1.이론 - Numpy란?
Numerical Python으로 python에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리.

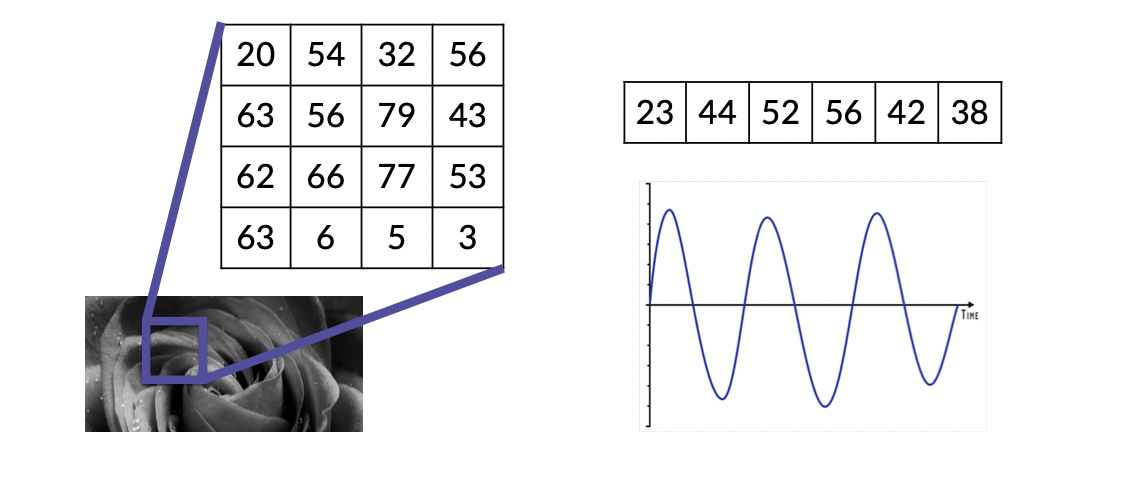
넘파이를 이용한다면 데이터의 대부분을 숫자 배열로 표현 가능하다.
왼쪽의 흑백이미지는 해당 픽셀에 대한 밝기(명암)을 나타내는 2차원 배열 데이터로 표현 가능하고, 오른쪽의 sound data는 시간 대비 음압을 1차원 숫자 배열 데이터로 표현 가능하다.
따라서 넘파이를 이용한다면 실생활의 많은 데이터를 배열로 나타낼 수 있으므로 배열을 효과적으로 바라보고, 가공하는 절차가 중요하다.
