16장
MNIST: 미국 국립표준기술원(NIST)이 고등학생과 인구조사국 직원 등이 쓴 7만개 숫자 손글씨
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print("학습셋 이미지 수: %d개" % (X_train.shape[0])) # training set 샘플 갯수
print("테스트셋 이미지 수: %d개" % (X_test.shape[0])) # test set 샘플 갯수학습셋 이미지 수: 60000개
테스트셋 이미지 수: 10000개plt.imshow(X_train[0], cmap='Greys')
plt.show()
for i in X_train[0]:
for j in i:
print(f"{j:4}", end="")
print()
# 28×28 = 784개의 속성, 0~9의 클래스
print(f'class : {y_train[0]}')
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0
0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0
0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0
0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
class : 5데이터 정규화(normalization)
케라스는 데이터를 0에서 1 사이의 값으로 변환한 후 구동할 때 최적의 성능을 보임
따라서 최대값으로 데이터를 나눠서 0과 1 사이값으로 만듦
# 가로 28, 세로 28의 2차원 배열 -> 784개의 1차원 배열
X_train = X_train.reshape(
X_train.shape[0], # 행의 갯수 (샘플 수)
784 # 열의 갯수 (전체 픽셀 갯수)
)
# 0과 1사이의 값으로 만들기 위해 실수형으로 바꿈
X_train = X_train.astype('float64')
# 255로 나눔
X_train = X_train / 255
# 위의 작업을 한번에 하는 코드
# -> X_train = X_train.reshape(X_train.shape[0], 784).astype('float64') / 255# y_train_pd = pd.get_dummies(y_train)
# 저번에는 문자열을 one hot encoding해서 bool로 이루어진 data frame으로 만들었음
# 이번엔 keras의 to_categorical함수를 이용해 one hot encoding함
# 원래 저장된 값이 정수값일때만 가능하며
# data frame이 아닌 numpy 배열을 반환함
y_train = to_categorical(y_train, 10) model = Sequential()
model.add(Dense(512, input_dim=784, activation='relu'))
model.add(Dense(10, activation='softmax'))# 프레임 설정
model = Sequential()
model.add(Dense(512, input_dim=784, activation='relu')) # 입력층: 784, 은닉층: 512
model.add(Dense(10, activation='softmax')) # 출력층: 10
# 다항분류는 softmax, 이항분류는 sigmoid
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 다항 분류용 교차 엔트로피 오차 함수checkpointer = ModelCheckpoint(
filepath = "./MNIST_MLP.hdf5" ,
monitor = 'val_loss' ,
verbose = 1 , # verbose 켰음
save_best_only = True # 최고 모델 저장
)
early_stopping_callback = EarlyStopping(
monitor = 'val_loss', # 자동 중단
patience = 10
)# 실행
history = model.fit(
X_train,
y_train,
validation_split = 0.25 ,
epochs = 30 ,
batch_size = 200 ,
