컬렉션이란?
프로그래밍을 하다보면, 여러 데이터를 담아놓기 위해 자료구조를 많이 사용하게 된다. 자료구조를 편의성있게, 공통적으로 추상화된 기능을 제공하기 위해 Collection 인터페이스를 자주 사용하게 된다.
- Collection?
Java 인터페이스 중 하나로, Iterable 인터페이스를 상속받은 인터페이스를 말한다. 여기서 Iterable 인터페이스는 Iterator를 지원하기 위한 인터페이스로 요소를 순회하며 탐색하기 위하여 사용된다.
Iterator는 hasNext, next, remove, foreach 등의 편의 기능을 제공한다.
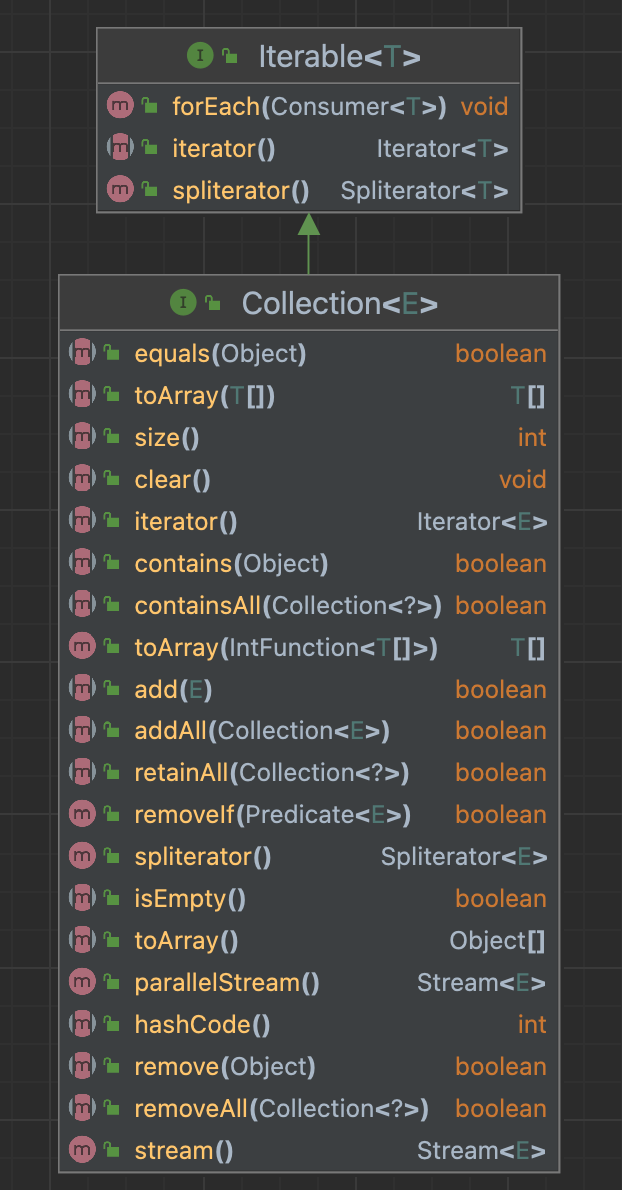 위와 같이, Collection 인터페이스는 수 많은 기능을 편의적으로 제공하기 위한 인터페이스임을 알 수 있다.
위와 같이, Collection 인터페이스는 수 많은 기능을 편의적으로 제공하기 위한 인터페이스임을 알 수 있다.
Oracle Docs를 보면 이를 상속받은, 구현한 수많은 인터페이스와 클래스를 볼 수 있다.
 이번 글에서는 자주 사용하는 List 그 중에서도 ArrayList, LikedList, Vector, Stack에 대하여 알아보려고 한다.
이번 글에서는 자주 사용하는 List 그 중에서도 ArrayList, LikedList, Vector, Stack에 대하여 알아보려고 한다.
List
-
1. ArrayList
ArrrayList는 다음과 같이 List, RandomAccess, Clonable, Serializable을 구현하고 있다.
인터페이스
용도 Serialziabe 객체를 저장하거나 파일에 저장할 수 있음을 의미 Clonable Object로 부터 상속 받은 clone() 메소드를 사용할 수 있음을 의미 Iterable 객체를 순회할 수 있으며, foreach의 문장을 사용할 수 있음을 의미 RandomAccess 임의로 데이터에 접근하는 알고리즘이 적용된다는 것을 의미
ArrayList는 내부의 Object 배열을 통해, 삽입, 삭제 조회등의 연산이 일어난다. 기본적으로 ArrayList 내부의 배열 사이즈는 10이며, 생성자를 통해 초기에 배열을 설정해야함을 유의해야 한다.
