
본격적인 데이터셋 공부에 앞서
데이터셋을 알아야 할 필요성에 대해 생각해보았습니다.
만약 요리를 한다고 생각해봅시다.
하나의 멋진 음식을 만들기 위해선 숙련된 요리사, 최고의 조리도구, 최상의 재료가 필요합니다.
이 이야기는 연구에서도 다를게 없다고 생각합니다.
숙련된 요리사는 연구자, 조리도구는 연구환경, 최상의 식재료는 데이터라고 비유할 수 있습니다.
이러한 것들이 갖춰졌을 때야 비로소, '기술'이라는 하나의 멋진 음식을 맛볼 수 있을 것입니다.
물론 '장인을 도구를 탓하지 않는다'라는 말도 있습니다.
하지만 장인이 과연 재료는 탓하지 않을까요?!
아무리 장인이라한들 어떠한 재료도 없이 빵과 음료를 만들어 낼 수는 없을 것입니다.
따라서 조리도구와 요리사에 대해선 잠시 뒤에 생각하고,
가장 먼저 재료에 대해서 살펴보도록 하죠.
nuScenes란?
nuScenes는 Aptiv(구 Nutonomy, 현 Motional)에서 개발한 오픈소스 자율주행 데이터셋으로, 자율주행 차량의 환경 인식(Perception)과 예측(Prediction) 연구를 지원하기 위해 2019년에 공개되었습니다. "nu"는 Nutonomy의 약자로, Scenes는 다양한 주행 장면을 의미합니다. KITTI나 Waymo데이터셋과 비교해 멀티모달 센서와 풍부한 어노테이션으로 주목받으며, 특히 360도 센서 커버리지와 시간적 연속성을 강조합니다.
https://www.nuscenes.org/nuscenes
주요특징
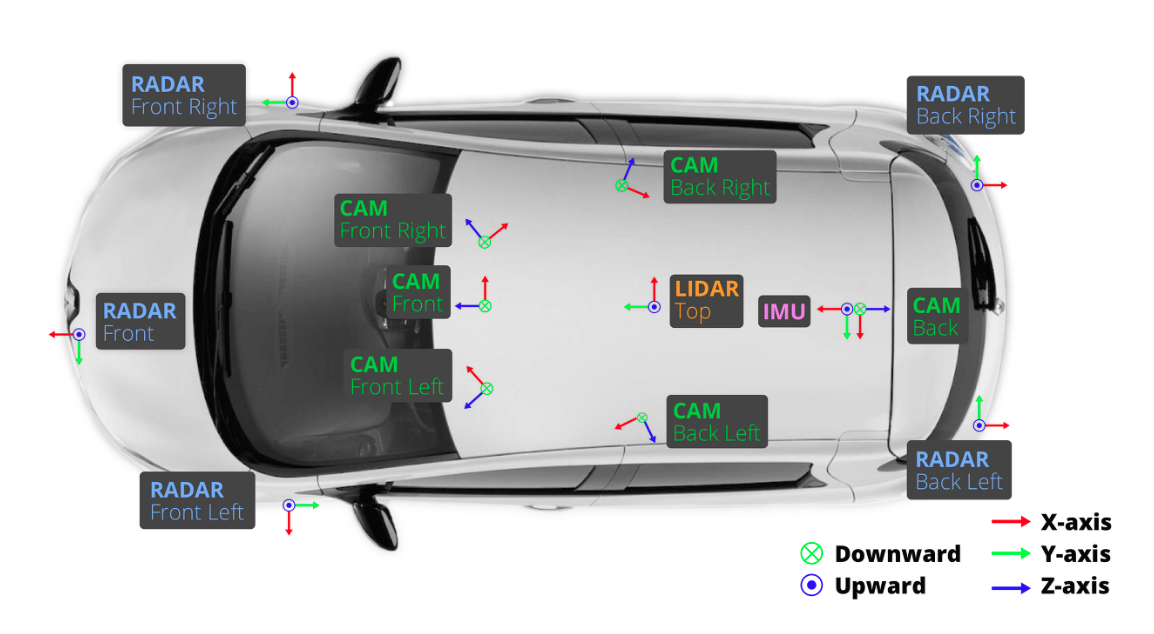
- 데이터 규모:
-1,000개 장면(Scenes), 각 장면은 20초 분량.