verbose = 0 ,
callbacks = [
early_stopping_callback, # 자동 중단
checkpointer # 최고 모델 저장
]
)Epoch 1: val_loss improved from inf to 0.18588, saving model to .\MNIST_MLP.hdf5
Epoch 2: val_loss improved from 0.18588 to 0.13380, saving model to .\MNIST_MLP.hdf5
Epoch 3: val_loss improved from 0.13380 to 0.11649, saving model to .\MNIST_MLP.hdf5
Epoch 4: val_loss improved from 0.11649 to 0.09968, saving model to .\MNIST_MLP.hdf5
Epoch 5: val_loss improved from 0.09968 to 0.09694, saving model to .\MNIST_MLP.hdf5
Epoch 6: val_loss improved from 0.09694 to 0.08530, saving model to .\MNIST_MLP.hdf5
Epoch 7: val_loss did not improve from 0.08530
Epoch 8: val_loss improved from 0.08530 to 0.07976, saving model to .\MNIST_MLP.hdf5
Epoch 9: val_loss did not improve from 0.07976
Epoch 10: val_loss did not improve from 0.07976
Epoch 11: val_loss did not improve from 0.07976
Epoch 12: val_loss did not improve from 0.07976
Epoch 13: val_loss did not improve from 0.07976
Epoch 14: val_loss did not improve from 0.07976
Epoch 15: val_loss did not improve from 0.07976
Epoch 16: val_loss did not improve from 0.07976
Epoch 17: val_loss did not improve from 0.07976
Epoch 18: val_loss did not improve from 0.07976# test set도 정규화
X_test = X_test.reshape(X_test.shape[0], 784).astype('float32') / 255
y_test = to_categorical(y_test, 10)
# test set으로 test
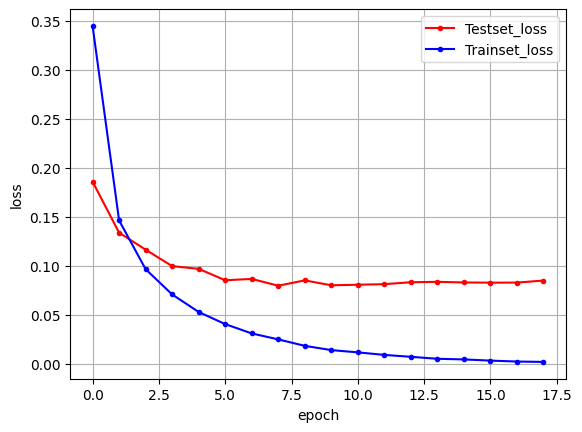
print(f'\n Test Accuracy: {model.evaluate(X_test, y_test)[1]:.4f}')313/313 [==============================] - 1s 2ms/step - loss: 0.0700 - accuracy: 0.9813
Test Accuracy: 0.9813# 그래프 출력
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
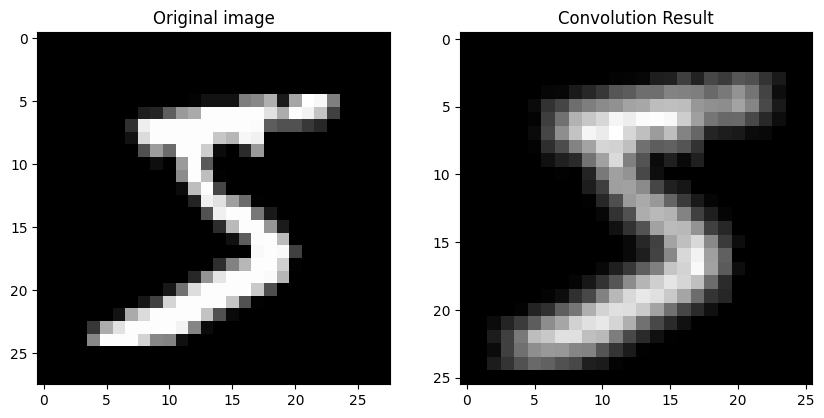
컨볼루션 신경망(CNN)
입력된 이미지의 특징을 추출하기 위해 커널(슬라이딩 윈도)을 도입
image = mnist.load_data()[0][0][0]
# 3x3 커널 생성
kernel = np.array([[1, 0, 1],
[0, 1, 0],
[1, 0, 1]])
# 컨볼루션 결과를 저장할 빈 배열 생성
result = np.zeros((26,26))
# 컨볼루션 연산 수행
for i in range(26):
for j in range(26):
result[i,j] = np.sum(image[i:i+3, j:j+3] * kernel) # 컨볼루션 연산
# 원본 이미지와 컨볼루션 결과
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
axs[0].imshow(image, cmap='gray')
