Set 인터페이스
Collection을 상속받은 인터페이스 중 하나인 Set은 순서와 상관없이 중복되지 않는 데이터를 저장하기위한 자료형이다.
Set을 구현한 많은 클래스 중 대표적으로 HashSet, TreeSet, LikedHashSet에 대해 알아보자.
1. HashSet
HashSet은 내부적으로 HashMap 자료형 변수를 갖고 있어 해당 변수 내에 삽입, 삭제, 검색등의 연산이 이루어진다.
- Hashmap
- HashMap은 내부적으로 다음과 같은 Node단위로 데이터를 저장한다. 해당 노드는 hascode, key, value, next(= 동일한 Hashcode 값이 같을 경우를 위하여)를 가지고 있다.
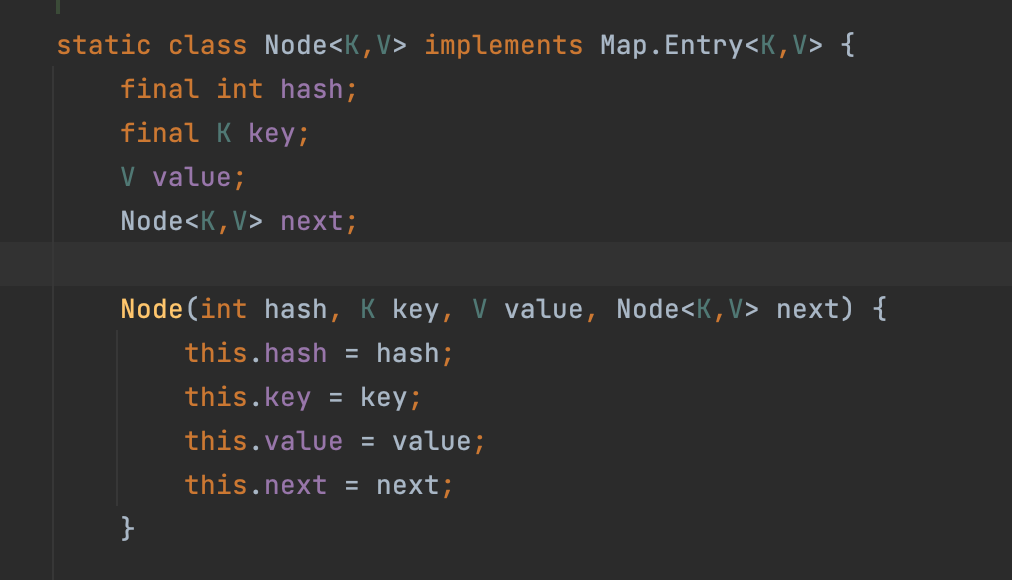
HashSet의 삽입 과정
- hashcode를 통해 HashMap에 저장된 데이터가 있는지 확인한다.
- HashMap 저장된 데이터가 없는 경우 삽입완료한다.
- HashMap에 저장된 데이터가 있는 경우, 해당 객체의 equals() 연산을 수행한다.
- equals() 연산의 결과가 true인 경우, 해당 객체를 저장하지 않고 종료한다.
- equals() 연산의 결과가 false인 경우, 해당 객체를 Node로 저장하고, Node의 next 참조를 통해 연결한다.
HashSet의 삽입 과정은 위와 같은데, 삽입 뿐만아니라 삭제, 검색등의 연산도 hashcode와 equals를 이용하므로 서로 다른객체임을 명확히 하기위해서는 hashcode와 equals 메소드의 오버라이딩 해야한다.
HashSet은 기본적으로 16개의 저장 공간을 갖고 있고 0.75의 로드팩터(= 저장공간 대비 데이터 개수)를 갖는다. 만약, HashSet을 사용하던 중 설정되어 있는 로드팩터보다 커지면 저장공간의 크기는 증가하고, 재정리 작업을 수행한다.
2. TreeSet
TreeSet은 Red-Black Tree의 이진탐색 트리로 이루어져 있다. 이진탐색 트리는 Tree Level이 균등하기 때문에 검색에 대해 빠른 응답을 갖고 있다. 하지만, 삽입, 삭제시 Tree Level의 밸런스가 무너지면 해당 Level을 다시 밸런싱하게 유지하기 위해 재구성되는데 추가 연산이 필요하다.
TreeSet은 내부적으로 TreeMap 자료형 변수를 갖고 있으며 해당 변수내에 삽입, 삭제, 검색등의 연산이 이루어진다.
