
란? 타원형의 모양을 클루스터링 할 수 있고, soft clustering (한 데이터가 여러 개의 클러스터에 포함 가능) 이다.
예를 들어, 한 포인트가 클러스터 A에 0.8, 클러스터 B에 0.2의 확률로 속할 수 있습니다.
: EM 알고리즘에서는 likelihood를 최대화하는 방향으로 파라미터를 업데이트하여 모델을 개선합니다.
(과정)
- 초기의 cluster k 지정
2. E step ( Expectation step)
-
각 데이터 포인트가 특정 클러스터에 속할 확률(soft clustering) 계산 후
-
이 확률을 사용하여 현재 파라미터의 likelihood (모델이 얼마나 잘 설명하는지 수치적, 확률로 나타냄) 을 계산합니다.
(log-likelihood 계산시 위에서 계산 한 확률 사용된다는 의미, 확률을 찾는 것도 likelihood의 일부임 그걸 사용해서 계산하니까! )
3. M step (Maximization step)
: 계산된 가능도(likelihood)를 최대화하는 새로운 파라미터 (새로운 확률분포) 를 얻는다.
- 이때, Recalculated cluster center. (클루스터 센터를 e step 에서 계산한 확률을 사용해 재계산 한다 )
4. E, M step을 반복한다.
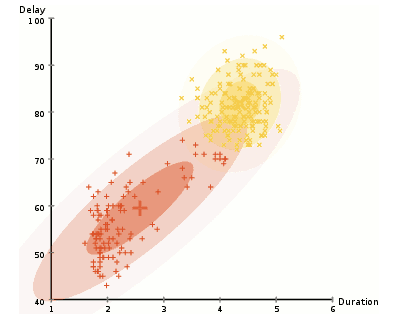
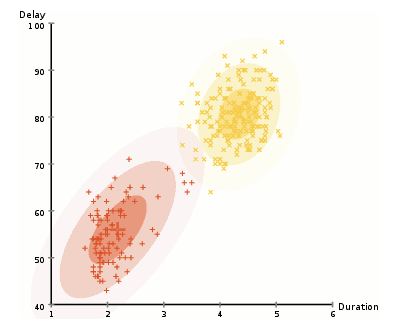
-> 
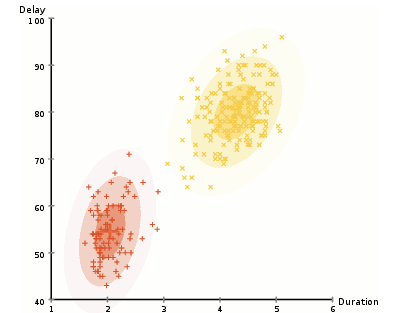

Let's study hard!