DFS란?
-
깊이 우선 탐색은 그래프의 시작 노드에서 출발하여 탐색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마친 후 다른 쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘이다.
-
미로를 생각하면, 한 방향으로만 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 뒤로 돌아 가장 가까운 갈림길로 가서 그곳에서부터 다른 방향으로 다시 탐색을 하는데, 이것이 DFS라고 생각하면 편하다.
-
즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것이다.
DFS 특징
-
그래프 완전 탐색 기법 중 하나이다 -> 모든 노드를 탐색하고자 할때 사용한다.
-
Stack과 재귀함수를 이용하여 구현할 수 있다.
-
재귀함수를 이용하므로 스택 오버 플로에 유의해야한다.
-
Stack을 사용하기 때문에 후입선출의 방식을 따른다.
-
깊이 우선 탐색을 응용하여 풀 수 있는 문제는 단절점 찾기, 단절선 찾기, 사이클 찾기, 위상 정렬 등이 있다.
DFS 예시
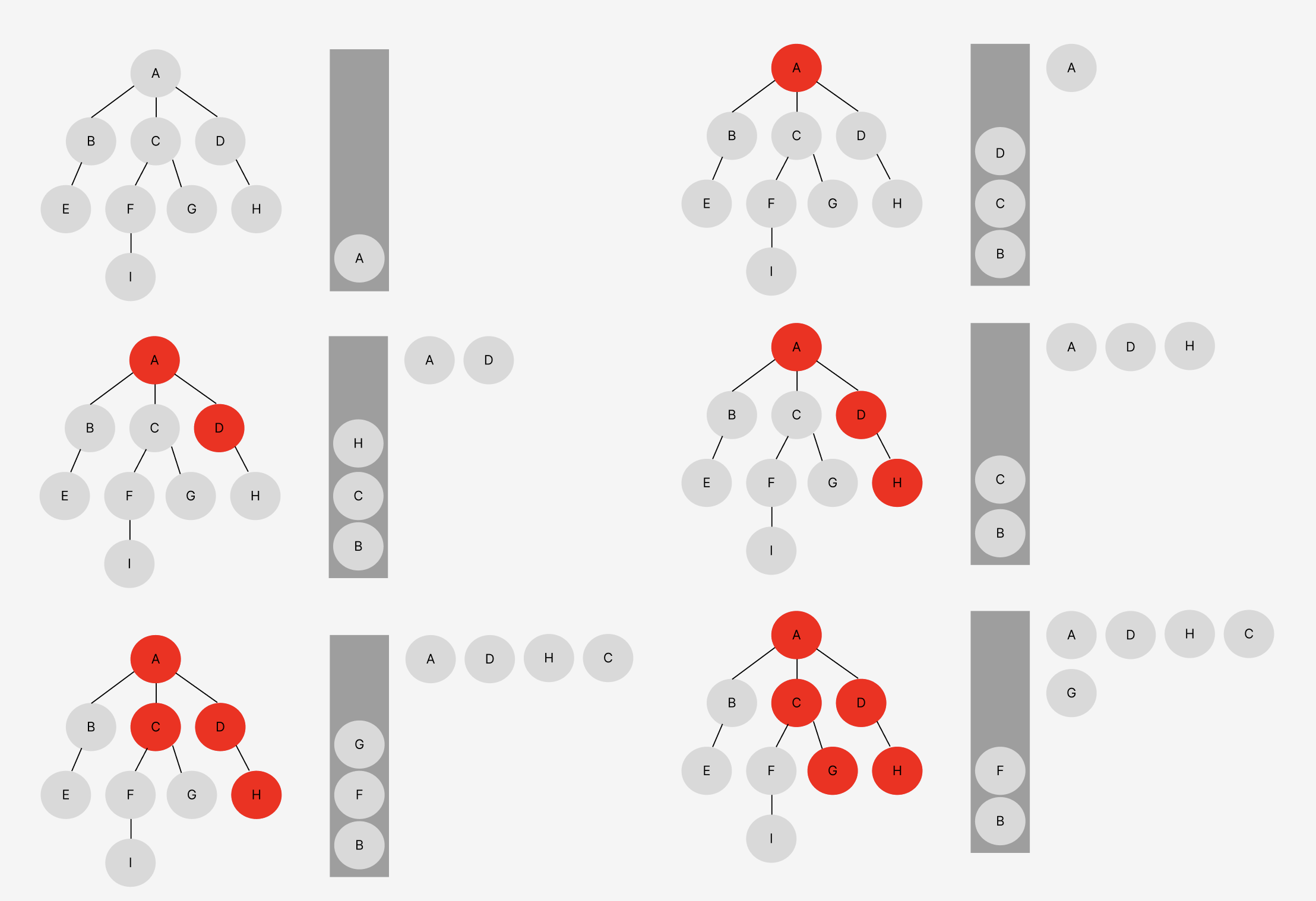
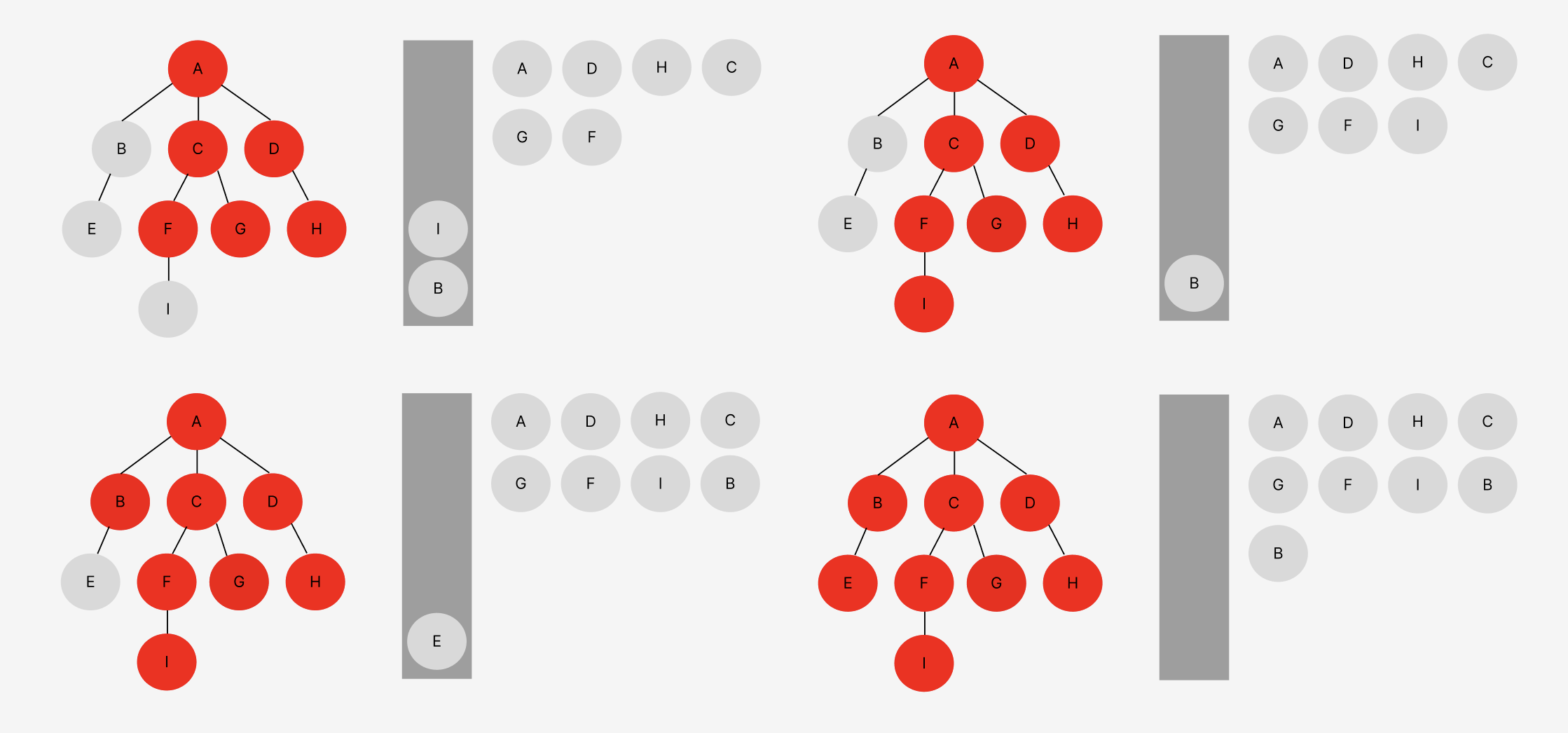
DFS의 시간 복잡도
DFS의 시간 복잡도를 계산할 때는 그래프가 인접 리스트나 인접 행렬로 구현되었는지에 따라 다르다.
