기존 상황
길지 않은 개발 일정과 팀 전체가 Spring Batch에 대한 지식이 없었던 터라, 유지보수 측면에서 배치 서버를 Spring Web MVC 로만 구현하게 되었고, Service class에서 모든 로직처리 하고있었다.
복잡한 코드
스케줄링 되는 작업 자체는 1개 뿐이지만, 한 클래스에서 처리하다보니 코드 복잡도가 높았다.
(파일 다운로드 -> A 유형 처리 -> B 유형 처리 -> C 유형 처리 -> D 유형 처리 -> 파일 삭제)
단계마다 로깅을 심어두긴 했으나, 에러가 발생했을 때 바로 알아보기엔 힘들었다.
메모리 소모
개발 진행 전 검토 단계 때 확인한 것보다, 실제 파일의 데이터가 생각보다 크다보니 메모리가 많이 쓰였다.
(a) 파일 하나(25MB, 배열 형태로 천개의 데이터가 존재)씩 읽고
(b) 읽은 파일 하나에서 데이터 리스트를 객체로 한번에 만듦
(c) 맵핑은 순차 처리로 하지만, 이전 과정에서 읽고 기다리는데서 메모리를 많이 잡아먹었다.
files.stream()
.map(Files::readString) // (a)
.map(jsonString -> { // (b)
return objectMapper.readValue(jsonString, new TypeReference<List<ContentRes>>() {
});
})
.flatMap(List::stream)
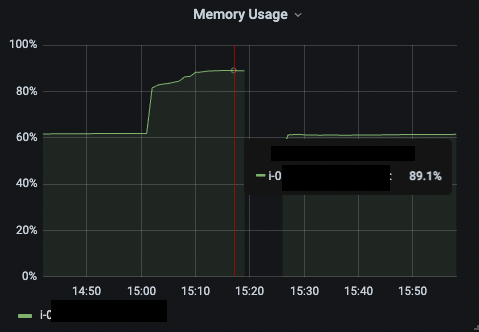
.map(this::convertToContent) // (c)배치 서버는 최소 인스턴스 스펙으로 가져갈 예정이었는데, 데이터가 큰 작업을 수행시켜보니 메모리 사용량 약 90% 를 찍고 서버가 죽어버리는 현상이 발생했다.
개별 Insert 속도
개별로 Insert를 수행하다 보니 주간 작업의 경우 항목의 수가 많지 않으나, 처음 마이그레이션 시에는 50만개를 진행하면서 생각보다 시간이 오래걸렸다.
몇 개씩 모았다가 Bulk Insert를 하려고 보니, 위의 문제들을 포함해서 차라리 빨리 Spring Batch로 바꾸는게 나을 것 같다는 생각을 하게되었다.
어떤걸 해결할 수 있을까?
Spring-Batch?
유연성과 확장성, 운영 효율성을 갖춘 대규모, 복잡한 배치 작업을 필요로 하는 프로젝트에 적합한 프레임워크
기존 상황에서 Spring Batch로 바꿨을 때 다음과 같은 장점이 있었다.
-
작업을 Step 단위로 나누어 관리하며 코드의 모듈성과 가독성 향상
-
작업 흐름을 Config 설정에서 명확하게 파악할 수 있었다.
new JobBuilder("weeklyContentJob") .repository(jobRepository) .start(fileRemoveStep) .next(weeklyFileDownloadStep) .next(createContentStep) .next(updateContentStep) .next(descriptionUpdateStep) .next(cotentClosedStep) .next(fileRemoveStep) .listener(jobExecutionListener) .build(); -
또한 DB Meta Table을 통해 처리 현황(시작 시간, 처리 상태)을 각각 파악하기 쉬웠다.
