13장
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/sonar3.csv', header=None)
df.head(5) # 0~4까지의 sample확인WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\losses.py:2976: The name tf.losses.sparse_softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.sparse_softmax_cross_entropy instead.
fatal: destination path 'data' already exists and is not an empty directory.| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0200 | 0.0371 | 0.0428 | 0.0207 | 0.0954 | 0.0986 | 0.1539 | 0.1601 | 0.3109 | 0.2111 | ... | 0.0027 | 0.0065 | 0.0159 | 0.0072 | 0.0167 | 0.0180 | 0.0084 | 0.0090 | 0.0032 | 0 |
| 1 | 0.0453 | 0.0523 | 0.0843 | 0.0689 | 0.1183 | 0.2583 | 0.2156 | 0.3481 | 0.3337 | 0.2872 | ... | 0.0084 | 0.0089 | 0.0048 | 0.0094 | 0.0191 | 0.0140 | 0.0049 | 0.0052 | 0.0044 | 0 |
| 2 | 0.0262 | 0.0582 | 0.1099 | 0.1083 | 0.0974 | 0.2280 | 0.2431 | 0.3771 | 0.5598 | 0.6194 | ... | 0.0232 | 0.0166 | 0.0095 | 0.0180 | 0.0244 | 0.0316 | 0.0164 | 0.0095 | 0.0078 | 0 |
| 3 | 0.0100 | 0.0171 | 0.0623 | 0.0205 | 0.0205 | 0.0368 | 0.1098 | 0.1276 | 0.0598 | 0.1264 | ... | 0.0121 | 0.0036 | 0.0150 | 0.0085 | 0.0073 | 0.0050 | 0.0044 | 0.0040 | 0.0117 | 0 |
| 4 | 0.0762 | 0.0666 | 0.0481 | 0.0394 | 0.0590 | 0.0649 | 0.1209 | 0.2467 | 0.3564 | 0.4459 | ... | 0.0031 | 0.0054 | 0.0105 | 0.0110 | 0.0015 | 0.0072 | 0.0048 | 0.0107 | 0.0094 | 0 |
5 rows × 61 columns
0~59열: 음파 주파수의 에너지를 0에서 1사이의 숫자로 표시
60열: 광물의 종류를 나타냄 (일반 암석: 0 ,광석: 1)
print(df[60].value_counts()) # 60열(클래스)에서 항목이 각각 몇개씩 포함되어있는지?
일반_암석_갯수 = df[60].value_counts()[0]
광석_갯수 = df[60].value_counts()[1]
전체_갯수 = df.shape[0]
print(f'일반 암석 갯수: {일반_암석_갯수} 광석 갯수: {광석_갯수} 전체 갯수: {전체_갯수}')60
1 111
0 97
Name: count, dtype: int64
일반 암석 갯수: 97 광석 갯수: 111 전체 갯수: 208광석이 111개, 일반 암석이 97개 있음
# df.iloc: DataFrame에서 필요한 row, column만 불러오기 위한 pandas 문법
X = df.iloc[:,0:60] # 0~59열 (속성)
y = df.iloc[:,60] # 60열 (광물의 종류)model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 이항분류이므로 sigmoid
model.summary()WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\backend.py:873: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 24) 1464
dense_1 (Dense) (None, 10) 250
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 1725 (6.74 KB)
Trainable params: 1725 (6.74 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, y, epochs=200, batch_size=10)WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\optimizers\__init__.py:309: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
Epoch 1/200
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\base_layer_utils.py:384: The name tf.executing_eagerly_outside_functions is deprecated. Please use tf.compat.v1.executing_eagerly_outside_functions instead.
21/21 [==============================] - 2s 3ms/step - loss: 0.6928 - accuracy: 0.5385
Epoch 2/200
...
Epoch 200/200
21/21 [==============================] - 0s 2ms/step - loss: 0.0211 - accuracy: 1.0000과적합이란?
학습이 반복될수록 학습이 깊어져 학습셋 내부에서 성공률이 높아지지만
학습에 사용하지 않은 테스트셋에서는 효과가 없다는 문제
과거의 데이터를 토대로 새로운 데이터를 예측하는것이 목적이므로 과적합 방지는 중요
과적합 방지 방법
학습할 데이터셋: Training set
학습을 진행하면서 테스트할 데이터셋: Test set
학습과 동시에 테스트를 병행하며 진행, 학습을 진행하면서
테스트 결과가 더 이상 좋아지지 않는 지점에서 학습을 멈추는것이 필요
X = df.iloc[:,0:60] # 0~59열 (속성)
y = df.iloc[:,60] # 60열 (광물의 종류)# train_test_split: 저장된 X 데이터와 y 데이터에서 각각 정해진 비율(%)만큼
# 학습셋과 테스트셋으로 분리시키는 함수
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
# 테스트셋을 30%으로 설정# 모델 설정
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 실행
history = model.fit(X_train, y_train, epochs=200, batch_size=10)Epoch 1/200
15/15 [==============================] - 1s 3ms/step - loss: 0.6982 - accuracy: 0.5379
...
