Java8 부터 지원한 stream을 사용하면서 filter, map, flatMap, collect가 어떤 기능을 위해 쓰는지는 필요에 의해 검색해가며 알긴 했지만, stream에 대해 궁금증이 생겼을 때 일단 동작하니 넘겼던 지난날의 근본없음을 반성하는 마음으로 공부해보게 되었다.
Modern JAVA In Action의 Chapter 4 ~ 6을 보며 새롭게 알게된 내용을 정리했다.
Stream Source의 순서와 최종 결과의 순서는 보장될까?
별도 sorted를 사용하지 않고, source가 순서가 있는 collection이라면 stream도 순서대로 소비된다.
즉, 순서가 유지된다.
source : 처음에 제공된 collection, array, I/O resource
Stream의 내부 동작은 언제 일어날까??
collect가 호출되기 전까지 앞의 method들이 호출되고 chain이 queue에 쌓여있을거라 생각하지만,
collect(Terminal operation)가 호출되기 전까지는 결과 뿐만아니라 source의 요소도 선택되지 않는다.
중간 연산자(Intermediate operation)가 아예 수행되지 않고 기다린다.
-> lazy evaluation
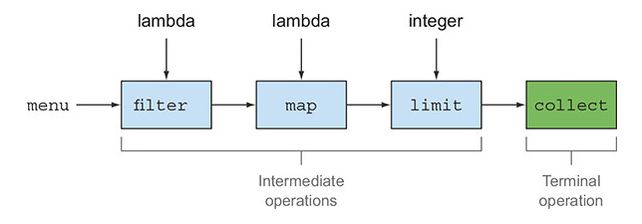
Intermediate operation
- 다른 stream을 return 한다.
- filer
- sorted
Terminal operation
- stream pipeline을 실행하고 result를 생성한다.
- collect
- count
- forEach
anyMatch, findFirst 등은 source를 전부 확인할까?
전체 stream을 처리하지 않고, source 하나 씩 중간 연산들을 모두 수행하고, 요소가 발견되자 마자 결과가 생성된다. (limit도 동일)
-> short circuiting evaluation
List<String> names =
menu.stream()
.filter(dish -> {
System.out.println("filtering:" + dish.getName());
return dish.getCalories() > 300;
})
.map(dish -> {
System.out.println("mapping:" + dish.getName());
return dish.getName();
})
.limit(3)
.collect(toList());
System.out.println(names);filtering:pork
mapping:pork
filtering:beef
mapping:beef
filtering:chicken
mapping:chicken
[pork, beef, chicken]findFirst와 findAny는 같은게 아닌가?
stream이 source collection 순서대로 처리하는데 stream API는 왜 findFirst와 findAny 비슷한 동작을 만들었을까?
parallel stream을 사용할 때, 어떤 요소가 반환되는지 신경쓰지 않으면 findAny를 사용한다.
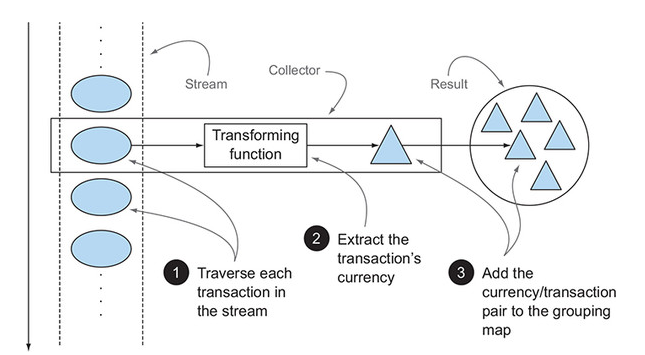
Collection, Collector, collect의 차이
Map<Currency, List<Transaction>> transactionsByCurrencies =
transactions.stream()
.collect(groupingBy(Transaction::getCurrency));- collect method에 전달되는 argument는 Collector interface의 구현체이다.
- toList : 각 요소 목록을 차례로 List를 만들어라
- groupingBy : key가 bucket이고 value가 bucket에서 list의 요소들로 하는 Map을 만들어라
- Collector
- stream의 reduction 작업을 수행하는 방법을 정의한다.
- element를 변환 과정인 Collector는 최종 output의 data structure에 최종 결과값을 누적시켜둔다.
- Collectors utility class는 다양한 static factory method들을 제공한다. ex. Collectors.toList()
public interface Collector<T, A, R>
Classification of an item in the stream during the grouping process
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
Function<A, R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}