- TreeMap
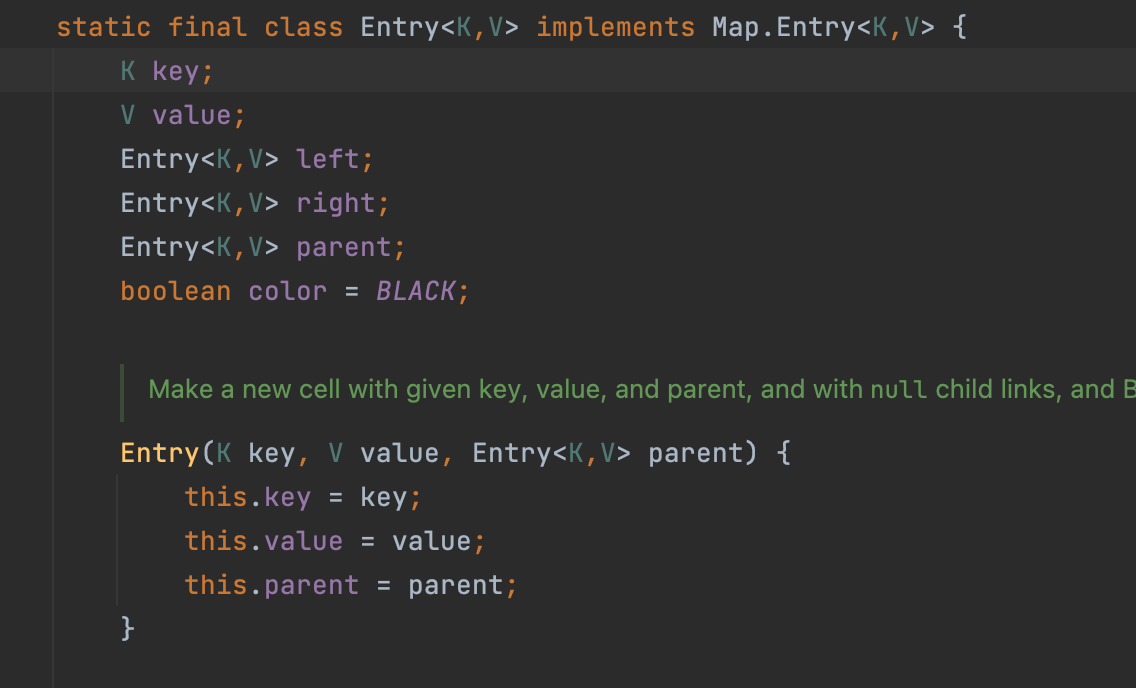
TreeSet은 저장할 때, comparator 비교를 통해, 이진탐색 트리를 구성한다. TreeSet에 String과 같은 이미 정의되어 있는 특별한 자료형을 저장할 때는 대소문자 혹은 숫자를 구분하여 이진탐색 트리를 구성한다. 만약, 다음과 같이 CustomClass를 TreeSet에 저장하려면, 해당 객체의 Key값을 비교할 수 있도록 comparator를 구현하여 다음과 같이 전달해야 한다. 만약, 그렇지 않으면 ClassCast Exception 에러가 발생한다.
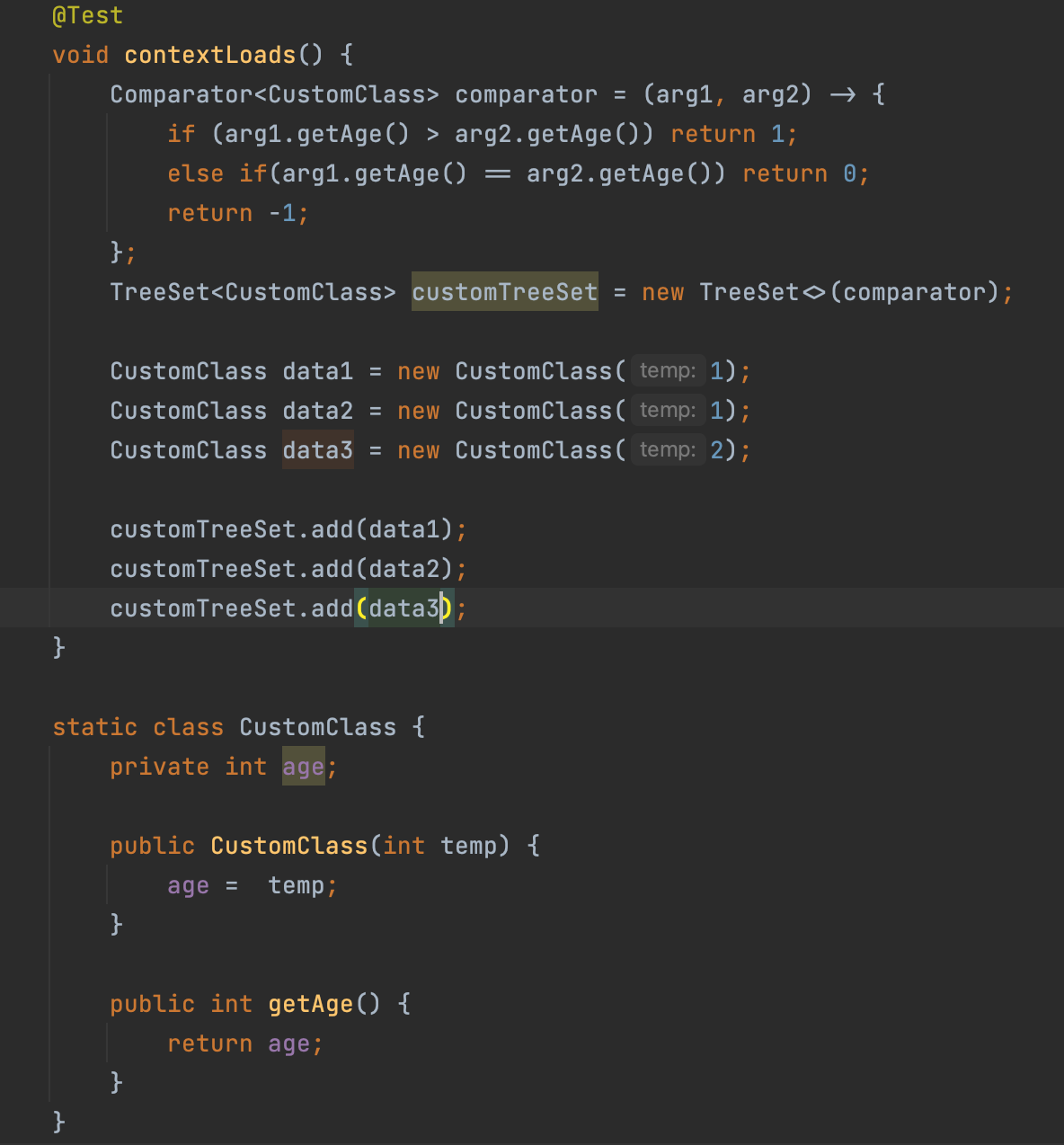
또, TreeSet은 HashSet과 달리 hashCode() 메서드는 요소 간의 동등성을 결정하거나,정렬하는 데에 사용되지 않는다.(위에서 말했듯, comparator를 사용한다.) 다만, 해당 데이터를 검색하거나 TreeSet에서 데이터의 존재 여부를 판단할때에는 hascode() 메소드를 사용한다.
3. LinkedHashSet
LinkedHashSet은 HashSet을 확장한 컬렉션이고, 추가적으로 구현한 것은 별로 없다. 따라서, 1.HashSet과 매우 유사하다. 다만, LinkedHashSet은 HashSet과 저장된 순서를 유지한다.
HashSet vs LinkedHashSet vs TreeSet 차이점