axs[0].set_title('Original image')
axs[1].imshow(result, cmap='gray')
axs[1].set_title('Convolution Result')
plt.show()
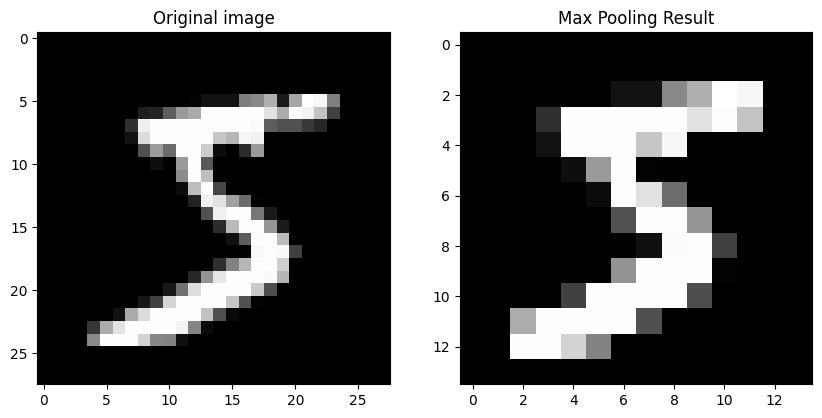
Pooling(sub sampling)
컨볼루션 층을 통해 특징을 추출한 결과가 여전히 크고 복잡하면 이를 다시 축소시키는 기법
맥스 풀링: 정해진 구역 안에서 최댓값을 뽑아내는 것
image = mnist.load_data()[0][0][0]
# 풀링 window 크기 정의
pool_size = 2
# 풀링 결과를 저장할 빈 배열 생성
result = np.zeros((image.shape[0]//pool_size, image.shape[1]//pool_size))
# 맥스 풀링 수행
for i in range(0, image.shape[0], pool_size):
for j in range(0, image.shape[1], pool_size):
result[i//pool_size, j//pool_size] = np.max(image[i:i+pool_size, j:j+pool_size]) # max 값 추출
# 원본 이미지와 맥스 풀링 결과
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
axs[0].imshow(image, cmap='gray')
axs[0].set_title('Original image')
axs[1].imshow(result, cmap='gray')
axs[1].set_title('Max Pooling Result')
plt.show()
Drop out
은닉층에 배치된 노드 중 일부를 임의로 꺼서 과적합을 방지
# 은닉층의 노드 값
hidden_layer = np.array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
# 드롭아웃 비율
dropout_rate = 0.3
# 드롭아웃 마스크 생성
dropout_mask = np.random.rand(hidden_layer.shape[0]) > dropout_rate
# 드롭아웃 적용
output = hidden_layer * dropout_mask
print("드롭아웃 전 은닉층의 노드 값:")
print(hidden_layer)
print("드롭아웃 후 은닉층의 노드 값:")
print(output)드롭아웃 전 은닉층의 노드 값:
[0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
드롭아웃 후 은닉층의 노드 값:
[0.1 0.2 0.3 0.4 0.5 0.6 0.7 0. 0. 1. ]모델에 Convolution, Pooling, Dropout 적용
# 기존 모델 제거
del model
# 프레임 설정
model = Sequential()
# -----------------------------CNN------------------------------
model.add(
Conv2D(
32,
kernel_size = (3,3) , # 3×3 크기의 커널
input_shape = (28,28,1) , # 28×28 크기의 흑백 입력이미지 (컬러면 3, 흑백이면 1)
activation = 'relu'
)
)
model.add(
Conv2D(
64,
kernel_size = (3,3) , # 3×3 크기의 커널
activation = 'relu'
)
)
model.add(
MaxPooling2D(
pool_size = (2,2) # 2x2의 window size
)
)
model.add(Dropout(0.25)) # 25%의 노드 끔
model.add(Flatten( )) # fully connected layer에 연결하기 위해 2차원 -> 1차원
# ---------------------fully connected layer--------------------
model.add(Dense(128, activation='relu') )
model.add(Dropout(0.5) ) # 여기서도 50% drop out...