물론, 파이썬 리스트를 통해 배열을 나타낼 수 있기는 하지만, 파이썬 리스트에 비해 빠른 연산이 가능하고 효율적으로 메모리를 사용가능하다는 장점이 있다.
1-1. 행렬 만들기
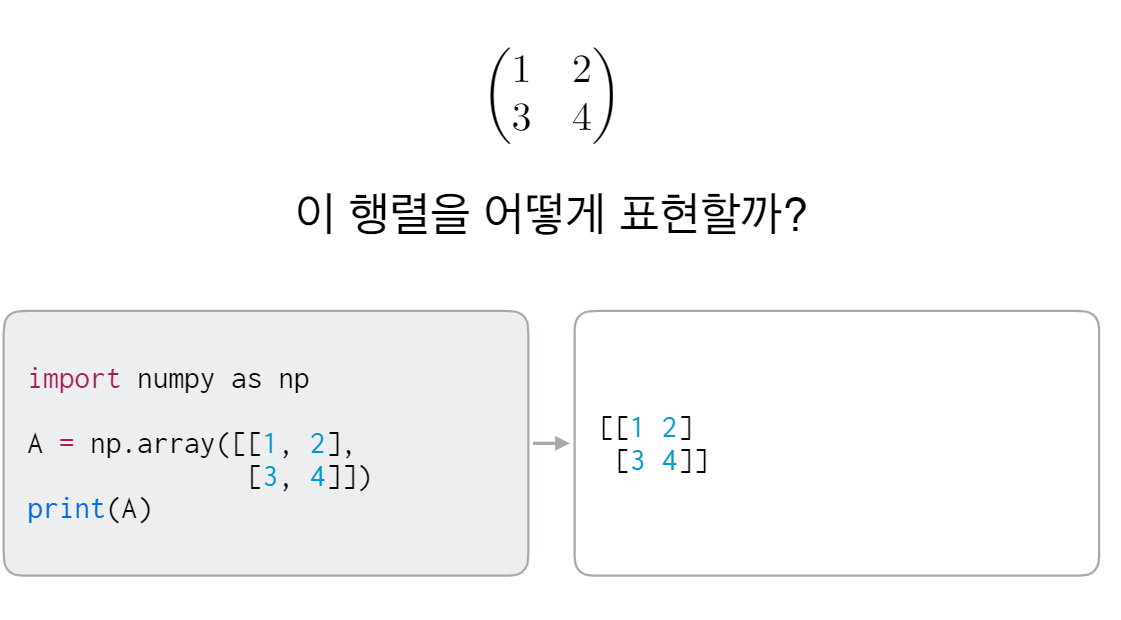
1-2. Numpy array
이렇게 만들어진 행렬은 곱셈, 덧셈, 뺄셈이 가능하다.
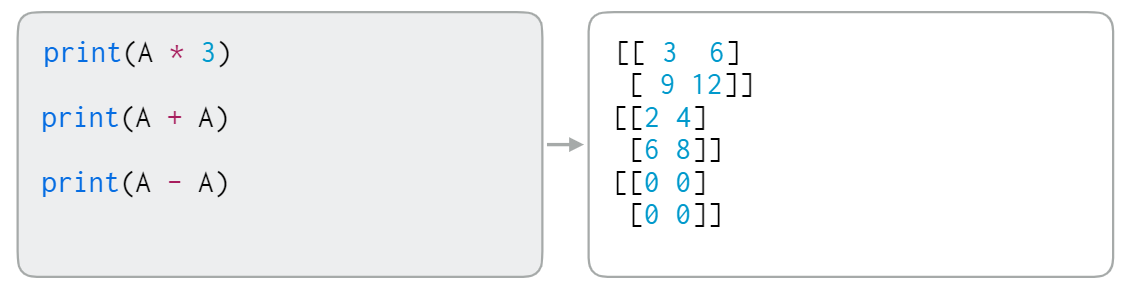
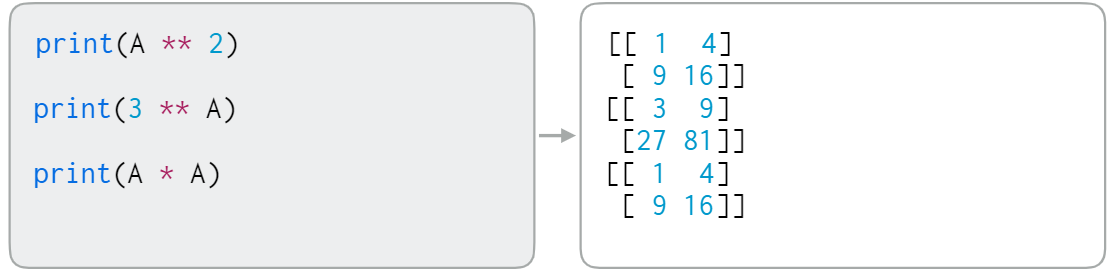
1-3. Numpy Array - 산술연산
행렬 내 원소에 대한 산술연산도 가능함. ("element-wise operation")
1-4. 행렬 곱셈
np.dot(x,y)는 x*y와 다르다.