Epoch 200/200
15/15 [==============================] - 0s 2ms/step - loss: 0.0188 - accuracy: 1.0000학습셋으로 테스트한 결과
Epoch 200/200
15/15 [==============================] - 0s 2ms/step - loss: 0.0142 - accuracy: 1.0000
# model.evaluate: 만들어진 모델을 테스트셋으로 테스트해보는 함수
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])2/2 [==============================] - 0s 5ms/step - loss: 0.6969 - accuracy: 0.8254
Test accuracy: 0.8253968358039856테스트셋으로 테스트한 결과
2/2 [==============================] - 0s 5ms/step - loss: 0.7373 - accuracy: 0.7778
Test accuracy: 0.7777777910232544
학습셋으로 테스트한건 정확도가 1이지만 테스트셋으로 테스트한것은 0.78밖에 안나옴
-> 과적합 되었다는것을 알 수 있음
모델 저장 방법
# 모델 저장
model.save('./data/model/my_model.hdf5')
# model 변수 초기화
del model
try:
print(model)
except NameError:
print("model 초기화 성공")model 초기화 성공
c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(# 모델 불러오기
model = load_model('./data/model/my_model.hdf5')
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])2/2 [==============================] - 0s 5ms/step - loss: 0.6969 - accuracy: 0.8254
Test accuracy: 0.8253968358039856K겹 교차 검증 (k-fold cross validation)
데이터수가 부족한 상황에선 test set까지 학습에 사용해야할 필요가 생김
이때 K겹 교차 검증 (k-fold cross validation)을 사용함
하는 방법: 데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용 나머지를 모두 학습셋으로 사용
# KFold(): 데이터를 원하는 수만큼 나누어 하나는 test set 나머지는 training set으로 사용하게 해주는 함수
k = 5 # 몇개의 파일로 나눌건지
kfold = KFold(n_splits=k, shuffle=True) # KFold함수를 불러옴
acc_score = [] # 정확도가 채워질 acc_score 배열
# 5개로 X(각 샘플마다의 속성이 담긴 data)가 spilit # spilit된 행(샘플)의 index가
for train_index, test_index in kfold.split(X): # 좌변의 train_index, test_index에 저장됨
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:] # 해당 index(행)에 해당하는
y_train, y_test = y.iloc[train_index], y.iloc[test_index] # 값의 배열이 좌변에 저장
accuracy = model.evaluate(X_test, y_test)[1] # 정확도를 구함
acc_score.append(accuracy) # acc_score 리스트에 저장2/2 [==============================] - 0s 5ms/step - loss: 0.2634 - accuracy: 0.9524
2/2 [==============================] - 0s 5ms/step - loss: 0.1467 - accuracy: 0.9524
2/2 [==============================] - 0s 5ms/step - loss: 0.0413 - accuracy: 0.9762
2/2 [==============================] - 0s 7ms/step - loss: 0.2779 - accuracy: 0.9512
2/2 [==============================] - 0s 6ms/step - loss: 0.3938 - accuracy: 0.90245개의 loss, accuracy가 나오는 것을 볼 수 있음
# 정확도가 채워질 빈 리스트 초기화
acc_score = []
def model_fn(): # 모델 세팅만 해서 return해주는 함수 (컴파일이랑 실행 필요)
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0) # verbose: 함수 수행시 발생하는 상세한 정보를 출력할지?
accuracy = model.evaluate(X_test, y_test)[1] # 0번: loss 1번: accuracy
return model, history, accuracy
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model, history, accuracy = model_fn()
# accuracy 리스트에 append
acc_score.append(accuracy)
# 정확도의 평균
avg_acc_score = sum(acc_score) / k
# 결과 출력
print('정확도: ', np.round(acc_score, 2)) # 리스트에 적용이 가능한 반올림 함수는
print('정확도 평균: ', np.round(avg_acc_score, 2)) # numpy 패키지의 round 함수2/2 [==============================] - 0s 6ms/step - loss: 0.5098 - accuracy: 0.8333
2/2 [==============================] - 0s 8ms/step - loss: 0.3355 - accuracy: 0.9048
2/2 [==============================] - 0s 5ms/step - loss: 1.0617 - accuracy: 0.7381
WARNING:tensorflow:5 out of the last 19 calls to <function Model.make_test_function.<locals>.test_function at 0x000001DB2C89CA40> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
2/2 [==============================] - 0s 6ms/step - loss: 0.8847 - accuracy: 0.6585
WARNING:tensorflow:6 out of the last 21 calls to <function Model.make_test_function.<locals>.test_function at 0x000001DB2DA91B20> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
2/2 [==============================] - 0s 6ms/step - loss: 0.2327 - accuracy: 0.9024
정확도: [0.83 0.9 0.74 0.66 0.9 ]
정확도 평균: 0.8114장
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from sklearn.model_selection import train_test_split
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/wine.csv', header=None)
print(f'행(sample)과 열(attribute + class)개수: {df.shape}')
df.head(5)
# sample이 6497개, 속성은 12개, 클래스는 1개 라는 것을 알 수 있음
X = df.iloc[:,0:12] # attribute 추출
y = df.iloc[:,12] # 클래스 추출WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\losses.py:2976: The name tf.losses.sparse_softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.sparse_softmax_cross_entropy instead.