-약 40,000 키프레임 (2Hz 샘플링, 0.5초 간격).
-총 1.4M개의 3D 바운딩 박스 어노테이션.
-약 1.4TB (압축 해제 시).- 센서 구성:
-LiDAR: 1개 (32채널, 20Hz, 최대 70m 범위).
-카메라: 6개 (1600x900 해상도, 12Hz, 360도 뷰: 전방, 측면, 후방).
-레이더: 5개 (77GHz, 250m 범위, 13Hz).
-IMU/GPS: 차량 위치와 방향 제공.- 수집 환경:
-위치: 싱가포르와 보스턴 (도시 환경 중심).
-조건: 맑음, 비, 낮, 밤 등 다양한 날씨와 조명 포함.
-다양성: 보행자, 차량, 자전거 등 복잡한 교통 상황.- 어노테이션:
-23개 객체 클래스 (예: car, pedestrian, bicycle, traffic_cone 등).
-3D 박스 (translation, size, rotation).- 특이사항:
-가시성(visibility, 1~4), 상태(정지/이동) , 시간적 연속성(객체 추적을 위한 prev, next 토큰)에 대한 정보를 표현.
데이터셋을 활용해 모델의 성능을 정량화하고, 이를 통해 모델의 능력, 데이터셋의 난이도, 실세계 적용 가능성을 평가하는 과정은 주요합니다.
우리는 왜 nuScenes가 최근 자율주행 연구에서 채택되는지 그 소개와 특징을 통해 알 수 있습니다. 바로 '멀티모달 센서'와 '시간적 연속성' 때문입니다.
최근의 자율주행 연구는 transformer기반의 멀티모달 데이터를 처리하는 방식으로 E2E 아키텍쳐를 위한 센서퓨전 및 시계열데이터 처리에 대한 연구가 지속되고 있습니다.
때문에 인지모델과 E2E모델에 대한 연구에서 nuScenes는 매우 적합한 데이터셋으로 선택됩니다.
Keyframe과 token
nuscenes 데이터셋의 구조를 상세히 알아보기전, nuScenes의 핵심요소인 Keyframe에 대한 설명과 더불어 고유식별자인 token에 대한 선행개념이 필요합니다.
keyframe
- 키프레임은 nuScenes 데이터셋에서 수집주기가 서로 다른 각 센서들로 취득한 데이터들을 2Hz 간격(0.5초마다)의 동기화 시점으로 묶어둔 프레임(Frame)을 의미합니다.
- 키프레임은 동일주기(2Hz)로 동기화된 프레임들에 어노테이션을 함께 제공되며, 센서 데이터는 samples 디렉토리에, 어노테이션 JSON은 버전별 메타데이터 디렉토리에 저장됩니다.
- 키프레임에 속하지 못한 데이터들은 어노테이션이 없이 sweeps 디렉토리에 저장되며, "과거 프레임(Sweep)"으로도 활용됩니다.
- 각 키프레임은 LiDAR 데이터를 기준으로 정의되며, 해당 시점의 모든 센서 데이터(카메라, 레이더 등)가 동기화됩니다.
- 각 키프레임은 동기화된 각 센서 데이터(LiDAR, 카메라, 레이더)에 대해 nuScenes 고유 개념인 token을 부여받음으로써 데이터를 식별하고 연결관계를 파악가능합니다.
Token
- 토큰은 nuScenes 데이터셋에서 각 데이터 요소(샘플, 센서 데이터, 객체 등)를 고유하게 식별하는 문자열 ID입니다.