x = np.array([[1,2],[3,4]])
y = np.array([[3,4],[3,2]])
print(np.dot(x,y)) # [[ 9 8 ]
# [ 21 20]]
print(x * y) # [[3 8]
# [9 8]]1-5. Numpy Array - 비교연산
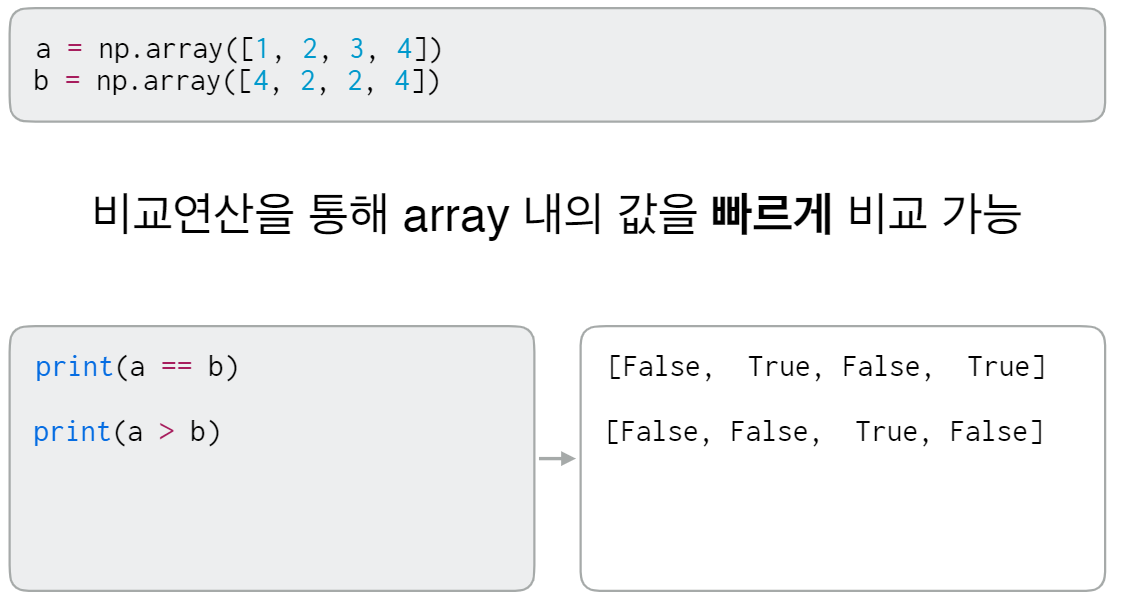
1-6. Numpy Array - 논리연산

1-7. Numpy Array - Reductions

1-8. Logical Reductions
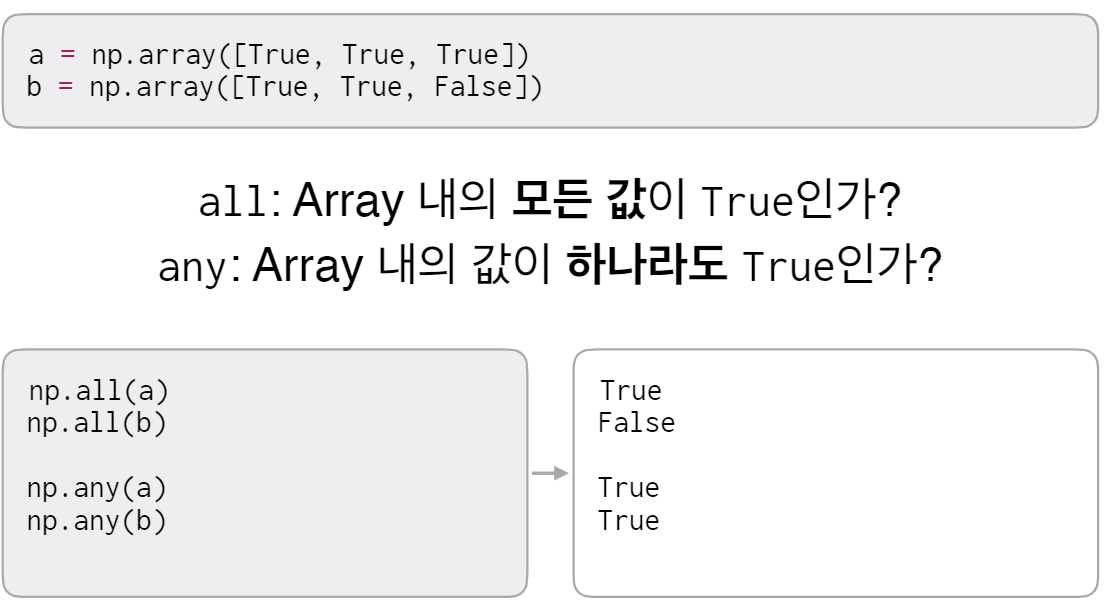
1-9. Statistical Reductions

2. 코드 실습
2-1. Numpy vs Python
#numpy 이용
import numpy as np
np.array([1,2,3,4,5])
#파이썬 이용
list(range(10))
np.array([1, 2, 3, 4, 5])
#실수형태의 array (원소 1개라도 실수이면 모두 실수로 나타남)
np.array([3, 1.4, 2, 3, 4])
#2차원 array
np.array([[1, 2],
[3, 4]])
#데이터 타입을 지정 가능
np.array([1, 2, 3, 4], dtype='float')2-2. 배열 데이터 타입 dtype
#python list와는 다르게 array는 단일 타입으로 구성됨.
arr = np.array([1,2,3,4], dtype=float)
arr
