데이터 해석 오류에 대한 글을 읽으면서 앞으로 데이터를 분석할 때 필요한 습관을 생각해본다.
1. 표본의 대표성 확보여부 확인
2차 세계대전 당시 미 해군은 전투기의 총탄 자국이 많은 곳을 보강해, 더 튼튼한 전투기를 만드는 연구를 진행했습니다. 이때 통계학자 아브라함 왈드(Abrahan Wald)는 총탄 자국이 많은 곳이 아니라, 총탄 자국이 적은 곳을 강화해야 한다고 주장합니다. 무사 귀환한 전투기는 그 부위에 총탄을 맞고도 무사 귀환했을 만큼 크게 영향이 없었다는 것입니다. 이는 전체 전투기가 아닌 무사 귀환한 전투기를 대상으로 총탄 자국을 확인하다 보니 발생한 인지적 오류였습니다.
- 위 사례에서 모집단은 전투에 참가한 모든 전투기이나, 표본에는 전투에 참가하고 무사히 귀환한 전투기만 포함되었다.
- 무사히 귀환한 전투기 뿐만 아니라 전투 중 추락한 전투기까지 표본에 포함하여 분석해야 표본이 모집단을 대표한다고 할 수 있을 것이다.
- 전투 중 추락한 전투기를 확인하기 위해서는 전장에 나가야하며 이는 매우 위험하므로 아브라함 왈드의 주장과 가정이 현실적으로 타당했던 것으로 보인다.
2. 편향된 데이터를 주의할 것
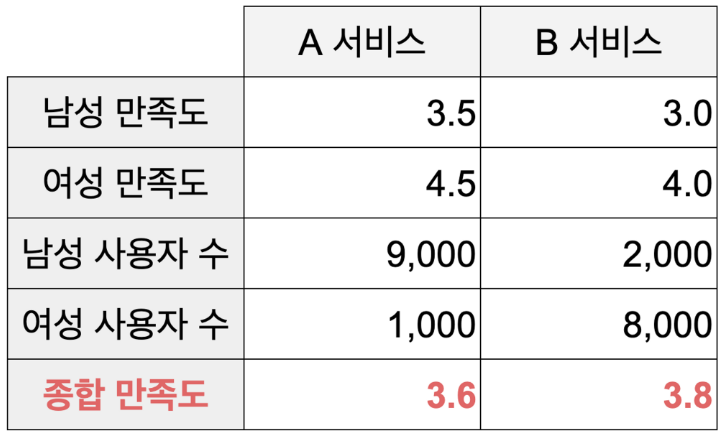
- 위 사례에서 모든 서비스에서 남성이 여성보다 낮은 만족도 점수를 주고 있는 것이 확인된다.
- 두 성별의 만족도를 산술평균하면 A서비스의 만족도가 4.0점으로 더 높아야하나 성별 사용자 기준 가중평균한 결과 종합 만족도는 B서비스가 높게 나왔다.
- 이는 데이터 편향에 따라 발생한 것인데, 특정 범주에 몰려 있는 자료를 분석하면 결과가 해당 범주의 특성에 지나치게 과적합(overfitting)되는 문제점이 나타난다.
- 데이터를 해석할 때 범주별 데이터의 분포를 확인하고 분포가 불균형할 경우 표본 수를 조정(Oversampling, Undersamling)하는 방안 등을 생각해볼 수 있다.
- 또는 성별 만족도와 서비스별 사용자 수를 따로 분석하여 새로운 시사점을 도출해 볼 수도 있을 것이라고 생각한다.

의미 있는 한걸음을 추구합니다.