(아래는 sensor_token에 대한 예시)
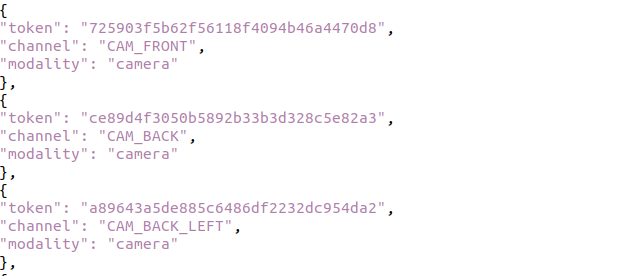
- 키프레임은 sample_token으로 식별되며, 이 토큰은 동기화된 센서 데이터(LiDAR, 카메라, 레이더)와 어노테이션을 연결합니다.
- Token 각 데이터 간 관계를 연결하며, nuscenes-devkit 같은 전용 API로 접근할 때 사용됩니다.
- 모든 토큰은 고유하며, 계층적 구조로 연결됩니다 (예: scene_token - sample_token - sample_data_token).
- 토큰들은 JSON 파일(/v1.0-{version}/)에서 정의되며, 데이터베이스처럼 각 토큰들은 서로 유기적으로 동작합니다.
Token의 계층적 구조
앞서 토큰들은 계층적인 구조로 연결된다고 했습니다.
아래는 nuScenes 공식문서에 나와있는 토큰의 schema 입니다.
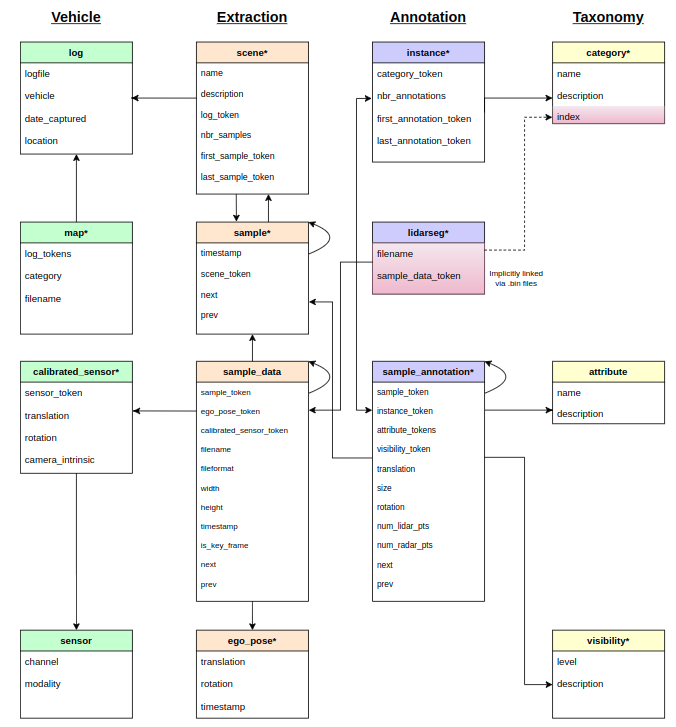
간단하게 설명하자면
log가 가장 상위 토큰으로 각 씬들을 명시하고,
scene은 특정 씬에 대한 첫 프레임과 마지막 프레임을 나타내며,
sample은 각 키 프레임의 시간 순서를 나타내며
sample_data는 해당 프레임 마다를 구성하는 센서데이터와 어노테이션들을 연결합니다.
각 토큰들이 서로 어떻게 연결되는지, 상호작용하는지는
아래 정말 잘 설명된 블로그가 있으니 궁금하시다면 꼭 한번 방문하셔서 보시길 바랍니다.
https://shyun.tistory.com/23
nuScenes 데이터셋 구조
전반적인 파일구조는 다음과 같습니다.
nuscenes/
├── v1.0-{version}/ 메타데이터와 어노테이션
├── samples/ 키프레임 센서 데이터
├── sweeps/ 키프레임이 아닌 센서 데이터 (Sweep)
├── maps/ HD 맵
*메타데이터란? 데이터에 대한 데이터(Data about Data)로, 센서 데이터의 맥락과 구조를 설명하는 정보로, nuScenes에서는 센서 데이터(LiDAR, 카메라 등)의 생성 조건, 관계, 설정을 정의합니다.
*어노테이션? 센서 데이터에 부여된 정답 레이블(Ground Truth)로, 주로 객체 정보(위치, 크기 등)를 포함.
