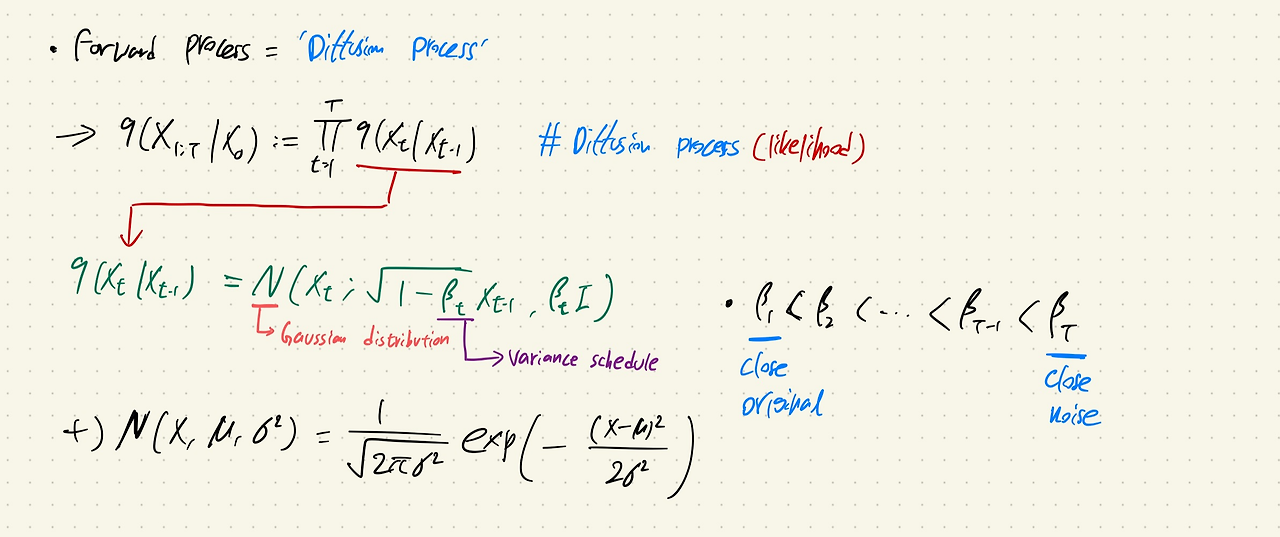 출처:https://kyujinpy.tistory.com/95
출처:https://kyujinpy.tistory.com/95
-
위의 수식에서 는 diffusion rate(variance schedule)로 분산이 발산하는것을 방지해준다. 즉 Scaling 역할을 하는 것이다.
-
의 은 은 Original image에 가까운 수준이고, 는 Nosiy image에 가까운 수준을 의미한다.
-
(Original image)에서 (Noisy image)로 전개할 때, 0~T의 모든 수식을 step by step으로 전개해야되기 때문에 많은 memory를 소모하고 시간도 오래걸리는 단점이 있다.
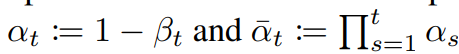
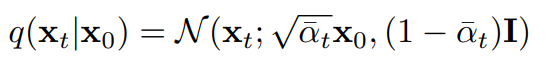
-
위의 단점을 해결하기 위해서 를 이용한다.

출처:https://kyujinpy.tistory.com/95 -
는 gaussian distribution에서 나오는 값이기 때문에 평균을 기준으로 어느정도 분산으로 치우친 값을 가지고 있다.
-
따라서 = 로 표현이 가능하다.
-
로 표현을 하게 된다면, ~ 로 한번에 전개가 가능해진다.
-
Gaussian distribution을 활용해서 noise를 더해가면서 를 이용하여 ~ 를 만드는 과정을 한번에 Sampling 할 수 있다는 것이다.
Backward process
-
Backward process는 VAE와 동일하게 model의 likelihood(가능도)를 최대화 하는 것에 초점을 두었다.
-
VAE와 동일하게 ELBO를 찾고 이를 최대화 하는 방향으로 훈련을 진행한다.

-
Diffusion에서는 위 수식의 Loss Function으로 활용하여 훈련을 진행하고, 이를 효율적으로 바꾸기 위해서 밑의 수식처럼 표현한다.
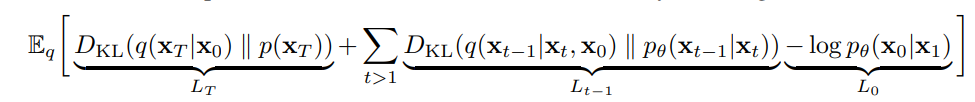
-
: KL-divergence를 통해서 으로 를 생성하는 q분포와 p()의 분포가 유사해지도록 한다.
-
: Backward process와 diffusion process간의 분포가 유사해지도록 한다.
-
: reconstruction loss로 에서 나올 likelihood를 최대화 한다.
DDPM
-
Forward process 와 backward process가 있다.
-
DDPM에서는 Backward process에 훈련을 가능하게 하고 Forward process에는 를 일정하게 유지하여서 훈련할 필요가 없게 만들었다.
-
이를 통해 를 무시할 수 있게 한다.
Backward Process
-
DDPM은 2가지 방법을 제시한다.
-
첫번째는 분산과 관련된 조건이다.
-
Backward process에서 sampling을 할 때, gaussian distribution의 분산을 2가지 조건으로 설정하는 것이다.
-
첫번째 방식은이 으로 최적화되고, 두번째 방식은 one point로 최적화된다고 언급한다.
Simplified training objective
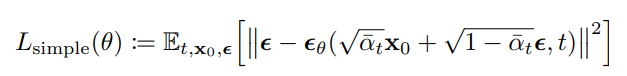
-
새롭게 정의된 DDPM Loss이다.
-
기존의 Diffusion보다 loss function이 매우 간단해 졌으며, 만 신경써주면 되기 때문이다.
-
이러한 이유는 가 고정되었고 를 신경쓸 필요가 없기 때문이다.
-
이를 통해 모델이 더 어려운 noise 제거 작업을 더 잘 학습하게 되어, 전체적인 성능 향상을 이끌어 낸다.
Result