arr.dtype
arr.astype(int)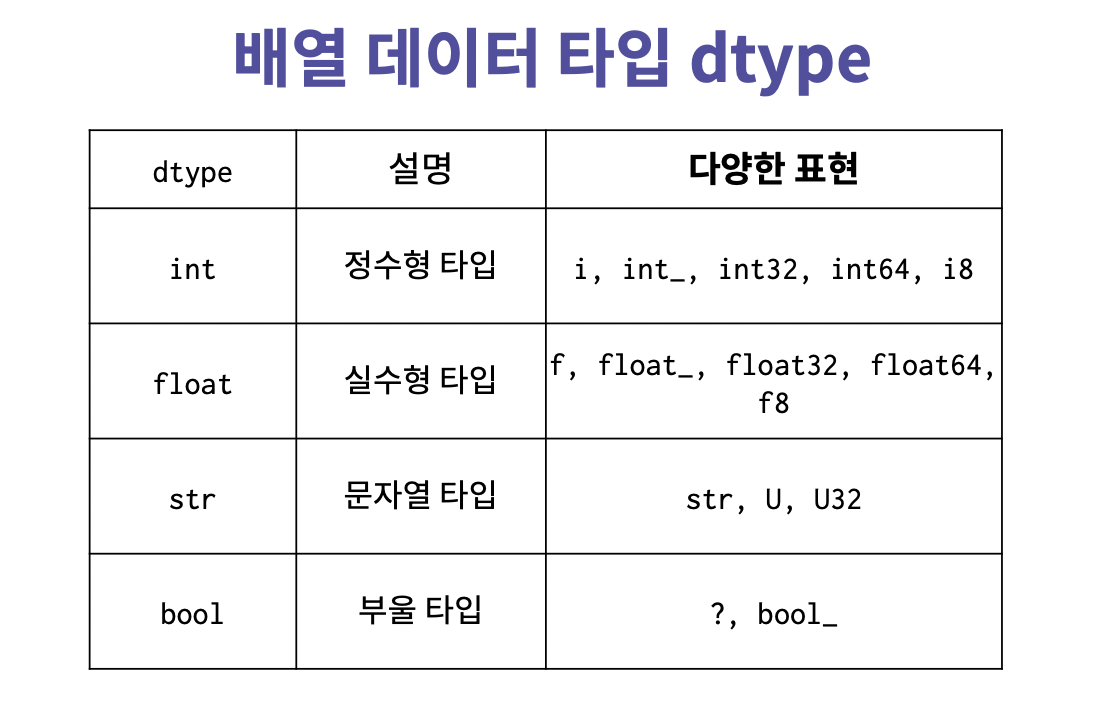
np.zeros(10, dtype=int)2-3. 3*5 모양으로 만들어라
np.ones((3, 5), dtype=float)
#start, end, step
np.arange(0, 20, 2)
np.linspace(0, 1, 5)2-4. 난수로 채워진 배열 만들기
#인자로 튜플을 받는다. 튜플 = shape
np.random.random((2, 2))
#np.random.normal(평균, 표준편차, shape) : 정규분포
np.random.normal(0, 1, (2, 2))
#np.random.randint(start, end, shape): start부터 end까지 2*2 형태로 출력
np.random.randint(0, 10, (2, 2))2-5. 배열의 기초
x2 = np.random.randint(10, size=(3,4))
x2.ndim
x2.shape
x2.size
x2.dtype2-6. 찾고 잘라내기 : indexing
x=np.arange(7)
x[3]
x[7]
x[0] = 10
x2-7. 찾고 잘라내기 : slicing
x[1:4]
x[1:]
x[:4]
x[::2]
2-8. 모양 바꾸기
x = np.arange(8)
x.shape
x2 = x.reshape((2,4))
x2
x2.shape2-9. 이어붙이고 나누고 ; concatenate : array를 이어 붙인다.