이제 세부적으로 각 디렉토리에 대해 살펴볼까요?
nuScenes/v1.0-{version}
- 역할 : 키프레임(sample)에 대한 어노테이션과 메타데이터(데이터셋의 계층적 구조와 관계)에 대한 json파일들이 존재하여, 센서 데이터(samples/, sweeps/)를 해석하는 데 필요한 정보를 제공합니다.
*여기서 {version}은 mini 또는 trainval으로 데이터셋 버전에 따라 달라짐- 구성 : JSON 파일들로 이루어져 있으며, 총 12개의 JSON 파일이 포함되며, 각 파일은 고유한 역할과 데이터를 갖습니다.
아래는 위 폴더를 구성하는 각 .json파일에 대한 설명입니다.
/v1.0-{version}/map.json
: 데이터가 취득된 장소(map)을 나타냅니다. HD 맵 데이터와의 연결 정보를 저장하고, maps/의 맵 파일을 데이터셋과 연결합니다.

token: 맵 고유 식별자.
filename: 맵 파일 경로 (예: maps/basemap-1234.png).
log_token: 맵이 속한 로그 참조.
/v1.0-{version}/log.json
: 데이터 수집 로그(주행 기록) 정보를 저장. 데이터 수집의 맥락을 제공.
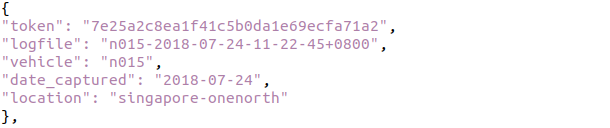
token: 로그 고유 식별자.
logfile: 로그 파일 이름.
vehicle: 차량 이름.
date_captured: 수집 날짜.
location: 수집 장소 (예: "singapore").
/v1.0-{version}/scene.json
: 시퀀스(20초 주행 장면) 단위의 메타데이터를 저장합니다.

token: 시퀀스 고유 식별자.
log_token: 데이터 수집 로그 참조.
nbr_samples: 시퀀스 내 샘플 수.
first_sample_token: 첫 샘플 토큰.
last_sample_token: 마지막 샘플 토큰.
의미: 전체 주행 시퀀스의 개요를 제공.
/v1.0-{version}/sample.json
: 데이터셋의 키프레임(Sample)을 정의하는 메타데이터 파일입니다. 키프레임은 2Hz 간격(0.5초마다)으로 샘플링된 특정 시점의 데이터입니다. 시간적 연속성을 나타내며, samples/의 센서 데이터(LiDAR, 카메라 등)를 특정 시점과 연결합니다.

token: 샘플의 고유 식별자.
timestamp: 데이터 수집 시각 (마이크로초 단위). sample_token과 대응하는 timestamp
prev: 이전 샘플 토큰 (첫 샘플이면 빈 문자열).
next: 다음 샘플 토큰 (마지막이면 빈 문자열).
scene_token: 이 샘플이 속한 상위 시퀀스(Scene)의 토큰.
/v1.0-{version}/sample_data.json
: 개별 센서 데이터(LiDAR, 카메라, 레이더)의 파일 경로와 메타데이터를 저장합니다.
samples/와 sweeps/의 실제 파일을 샘플과 연결해줍니다.

token: 센서 데이터의 고유 식별자.
sample_token: 이 데이터가 속한 상위 샘플의 토큰.
filename: 센서 데이터 파일 경로 (예: samples/LIDAR_TOP/xxx.pcd.bin).
timestamp: 수집 시각.
calibrated_sensor_token: 센서 캘리브레이션 참조.
/v1.0-{version}/sample_annotation.json
: 3D 객체에 대한 어노테이션(정답 레이블)을 저장. 모델이 학습할 객체의 위치, 크기, 방향 등 정답 데이터를 제공.

