앞서 전반적인 학습은 nuscenes데이터셋에 대한 pkl파일로 진행
따라서 먼저, nuscens_pkl의 구조를 파악하고,
커스텀 데이터셋이 이와 동일한 구조로 컨버팅 코드를 구성해야 한다.
기존 nuscenes데이터셋에 대해서 MMDetection3D는 컨버팅 코드를 제공, 하지만 해당 컨버팅은 nuScenes에서 명시한 데이터타입, 파일구조, 파일형식을 갖기때문에
커스텀데이터셋에 대해서는 동일하게 사용할 수 없다.
따라서 커스텀 데이터셋 파일구조 와 형식에 대해 nuScenes의 pkl의 구조를 지키며
데이터를 파싱해서 밀어 넣을 필요가 있다.
.pkl 파일 생성 목적
원본 데이터(JSON, 이미지 파일 등)를 직접 로드하면 I/O 병목이 발생하고 로드 속도가 느려짐.
.pkl 파일은 전처리된 정보를 직렬화(Serialization)하여 저장한 파일로, 로드 속도가 빠르고 모델 학습에 필요한 정보를 효율적으로 제공. BEVFormer는 시간적 정보를 활용하므로, 시퀀스 데이터(연속된 프레임)를 .pkl 파일에 포함.
nuscenes_infos_temporal_train.pkl: 학습 데이터용.
nuscenes_infos_temporal_val.pkl: 검증/테스트 데이터용.
temporal은 시간적 정보를 포함한다는 의미.
nuscenes_infos_temporal_train.pkl 구조
create_data.py로 생성한 pkl 파일을 열람하면 아래와 같은 정보가 존재.
1.카메라 관련
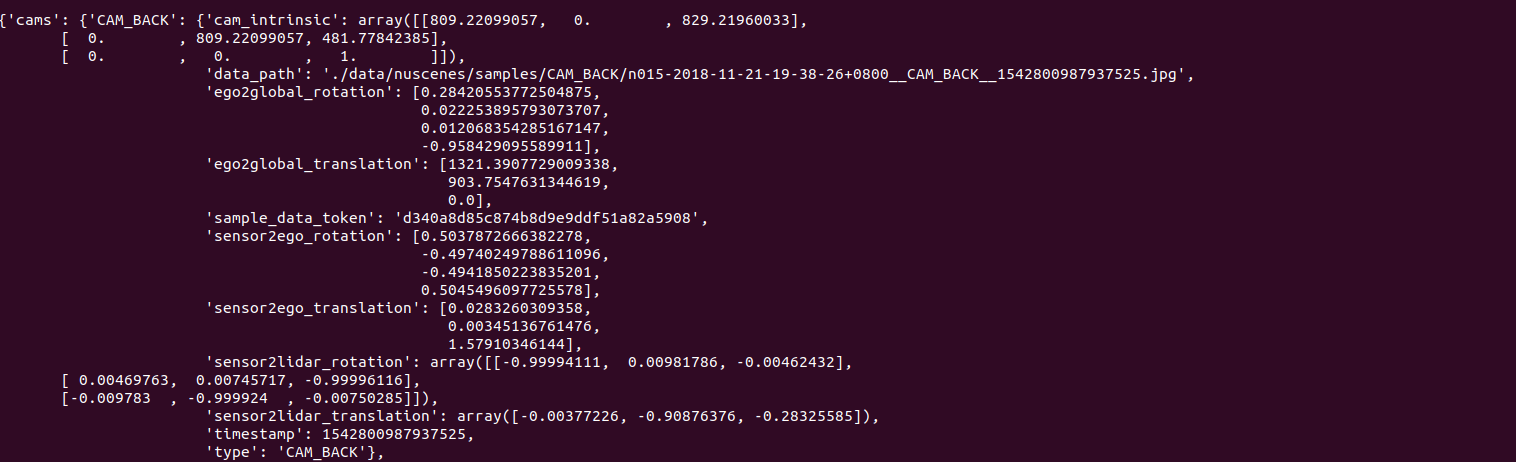
- 6개 카메라 뷰(CAM_FRONT, CAM_BACK 등)의 이미지 파일 경로.
- cam_intrinsic: 카메라 내부 파라미터(초점 거리, 주점 좌표 등)
- sensor2ego_rotation, sensor2ego_translation: 카메라에서 ego 좌표계로의 변환.
2.에고차량 관련
- CAN정보 : 차량의 위치 및 회전 정보 ex) [1476.24551, 1141.10456, ...]
- ego2global_rotation, ego2global_translation: ego에서 글로벌 좌표계로의 변환.