행(sample)과 열(attribute + class)개수: (6497, 13)
fatal: destination path 'data' already exists and is not an empty directory.| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 주석산 농도 | 아세트산 농도 | 구연산 농도 | 잔류 당분 농도 | 염화나트륨 농도 | 유리 아황산 농도 |
| 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|
| 총 아황산 농도 | 밀도 | 황산칼륨 농도 | 알코올 도수 | 와인의 맛(0~10등급) | 클래스(1: 레드 와인, 0: 화이트 와인) |
test set: 학습을 계속 반복하면서 학습에 사용되지 않은 외부 data set(test set)에 효과가 있는지 확인하는 용도
validation set (검증셋)
최적의 학습 파라미터를 찾기 위해 학습 과정에서 사용하는 데이터
model.fit() 함수 안에 validation_split이라는 옵션을 주면 만들 수 있음
# train set과 test set으로 나눔
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
# train set : test set = 8 : 2
def model_fn():
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
model = model_fn()
model.summary()WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\backend.py:873: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\optimizers\__init__.py:309: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 30) 390
dense_1 (Dense) (None, 12) 372
dense_2 (Dense) (None, 8) 104
dense_3 (Dense) (None, 1) 9
=================================================================
Total params: 875 (3.42 KB)
Trainable params: 875 (3.42 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________history = model.fit(
X_train ,
y_train ,
epochs = 50 ,
batch_size = 500 ,
validation_split = 0.25 # 0.8 * 0.25 = 0.2
)
# train : test : validation = 6 : 2 : 2Epoch 1/50
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\base_layer_utils.py:384: The name tf.executing_eagerly_outside_functions is deprecated. Please use tf.compat.v1.executing_eagerly_outside_functions instead.
8/8 [==============================] - 2s 47ms/step - loss: 0.4171 - accuracy: 0.8312 - val_loss: 0.4037 - val_accuracy: 0.8792
Epoch 2/50
8/8 [==============================] - 0s 9ms/step - loss: 0.3127 - accuracy: 0.8956 - val_loss: 0.2880 - val_accuracy: 0.8800
...
Epoch 50/50
8/8 [==============================] - 0s 11ms/step - loss: 0.1371 - accuracy: 0.9484 - val_loss: 0.1588 - val_accuracy: 0.9485score = model.evaluate(X_test, y_test) # test set으로 테스트
print('Test accuracy:', score[1]) # 0번: loss 1번: accuracy41/41 [==============================] - 0s 2ms/step - loss: 0.1311 - accuracy: 0.9531
Test accuracy: 0.9530768990516663각 epochs마다의 모델 저장하는 방법
modelpath = "./data/model/{epoch:02d}-{val_accuracy:.4f}.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, verbose=1) # 모델 저장 함수
# 모델 초기화
del model
model = model_fn()
history = model.fit(
X_train ,
y_train ,
epochs = 50 ,
batch_size = 500 ,
validation_split = 0.25 ,
verbose = 0 ,
callbacks = [checkpointer] # 각 epochs마다의 모델 저장
)
score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])Epoch 1: saving model to ./data/model\01-0.2454.hdf5
Epoch 2: saving model to ./data/model\02-0.2392.hdf5
c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
Epoch 3: saving model to ./data/model\03-0.7992.hdf5
Epoch 4: saving model to ./data/model\04-0.8038.hdf5
...
Epoch 49: saving model to ./data/model\49-0.9323.hdf5
Epoch 50: saving model to ./data/model\50-0.9323.hdf5
41/41 [==============================] - 0s 2ms/step - loss: 0.1772 - accuracy: 0.9362
Test accuracy: 0.9361538290977478매 에포크마다 결과를 그래프로 확인하는 법
# 모델 초기화
del model
model = model_fn()
### 그래프를 그리기 위해서 epochs를 2000으로 늘려봄
history = model.fit(
X_train ,
y_train ,
epochs = 2000,
batch_size = 500 ,
verbose = 0 ,
validation_split = 0.25 # 0.8 * 0.25 = 0.2
)
print(history.params) # model.fit()의 설정값
print(history.epoch) # 에포크 횟수 배열
hist_df = pd.DataFrame(history.history) # 매 에포크마다의 결과를 표로 출력
hist_df{'verbose': 0, 'epochs': 2000, 'steps': 8}
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104,
...
