
01. 퀵 정렬 개념
1) 퀵 정렬 과정
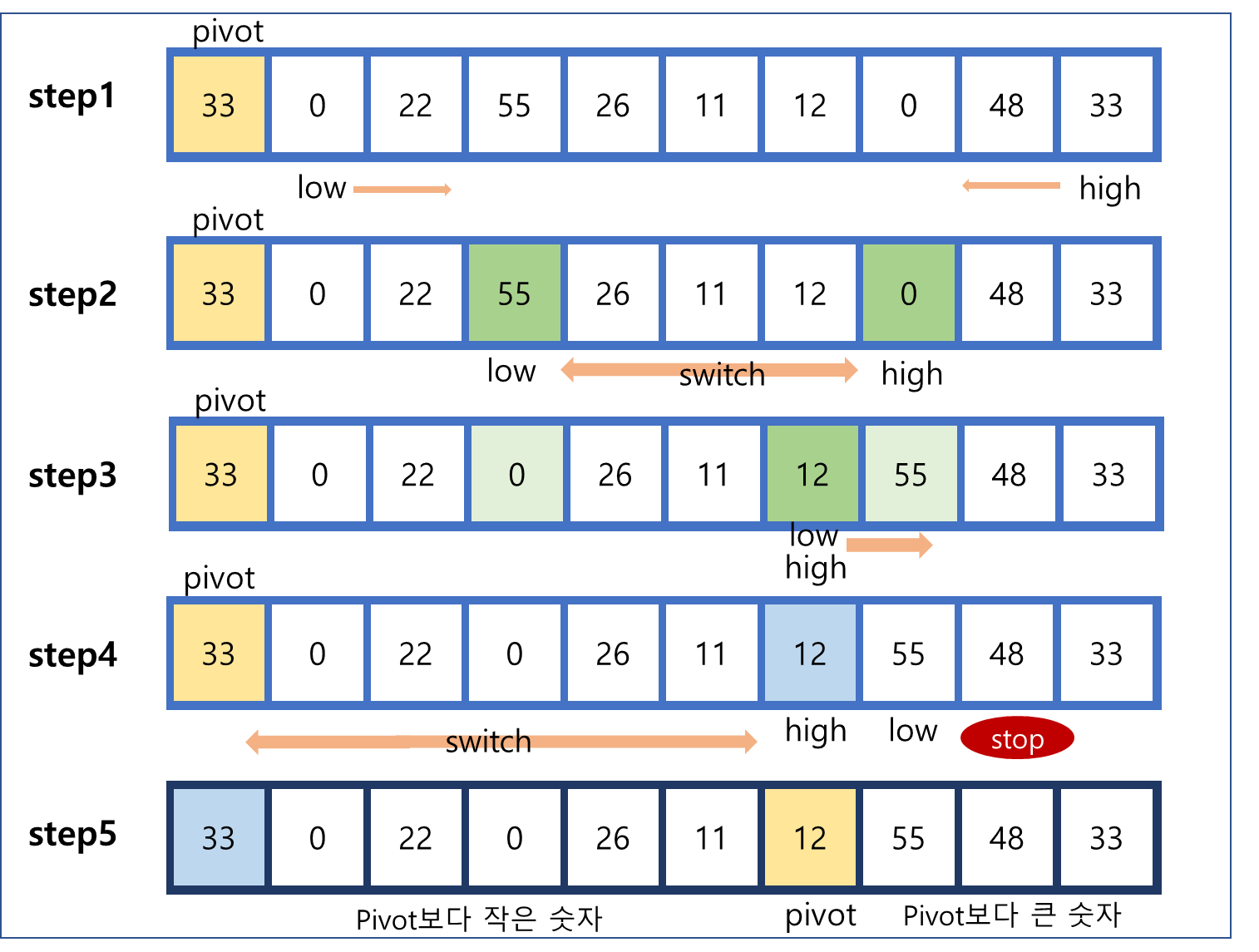
-
step1 : pivot의 위치를 선정(그림에서는 맨 왼쪽)
-
step2 : low는 pivot보다 큰 숫자가 나올 때까지 오른쪽으로 이동하고, high는 pivot보다 작은 숫자가 나올 때까지 왼쪽으로 이동한다.
-
step3 : low와 high pointer가 멈추면 서로 교환해준다. low와 high pointer를 다시 이동시켜 준다.
-
step4 : low와 high가 엇갈릴 때까지 같은 조건으로 low와 high pointer를 이동한다.
-
step5 : pointer의 이동을 멈추고 pivot과 high를 교환한다.
-
step6 : pivot을 기준으로 왼쪽에는 작은 숫자들, 오른쪽에는 큰 숫자들이 위치하며 나눠진다. 현재의 pivot에 해당하는 숫자는 자리가 고정된다.
-
step7 : 이후에는 왼쪽 숫자들과 오른쪽 숫자들의 pivot을 선정하여 재귀적으로 step1~6를 반복한다.
2) 퀵 정렬 개념
- 분할(Divide) : 입력 배열을 pivot을 기준으로 비균등하게 2개의 부분 리스트로 분할한다.
- pivot의 왼쪽에는 pivot보다 작은 숫자 배열, 오른쪽에는 pivot보다 큰 숫자 배열이 위치한다.
- 정복(Conquer) : 부분 배열을 quick sort를 재귀적으로 사용해 정렬한다.