model.add(Dense(10, activation='softmax'))
# 다항분류는 softmax, 이항분류는 sigmoid
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 다항 분류용 교차 엔트로피 오차 함수
model.summary()Model: "sequential_17"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 26, 26, 32) 320
conv2d_5 (Conv2D) (None, 24, 24, 64) 18496
max_pooling2d_2 (MaxPoolin (None, 12, 12, 64) 0
g2D)
dropout_4 (Dropout) (None, 12, 12, 64) 0
flatten_2 (Flatten) (None, 9216) 0
dense_32 (Dense) (None, 128) 1179776
dropout_5 (Dropout) (None, 128) 0
dense_33 (Dense) (None, 10) 1290
=================================================================
Total params: 1199882 (4.58 MB)
Trainable params: 1199882 (4.58 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________# 데이터 다시 불러오기
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
checkpointer = ModelCheckpoint(
filepath = "./MNIST_CNN.hdf5" ,
monitor = 'val_loss' ,
verbose = 1 , # verbose 켰음
save_best_only = True # 최고 모델 저장
)
early_stopping_callback = EarlyStopping(
monitor = 'val_loss', # 자동 중단
patience = 10
)
# 실행
history = model.fit(
X_train,
y_train,
validation_split = 0.25 ,
epochs = 30 ,
batch_size = 200 ,
verbose = 0 ,
callbacks = [
early_stopping_callback, # 자동 중단
checkpointer # 최고 모델 저장
]
)Epoch 1: val_loss improved from inf to 0.07881, saving model to .\MNIST_CNN.hdf5
c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
Epoch 2: val_loss improved from 0.07881 to 0.05954, saving model to .\MNIST_CNN.hdf5
Epoch 3: val_loss improved from 0.05954 to 0.04701, saving model to .\MNIST_CNN.hdf5
Epoch 4: val_loss improved from 0.04701 to 0.04553, saving model to .\MNIST_CNN.hdf5
Epoch 5: val_loss improved from 0.04553 to 0.04013, saving model to .\MNIST_CNN.hdf5
Epoch 6: val_loss did not improve from 0.04013
Epoch 7: val_loss improved from 0.04013 to 0.03747, saving model to .\MNIST_CNN.hdf5
Epoch 8: val_loss did not improve from 0.03747
Epoch 9: val_loss did not improve from 0.03747
Epoch 10: val_loss did not improve from 0.03747
Epoch 11: val_loss did not improve from 0.03747
Epoch 12: val_loss improved from 0.03747 to 0.03733, saving model to .\MNIST_CNN.hdf5
Epoch 13: val_loss did not improve from 0.03733
Epoch 14: val_loss did not improve from 0.03733
Epoch 15: val_loss did not improve from 0.03733
Epoch 16: val_loss did not improve from 0.03733
Epoch 17: val_loss did not improve from 0.03733
Epoch 18: val_loss did not improve from 0.03733
Epoch 19: val_loss did not improve from 0.03733
Epoch 20: val_loss did not improve from 0.03733
Epoch 21: val_loss did not improve from 0.03733
Epoch 22: val_loss did not improve from 0.03733# 테스트 정확도 출력
print(f'\n Test Accuracy: {model.evaluate(X_test, y_test)[1]:.4f}')
# 그래프 출력
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
# 테스트 정확도가 대폭 향상 되었음을 확인 가능313/313 [==============================] - 3s 10ms/step - loss: 0.0354 - accuracy: 0.9919
Test Accuracy: 0.9919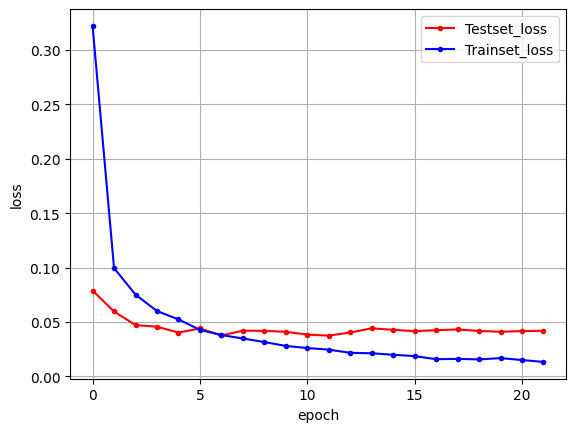
17장
텍스트 컴퓨터 알고리즘은 수치로 된 데이터만 이해 가능
자연어 처리를 위해선 텍스트를 전처리하는 과정 필요
Tokenization
텍스트를 단어별, 문장별, 형태소별로 나눔
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.preprocessing.text import text_to_word_sequence, Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Embedding
text = '아 대학원 진짜 너무 가기 싫다.'
result = text_to_word_sequence(text) # 토큰화 해줌
print("\n원문:\n", text)
print("\n토큰화:\n", result)WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\losses.py:2976: The name tf.losses.sparse_softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.sparse_softmax_cross_entropy instead.
원문:
아 대학원 진짜 너무 가기 싫다.