1941, 1942, 1943, 1944, 1945, 1946, 1947, 1948, 1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971, 1972, 1973, 1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999]| loss | accuracy | val_loss | val_accuracy | |
|---|---|---|---|---|
| 0 | 0.631229 | 0.748781 | 0.524227 | 0.755385 |
| 1 | 0.477113 | 0.749551 | 0.422466 | 0.760000 |
| 2 | 0.396493 | 0.768797 | 0.379726 | 0.792308 |
| 3 | 0.366436 | 0.793944 | 0.362473 | 0.814615 |
| 4 | 0.351955 | 0.821144 | 0.348665 | 0.838462 |
| ... | ... | ... | ... | ... |
| 1995 | 0.022618 | 0.994868 | 0.071947 | 0.982308 |
| 1996 | 0.022527 | 0.994611 | 0.072806 | 0.982308 |
| 1997 | 0.024500 | 0.993328 | 0.072431 | 0.984615 |
| 1998 | 0.021964 | 0.994355 | 0.071639 | 0.982308 |
| 1999 | 0.021676 | 0.994611 | 0.074115 | 0.982308 |
2000 rows × 4 columns
y_vloss = hist_df['val_loss'] # 검증셋의 오차 배열
y_loss = hist_df['loss'] # 학습셋의 오차 배열
x_len = np.arange(len(y_loss)) # x축은 y_loss배열의 원소 개수로
# np.arange를 이용하여 0부터 n-1까지의 배열을 만듦
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_loss')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
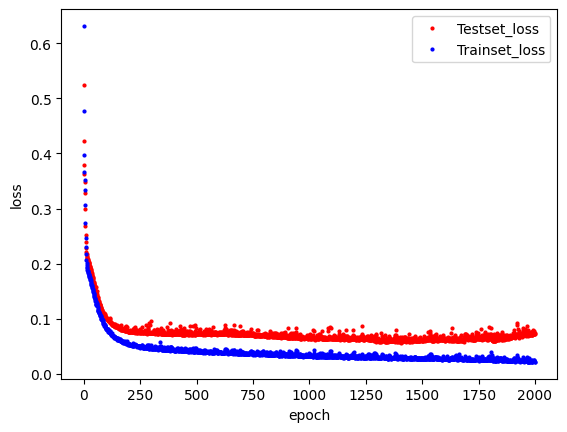
250지점에 testset_loss의 loss가 커지는것을 볼 수 있음
-> 250번의 epoch에서 과적합 발생!
과적합으로 인해 학습이 진행되어도 테스트셋 오차가 줄어들지 않으면 학습을 자동으로 멈추게 하는 방법
early_stopping_callback = EarlyStopping(
monitor = 'val_loss', # 각 epochs마다의 테스트 결과중 어떤 값을 기준으로 삼을지 -> 검증셋의 오차
patience = 20 # 해당 값이 20번의 epochs가 진행되는 동안 한번도 향상되지 않으면 학습을 종료시킴
) # 여기선 검증셋의 오차가 20번 이상 낮아지지 않을 경우 학습을 종료할 것학습 결과중 하나의 값을 기준으로 최고의 모델만을 저장하는 방법
modelpath = "./data/model/Ch14-4-bestmodel.hdf5" # 최고의 모델 저장 경로
checkpointer = ModelCheckpoint(
filepath = modelpath ,
monitor = 'val_loss' , # 검증셋의 오차값을 기준으로
save_best_only = True , # 가장 최고의 모델 선정해서 저장
verbose = 0
)# 모델 초기화
del model
model = model_fn()
history = model.fit(
X_train ,
y_train ,
epochs = 2000 ,
batch_size = 500 ,
validation_split = 0.25 ,
verbose = 1 ,
callbacks = [
early_stopping_callback , # 학습 자동 멈춤
checkpointer # 최고의 모델 저장
]
)Epoch 1/2000
1/8 [==>...........................] - ETA: 8s - loss: 2.0327 - accuracy: 0.1620
c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
8/8 [==============================] - 2s 80ms/step - loss: 0.7668 - accuracy: 0.6223 - val_loss: 0.5495 - val_accuracy: 0.7623
Epoch 2/2000
8/8 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.7580 - val_loss: 0.4919 - val_accuracy: 0.7708
...
Epoch 346/2000
8/8 [==============================] - 0s 8ms/step - loss: 0.0444 - accuracy: 0.9879 - val_loss: 0.0706 - val_accuracy: 0.9800
Epoch 347/2000
8/8 [==============================] - 0s 11ms/step - loss: 0.0442 - accuracy: 0.9882 - val_loss: 0.0739 - val_accuracy: 0.9785score = model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
# test set으로 테스트한 결과 정확도가 대폭 향상된것을 볼 수 있음41/41 [==============================] - 0s 2ms/step - loss: 0.0471 - accuracy: 0.9885
Test accuracy: 0.988461554050445615장
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from sklearn.model_selection import train_test_split
!git clone https://github.com/taehojo/data.git
df = pd.read_csv("./data/house_train.csv")fatal: destination path 'data' already exists and is not an empty directory.row_count, column_count = df.shape
attribute_header = df.columns.tolist()[0:-1] # 0 ~ -2(79) 슬라이스로 속성부분의 헤더 추출
class_header = df.columns.tolist()[-1] # -1(80) 음수 인덱스를 통해 클래스의 헤더 추출
print(f'행(sample) : {row_count}' )
print(f'열(attribute + class) : {column_count}')
print('속성 부분의 헤더:', attribute_header )
print('클래스의 헤더:', class_header )행(sample) : 1460
열(attribute + class) : 81
속성 부분의 헤더: ['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition']
클래스의 헤더: SalePricedf.dtypes
# 각 속성의 자료형이 다양하다는것을 알 수 있음Id int64
MSSubClass int64
MSZoning object
LotFrontage float64
LotArea int64
...