- 재귀적으로 quick sort를 사용하는 과정에서 divide가 된다.
02. 퀵 정렬 코드(Python)🔍
# 💡퀵 정렬
# 2. 분할해서 pivot 기준으로 pivot보다 작은 것은 왼쪽으로, pivot보다 큰 것은 오른쪽으로 넣기
def partition(start, end):
# 2-1. pivot 지정 - 왼쪽 끝으로 지정
pivot = quick_nums[start]
low = start + 1
high = end
# 2-2. low high 엇갈릴 때까지 반복
while True: # low와 high가 엇갈려 있지 않고,
while low <= high and quick_nums[low] <= pivot: # 각 세부 반복문을 돌면서 low는 pivot보다 큰 수가 나올 때까지 오른쪽으로 이동
low += 1
while low <= high and quick_nums[high] >= pivot: # high는 pivot보다 작은 수가 나올 때까지 왼쪽으로 이동
high -= 1
# 📌 low == high 이유: 엇갈리는 순간을 만들기 위해,
# 📌 quick_nums[low] == pivot 허용한 이유: pivot과 동일한 것들이, low, high로 의미없이 서로 교환되는 것을 막기 위해
# 2-3. 세부 while 문이 멈추고, 엇갈려 있다면 바깥 while을 빠져 나오고
if low > high:
break
# 엇갈려 있지 않으면 low와 high를 서로 교환해준다. -> 엇갈린 상황에서 low high를 교환해주면 정렬을 한 것들이 망가진다.(10 22 -> 22 10)
else:
quick_nums[low], quick_nums[high] = quick_nums[high], quick_nums[low]
# 2-4. 엇갈린 상태에서 pivot 값과 high 값을 교환(엇갈려 있으므로 high가 low보다 작다 -> high를 pivot과 바꾼다.)
quick_nums[start], quick_nums[high] = quick_nums[high], quick_nums[start]
# 2-5. 새로운 pivot의 위치를 반환 -> 이 숫자의 위치는 영구적으로 고정
return high
# 1. start와 end 사이를 정렬하기
def quick_sort(start, end):
# 1-1. start와 end가 엇갈리지 않을 때 sort 가능
# start와 end가 같아도 되지만 어차피 partition 후에 pivot = start = end이 되므로 그 아래 코드에서 걸러진다.)
if start < end:
pivot = partition(start, end)
quick_sort(start, pivot-1) # pivot보다 작은 것들을 sort,
quick_sort(pivot+1, end) # pivot보다 큰 것들을 sort
quick_nums = [0, 55, 22, 33, 2, 1, 10, 26, 42]
quick_sort(0, len(quick_nums)-1)
print(quick_nums) # [0, 1, 2, 10, 22, 26, 33, 42, 55]- pivot을 기준으로 왼쪽 부분 리스트와 오른쪽 부분 리스트를 재귀적으로 quick sort하면서 각각의 pivot들을 고정시켜준다.
03. 퀵 정렬 시간복잡도⏱
1) 최선의 시간복잡도 : O(nlogn)
-
각 순환 호출 전 단계에서의 비교 연산(평균): n
- pivot을 기준으로 왼쪽 오른쪽을 나누어 각각을 quick sort로 순환 호출하기 전에 비교 연산을 통해 pivot의 위치를 지정하는 연산
-
순환 호출 : logn
- merge sort처럼 쪼갤 때마다 두 부분으로 나눌 수 있으면 재귀의 깊이는 logn이다.(최적의 상황)
- T(n) = n + 2T(n/2)
- n : 재귀 전에 pivot 선정해서 왼쪽 오른쪽 나누기
- 2T(n/2) : 왼쪽, 오른쪽 두 부분 리스트에서 quick sort 호출하기
- T(n) = O(nlogn)
2) 최악의 시간복잡도 : O(n^2)
-
이미 정렬된 형태에서 최악의 시간 복잡도를 갖는다.
-
정렬을 진행하면, pivot이 한 쪽 끝으로 쏠리게 되서 두 부분 리스트를 나눌 수가 없다.
- 순환 호출이 각 단계마다 한번씩만 일어난다. 순환 호출 단계는 n이 된다.
- 호출 전, 각 숫자들을 pivot과 비교하는 연산은 평균적으로 n이다.
-
순환 호출 단계 * 호출 전 단계에서의 비교 연산 : O(n^2)
-
결국 퀵 정렬의 최악의 시간복잡도는 버블 정렬과 비슷한 원리다.
04. 퀵 정렬 특징❗
-
분할 정복 알고리즘의 한 종류
- 분할 정복이란 문제를 작은 2개의 문제로 분리하고, 각각을 해결한 다음, 그 결과를 모아서 원래의 문제를 해결하는 전략
- merge sort와는 다르게 불균형 분할이다.
-
pivot을 선정하는 방법에 따라 속도가 달라진다.
-
이미 정렬되어 있거나, 역순으로 정렬되어 있는 배열에서는 O(n^2)로 매우 느리다.
-
배열 안에서 교환이 일어나므로 merge sort와는 달리 추가 메모리를 필요로 하지 않는다.
-
시간 복잡도가 O(nlogn)을 가지는 다른 정렬 알고리즘(merge sort, heat sort)와 비교했을 때, 가장 빠르다.
- 한번 결정된 pivot들은 고정되어 다음 연산에 포함되지 않기 때문이다.