token: 어노테이션 고유 식별자.
sample_token: 이 어노테이션이 속한 샘플의 토큰.
instance_token : 객체 인스턴스의 고유 식별자, 동일 객체가 여러 키프레임에 걸쳐 나타날 경우, 시간적 연속성을 추적하기 위해 사용. category_token을 통해 객체의 카테고리 정보와 연결
visibility_token: 가시성 등급 식별자 (1~4).
attribute_token : 객체 움직임 정보 식별자(moving, stopped, parked, ...)
translation: 객체 중심 위치 [x, y, z] (글로벌 좌표계, 미터).
size: 객체 크기 width, length, height.
rotation: 객체 방향 (쿼터니언 [w, x, y, z]).
category_token: 객체 클래스 식별자(예: "vehicle.car").
prev, next: 시간적 연속성 토큰.
num_lidar_pts: LiDAR 포인트 수.
num_radar_pts: radar 포인트 수.
/v1.0-{version}/ego_pose.json
: 자율주행 차량(Ego Vehicle)의 위치와 방향 정보를 저장. IMU/GPS 데이터를 기반으로 차량의 글로벌 위치를 제공.
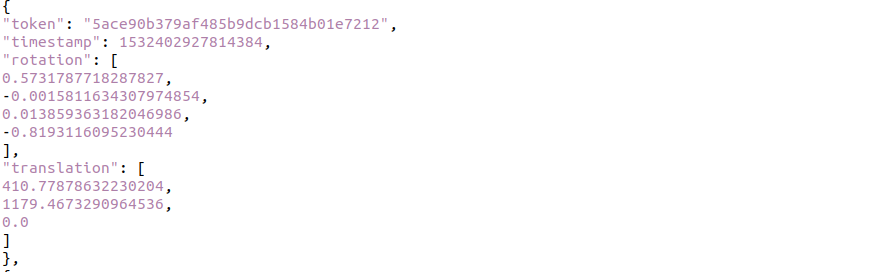
token: 에고 정보 고유 식별자.
translation: 차량 위치 [x, y, z] (글로벌 좌표계).
rotation: 차량 방향 (쿼터니언 [w, x, y, z]).
timestamp: 수집 시각.
/v1.0-{version}/calibrated_sensor.json
:센서의 캘리브레이션 정보를 저장. 센서 간 좌표 변환(Extrinsic)을 정의해 데이터 통합 가능.
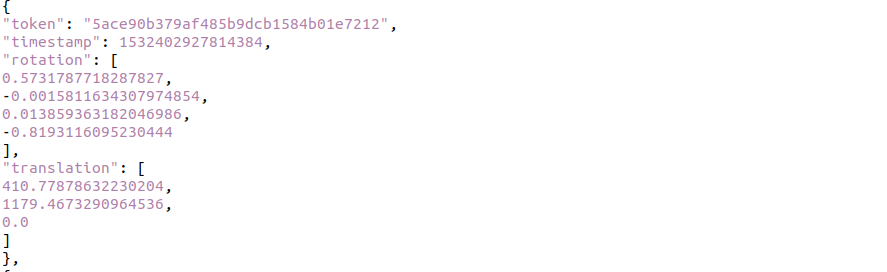
token: 센서 고유 식별자.
sensor_token: 센서 유형 (예: "LIDAR_TOP").
translation: 센서의 차량 내 위치 [x, y, z].
rotation: 센서 방향 (쿼터니언 [w, x, y, z]).
/v1.0-{version}/category.json
: 객체 클래스의 정의를 저장. 어노테이션에서 사용하는 클래스 목록 제공.

token: 클래스 고유 식별자.
name: 클래스 이름 (예: "vehicle.car").
description: 클래스 설명.
/v1.0-{version}/attribute.json
: 객체의 속성(상태)을 정의. sample_annotation.json의 속성(예: 정지/이동)을 보완.

token: 속성 고유 식별자.
name: 속성 이름 (예: "vehicle.moving", "vehicle.stopped").
description: 속성 설명.
/v1.0-{version}/instance.json
: 객체 인스턴스(시간을 초월한 개별 객체)를 정의합니다. 동일 객체를 여러 샘플에서 추적.

token: 인스턴스 고유 식별자.
category_token: 클래스 참조.
first_annotation_token: 첫 어노테이션 참조.
last_annotation_token: 마지막 어노테이션 참조.