MoSold int64
YrSold int64
SaleType object
SaleCondition object
SalePrice int64
Length: 81, dtype: object!cat ./data/house_train.csv
df.head(5)
# csv파일에 NA라고 써있는 부분, 판다스로 불러와서 출력시킬때 NaN이라 적혀있는 부분이 결측치라는것을 알 수 있음Id,MSSubClass,MSZoning,LotFrontage,LotArea,Street,Alley,LotShape,LandContour,Utilities,LotConfig,LandSlope,Neighborhood,Condition1,Condition2,BldgType,HouseStyle,OverallQual,OverallCond,YearBuilt,YearRemodAdd,RoofStyle,RoofMatl,Exterior1st,Exterior2nd,MasVnrType,MasVnrArea,ExterQual,ExterCond,Foundation,BsmtQual,BsmtCond,BsmtExposure,BsmtFinType1,BsmtFinSF1,BsmtFinType2,BsmtFinSF2,BsmtUnfSF,TotalBsmtSF,Heating,HeatingQC,CentralAir,Electrical,1stFlrSF,2ndFlrSF,LowQualFinSF,GrLivArea,BsmtFullBath,BsmtHalfBath,FullBath,HalfBath,BedroomAbvGr,KitchenAbvGr,KitchenQual,TotRmsAbvGrd,Functional,Fireplaces,FireplaceQu,GarageType,GarageYrBlt,GarageFinish,GarageCars,GarageArea,GarageQual,GarageCond,PavedDrive,WoodDeckSF,OpenPorchSF,EnclosedPorch,3SsnPorch,ScreenPorch,PoolArea,PoolQC,Fence,MiscFeature,MiscVal,MoSold,YrSold,SaleType,SaleCondition,SalePrice
1,60,RL,65,8450,Pave,NA,Reg,Lvl,AllPub,Inside,Gtl,CollgCr,Norm,Norm,1Fam,2Story,7,5,2003,2003,Gable,CompShg,VinylSd,VinylSd,BrkFace,196,Gd,TA,PConc,Gd,TA,No,GLQ,706,Unf,0,150,856,GasA,Ex,Y,SBrkr,856,854,0,1710,1,0,2,1,3,1,Gd,8,Typ,0,NA,Attchd,2003,RFn,2,548,TA,TA,Y,0,61,0,0,0,0,NA,NA,NA,0,2,2008,WD,Normal,208500
2,20,RL,80,9600,Pave,NA,Reg,Lvl,AllPub,FR2,Gtl,Veenker,Feedr,Norm,1Fam,1Story,6,8,1976,1976,Gable,CompShg,MetalSd,MetalSd,None,0,TA,TA,CBlock,Gd,TA,Gd,ALQ,978,Unf,0,284,1262,GasA,Ex,Y,SBrkr,1262,0,0,1262,0,1,2,0,3,1,TA,6,Typ,1,TA,Attchd,1976,RFn,2,460,TA,TA,Y,298,0,0,0,0,0,NA,NA,NA,0,5,2007,WD,Normal,181500
...
1459,20,RL,68,9717,Pave,NA,Reg,Lvl,AllPub,Inside,Gtl,NAmes,Norm,Norm,1Fam,1Story,5,6,1950,1996,Hip,CompShg,MetalSd,MetalSd,None,0,TA,TA,CBlock,TA,TA,Mn,GLQ,49,Rec,1029,0,1078,GasA,Gd,Y,FuseA,1078,0,0,1078,1,0,1,0,2,1,Gd,5,Typ,0,NA,Attchd,1950,Unf,1,240,TA,TA,Y,366,0,112,0,0,0,NA,NA,NA,0,4,2010,WD,Normal,142125
1460,20,RL,75,9937,Pave,NA,Reg,Lvl,AllPub,Inside,Gtl,Edwards,Norm,Norm,1Fam,1Story,5,6,1965,1965,Gable,CompShg,HdBoard,HdBoard,None,0,Gd,TA,CBlock,TA,TA,No,BLQ,830,LwQ,290,136,1256,GasA,Gd,Y,SBrkr,1256,0,0,1256,1,0,1,1,3,1,TA,6,Typ,0,NA,Attchd,1965,Fin,1,276,TA,TA,Y,736,68,0,0,0,0,NA,NA,NA,0,6,2008,WD,Normal,147500| Id | MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | ... | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal | 208500 |
| 1 | 2 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal | 181500 |
| 2 | 3 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal | 223500 |
| 3 | 4 | 70 | RL | 60.0 | 9550 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 2 | 2006 | WD | Abnorml | 140000 |
| 4 | 5 | 60 | RL | 84.0 | 14260 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 12 | 2008 | WD | Normal | 250000 |
5 rows × 81 columns
df.isnull().sum().sort_values(ascending=False).head(20)
