1. 군집화 개론
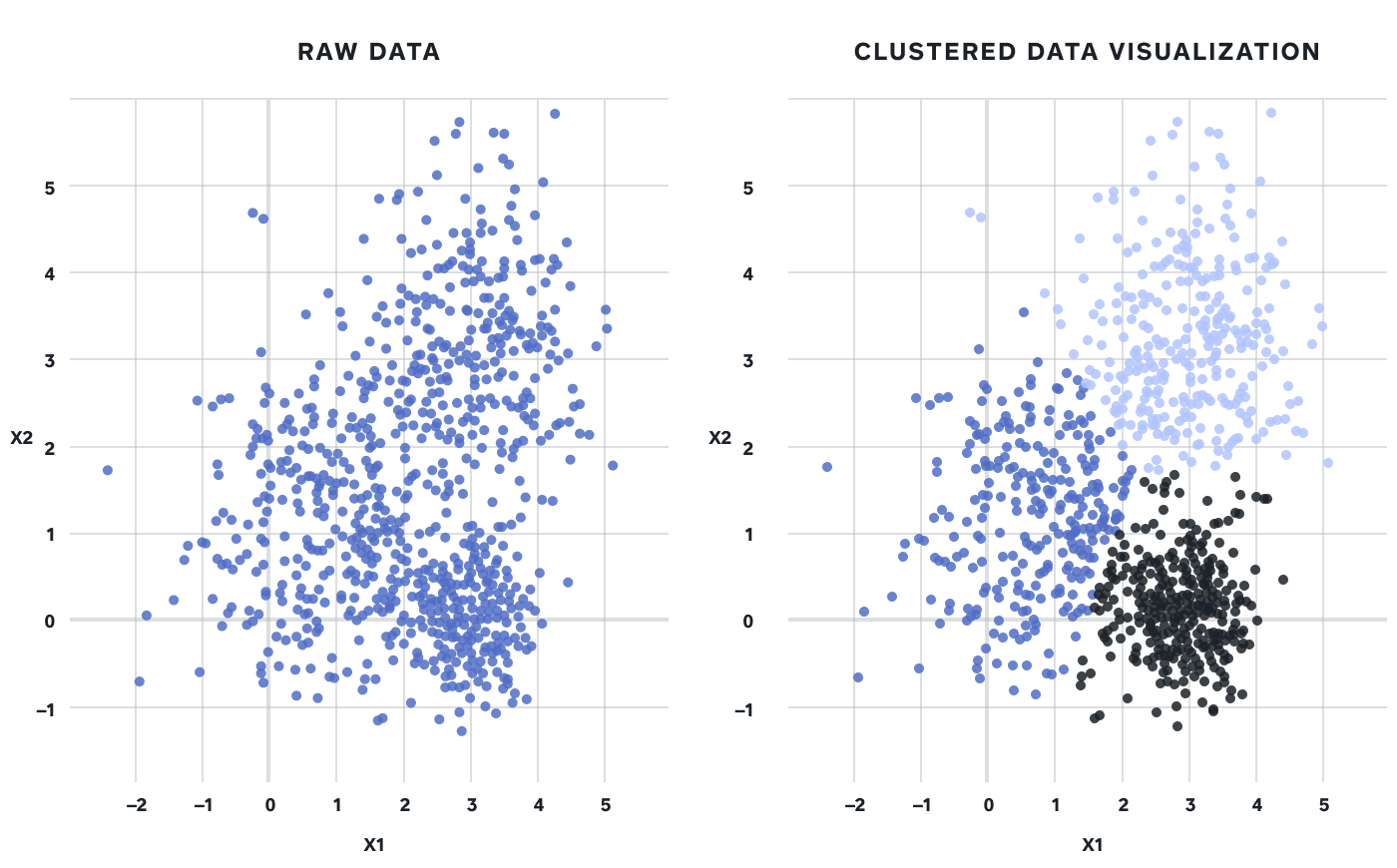
군집화의 목적은 분류이다. 그런데 이 분류는 당연하게 지도에서 Classification을 의미하지 않는다. 비지도 학습으로서 군집화는 각 데이터 포인트의 유사도를 기반으로 비슷한 것 끼리 묶는 것이다.
1-1. Distance Metrics
이때 거리를 측정하는데에는 아래와 같은 방법 등을 사용할 수 있다.
- 유클리드 거리(Euclidean Distance)
- 코사인 유사도(Cosine Similarity)
- 맨해튼 거리(Manhattan Distance)
- 마할라노비스 거리(Mahalanobis Distance)
- 자커드 거리(Jaccard Distance)
2. 잘 클러스팅을 한다는 의미
클러스터링을 잘 한다는 것은 분리도와 응집도를 최적화하는 것이다.