노드의 수 = V, 간선의 수 = E
- 인접 리스트를 이용한 DFS
인접 리스트는 각 노드마다 해당 노드에 연결된 간선들을 리스트로 저장하는 방식이다.
노드 1: [2, 5]
노드 2: [1, 5]
노드 3: [4]
노드 4: [3, 6]
노드 5: [1, 2]
노드 6: [4]-
노드 방문: DFS는 모든 노드를 한 번씩 방문하므로, 노드 방문에 걸리는 시간은 O(V)이다.
-
간선 탐색: 각 노드에서 해당 노드와 연결된 모든 간선을 하나씩 탐색하므로, 간선을 모두 탐색하는 데 걸리는 시간은 O(E)이다. 한 번 간선을 따라가면 그 간선은 다시 탐색되지 않는다.
-
따라서 인접 리스트를 사용한 DFS의 전체 시간 복잡도는 O(V + E)이다.
- 인접 행렬를 이용한 DFS
인접 행렬은 노드 간의 연결 관계를 2차원 배열로 저장하는 방식이다. 노드 u와 노드 v가 연결되어 있으면 matrix[u][v] = 1로 저장한다.
1 2 3 4 5 6
1 [ 0, 1, 0, 0, 1, 0 ]
2 [ 1, 0, 0, 0, 1, 0 ]
3 [ 0, 0, 0, 1, 0, 0 ]
4 [ 0, 0, 1, 0, 0, 1 ]
5 [ 1, 1, 0, 0, 0, 0 ]
6 [ 0, 0, 0, 1, 0, 0 ]- 노드 방문: 노드를 한 번 방문하는데 걸리는 시간은 여전히 O(V)이다.
- 간선 탐색: 인접 행렬에서는 노드 간 연결 여부를 확인하려면 모든 노드 쌍을 확인해야 하므로, 각 노드마다 O(V) 시간이 소요된다.
- 따라서, 인접 행렬을 사용한 DFS의 시간 복잡도는 O(V²)다.
백준11723
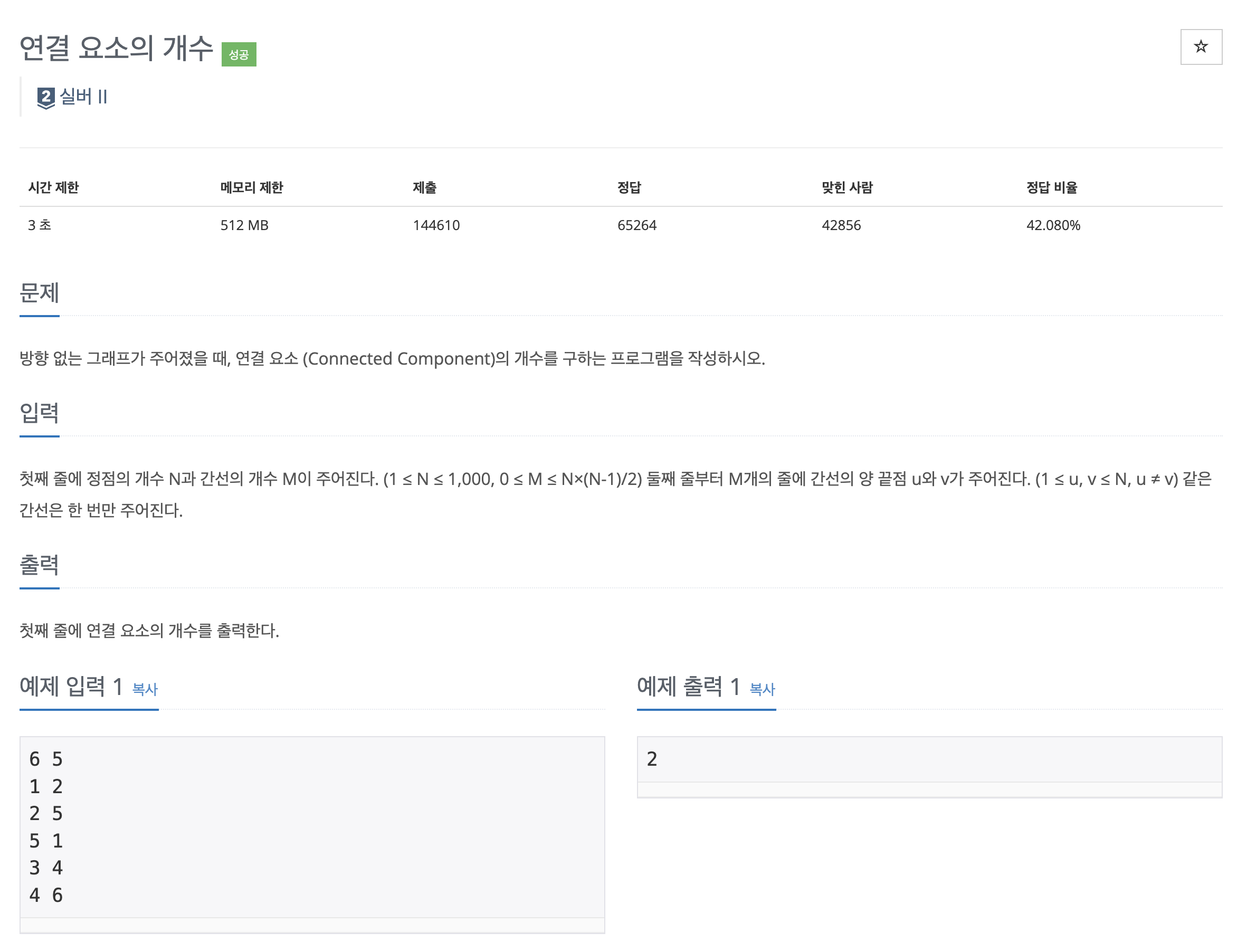
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.Stack;
public class Main {
static int N, M;
static List<List<Integer>> list;
static boolean[] visited;
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
N = input.nextInt();