# isnull() : null인지 아닌지 true, false로 표시
# sum() : true인것의 갯수를 세줌
# sort_values(ascending=False) : 갯수가 큰것부터 내림차순으로 표시
# head(20) : 상위 20개만 표시
# 결측치가 매우 많다는 것을 볼 수 있음PoolQC 1453
MiscFeature 1406
Alley 1369
Fence 1179
MasVnrType 872
FireplaceQu 690
LotFrontage 259
GarageYrBlt 81
GarageCond 81
GarageType 81
GarageFinish 81
GarageQual 81
BsmtFinType2 38
BsmtExposure 38
BsmtQual 37
BsmtCond 37
BsmtFinType1 37
MasVnrArea 8
Electrical 1
Id 0
dtype: int64결측치를 평균값으로 채우는 법
# one-hot encoding
# 카테코리형 변수(문자열)를 bool변수로 바꿈
df = pd.get_dummies(df)
print(f'one-hot encoding으로 인해 늘어난 열 사이즈(원래는 81개 였음): {df.shape[1]}')
df.head(5)one-hot encoding으로 인해 늘어난 열 사이즈(원래는 81개 였음): 289| Id | MSSubClass | LotFrontage | LotArea | OverallQual | OverallCond | YearBuilt | YearRemodAdd | MasVnrArea | BsmtFinSF1 | ... | SaleType_ConLw | SaleType_New | SaleType_Oth | SaleType_WD | SaleCondition_Abnorml | SaleCondition_AdjLand | SaleCondition_Alloca | SaleCondition_Family | SaleCondition_Normal | SaleCondition_Partial | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | 65.0 | 8450 | 7 | 5 | 2003 | 2003 | 196.0 | 706 | ... | False | False | False | True | False | False | False | False | True | False |
| 1 | 2 | 20 | 80.0 | 9600 | 6 | 8 | 1976 | 1976 | 0.0 | 978 | ... | False | False | False | True | False | False | False | False | True | False |
| 2 | 3 | 60 | 68.0 | 11250 | 7 | 5 | 2001 | 2002 | 162.0 | 486 | ... | False | False | False | True | False | False | False | False | True | False |
| 3 | 4 | 70 | 60.0 | 9550 | 7 | 5 | 1915 | 1970 | 0.0 | 216 | ... | False | False | False | True | True | False | False | False | False | False |
| 4 | 5 | 60 | 84.0 | 14260 | 8 | 5 | 2000 | 2000 | 350.0 | 655 | ... | False | False | False | True | False | False | False | False | True | False |
5 rows × 289 columns
# df.fillna(): 결측치를 괄호안의 값으로 채워주는 함수
df = df.fillna(df.mean()) # df.mean(): 평균값으로 채움
df.head(5)| Id | MSSubClass | LotFrontage | LotArea | OverallQual | OverallCond | YearBuilt | YearRemodAdd | MasVnrArea | BsmtFinSF1 | ... | SaleType_ConLw | SaleType_New | SaleType_Oth | SaleType_WD | SaleCondition_Abnorml | SaleCondition_AdjLand | SaleCondition_Alloca | SaleCondition_Family | SaleCondition_Normal | SaleCondition_Partial | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | 65.0 | 8450 | 7 | 5 | 2003 | 2003 | 196.0 | 706 | ... | False | False | False | True | False | False | False | False | True | False |
| 1 | 2 | 20 | 80.0 | 9600 | 6 | 8 | 1976 | 1976 | 0.0 | 978 | ... | False | False | False | True | False | False | False | False | True | False |
| 2 | 3 | 60 | 68.0 | 11250 | 7 | 5 | 2001 | 2002 | 162.0 | 486 | ... | False | False | False | True | False | False | False | False | True | False |
| 3 | 4 | 70 | 60.0 | 9550 | 7 | 5 | 1915 | 1970 | 0.0 | 216 | ... | False | False | False | True | True | False | False | False | False | False |
| 4 | 5 | 60 | 84.0 | 14260 | 8 | 5 | 2000 | 2000 | 350.0 | 655 | ... | False | False | False | True | False | False | False | False | True | False |