x = np.array([0,1,2])
y = np.array([3,4,5])
np.concatenate([x,y])
matrix = np.arange(4).reshape(2,2)
np.concatenate([matrix, matrix],axis=0)
matrix = np.arange(4).reshape(2,2)
np.concatenate([matrix, matrix],axis=1)
2-10. np.spli : axis축을 기준으로 나눌 수 있다.
matrix = np.arange(16).reshape(4,4)
upper,lower = np.split(matrix, [3], axis=0)
matrix
upper
lower
matrix = np.arange(16).reshape(4,4)
left,right = np.split(matrix, [3], axis=1)
matrix
left
right2-11. 루프는 느리다
#array의 모든 원소에 5를 더해서 만드는 함수
def add_five_to_array(values):
output = np.empty(len(values)) #받은 길이만큼의 빈 array
for i in range(len(values)):
output[i] = values[i] + 5
return output
values = np.random.randint(1,10, size=5)
values
add_five_to_array(values)만약 array의 크기가 크다면?

2-12. 기본연산
array는 사칙연산에 대한 기본 연산을 지원한다.
x = np.arange(4)
x
x+5
x-5
x*5
x/5다차원 행렬에도 적용가능하다.
x = np.arange(4).reshape((2,2))
y = np.random.randint(10, size=(2,2))
x
y
x+y
x-y2-13. 브로드캐스팅
Broadcasting : shape이 다른 array끼리의 연산
np.arange(3).reshape((3,1))
np.arange(3)
np.arange(3).reshape((3,1)) + np.arange(3)2-14. 집계함수
집계 : 데이터에 대한 요약 통계를 볼 수 있다.
x = np.arange(8).reshape((2,4))
x
np.sum(x)
np.min(x)
np.max(x)
np.mean(x)
np.std(x)
np.sum(x, axis=0)
np.sum(x, axis=1)2-15. 마스킹 연산
마스킹 연산 : True, Flase array를 통해서 특정 값을 뽑아내는 방법
x = np.arange(5)
x<3
x>5
x[x<3] #True인 값들은 추출됨3. 실습
3-1. NumPy 행렬 만들기
1) 배열 3x4의 크기를 가진 다음의 행렬 A를 선언.
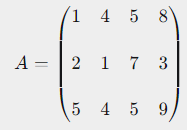
import numpy as np
def main():
print(matrix_tutorial())
def matrix_tutorial():
# Create the matrix A here...
A = np.array([[[1,4,5,8],
[2,1,7,3],
[5,4,5,9]]])
return A
if __name__ == "__main__":
main()
3-2. NumPy 산술연산자
- A 원소의 합이 1이 되도록 표준화(Normalization)를 적용하고 결괏값을 A에 지정.