M = input.nextInt();
visited = new boolean[N + 1];
list = new ArrayList<>();
for (int i = 0; i <= N; i++) {
list.add(new ArrayList<>());
}
for (int i = 1; i <= M; i++) {
int u = input.nextInt();
int v = input.nextInt();
list.get(u).add(v);
list.get(v).add(u);
}
/*
[
노드 1: [2, 5]
노드 2: [1, 5]
노드 3: [4]
노드 4: [3, 6]
노드 5: [1, 2]
노드 6: [4]
]
*/
int count = 0;
for (int i = 1; i <= N; i++) {
if (!visited[i]) {
dfsStack(i);
count++;
}
}
System.out.println(count);
}
//재귀를 이용한 DFS
static void dfs(int n) {
visited[n] = true;
for (int i = 0; i < list.get(n).size(); i++) {
int neighbor = list.get(n).get(i);
if (!visited[neighbor]) {
dfs(neighbor);
}
}
}
// 스택을 사용한 DFS
static void dfsStack(int n) {
Stack<Integer> stack = new Stack<>();
stack.push(n);
visited[n] = true;
while (!stack.isEmpty()) {
int current = stack.pop();
for (int i = 0; i < list.get(current).size(); i++) {
int neighbor = list.get(current).get(i);
if (!visited[neighbor]) {
stack.push(neighbor);
visited[neighbor] = true;
}
}
}
}
// 1 -> 5 -> 2
// 3 -> 4 -> 6
}재귀사용
스택사용