5 rows × 289 columns
df_corr = df.corr() # correlation (상관관계)
df_corr_sort = df_corr.sort_values('SalePrice', ascending=False) # 집값과 관련이 큰 순서대로 sorting
df_corr_sort['SalePrice'].head(10) # 상위 10개 출력SalePrice 1.000000
OverallQual 0.790982
GrLivArea 0.708624
GarageCars 0.640409
GarageArea 0.623431
TotalBsmtSF 0.613581
1stFlrSF 0.605852
FullBath 0.560664
BsmtQual_Ex 0.553105
TotRmsAbvGrd 0.533723
Name: SalePrice, dtype: float64cols = ['SalePrice','OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()
# 관련도 높은 10개의 상관관계 그래프를 찍어보면 집값과 양의 상관관계를 갖고있는것을 볼 수 있음
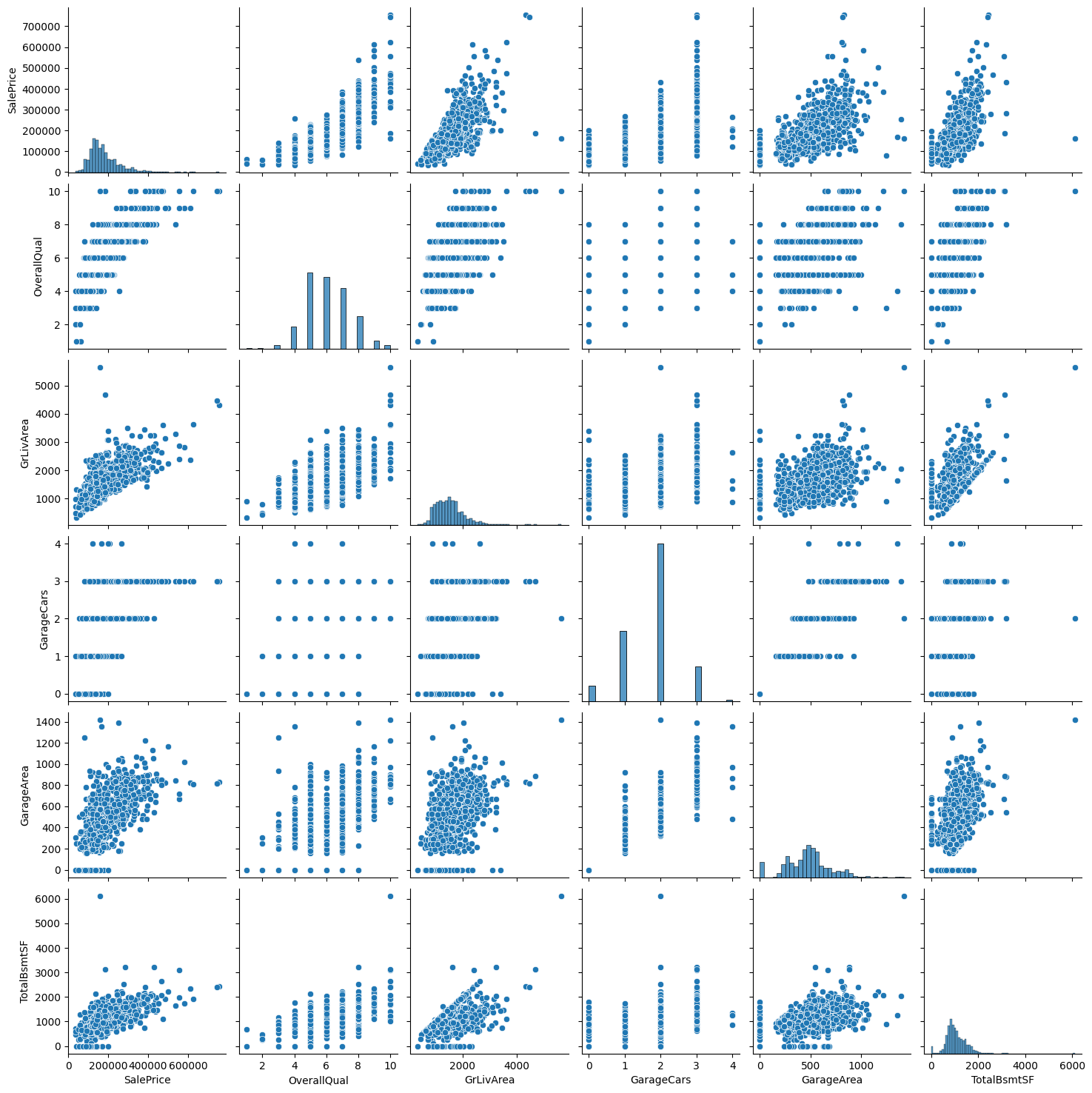
# 상관 관계 높은 속성 5개의 index
cols_train = ['OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
# 샘플마다 5개의 상관 관계 높은 속성(index)의 값만을 추출
X_train_pre = df[cols_train]
print(X_train_pre)
# 클래스 부분의 값 추출
y = df['SalePrice'].values
# train_test_split: 저장된 X 데이터와 y 데이터에서 각각 정해진 비율(%)만큼
# 학습셋과 테스트셋으로 분리시키는 함수
X_train, X_test, y_train, y_test = train_test_split(X_train_pre, y, test_size=0.2)
# train : test = 8 : 2 OverallQual GrLivArea GarageCars GarageArea TotalBsmtSF
0 7 1710 2 548 856
1 6 1262 2 460 1262
2 7 1786 2 608 920
3 7 1717 3 642 756
4 8 2198 3 836 1145
... ... ... ... ... ...
1455 6 1647 2 460 953
1456 6 2073 2 500 1542
1457 7 2340 1 252 1152
1458 5 1078 1 240 1078
1459 5 1256 1 276 1256
[1460 rows x 5 columns]model = Sequential() # X_train의 열 갯수 = 속성 갯수
model.add(Dense(10, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary() # 저번에 했었던 다항 분류와 이항 분류가 아닌
# 수치를 예측하는 선형 회귀이므로 평균 제곱 오차 적용Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_12 (Dense) (None, 10) 60
dense_13 (Dense) (None, 30) 330
dense_14 (Dense) (None, 40) 1240
dense_15 (Dense) (None, 1) 41
=================================================================
Total params: 1671 (6.53 KB)
Trainable params: 1671 (6.53 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________# val_loss(검증셋의 오차)가 20번의 epochs가 진행되는 동안
# 한번도 향상되지(줄어들지) 않으면 학습을 종료시킴
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
# val_loss(검증셋의 오차)기준 최고의 모델 저장
modelpath = "./data/model/Ch15-house.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
# 실행
history = model.fit(
X_train ,
y_train ,
validation_split = 0.25 , # 0.8 * 0.25 = 0.2 (20% -> validation)
epochs = 2000 ,
batch_size = 32 ,
callbacks = [
early_stopping_callback, # 자동 중단
checkpointer # 최고 모델
]
)Epoch 1/2000
28/28 [==============================] - 1s 12ms/step - loss: 39379537920.0000 - val_loss: 36773675008.0000
Epoch 2/2000
1/28 [>.............................] - ETA: 0s - loss: 38825771008.0000
c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
28/28 [==============================] - 0s 6ms/step - loss: 38953889792.0000 - val_loss: 36171620352.0000
Epoch 3/2000
28/28 [==============================] - 0s 5ms/step - loss: 37925081088.0000 - val_loss: 34609692672.0000
Epoch 4/2000
28/28 [==============================] - 0s 5ms/step - loss: 35376328704.0000 - val_loss: 30863357952.0000
...