3.LiDAR 관련 (lidar_path, sweeps)
- lidar_path: 현재 프레임의 LiDAR 데이터 경로.
- lidar2ego_rotation, lidar2ego_translation: LiDAR에서 ego 좌표계로의 변환.

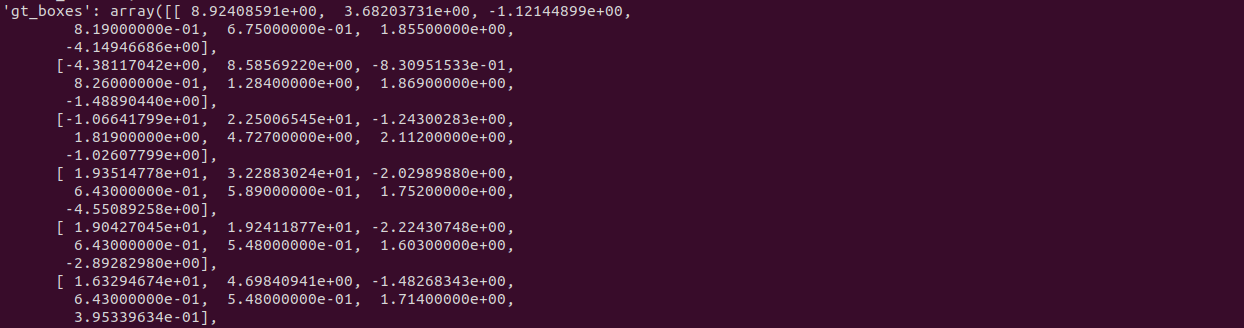
4.3D 바운딩 박스 (gt_boxes)
- 객체의 3D 좌표, 크기, 회전 각도. - LiDAR 좌표계 기준
- 형상: [x, y, z, l, w, h, ry]
5.클래스 라벨 (gt_names)
- 객체의 클래스 이름.

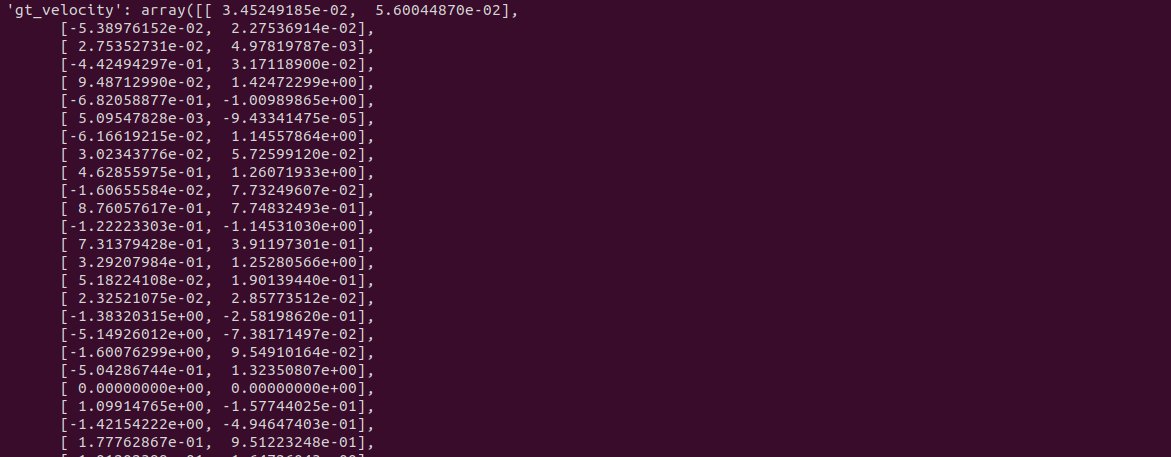
6.속도 정보 (gt_velocity)
- 객체의 2D 속도 ex) [0.136542361, 0.0715268405]
7.타임스탬프 및 시간적 정보
- timestamp: 현재 프레임의 타임스탬프 ex) 1542800864948320

- frame_idx: 시퀀스 내 프레임 인덱스 ex) 34

- prev, next: 이전/다음 프레임 토큰

- scene_token: 장면 토큰

8. LiDAR 포인트클라우드 및 RADAR 획득 수
- 객체 별 LiDAR 포인트클라우드 및 RADAR 획득 수

9.유효성 플래그 (valid_flag)
- 객체가 유효한지 여부 - 대게 num_lidar_pt를 통해 생성( 객체의 실제존재 여부를 라이다 포인클라우드 수로 검열)

