

파이썬에서 판다스 데이터프레임을 전처리하다보면 아래와 같은 경고나 오류가 나올 때가 있다. 이 증상에 대한 원인과 대처법을 알아보자.
-
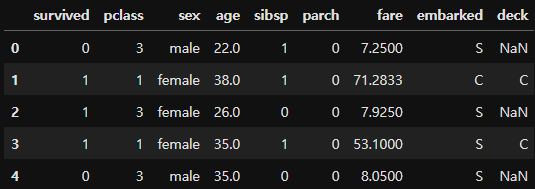
(상황) 다음과 같은 데이터프레임에서 survived의 데이터타입을 object로 변환하려한다.
-
다음과 같이 코드를 작성해서 실행하니
df2 = df[['survived', 'pclass']] df2.survived = df2.survived.astype(object) -
아래와 같은 경고메세지가 나왔다.

-
'A value is trying to be set on a copy of a slice from a DataFrame' 즉 데이터프레임 일부의 복사본을 수정하려한다는 경고문이다. 나는 데이터프레임 원본을 수정하려하는데 왜 이런 경고문이 나오는 것일까? 아래 documentation을 확인해본다.
-
Copy on Write(CoW) 적용과 Chained indexing 미지원
-
링크로 연결되는 판다스 documentation에서는 판다스 3.0버전부터 CoW를 적용함에 따라 Chained indexing을 지원하지 않는다고 설명하고 있다.
[바로가기] Pandas documentation-
Chained indexing이란 데이터프레임을 인덱스해서 추출할 때 추출한 데이터프레임에 다시 인덱스를 이용해 새로운 데이터프레임을 추출하는 것을 의미한다. 예를들면 아래 코드와 같다.
df[['column1','column2']]['column1'] == 'abcd' -
Chained indexing은 분석 시 의식의 흐름에 따라 간결하게 데이터프레임을 가공하는 장점이 있지만 추후 인덱싱한 데이터프레임을 수정할 때 원본 프레임까지 수정하는지 여부가 애매모호해지는 문제점이 있다. 예를 들어 위 코드는 첫 번째 인덱싱에서 부분데이터를 반환하므로 원본 데이터와 부분데이터가 메모리에 공존하게 되데, 이후 인덱싱으로 df의 해당 칼럼을 수정하는 것인지? 아니면 df의 부분집합을 수정하려고 하는 것인지 처리하는 시스템 입장에서는 모호하다.
-
-
따라서 판다스에서는 Copy on Write(CoW, 쓰기 시 복사)를 준수하도록 권고하고 있으며 향후 동일한 코드 입력 시 작동하지 않을 것이라고 사전 경고를 하고 있는 것이다.
-
-
(오류 방지방안 1) _is_view 속성을 이용하여 데이터프레임의 원본여부 확인하기
-
_is_view란 대상 데이터프레임이 원본 테이블과 동일한지(view) 아니면 원본 테이블의 복사본(copy)인지 확인하는 메소드이다. 위 사례의 속성을 확인하면 아래와 같다.
df2._is_view >> False -
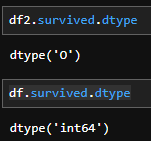
결과는 False이며, df2는 df와 다른 데이터프레임이라는 것이 확인된다. 여기서 데이터타입을 object로 변경하는 코드를 실행한 후 결과를 확인해보면,
-
복사본인 df2의 데이터타입은 변하였으나 원본인 df의 데이터타입은 변하지 않았다. 만약 원본 df의 데이터타입을 바꾸려는 상황이었다면 대상 데이터프레임이 복사본일 때 원본 변경 여부를 반드시 확인할 필요가 있다.
-
-
(오류 방지방안 2) .copy() 메소드 사용 준수!
-
CoW를 준수하여 작성한 코드는 아래와 같다. 전처리한 df를 복사(copy)하여 df2를 새로 만들어준다. 이를 통해 정수 타입으로 변환하려는 데이터프레임을 df2으로 명확히 해준다. 이후 코드를 실행하면 경고나 오류 문구가 출력되지 않는 것을 확인할 수 있다.
df2 = df.dropna().copy() df2['total_spent'] = df2['total_spent'].astype(int) -
만약 원본을 변경하고 싶지 않다면 반드시 sub 데이터프레임 생성 후 반드시 copy메소드를 통해 복사본임을 명확히 해야 향후 예상치 않게 원본이 수정되는 일을 막을 수 있다.
-