Epoch 76/2000
28/28 [==============================] - 0s 4ms/step - loss: 2481225216.0000 - val_loss: 1970812544.0000
Epoch 77/2000
28/28 [==============================] - 0s 5ms/step - loss: 2456199168.0000 - val_loss: 1970763520.0000NUM_OF_SAMPLES = 50
# y축
real_prices = []
pred_prices = []
# x축
X_num = np.arange(1, NUM_OF_SAMPLES+1)
Y_prediction = model.predict(X_test).flatten() # flatten(): 다차원 배열을 1차원으로 평탄화
for i in range(NUM_OF_SAMPLES):
real = y_test[i]
prediction = Y_prediction[i]
print("실제가격: {:.2f}, 예상가격: {:.2f}".format(real, prediction))
# y축 데이터
real_prices.append(real)
pred_prices.append(prediction) 10/10 [==============================] - 0s 2ms/step
실제가격: 167500.00, 예상가격: 206969.61
실제가격: 218000.00, 예상가격: 196817.39
실제가격: 180500.00, 예상가격: 199338.03
실제가격: 131000.00, 예상가격: 168687.52
실제가격: 120500.00, 예상가격: 122314.71
실제가격: 187500.00, 예상가격: 201336.58
실제가격: 383970.00, 예상가격: 294443.03
실제가격: 200000.00, 예상가격: 286901.84
실제가격: 192500.00, 예상가격: 194766.16
실제가격: 120000.00, 예상가격: 109649.51
실제가격: 178900.00, 예상가격: 162699.98
실제가격: 194000.00, 예상가격: 197920.42
실제가격: 260000.00, 예상가격: 203003.70
실제가격: 138500.00, 예상가격: 123233.11
실제가격: 207500.00, 예상가격: 203874.05
실제가격: 239000.00, 예상가격: 299424.41
실제가격: 35311.00, 예상가격: 75971.65
실제가격: 138800.00, 예상가격: 142213.09
실제가격: 91000.00, 예상가격: 108552.38
실제가격: 143000.00, 예상가격: 221579.41
실제가격: 169000.00, 예상가격: 223339.27
실제가격: 325000.00, 예상가격: 244547.78
실제가격: 367294.00, 예상가격: 266401.81
실제가격: 224000.00, 예상가격: 185146.80
실제가격: 159000.00, 예상가격: 191219.28
실제가격: 136500.00, 예상가격: 207227.62
실제가격: 128000.00, 예상가격: 136896.97
실제가격: 197500.00, 예상가격: 193194.78
실제가격: 176000.00, 예상가격: 162350.25
실제가격: 178000.00, 예상가격: 182806.89
실제가격: 335000.00, 예상가격: 250310.55
실제가격: 173000.00, 예상가격: 173705.59
실제가격: 214500.00, 예상가격: 212311.73
실제가격: 144000.00, 예상가격: 162858.23
실제가격: 173000.00, 예상가격: 183504.64
실제가격: 112000.00, 예상가격: 144470.08
실제가격: 424870.00, 예상가격: 331719.88
실제가격: 207000.00, 예상가격: 185146.80
실제가격: 237000.00, 예상가격: 227868.73
실제가격: 320000.00, 예상가격: 244123.70
실제가격: 194500.00, 예상가격: 182916.98
실제가격: 120000.00, 예상가격: 130170.38
실제가격: 148000.00, 예상가격: 153926.95
실제가격: 230000.00, 예상가격: 249273.30
실제가격: 250000.00, 예상가격: 272549.91
실제가격: 110000.00, 예상가격: 145987.30
실제가격: 129000.00, 예상가격: 170245.39
실제가격: 87500.00, 예상가격: 100895.91
실제가격: 188000.00, 예상가격: 193161.73
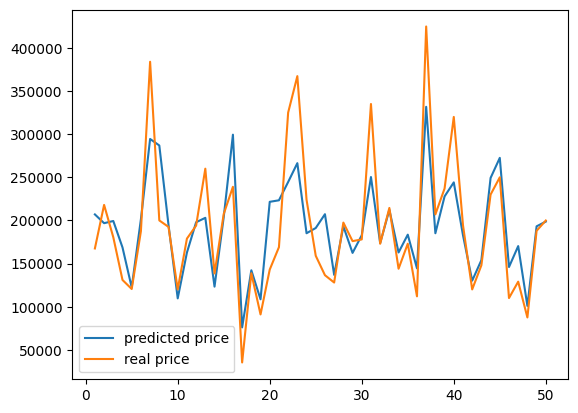
실제가격: 199900.00, 예상가격: 198658.11plt.plot(X_num, pred_prices, label='predicted price')
plt.plot(X_num, real_prices, label='real price')
plt.legend()
plt.show()
# 비슷한 경향성을 보이는 것을 확인할 수 있음