데이터 분석을 하면서 EDA에 사용하는 value_counts()는 다소 형식적으로 이용하곤 한다. 이 글에서는 value_counts()의 옵션을 이용하여 데이터 핸들링 역량을 높이는 방안을 살펴본다.
-
(option 1) dropna = False
- 빈도수를 계산할 때 결측치를 포함한다. 기본값은 True이며 해당 옵션을 지정하여 결측치 수를 따로 계산하는 번거로움을 덜어낼 수 있다.
df[col].value_counts(dropna = False) # default : True
- 사용 예시(dropna = False 지정 전후)
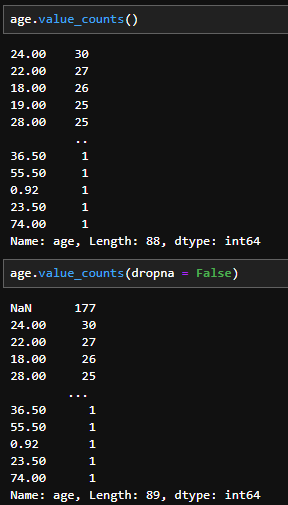
- 빈도수를 계산할 때 결측치를 포함한다. 기본값은 True이며 해당 옵션을 지정하여 결측치 수를 따로 계산하는 번거로움을 덜어낼 수 있다.
-
(option 2) ascending = True
- 빈도수의 오름차순으로 정렬한다. 기본값은 False이며, 해당 기준 index 등을 참조하여 이용할 수 있다. (물론 내림차순 기준 -1 index를 사용해도 가능)
df[col].value_counts(ascending = True) # default : False - 사용 예시(ascending = True 사용 시)
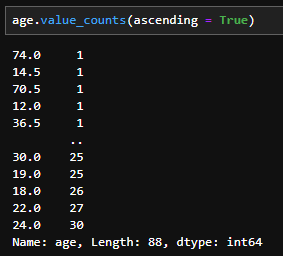
- 빈도수의 오름차순으로 정렬한다. 기본값은 False이며, 해당 기준 index 등을 참조하여 이용할 수 있다. (물론 내림차순 기준 -1 index를 사용해도 가능)
-
(option 3) normalize = True
- 절대빈도가 아닌 상대빈도를 산출할 때 사용한다. 기본값은 False이다. 상당히 유용한 기능인데, 필자는 그동안 절대빈도를 계산하고 총계를 나누어 사용했었다.
df[col].value_counts(normalize = True) # default : False - 사용 예시(normalize = True 사용 시)
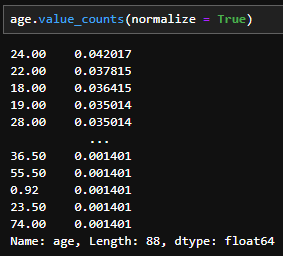
- 절대빈도가 아닌 상대빈도를 산출할 때 사용한다. 기본값은 False이다. 상당히 유용한 기능인데, 필자는 그동안 절대빈도를 계산하고 총계를 나누어 사용했었다.
-
(option 4) bins = #
- 변수 값을 설정한 구간 수만큼 균등하게 나누고 빈도를 산출한다. 이 또한 매우 유용한데, 필자는 그동안 판다스의 cut 함수로 이를 구현하였다.
df[col].value_counts(bins = #) # default : 미설정 - 사용 예시(bins = 5 적용 시)
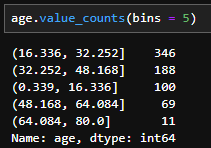
- 변수 값을 설정한 구간 수만큼 균등하게 나누고 빈도를 산출한다. 이 또한 매우 유용한데, 필자는 그동안 판다스의 cut 함수로 이를 구현하였다.

의미 있는 한걸음을 추구합니다.