/v1.0-{version}/visibility.json
: 객체의 가시성 등급을 정의. sample_annotation.json의 visibility_token을 해석.

token: 가시성 고유 식별자.
level: 가시성 등급 (1~4: 0-40%, 40-60%, 60-80%, 80-100%).
description: 등급 설명.
nuScenes/samples
- 역할: 키프레임(Keyframe) 센서 데이터를 저장합니다. 키프레임은 데이터셋에서 어노테이션(Annotation)이 제공되는 특정 시점의 데이터를 의미하며, 주로 분석 및 학습에 사용됩니다. 이 디렉토리는 nuScenes 데이터셋의 핵심 데이터로, LiDAR, 카메라, 레이더 등 다양한 센서에서 수집된 데이터를 포함합니다.
- 구성: 센서별로 하위 디렉토리로 나뉘며, 각 파일은 특정 센서에서 특정 시점(샘플)에 수집된 데이터를 나타냅니다. 파일 이름은 고유한 토큰(Token)을 기반으로 생성됩니다.
- 세부구성
-하위 디렉토리

-파일 형식
카메라: .jpg (이미지 파일)
LiDAR: .pcd.bin (바이너리 포인트 클라우드 파일)
레이더: .pcd.bin (포인트 클라우드 형식으로 저장)
각 파일은 특정 시점의 센서 데이터를 나타내며, v1.0-{version}/sample.json 파일과 연결되어 해당 샘플의 메타데이터(위치, 타임스탬프 등)를 제공합니다.
ex) CAM_FRONT/sample-abc123.jpg는 sample.json에서 token: abc123에 해당하는 키프레임의 전방 카메라 이미지입니다.
nuScenes/sweep
- 역할: 키프레임이 아닌 센서 데이터(Sweep)를 저장합니다. Sweep은 키프레임 사이의 중간 시점 데이터를 의미하며, 주로 연속적인 센서 데이터를 제공하여 시간적 흐름을 분석하거나 보간(Interpolation)에 활용됩니다. 단, Sweep 데이터에는 어노테이션이 제공되지 않습니다.
- 구성: samples와 유사하게 센서별 하위 디렉토리로 나뉘며, 파일 이름은 Sweep 데이터임을 나타내는 고유한 토큰과 타임스탬프를 기반으로 생성됩니다.
- 세부구성
-하위 디렉토리
-파일형식 : samples와 동일
nuScenes/maps
- 역할: HD 맵(High-Definition Map) 데이터를 저장합니다. 이 디렉토리는 데이터셋에서 수집된 주행 환경의 지리적 맥락을 제공하며, 자율주행 연구에서 차량의 위치 추정(Localization), 경로 계획(Path Planning), 환경 이해(Scene Understanding) 등에 활용됩니다. HD 맵은 도로 구조, 차선, 교차로, 신호등 등의 정보를 포함하고 있어 센서 데이터와 결합하여 정밀한 분석을 가능하게 합니다.
- 구성: 맵 데이터는 주로 이미지 파일(예: .png) 또는 벡터화된 데이터로 제공되며, 각 파일은 특정 지역의 맵을 나타냅니다. 이 데이터는 v1.0-{version}/map.json 파일과 연결되어 메타데이터(맵 식별자, 로그 참조 등)를 제공받습니다.
-
세부구성
-파일형식 : .png, .json
-도로 구조 : 차선(Lane), 교차로(Intersection), 도로 경계(Road Boundary) 등.
-고정 객체 : 신호등, 표지판, 건널목 등의 위치.
-지리적 참조 : 맵은 실제 좌표계(예: UTM 좌표)와 매핑되어 센서 데이터와 정렬(Alignment) 가능. -
v1.0-{version}/map.json 과의 연결성
-map.json 파일은 각 맵 파일에 대한 메타데이터를 제공합니다. 이를 통해 특정 주행 시퀀스(scene.json)와 맵 데이터를 연결할 수 있습니다. -
v1.0-{version}/log.json 과의 연결성
-log.json의 location 필드(예: "singapore" 또는 "boston")를 통해 해당 맵과 로그가 연결됨을 알 수 있습니다.