토큰화:
['아', '대학원', '진짜', '너무', '가기', '싫다']Bag-of-Words (단어의 빈도수 계산)
같은 단어가 몇번 반복되서 쓰였는지 확인
docs = [
'니코니코니 아나타노 하토니 니코니코니' ,
'에가오 토도게루 야자와 니코니코' ,
'앗 다메다메다메 니코와 밍나노 모노❤️'
]
token = Tokenizer()
token.fit_on_texts(docs) # 토큰화 함수에 문장 입력
word_counts = token.word_counts # 각 단어 빈도수
document_count = token.document_count # 문장 갯수
word_in_docs = token.word_docs # 각 단어가 각 문장에 포함된 갯수
word_index = token.word_index # 단어 index값
print("\nWord Count:\n", word_counts)
print("\nDocument Count: ", document_count)
print("\nWords in Documents:\n", word_in_docs)
print("\nWord Index Values:\n", word_index) Word Count:
OrderedDict([('니코니코니', 2), ('아나타노', 1), ('하토니', 1), ('에가오', 1), ('토도게루', 1), ('야자와', 1), ('니코니코', 1), ('앗', 1), ('다메다메다메', 1), ('니코와', 1), ('밍나노', 1), ('모노❤️', 1)])
Document Count: 3
Words in Documents:
defaultdict(<class 'int'>, {'니코니코니': 1, '아나타노': 1, '하토니': 1, '토도게루': 1, '에가오': 1, '니코니코': 1, '야자와': 1, '밍나노': 1, '다메다메다메': 1, '니코와': 1, '모노❤️': 1, '앗': 1})
Word Index Values:
{'니코니코니': 1, '아나타노': 2, '하토니': 3, '에가오': 4, '토도게루': 5, '야자와': 6, '니코니코': 7, '앗': 8, '다메다메다메': 9, '니코와': 10, '밍나노': 11, '모노❤️': 12}단어의 출현 빈도를 추출 해봤음
이제 해당 단어가 문장의 어디에서 왔는지, 각 단어의 순서는 어떠했는지 등에 관한 정보를 추출해야됨
단어의 one-hot encoding
text = "아 대학원 진짜 너무 가기 싫다."
token = Tokenizer()
token.fit_on_texts([text])
print(token.word_index)
''' # 주의 (헷갈림)
x = text_to_word_sequence(text) # 토큰화 해주는 함수
print(x)
'''
x = token.texts_to_sequences([text]) # 토큰의 인덱스 배열을 반환하는 함수
print(x){'아': 1, '대학원': 2, '진짜': 3, '너무': 4, '가기': 5, '싫다': 6}
[[1, 2, 3, 4, 5, 6]]word_size = len(token.word_index) + 1
# keras의 to_categorical함수
# one hot encoding함
# 원래 저장된 값이 정수값일때만 가능하며
# data frame이 아닌 numpy 배열을 반환함
x = to_categorical(x, num_classes=word_size) # num_classes로 클래스 갯수 명시 가능
print(x)
# index들이 벡터화된것을 볼 수 있음[[[0. 1. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 1.]]]word embedding(단어 임베딩)
원-핫 인코딩을 그대로 사용하면 벡터의 길이가 너무 길어진다는 단점
단어 임베딩은 단어가 유사도를 계산하여 주어진 배열을 정해진 길이로 압축하는 방법
케라스에서 제공하는 Embedding() 함수를 사용하면 됨
model = Sequential() # 단어를 매번 얼마나 입력할지
model.add(Embedding(16, 4, input_length=2))
model.summary() # 입력, 출력
del modelWARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\backend.py:873: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 2, 4) 64
=================================================================
Total params: 64 (256.00 Byte)
Trainable params: 64 (256.00 Byte)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________텍스트를 읽고 긍정, 부정 예측