응집도(cohesion)는 클러스터 내 데이터가 얼마나 가까운가를, 분리도(separation)는 클러스터 간 데이터가 얼마나 떨어져 있는가를 의미한다. 이 둘은 트레이드오프 관계이다. 직관적으로 클러스터 수인 k를 증가시키면, 응집도는 올라가지만 분리도는 낮아진다.
여기서 주목할 점은, 거리만을 가지고 이 분리도와 응집도를 정의하지 않는다. 밀도와 확률을 이용해 이를 판단하는 클러스터링 기법도 존재한다.
3. 거리, 밀도, 확률 기반 모델
3-1. 거리 기반 모델
- K-평균 (K-means)
데이터 포인트를 k개의 클러스터로 나누고, 각 클러스터 중심(centroid)까지의 거리 합을 최소화하며 주로 유클리드 거리 사용한다. - 계층적 클러스터링 (Hierarchical Clustering)
데이터 포인트를 점진적으로 병합(agglomerative)하거나 분할(divisive)하며 트리 구조(덴드로그램)를 생성하며 유클리드, 맨해튼, 코사인 등 거리를 선택할 수 있다. - K-메도이드 (K-medoids)
K-평균의 변형으로, 중심 대신 실제 데이터 포인트(medoid)를 대표로 사용한다. 이상치에 덜 민감하며 거리는 유클리드, 맨해튼 등을 자유 선택한다.
당연히 이 방식말고 다른 모델들도 존재하며, 특히 K_* 인 기법들의 경우 K-centroid clustering이라고 한다. 데이터가 연속형인 경우 mean, median을 사용하고, 이산형일 경우 mode, medoid가 일반적으로 사용된다.
3-2. 밀도 기반 모델
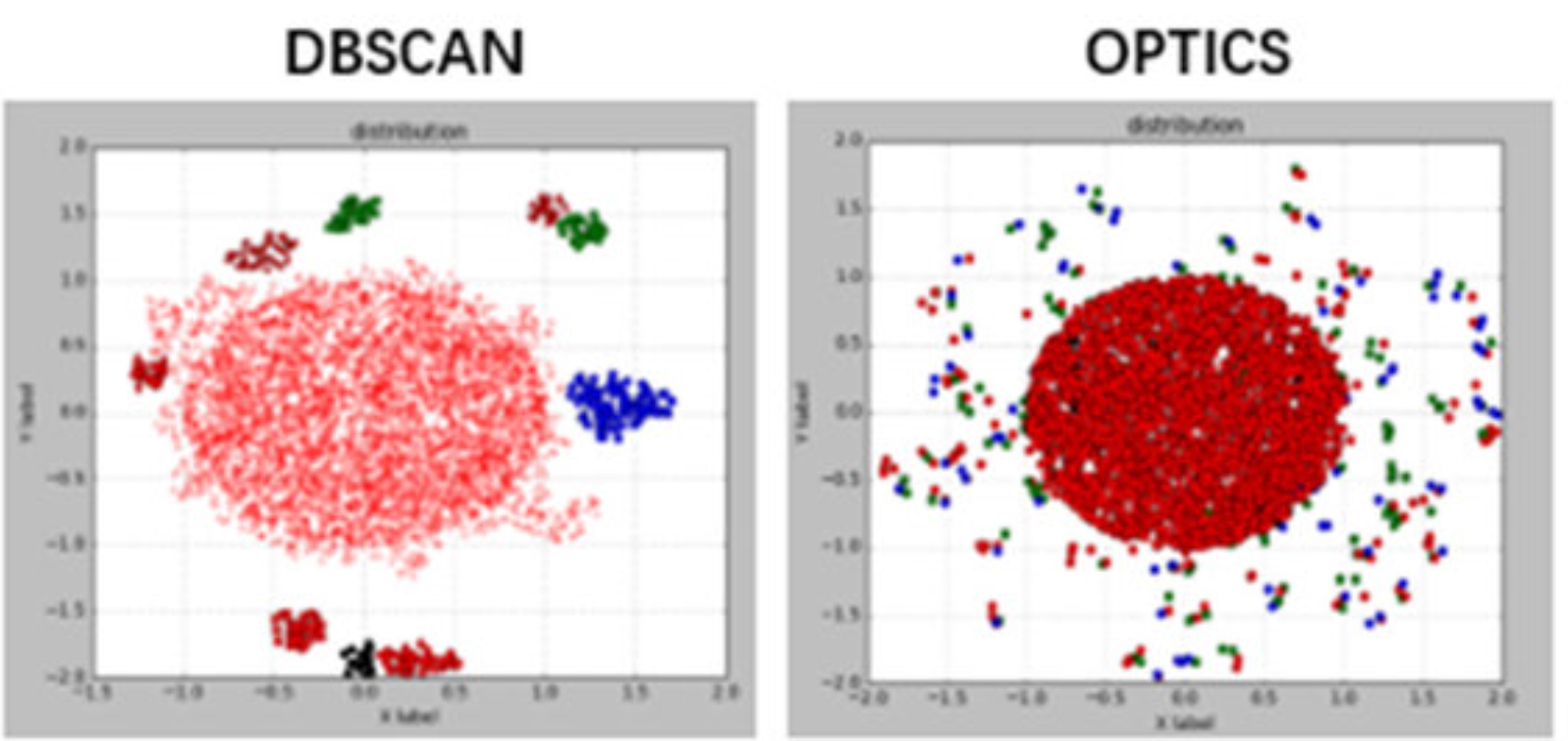
-
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
ϵ 거리 내에 최소 포인트 수(MinPts)가 있는 "핵심 포인트"를 중심으로 클러스터를 확장한다. 밀도는 ϵ 반경 내 포인트 수를 의미한다. -
OPTICS (Ordering Points To Identify the Clustering Structure)
DBSCAN의 확장으로, 밀도 기반 클러스터를 계층적으로 추출하며 ϵ 값에 덜 민감하다. 핵심 거리(core distance)와 도달 거리(reachability distance)로 밀도를 정의한다. -
HDBSCAN (Hierarchical DBSCAN)
DBSCAN을 계층적으로 확장하고, 클러스터 안정성을 고려해 최적 클러스터를 선택한다.