여기까지 nuScenes에서 기본으로 제공되는 데이터셋에 대한 구조와 각 용어 및 개념에 대한 설명이었습니다.
nuScenes는 위의 기본 데이터셋 말고도 다양한 확장(extension)팩을 지원하는데요. 이를 nuScenes 데이터셋은 기본 데이터셋 외에도 연구와 자율주행 기술 개발을 더욱 풍부하게 지원하기 위해 여러 확장팩(Expansion Packs)을 제공합니다. 이 확장팩들은 기본 데이터셋에 추가적인 데이터나 기능을 제공하며, 특정 작업(예: 경로 예측, LiDAR 세그멘테이션, 차량 동역학 분석 등)에 특화되어 있습니다. 아래에서 주요 확장팩들을 설명드리겠습니다.
Map Expansion (맵 확장팩)
- 파일위치 : /data/sets/nuscenes/maps
- 역할 : 기본 데이터셋의 maps/ 디렉토리를 확장하여 더 풍부한 HD 맵(High-Definition Map) 데이터를 제공합니다. 이 확장팩은 자율주행 차량의 내비게이션, 경로 계획, 환경 이해를 개선하기 위해 설계되었습니다.
- 구성 : 기본 maps/ 디렉토리의 정적 맵 데이터를 보완하여 더 세밀한 도로 네트워크와 환경 정보를 제공합니다.
- 세부구성
-하위 디렉토리

-파일형식 : 비트맵(.png) 또는 벡터 데이터로 제공되며, NuScenesMap 클래스를 통해 시각화 및 쿼리가 가능
CAN Bus Expansion (CAN 버스 확장팩)
파일위치: /data/sets/nuscenes/can_bus
역할: 차량의 저수준 동역학 및 상태 데이터를 제공하여 센서 데이터와 결합해 차량 움직임과 제어 상태를 분석할 수 있게 합니다.
구성
-IMU: 가속도, 각속도 등 관성 측정 데이터.
-Pose: 차량의 위치 및 방향(로컬라이제이션 데이터와 별도).
-Steering Angle: 조향각 피드백.
-Wheel Speeds: 바퀴 속도.
-Throttle/Brake: 가속 및 제동 상태.
-Gear Position: 기어 상태.
-Signals: 방향 지시등 상태.
-Odometry: 주행 거리 데이터.
-Torque, Battery: 엔진 토크 및 배터리 상태(차량 모델에 따라 다름).
-
세부구성
-파일형식: JSON 또는 바이너리 형식으로 제공. -
센서 데이터와의 동기화
-samples/, sweeps/디렉토리 내부 센서데이터와 동기화를 통해 차량의 물리적 상태와 운전자 입력을 상세히 분석 가능
nuScenes-Lidarseg (LiDAR 세그멘테이션 확장팩)
- 위치: /v1.0-{version}/lidarseg
- 역할: LiDAR 포인트 클라우드에 세부적인 의미론적 레이블(Semantic Labels)을 추가하여 포인트 단위의 환경 이해를 지원합니다.
- 구성: 40,000개의 키프레임 LiDAR 포인트 클라우드에 14억 개의 포인트가 주석 처리됨.
32개의 의미론적 클래스(예: 차량, 보행자, 도로, 건물, 식생 등).
-
세부구성
-파일형식: .bin -
센서데이터와의 동기화
-각 파일은 sample_data_token으로 기본 데이터셋의 LiDAR 데이터와 연결
이렇게 nuScenes 기본데이터셋과 확장팩들, 그리고 세부적인 데이터구조에 대해 알아보았습니다. 이제 nuScenes 데이터셋의 구조를 이해했으니, 이 데이터를 실제 연구에 어떻게 활용하는지 BEVformer에서 사용된 핵심 라이브러리인 mmdetection3D에 대해 살펴보도록 하겠습니다.
다음포스팅은 MMDetection3D에 대한 설명과 BEVformer의 공식 소스코드와 함께 찾아뵈겠습니다.