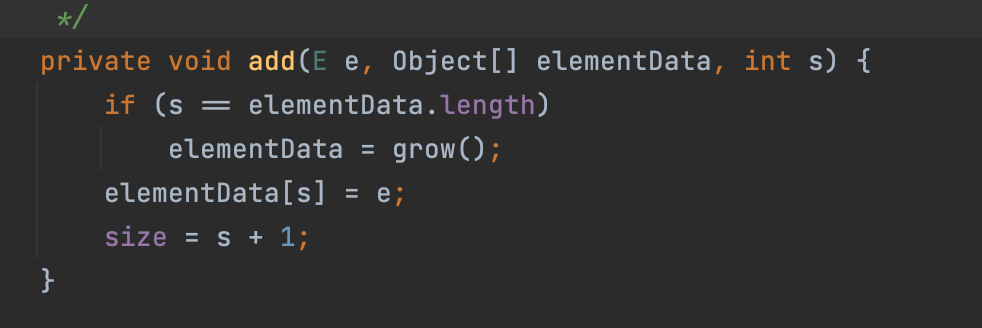
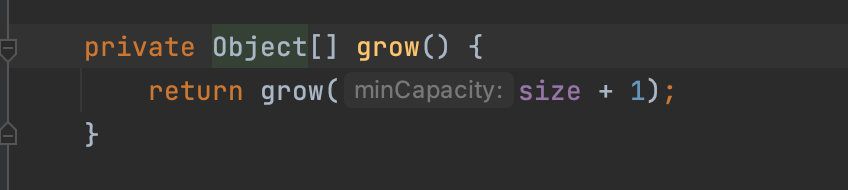
배열은 연속된 메모리에 저장된 자료구조이다. 배열의 사이즈는 가변적으로 변경이 불가능하다. 만약,위와 같이 add함수를 통해 데이터를 삽입 시 데이터가 저장된 배열의 크기를 초과한다면, 더 큰 크기의 새로운 배열을 생성하고, 기존의 데이터를 옮기는 연산을 수행하게 된다. 따라서, 초기에 ArrayList의 크기를 작게 잡아놓고, 잦은 삽입, 삭제를 한다면, 배열을 재할당, 값을 옮기는데 많은 자원을 낭비하게 될것이다.
-
2. LinkedList
LinkedList는 ArrayList와 달리 노드 단위로 저장이된다. LinkedList는 맨 앞을 가르키는 노드와 맨 뒤를 가르키는 노드를 갖고 있으며, 노드는 다음과 같이 데이터를 저장하는 item과 다음 요소를 참조하는 next, 이전 요소를 참조하는 prev 변수를 갖고 있는 것을 볼 수 있다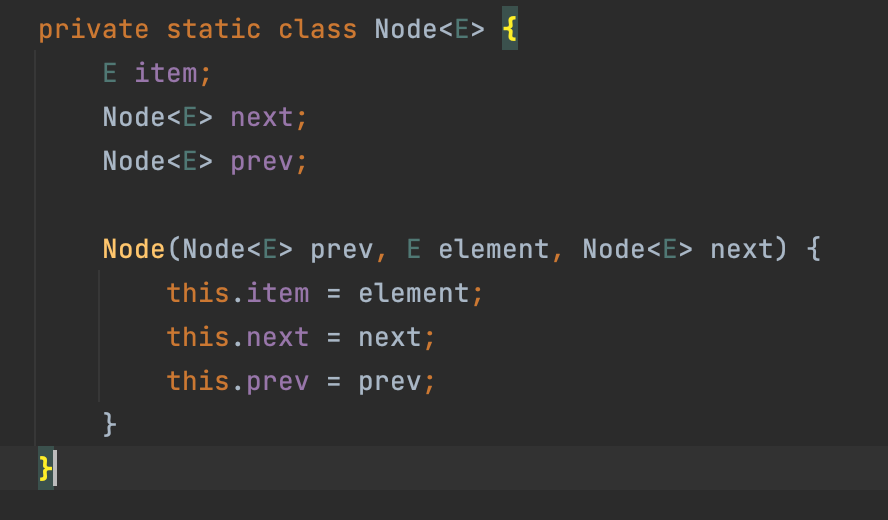 따라서, 데이터를 저장할 때, 실제 데이터 뿐 만아니라 앞뒤의 참조를 위한 추가적인 저장공간이 필요함을 알 수 있다.
따라서, 데이터를 저장할 때, 실제 데이터 뿐 만아니라 앞뒤의 참조를 위한 추가적인 저장공간이 필요함을 알 수 있다. -
3. Vector
Vector는 ArrayList와 비슷한 자료구조이며, ArrayList와 같이 내부적으로 배열을 사용해 데이터를 저장하며, 별도의 지정없이 10의 크기를 같은 배열을 갖고 있다. 제공하는 기능도 ArrayList와 매우 유사하다. -
4. Stack
Stack은 Vector를 상속받은 자료구조이며, LIFO의 구조를 가진다.