우선, HashSet과 LinkedHashSet은 버킷을 통해 데이터를 저장한다.
HashSet은 hashcode를 통해 버킷을 할당하고, 데이터를 저장한다. 만약 동일한 hashcode를 갖고 있는 요소가 있으면, equals()를 통해 동등성여부를 판단하고, 해당 결과에 따라 버킷 내에 내부적으로 다시 Tree구조로 데이터를 저장한다. 다만, LinkedHashSet은 이 과정에서 가장 마지막에 삽입된 요소가 제일 마지막으로 저장된다.
반면에, TreeSet은 버킷구조를 사용하지 않고, Comparator를 통한 Red-Black Tree의 이진탐색 트리를 통해 데이터를 저장한다.
HashSet은 요소의 순서가 중요하지 않을 때 사용할때 적합하고, LinkedHashSet은 빠른 액세스와 삽입 순서를 유지해야 하는 경우에 사용하기 적합하다. TreeSet은 Custom Comparator를 기반으로 사용자 정의에 따라서 정렬해야 하는 경우에 사용하는 것이 적합하다.
추가로, Set은 해당 데이터가 존재하는지 여부를 판단하기 위해 사용된다. hashcode계산 혹은 balance tree를 통해 O(1), O(logN)안에 빠르게 판단할 수 있다. 만약, Set을 통해 해당 데이터를 가져와 추가적인 연산을 필요하려면, 모든 요소를 순회하며, 해당 데이터를 가져와야 한다. 따라서 이런 경우 Set보다는 Map이나, List등의 다른 자료구조를 사용하는 것이 적합할 수 있다.
