
회귀모델을 제외한 머신러닝 모델은 성능은 우수하나 해석이 어려운 문제점이 있다. 입력변수 중 가장 중요한 변수를 찾는 것은 데이터기반 의사결정을 위해 중요한 일이다. 본 글에서는 머신러닝 모델에서 이러한 변수의 중요도를 찾는 세 가지 방법을 살펴보고 실습 데이터로 직접 계산해보고자 한다.
1. Feature importance
-
트리 기반 모델에서 각 노드가 변수별 특정 기준으로 Split될 때 불순도 감소분의 평균을 해당 변수의 중요도로 정의하여 계산하는 방법이다.
각 노드에서 불순도의 감소분은 아래와 같이 표현할 수 있다.
특정 변수를 기준으로 분기한 결과 불순도가 감소하였다면 해당 변수가 기여를 한 것으로 본다.
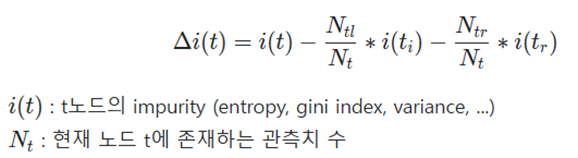
-
Feature importance 방식은 빠르고 직관적이다. 트리 기반 모델(Decision Tree, RandomForest, Boosting계열 알고리즘 등)에서 기본적으로 Feature importance를 속성으로 제공한다.
-
그러나 범주의 종류가 많은 변수를 이용하면 이 변수가 분기에 활용될 가능성이 높아 해당 변수의 Feature importance가 과하게 높게 나올 수 있어 주의가 필요하다.
또한 의사결정나무의 분기 과정에서 감소하는 불순도를 이용하였기 때문에 트리 기반 모델에서만 계산할 수 있는 근본적 한계가 있다.
2. Drop column importance
-
이름에서 알 수 있듯이 변수를 하나씩 제거하면서 모델 성능의 변화를 측정하고 이를 해당 변수의 중요도로 정의하여 계산하는 방법이다.
-
우리가 흔히 생각하는 중요도의 개념과 비슷하여 직관적으로 이해하기 편하며 트리기반 모델이 아니어도 이용 가능하다.
-
그러나 변수를 제거하면서 모델링을 해줘야하기 때문에 데이터 사이즈가 큰 경우 계산에 오랜 시간이 소요될 수 있다.
3. Permutation importance
-
지금까지의 중요도 척도는 모델링을 통해 파악하는 성격이었다. permutation importance는 그와는 성격이 조금 다른데, 모델링이 아닌 테스팅을 통해 변수의 중요도를 파악한다.
즉, 모델을 테스트할 때 대상 변수의 값을 무작위로 섞었을 때와 안했을 때 모델 성능의 차이를 확인하는데, 만약에 모델 성능에 중요한 변수라면 테스트데이터를 섞었을 때 성능이 크게 떨어졌을 것이다. 반대로, 성능에 별 차이가 없다면 해당 변수는 중요하지 않을 수 있다.
이를 계산하기 위해 붓스트랩 샘플을 이용해 성능의 차이를 수 차례 구한다. 그리고 이를 평균내면 해당 변수의 일반적인 기여도가 산출된다.
-
permutation importance의 가장 큰 장점은 어떤 모델에서도 사용 가능하면서 테스팅을 이용하므로 모델링을 반복적으로 해줄 필요가 없다는 것이다.(위에 두 기법의 단점을 다소 해소)
-
단, 키와 몸무게 등 통계적으로 어느 정도 상관관계가 있는 변수의 값을 무작위로 섞으면 현실적으로 불가능한 데이터가 생성되어 결과의 신뢰도가 떨어진다는 단점도 존재한다.
4. 정리
-
변수 중요도를 측정하는 세 가지 방법은 개념과 목적이 다르기때문에 어떤 방법이 우수하다고 단정짓기 어렵다. 각각의 상황에 맞게 적절한 방법을 선택해서 사용하는 것이 바람직하다.
