Project : BEVformer on Sim
1.Intro

BEVFormer 논문을 리뷰한 후, nuScenes 데이터셋을 기반으로 작성된 BEVFormer 공식 소스코드를 활용하여 Morai에서 제공된 데이터셋을 가공하고, 이를 통해 모델 학습과 실시간 추론 과정을 기록하고자 합니다. 이 시리즈의 목표는 향후 실세계 차량에
2.nuScenes 데이터셋 구조

본격적인 데이터셋 공부에 앞서 왜 데이터셋이 뭔지, 역할이 어떤건지, 어떻게 사용하는지 그 필요성을 생각해보았습니다. 만약 요리를 한다고 생각해보죠. 하나의 멋진 음식을 만들기 위해선 숙련된 요리사, 최고의 조리도구, 최상의 재료가 필요합니다. 이 이야기는 연구에서도
3.MMDetection3D 직관적으로 이해하기

본격적으로 BEVformer 소스코드를 뜯어보기전에, 먼저 MMDetection3D에 대해 알아봅시다.안그러면 처음 소스코드를 뜯어보았을때이게뭐지? 모델구조가 어디있지? 내가 뭘보고 있는거지?그냥 포기할란다..하는 반응이 나옵니다. 제가 그랬어요MMDetection3D
4.중간점검 : How to do

프로젝트의 목적을 이루기 위해 해결해야할 문제는 다음과 같습니다.'시뮬레이터에서 수집된 커스텀데이터셋(nuScenes형식에 맞지않는)을 어떻게 기존 bevformer학습과 검증과정에 이용할지'앞서 nuScenes와 MMDetection3D에 대해 알아보았습니다.이를 통
5.STEP 1: BEVformer 소스코드 뜯어보기
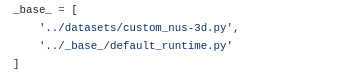
깃 주소: https://github.com/fundamentalvision/BEVFormer1) config 살펴보기base: 재사용모듈 정의, 기존 제공된 nus-3d.py에 대해 커스텀한 데이터셋 로드 모듈과 기존제공 런타임유형 설정을 명시model: 모
6.STEP 2 : 수정 부분 파악

목표커스텀데이터셋을 이용한 모델 학습차이점 파악nuscenes 데이터셋은 일관된 구조와 이러한 구조에 대해 많은 도구(데이터로드,검증 및 평가)를 지원하는 api 존재허나, 커스텀 데이터셋은 일관되지 않은 구조 + api존재 x해야할 일1) 기존 공식 소스코드에서 사용
7.STEP 3 : 학습과정에 대한 파악

tools/train.pyconfig 로드 (bevformer_base.py)데이터셋 빌드 build_dataset(cfg.data.train): cfg.data.train은 bevformer_base.py의 data.train 설정을 기반으로 데이터셋 인스턴스를 생성
8.STEP 4 : 커스텀 데이터셋 변환
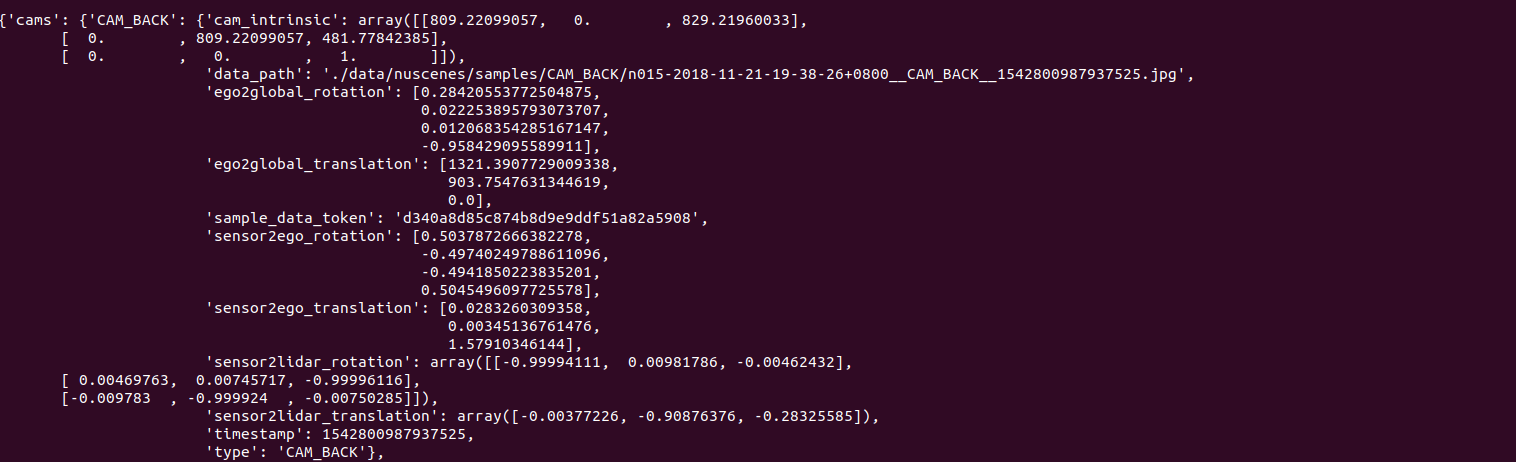
앞서 전반적인 학습은 nuscenes데이터셋에 대한 pkl파일로 진행따라서 먼저, nuscens_pkl의 구조를 파악하고, 커스텀 데이터셋이 이를 준수하도록 컨버팅 코드를 만들어야 함..pkl 파일 생성 목적원본 데이터(JSON, 이미지 파일 등)를 직접 로드하면 I/