3-3. 확률 기반 모델
확률 기반 클러스터링은 데이터가 특정 확률 분포에서 생성되었다고 가정하며, 가능도(likelihood)나 확률 밀도를 기준으로 클러스터를 나눈다.
가우시안 혼합 모델 (GMM, Gaussian Mixture Model)은 가장 대표적인 예시이다. 데이터를 여러 가우시안 분포의 혼합으로 모델링하고, 각 데이터가 특정 클러스터에 속할 확률을 계산(soft clustering)한다.
실제로는 모델들은 거리와 확률, 밀도 등을 복합적으로 사용하기도 한다. 여기서 중요한 점은, 같은 기반을 가지는 모델이라도 응집도와 분리도를 정의하는 방식이 다르기 때문에, 알맞는 평가지표를 사용해야 한다.
4. 평가 지표
흔히 알려진 silhouete coefficient, elbow method는 거리 기반 모델에 적합한 평가 지표이다. 이외에도 다른 기반들에 적합한 지표들이 존재한다. 간략하게 아래의 표와 같다.
해당 지표들에 대한 세부적인 정의에 대해서는 다른 글에서 다루어 보겠다.
클러스터링 기반에 따른 평가지표 정리
| 평가지표 | 거리 기반 | 밀도 기반 | 확률 기반 | 주요 특징 및 적합 모델 |
|---|---|---|---|---|
| 실루엣 계수 (Silhouette) | Yes | Limited | No | 거리로 응집도/분리도 측정 적합: K-평균, 계층적 클러스터링 |
| 엘보우 방법 (Elbow) | Yes | No | No | WCSS로 최적 k 탐색 적합: K-평균, K-메도이드 |
| 데이비스-볼딘 (DB Index) | Yes | Limited | No | 클러스터 내/간 거리 비율 적합: K-평균, K-메도이드, 계층적 클러스터링 |
| 던 지수 (Dunn Index) | Yes | Yes | No | 클러스터 간 최소 거리/내 최대 거리 적합: DBSCAN, OPTICS, HDBSCAN |
| 캘린스키-하라바츠 (CH) | Yes | No | Limited | 클러스터 내/간 분산 비율 적합: K-평균, GMM (보조적) |
| 갭 통계 (Gap Statistic) | Yes | No | No | WCSS와 랜덤 데이터 비교 적합: K-평균, K-메도이드 |
| 클러스터 안정성 (Stability) | Yes | Yes | Yes | 결과의 일관성 평가 적합: 모든 모델 (DBSCAN, HDBSCAN, 베이즈 혼합 모델에서 강점) |
| 로그 가능도 (Log-Likelihood) | No | No | Yes | 데이터 적합도 측정 적합: GMM, LDA, 베이즈 혼합 모델 |
| AIC/BIC | No | No | Yes | 가능도와 복잡도 균형 적합: GMM, 베이즈 혼합 모델 |
| 퍼플렉시티 (Perplexity) | No | No | Yes | 예측 가능도 평가 적합: LDA (텍스트 데이터) |
| 코히런스 점수 (Coherence) | No | No | Yes | 주제 해석 가능성 적합: LDA (텍스트 데이터) |
- 거리 기반: 실루엣, 엘보우, 데이비스-볼딘 등은 거리 매트릭스(유클리드, 맨해튼 등)에 의존하며, 구형 클러스터에 강점.
- 밀도 기반: 던 지수와 안정성은 밀도 단절과 이상치 처리를 반영, 비구형 클러스터에 적합.
- 확률 기반: 로그 가능도, AIC/BIC, 퍼플렉시티 등은 분포 적합도와 모델 복잡도를 평가, 텍스트나 복잡한 데이터에 유리.