-
Reader, Processor, Writer의 구조로 읽기, 처리, 쓰기 로직을 분리해 각 단계의 로직을 독립적으로 수정, 확장가능
-
Chunk 단위로 데이터를 처리하며 Processor에서 처리한 것을 모아 Chunk 수 만큼 DB Batch Insert 가능
-
Spring-Batch가 지원하는
JacksonJsonObjectReader를 활용해 JSON 파일에서 항목을 하나 씩 읽어 변환시키면서 메모리를 효율적으로 사용 -
각 Step의 상태에 따라 다음 Step으로 넘어가는 분기 처리 가능
-
실패한 작업을 자동으로 재시도하거나, 특정 지점에서 다시 시작할 수 있는 기능을 제공
-
skip, retry를 진행 할 Exception 지정 가능

결과
-
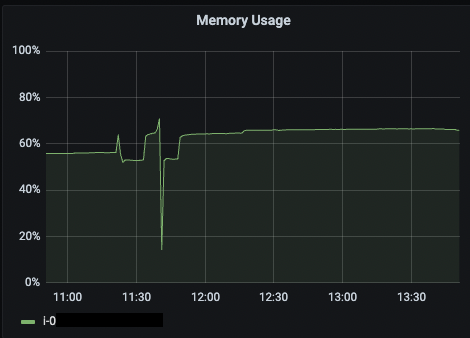
제일 처음에 메모리를 많이 사용했을 때와 동일한 데이터를 spring-batch 로 전환 해, 다시 작업을 진행했고 에러 없이 정상 처리되었다.
-
또한 최초 작업 시에는 인스턴스 스펙을 올려 멀티 프로세싱 처리를 했는데, 기존에는 직접 CompletableFuture 사용해 비니지스 로직에 붙여야 했지만, Spring Batch에서는 Step을 만들 때 설정만 해주면 비니지스 로직을 건들지 않다도 되는 점이 좋았다.
-
데이터가 적을 때는 크게 차이가 드러나지 않지만, 최초 작업 시에는 무조건 Insert 작업이 진행되기 때문에, 시간을 단축 시킬 수 있었다.
-
FE 개발자가 있었다면, DB Meta Table을 ADMIN에 연동할 수 있었겠지만..
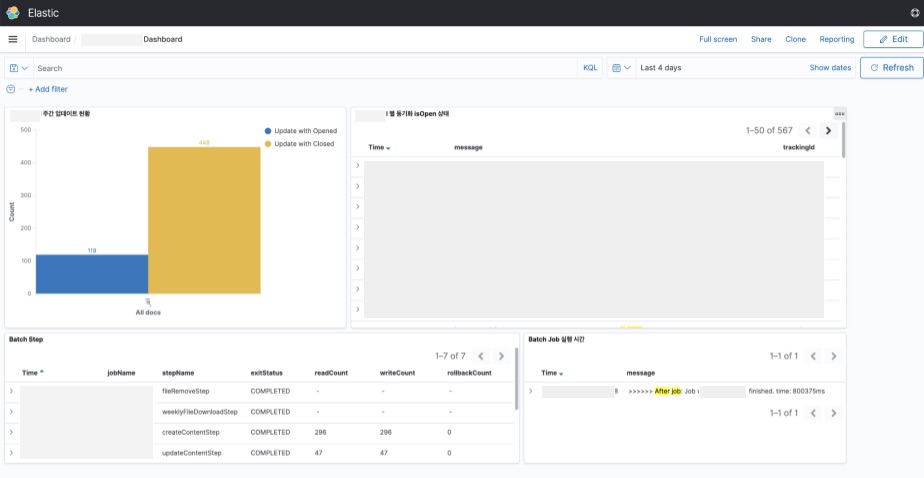
BE 개발자 뿐인 상황에서 작업을 늘리기엔 다른 업무가 많아, 대신 Step Listener에서 로깅으로 Step 별 작업 상황을 로깅해두고, 이를 Kibana Dashboard에서 볼 수 있도록 해두었다.@Override public ExitStatus afterStep(StepExecution stepExecution) { putTag(stepExecution); if (ExitStatus.COMPLETED.equals(stepExecution.getExitStatus())) { log.info(logMessage); } else { log.error(logMessage, stepExecution.getFailureExceptions()); } clearTag(); return stepExecution.getExitStatus(); } private void putTag(StepExecution stepExecution) { MDC.put("stepName", stepExecution.getStepName()); MDC.put("jobName", stepExecution.getJobExecution().getJobInstance().getJobName()); if (stepExecution.getReadCount() > 0) { MDC.put("readCount", String.valueOf(stepExecution.getReadCount())); MDC.put("writeCount", String.valueOf(stepExecution.getWriteCount())); MDC.put("rollbackCount", String.valueOf(stepExecution.getRollbackCount())); } MDC.put("exitStatus", stepExecution.getExitStatus().getExitCode()); } private void clearTag() { MDC.clear(); }