- matrix_tutorial() 함수가 A의 분산(Variance)값을 리턴하도록 코드를 작성
import numpy as np
def main():
print(matrix_tutorial())
def matrix_tutorial():
A = np.array([[1,4,5,8], [2,1,7,3], [5,4,5,9]])
# normalize : 원소의 합이 1이 되도록 적용하는 것
A = A/np.sum(A)
#variance : np.var()
return np.var(A)
if __name__ == "__main__":
main()3-3. NumPy 논리연산자
- A의 전치 행렬 B 생성
- B의 역행렬 구하여 C에 저장. 역행렬 구하는 것이 불가능 할 시 "not invertible" 리턴
- matrix_tutorial() 함수의 리턴값으로 0보다 큰 C의 원소를 모두 세어 개수를 리턴
import numpy as np
def main():
A = get_matrix()
print(matrix_tutorial(A))
def get_matrix():
mat = []
[n, m] = [int(x) for x in input().strip().split(" ")] #n :행, m : 열
for i in range(n):
row = [int(x) for x in input().strip().split(" ")]
mat.append(row)
return np.array(mat)
def matrix_tutorial(A):
B = np.transpose(A) # or A.T
try :
C = np.linalg.inv(B)
except:
return "not invertible"
return np.sum(C>0)
#C>0 을 함으로써 행렬의 모든 원소의 bull 가능. np에서는 True =1, False 0으로 인식하므로
if __name__ == "__main__":
main()
3-4. 벡터 연산으로 그림 그리기
import matplotlib as mpl
mpl.use("Agg")
import matplotlib.pyplot as plt
import elice_utils
import numpy as np
elice = elice_utils.EliceUtils()
def circle(P):
return np.linalg.norm(P) - 1 # 밑의 코드와 동일하게 동작합니다.
# return np.sqrt(np.sum(P * P)) - 1
def diamond(P):
return np.abs(P[0]) + np.abs(P[1]) - 1
def smile(P):
def left_eye(P):
eye_pos = P - np.array([-0.5, 0.5])
return np.sqrt(np.sum(eye_pos * eye_pos)) - 0.1
def right_eye(P):
eye_pos = P - np.array([0.5, 0.5])
return np.sqrt(np.sum(eye_pos * eye_pos)) - 0.1
def mouth(P):
if P[1] < 0:
return np.sqrt(np.sum(P * P)) - 0.7
else:
return 1
return circle(P) * left_eye(P) * right_eye(P) * mouth(P)
def checker(P, shape, tolerance):
return abs(shape(P)) < tolerance
def sample(num_points, xrange, yrange, shape, tolerance):
accepted_points = []
rejected_points = []
for i in range(num_points):
x = np.random.random() * (xrange[1] - xrange[0]) + xrange[0]
y = np.random.random() * (yrange[1] - yrange[0]) + yrange[0]
P = np.array([x, y])
if (checker(P, shape, tolerance)):
accepted_points.append(P)
else:
rejected_points.append(P)
return np.array(accepted_points), np.array(rejected_points)
xrange = [-1.5, 1.5] # X축 범위입니다.
yrange = [-1.5, 1.5] # Y축 범위입니다.
accepted_points, rejected_points = sample(
100000, # 점의 개수를 줄이거나 늘려서 실행해 보세요. 너무 많이 늘리면 시간이 오래 걸리는 것에 주의합니다.
xrange,
yrange,
smile, # smile을 circle 이나 diamond 로 바꿔서 실행해 보세요.
0.005) # Threshold를 0.01이나 0.0001 같은 다른 값으로 변경해 보세요.
plt.figure(figsize=(xrange[1] - xrange[0], yrange[1] - yrange[0]),
dpi=150) # 그림이 제대로 로드되지 않는다면 DPI를 줄여보세요.
plt.scatter(rejected_points[:, 0], rejected_points[:, 1], c='lightgray', s=0.1)
plt.scatter(accepted_points[:, 0], accepted_points[:, 1], c='black', s=1)
plt.savefig("graph.png")
elice.send_image("graph.png")
AI researcher를 꿈꾸는 간호사입니다 :)