방법 특징 장점 단점 Feature importance 노드 분기에 따라 감소하는 불순도로 계산 빠르고 사용이 편리 트리 기반 모델에서만 사용 가능 Drop column importance 변수 제거 시 감소하는 모델 성능으로 계산 직관적으로 이해하기 편함 모델링을 반복함에 따라 오랜 시간 소요 Permutation importance 테스트데이터에서 데이터를 무작위로 섞어 감소하는 모델 성능으로 계산 어떤 모델에서도 사용 가능하며 모델링 반복 불필요 현실적으로 불가능한 데이터 생성 가능
5. 파이썬 실습
-
본 실습에서는 scikit learn에서 제공하는 breast_cancer 데이터를 이용해 각 변수의 중요도를 계산해본다. 기본 모델은 RandomForest Classifier를 이용하였다.
Feature importance는 각 트리기반 모델에서 속성값으로 제공을 하고 있으며 Permutation importance는 별도 메소드를 이용하면 되나, Drop column importance는 직접 계산을 해주어야 한다.
-
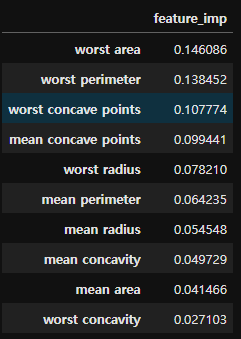
Feature importance
- 파이썬 코드
feature_importance_df = pd.DataFrame(rf_clf_model.feature_importances_,\ index = rf_clf_model.feature_names_in_).rename(columns = {0:'feature_imp'})\ .sort_values(by = 'feature_imp', ascending = False) - 결과
- 파이썬 코드
-
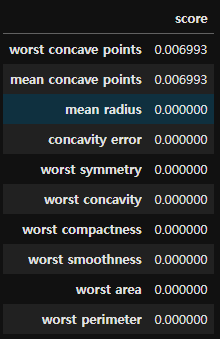
Drop column importance
-
파이썬 코드
score = [] drop_feature = [] rf_clf_model = RandomForestClassifier(random_state=42, n_estimators = 150) for col in X_train.columns: drop_feature.append(col) rf_clf_model.fit(X_train.drop(columns = col), y_train) score.append(rf_clf_model.score(X_test.drop(columns = col), y_test)) rf_clf_model.fit(X_train, y_train) base_score = rf_clf_model.score(X_test, y_test) drop_importance_df = pd.DataFrame(score, index = drop_feature).rename(columns = {0:'score'}) drop_importance_df['score'] = base_score - drop_importance_df['score'] drop_imp_10 = drop_importance_df.sort_values(by = 'score', ascending = False).head(10) -
결과
-
-
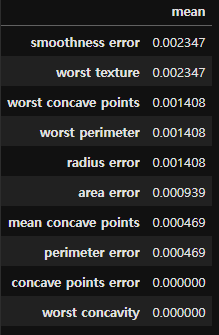
Permutation importance
-
파이썬 코드
from sklearn.inspection import permutation_importance permu_imp = permutation_importance(estimator = rf_clf_model, X = X_train, y = y_train, random_state=42) permu_importance_df = pd.DataFrame(permu_imp.importances, index = X_train.columns) permu_importance_df.columns = [f'repeat_{i}' for i in range(1, 6)] permu_importance_df.loc[:,'mean'] = permu_importance_df.iloc[:-1].mean(axis = 1) permu_importance_df -
결과
-
-
비교시각화
-
Drop column importance는 특정 변수에 중요도가 집중되어 비교가 어려우며, feature importance와 permutation importace는 중요도 비교가 가능한 수준이다.
-
계산 방법에 따라 중요한 변수 또한 다르게 나타난다. 어떠한 알고리즘을 중심으로 중요도를 계산할지 분석가의 판단이 필요한 부분이라고 생각한다

-