# 텍스트 리뷰 자료를 지정합니다.
docs = [
'너무 재밌네요',
'최고예요',
'참 잘 만든 영화예요',
'추천하고 싶은 영화입니다.',
'한 번 더 보고싶네요',
'글쎄요',
'별로예요',
'생각보다 지루하네요',
'연기가 어색해요',
'재미없어요'
]
classes = np.array([1,1,1,1,1,0,0,0,0,0])
# 토큰화
token = Tokenizer()
token.fit_on_texts(docs)
print(token.word_index) # 토큰화된 결과를 출력
x = token.texts_to_sequences(docs) # 토큰의 인덱스 배열을 x에
print("\n리뷰 텍스트, 토큰화 결과:\n", x){'너무': 1, '재밌네요': 2, '최고예요': 3, '참': 4, '잘': 5, '만든': 6, '영화예요': 7, '추천하고': 8, '싶은': 9, '영화입니다': 10, '한': 11, '번': 12, '더': 13, '보고싶네요': 14, '글쎄요': 15, '별로예요': 16, '생각보다': 17, '지루하네요': 18, '연기가': 19, '어색해요': 20, '재미없어요': 21}
리뷰 텍스트, 토큰화 결과:
[[1, 2], [3], [4, 5, 6, 7], [8, 9, 10], [11, 12, 13, 14], [15], [16], [17, 18], [19, 20], [21]]Padding(패딩)
딥러닝 모델에 입력하려면 학습 데이터의 길이가 동일해야 함
문장마다 토큰의 수를 똑같이 맞추는 작업
padded_x = pad_sequences(x, 4) # 모든 문장을 토큰 갯수 4로 맞추기
print("\n패딩 결과:\n", padded_x)패딩 결과:
[[ 0 0 1 2]
[ 0 0 0 3]
[ 4 5 6 7]
[ 0 8 9 10]
[11 12 13 14]
[ 0 0 0 15]
[ 0 0 0 16]
[ 0 0 17 18]
[ 0 0 19 20]
[ 0 0 0 21]]model = Sequential()
word_size = len(token.word_index) + 1
model.add(
Embedding(
word_size , # 입력: 22, 총 몇 개의 인덱스가 입력되어야 하는지, index의 갯수로 정함
8 , # 출력: 8, 몇 개의 임베딩 결과를 사용할 것인지, 임의로 정함
input_length=4 # 단어수: 4, 그리고 매번 입력될 단어 수는 몇 개로 할지
)
)
model.add(Flatten()) # 2차원(문장 단위) -> 1차원
model.add(Dense(1, activation='sigmoid'))
model.compile(
optimizer='adam' ,
loss='binary_crossentropy', # 긍정 or 부정 -> 이항분류
metrics=['accuracy']
)
model.summary()WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\optimizers\__init__.py:309: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 4, 8) 176
flatten (Flatten) (None, 32) 0
dense (Dense) (None, 1) 33
=================================================================
Total params: 209 (836.00 Byte)
Trainable params: 209 (836.00 Byte)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________model.fit(padded_x, classes, epochs=20)
print("\n Accuracy: %.4f" % (model.evaluate(padded_x, classes)[1]))Epoch 1/20
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\base_layer_utils.py:384: The name tf.executing_eagerly_outside_functions is deprecated. Please use tf.compat.v1.executing_eagerly_outside_functions instead.
1/1 [==============================] - 1s 1s/step - loss: 0.6985 - accuracy: 0.4000
Epoch 2/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6962 - accuracy: 0.4000
Epoch 3/20
1/1 [==============================] - 0s 8ms/step - loss: 0.6940 - accuracy: 0.5000
Epoch 4/20
1/1 [==============================] - 0s 9ms/step - loss: 0.6918 - accuracy: 0.5000
Epoch 5/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6895 - accuracy: 0.6000
Epoch 6/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6873 - accuracy: 0.7000
Epoch 7/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6851 - accuracy: 0.8000
Epoch 8/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6829 - accuracy: 0.8000
Epoch 9/20
1/1 [==============================] - 0s 9ms/step - loss: 0.6807 - accuracy: 0.9000
Epoch 10/20
1/1 [==============================] - 0s 9ms/step - loss: 0.6785 - accuracy: 0.9000
Epoch 11/20
1/1 [==============================] - 0s 6ms/step - loss: 0.6762 - accuracy: 0.9000
Epoch 12/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6740 - accuracy: 0.9000
Epoch 13/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6718 - accuracy: 0.9000
Epoch 14/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6695 - accuracy: 0.9000
Epoch 15/20
1/1 [==============================] - 0s 6ms/step - loss: 0.6673 - accuracy: 0.9000
Epoch 16/20
1/1 [==============================] - 0s 6ms/step - loss: 0.6650 - accuracy: 0.9000
Epoch 17/20
1/1 [==============================] - 0s 8ms/step - loss: 0.6628 - accuracy: 0.9000
Epoch 18/20
1/1 [==============================] - 0s 7ms/step - loss: 0.6605 - accuracy: 0.9000
Epoch 19/20
1/1 [==============================] - 0s 32ms/step - loss: 0.6582 - accuracy: 0.9000
Epoch 20/20
1/1 [==============================] - 0s 8ms/step - loss: 0.6559 - accuracy: 1.0000
1/1 [==============================] - 0s 212ms/step - loss: 0.6536 - accuracy: 1.0000
Accuracy: 1.0000
공기정