1. 조건으로 검색하기
1-1. numpy array 처럼 masking 연산이 가능함.
print("Masking & query")
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
df[“A”] < 0.5 #True/False로 결과 값 나오게 됨.
1-2. 조건에 맞는 DataFrame row를 추출 가능 - 내가 잘 사용 안하는데 활용하도록 노력해야할 부분
df[(df["A"] < 0.5) & (df["B"] > 0.3)]
df.query("A < 0.5 and B > 0.3")
#이건 바로 데이터 프레임 형식으로 추출됨.1-3. 예제
#@@ 조건으로 검색하기
print("Masking & query")
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
print(df, "\n")
#데이터 프레임에서 A컬럼값이 0.5보다 작고 B컬럼 값이 0.3보다 큰값들을 구해봅시다.
print(df[(df['A']<0.5) & (df['B']>0.3)])
print(df.query("A <0.5 and B>0.3"))2. 함수로 데이터 처리하기
df = pd.DataFrame(np.arange(5), columns=["Num"])
def square(x):
return x**2
df["Num"].apply(square)
df["Square"] = df.Num.apply(lambda x: x ** 2)
df = pd.DataFrame(columns=["phone"])
df.loc[0] = "010-1234-1235"
df.loc[1] = "공일공-일이삼사-1235"
df.loc[2] = "010.1234.일이삼오"
df.loc[3] = "공1공-1234.1이3오"
df["preprocess_phone"] = ''
def get_preprocess_phone(phone):
mapping_dict = {
"공": "0",
"일": "1",
"이": "2",
"삼": "3",
"사": "4",
"오": "5",
"-": "",
".": "",
}
for key, value in mapping_dict.items():
phone = phone.replace(key, value)
return phone
df["preprocess_phone"] = df["phone"].apply(get_preprocess_phone)
# replace : apply 기능에서 데이터 값만 대체하고 싶을 때 사용
df.Sex.replace({"Male": 0, "Female": 1})
df.Sex.replace({"Male": 0, "Female": 1}, inplace=True)2-1. 예제
#@@ 함수로 데이터 처리하기
df = pd.DataFrame(np.arange(5), columns=["Num"])
print(df, "\n")
# 값을 받으면 제곱을 해서 돌려주는 함수
def square(x):
return x**2
# apply로 컬럼에 함수 적용
df["Square"] = df["Num"].apply(square)
# 람다 표현식으로도 적용하기
df["Square"] = df["Num"].apply(lambda x: x ** 2)
print(df)3. 그룹으로 묶기
3-1. 간단한 집계를 넘어서서 조건부로 집계 하고 싶은 경우
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [1, 2, 3, 1, 2, 3], 'data2':np.random.randint(0, 6, 6)})
df.groupby('key’)
# <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x10e3588>
df.groupby('key').sum()
df.groupby(['key','data1']).sum()3-2. aggregate: groupby 를 통해 집계를 한번에 계산하는 방법
df.groupby('key').aggregate(['min', np.median, max])
df.groupby('key').aggregate({'data1': 'min', 'data2': np.sum}3-3. filter: groupby를 통해 그룹 속성으로 데이터 필더링
def filter_by_mean(x):
return x['data2'].mean() > 3
df.groupby('key').mean()
df.groupby('key').filter(filter_by_mean)3-4. apply : groubpy를 통해서 묶인 데이터에 함수 적용
df.groupby('key').apply(lambda x: x.max() - x.min()3-5. get_group : groupby로 묶인 데이터에서 key값으로 데이터를 가져올 수 있다.
df = pd.read_csv("./univ.csv")
df.head()
df.groupby("시도").get_group("충남")
len(df.groupby("시도").get_group("충남"))
#943-7. 실습 예제
#@@ 그룹으로 묶기
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [1, 2, 3, 1, 2, 3],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")
# groupby 함수를 이용해봅시다.
# key를 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby(['key']).sum())
# key와 data1을 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby(['key','data1']).sum())
# aggregate를 이용하여 요약 통계량을 산출해봅시다.
# 데이터 프레임을 'key' 칼럼으로 묶고, data1과 data2 각각의 최솟값, 중앙값, 최댓값을 출력하세요.
print(df.groupby(['key']).aggregate([min,np.median, max]))
# 데이터 프레임을 'key' 칼럼으로 묶고, data1의 최솟값, data2의 합계를 출력하세요.
print(df.groupby(['key']).agg({'data1':min,'data2':sum}))
print("filtering : ")
def over_mean(x):
return x.data2.mean()>3
print(df.groupby(['key']).filter(over_mean))
# groupby()로 묶은 데이터에 apply도 적용해봅시다.
# 람다식을 이용해 최댓값에서 최솟값을 뺀 값을 적용해봅시다.
print("applying : ")
print(df.groupby(['key']).apply(lambda x: x.max() - x.min()))
#@@ multiindex & pivot table
df1 = pd.DataFrame(
np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2']
)
print("DataFrame1")
print(df1, "\n")
df2 = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
print("DataFrame2")
print(df2, "\n")4. MultiIndex & pivot_table
4-1. 인덱스를 계층적으로 만들기
df = pd.DataFrame(
np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2']
)4-2. 열 인덱스를 계층적으로 만들기
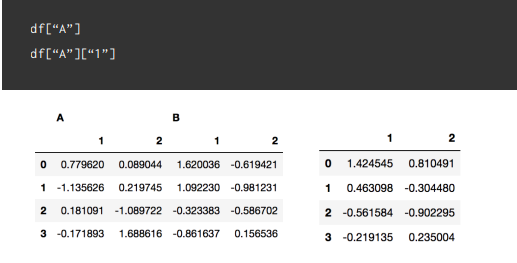
df = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
4-3. 다중 인덱스 컬럼의 경우 인덱싱은 계층적으로 한다
인덱스 탐색의 경우에는 loc, iloc를 사용가능하다
4-4. Pivot_table
데이터에서 필요한 자료만 뽑아서 새롭게 요약, 분석할 수 있는 기능 엑셀에서의 피봇테이블과 같다.
Index : 행 인덱스로 들어갈 key
Column : 열 인덱스로 라벨링 될 값
* Value : 분석할 데이터
# 타이타닉 데이터에서 성별과 좌석 별 생존률 구하기
df.pivot_table(index='sex', columns='class', values='survived’,aggfunc=np.mean)
df.pivot_table(index="월별", columns='내역', values=["수입", '지출'])
4-5. 실습 예제
#@@ multiindex & pivot table
df1 = pd.DataFrame(
np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2']
)
print("DataFrame1")
print(df1, "\n")
df2 = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
print("DataFrame2")
print(df2, "\n")
# 명시적 인덱싱을 활용한 df1의 인덱스 출력
print("df1.loc['A', 1]")
print(df1.loc['A', 1], "\n")
# df2의 [A][1] 칼럼 출력
print('df2["A"]["1"]')
print(df2["A"]["1"], "\n")
#@@ 피리부는 사나이를 따라가는 아이들 예제
df = pd.read_csv("./data/the_pied_piper_of_hamelin.csv")
child = df[df['구분']=="Child"]
print(child.groupby(['일차'])['나이'].mean())
print(child.pivot_table(index = '일차', columns='성별',values='나이', aggfunc=np.mean))
AI researcher를 꿈꾸는 간호사입니다 :)