ArrayList, Vector, Stack, LinkedList 비교
[ ArrayList vs Vector ]
우선, ArrayList와 Vector의 가장 큰 차이점은 연산 시, synchronized의 적용여부다.
| ArrayList | Vector |
|---|---|
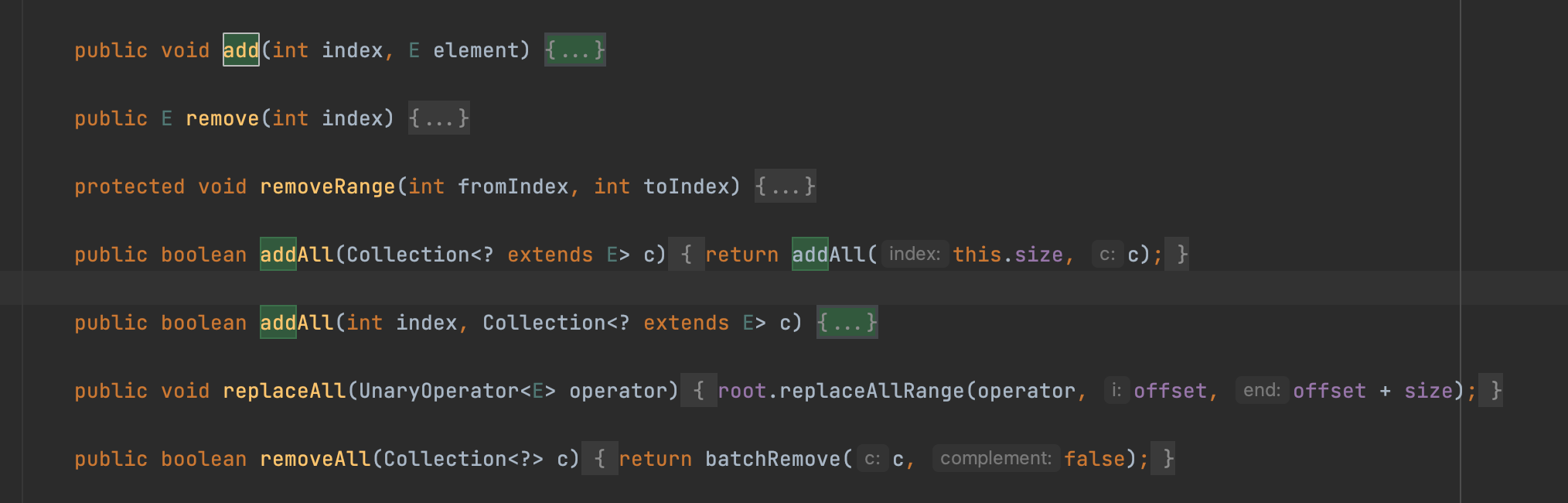 | 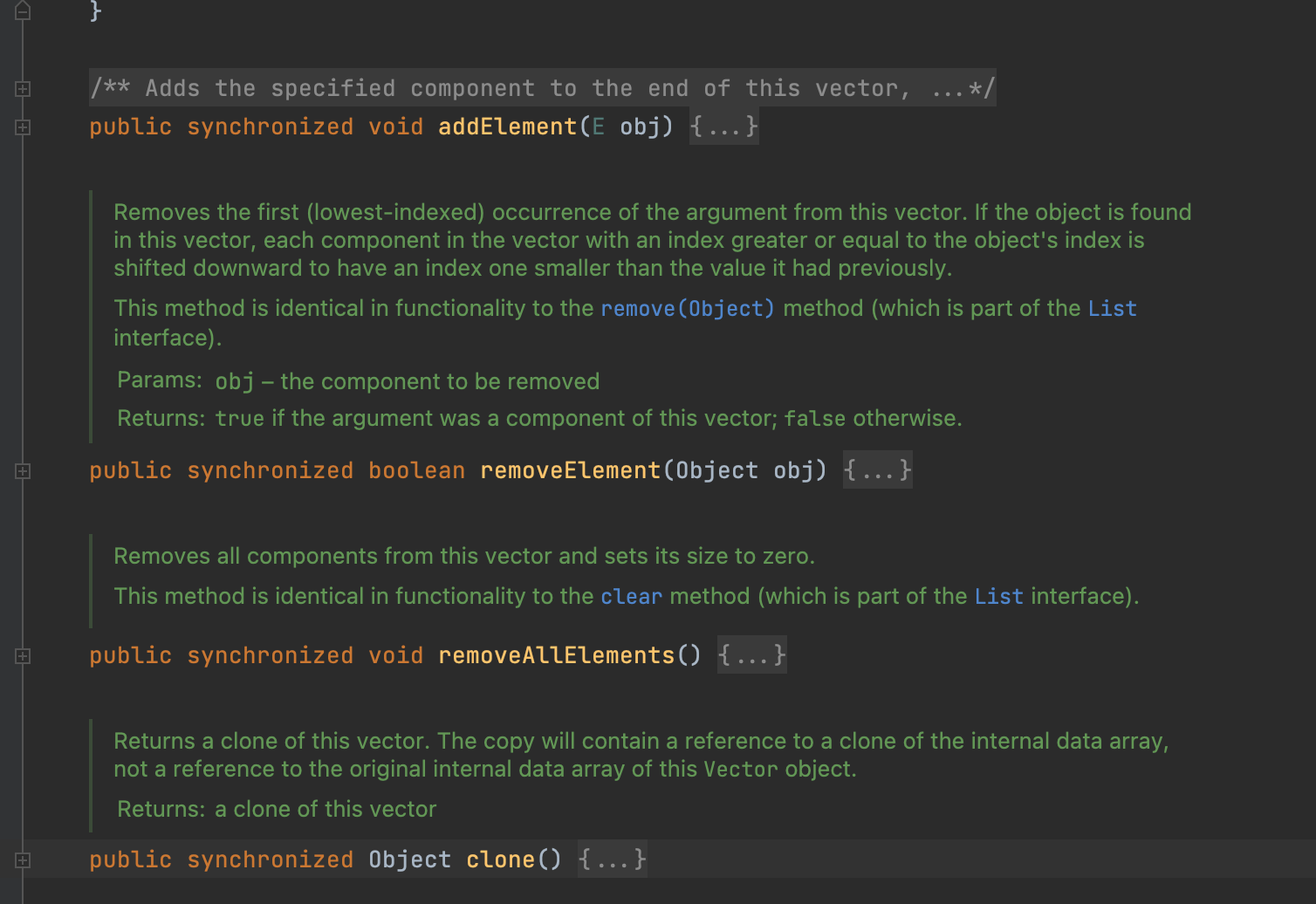 |
Vector를 연산할 때는 synchronized를 통해서 멀티스레드 환경에서 안전하다. 하지만, synchronized의 키워드로 인한 하나의 쓰레드만 접근할 수 있으므로 성능상은 좋지 않다. 이와 달리, ArrayList는 synchronized를 통한 동기화를 제공하지 않아, 멀티 스레드에서 안전하지는 않지만, 빠른 접근이 가능하다.
(참고 : Vector 내부에 구현된 메소드는 synchronized를 통해 동기화를 제공하지만, 이는 메소드 단위의 synchronzied를 제공한다. 따라서, 멀티 스레드에서 삽입과 삭제를 동시에 접근하는 상황이 나온다면, 멀티스레드 환경에서 Thread-safe 하지않다는 것을 유의하자)
[ Stack ]
다음은 Stack이다. Stack자료구조는 용도가 명확하다. Last-In First-Out의 구조를 갖는 자료구조이므로 LIFO구조가 필요한 곳에서 쓰면 된다. (추가로, Stack은 Vector를 상속받았고, 또 Vector와 같이 모든 메소드를 synchronized로 동기화를 제공한다.)
[ ArrayList ] vs [ LinkedList ]