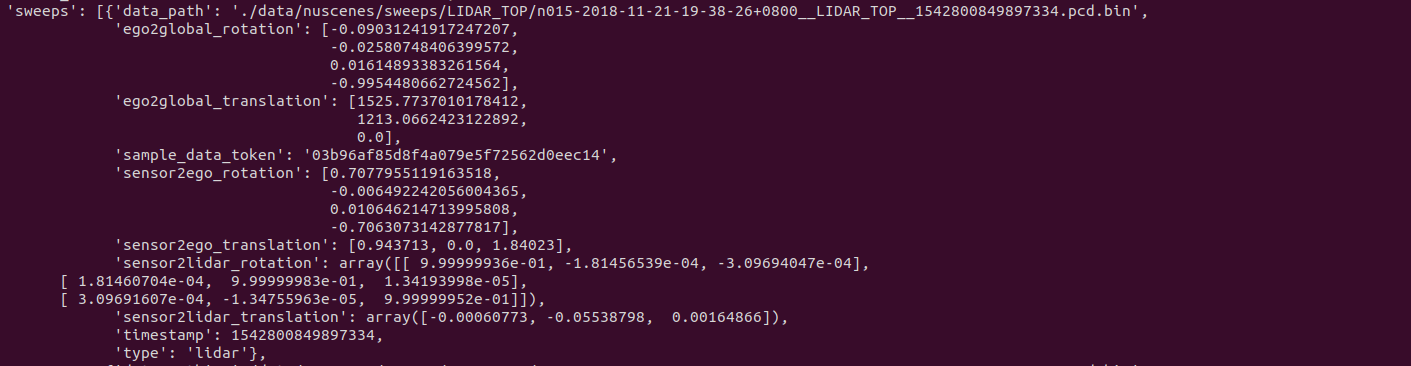
10. sweeps
- 특정 키프레임(Keyframe)에 대해 이전 시간대의 LiDAR 데이터
- nuScenes 데이터셋은 LiDAR 데이터를 키프레임(주요 샘플)과 스윕(이전 샘플)으로 나누어 관리
- 키프레임은 주기적으로 채취된 주요 데이터 포인트(예: 2Hz 주기)이고, 스윕은 그 사이의 연속적인 데이터 포인트(예: 20Hz 주기)
컨버팅 코드 생성 for 커스텀 데이터셋
앞서 설명한 것처럼 커스텀 데이터셋의 경우
기존 nuScenes 의 파일 구조(아래)가 아니다.

물론, 각 씬에 대한 디렉토리가 나눠져있고, 해당 씬에서 취득된 데이터 타입에 따른 디렉토리 분류는 되어있지만 '토큰'이라던가, '키프레임'이라던가 nuScenes의 매커니즘은 따르지않음. 따라서 먼저, 키프레임에 대해 데이터를 분류하고, 토큰을 부여하여 정렬하는 단계적인 과정이 필요.
아래는 컨버팅을 위해 커스텀데이터셋에 대한 단계적인 접근 과정이다.
1. 커스텀 데이터셋에 대한 데이터 취득 방법확인
2. 센서 내외재 파라미터, 센서 데이터 획득 주기확인
3. 씬에 대한 어노테이션 확인
4. map 정보 유뮤 확인
확인 후 맞닥뜨린 문제 및 해결방안
- 데이터 주기 불일치
nuScenes와 각 센서 데이터 획득 주기가 불일치함. 따라서 키프레임은 2Hz 주기(0.5초 간격)에 맞춰 LiDAR 데이터를 기준으로 각 센서데이터(CAN, cam, LiDAR)와 ego정보를 정렬해야함.
커스텀 데이터셋의 센서데이터들은 그 획득 시간에 대응하는 순차적인 숫자를 갖는 파일 이름을 형성, 따라서 파싱과정에서 각 센서데이터(CAN, cam, LiDAR)와 ego데이터파일 이름 순서 인덱스에 대해 for문으로 걸러내어 취합.
이를 통해 각 키 프레임을 형성 후, sample_data 토큰에 대해선 최상위디렉토리(씬순서) + 센서데이터취득시기 + 센서이름으로 생성하여 pkl에 입력
- CAN 정보의 부재

그래서 bevformer 돌리는거 성공하셨나요? 이거 mmdetection 이랑 paddle 밖에 없어서 골때리던데..