- 검색 연산 측면에서의 비교
ArrayList는 배열을 통해 저장하므로, O(1)의 접근 시간을 갖고 있다. 하지만, LinkedList는 맨 앞 노드부터 차례로 접근을 해야하므로 O(n)의 시간복잡도를 갖게 된다. - 삽입 & 삭제 연산 측면에서 비교
ArrayList에서 연산 시, 내부 배열의 크기가 초과된다면, 다시 배열을 할당하고, 복사하는 과정이 추가된다. 반면에 LinkedList는 ArrayList와 달리 삽입, 삭제 시, 참조를 통해 매우 가변적으로 확장할 수 있다. ( 배열과 달리 연속적으로 메모리에 저장될 필요가 없기 때문)
추가로, ArrayList는 배열로 데이터를 저장하기 때문에, 중간에 삽입, 삭제 시 이전 혹은 이후의 데이터들을 전부 앞으로 밀거나 뒤로 미는등의 추가 연산이 필요하다. (물론, LinkedList도 중간에 삽입, 삭제를 위해 앞에서부터 탐색해야한다.)
- 저장공간 효율성 측면에서의 비교
LinkedList는 데이터를 담을 저장공간 외에 앞, 뒤를 참조하는 추가의 저장공간이 필요하다. 반면에 ArrayList는 데이터만 담을 저장공간을 할당하기 때문에 효율적일 수 있다.
참고 1) https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html
참고 2) https://inpa.tistory.com/entry/JCF-%F0%9F%A7%B1-ArrayList-vs-Vector-%EB%8F%99%EA%B8%B0%ED%99%94-%EC%B0%A8%EC%9D%B4-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
