우선순위 큐 (Priority Queue)란?
- 일반적인 큐 자료구조는 FIFO 구조
- 우선순위 큐란?
-> 먼저 들어온 데이터를 무작정 처리하는 구조가 아니라 데이터의 우선순위에 따라 우선순위가 높은 데이터를 먼저 처리하는 구조
4, 6, 3, 1, 2 순으로 데이터가 들어오고 각각의 숫자를 우선 순위라 생각해보자.
1) 4가 큐에 들어옴 -> 현재 큐에 있는 데이터 중 우선 순위가 가장 높음
2) 6이 들어옴 -> 6은 4보다 우선순위가 높으므로, 6,4 순서로 정렬함
3) 3이 큐에 들어옴 -> 앞의 두 수보다 우선순위가 낮으므로 큐의 변화가 없음
4) 1이 큐에 들어옴 -> 앞의 데이터들보다 우선순위가 낮으므로 큐의 변화 없음
5) 2가 큐에 들어옴 -> 2는 1보다 우선순위가 크므로 자리를 바꿔줌
-> 이렇게 우선순위를 고려해 큐에 삽입하면 [6,4,3,2,1]의 리스트를 얻게 되고, 이를 순서대로 처리하면 우선순위에 맞게 데이터를 처리하는 것.
-> 그럼 데이터를 삽입할 때마다 큐에 있는 데이터를 하나씩 비교해서 우선순위에 맞는 자리를 찾아 넣으면 되겠다!
=> 구현은 쉽지만 삽입 과정에서 위치하게 될 데이터들을 모두 한 칸씩 뒤로 밀어야 한다는 단점이 있음. 또한 최악의 경우 삽입해야 하는 위치를 찾기 위해 모든 인덱스를 탐색해야 할 수 있으므로 데이터가 N개라면 O(N)의 시간 복잡도를 가짐 -> 따라서 힙 사용
힙(Heap) 이란?
- 기본적으로 완전 이진 트리로 이루어짐
- 모든 노드의 우선순위가 자식 노드의 우선순위보다 크거나 같으며, 우선순위의 기준을 어떻게 잡느냐에 따라서 최소힙과 최대힙으로 나뉨
최대힙 (Max Heap)
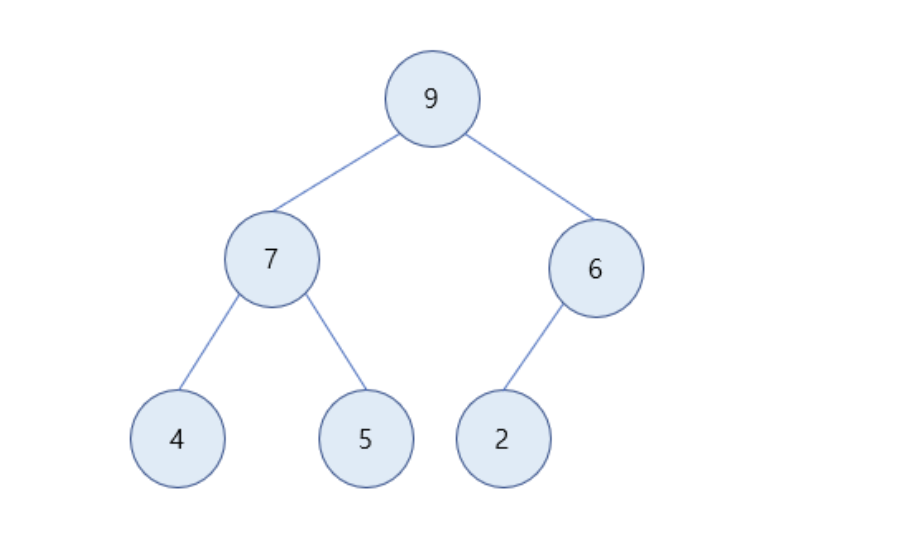
- 값이 클수록 우선순위가 높으며 힙의 성질에 따라 루트 노드로 올라갈수록 값이 커짐 (부모 노드 >= 자식 노드)
최소 힙 (Min Heap)
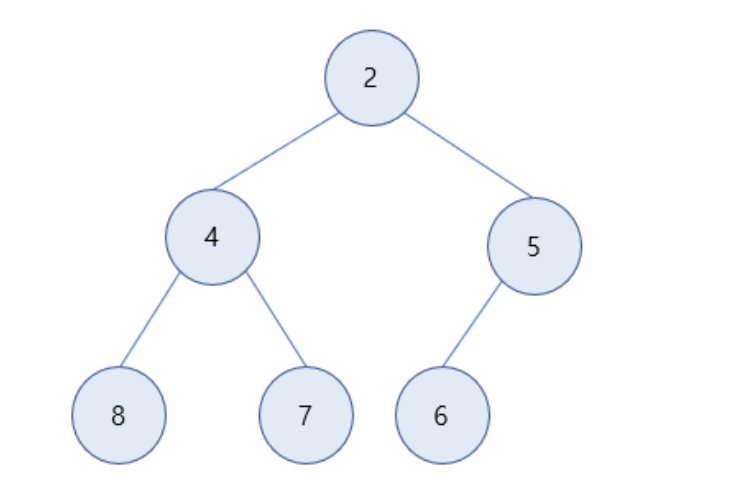
- 값이 작을수록 우선순위가 높으며 힙의 성질에 따라 루트 노드로 올라갈수록 값이 작아짐 (부모 노드 <= 자식 노드)
힙의 동작
- 최소힙으로
삽입
- 1을 최소힙에 삽입
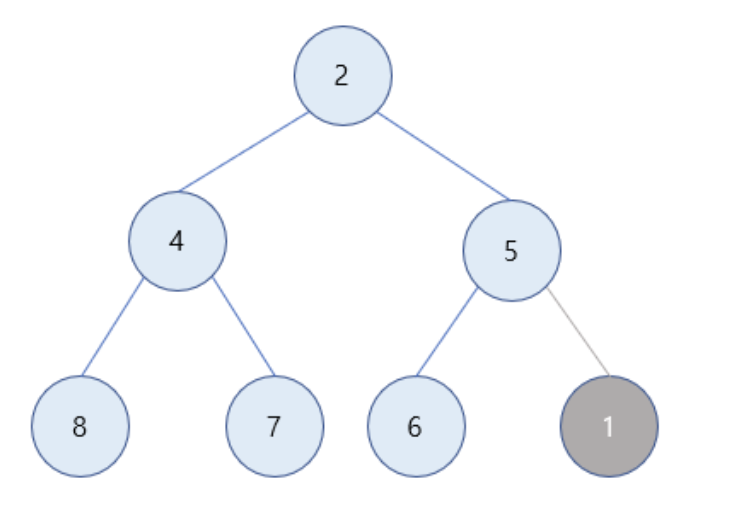
- 힙은 완전 이진 트리 -> 삽입할 때도 이를 유지해야 함
-
1은 값이 5인 부모 노드보다 값이 작으므로 최소 힙의 성질을 만족하기 위해 부모 노드와 자리를 바꿈
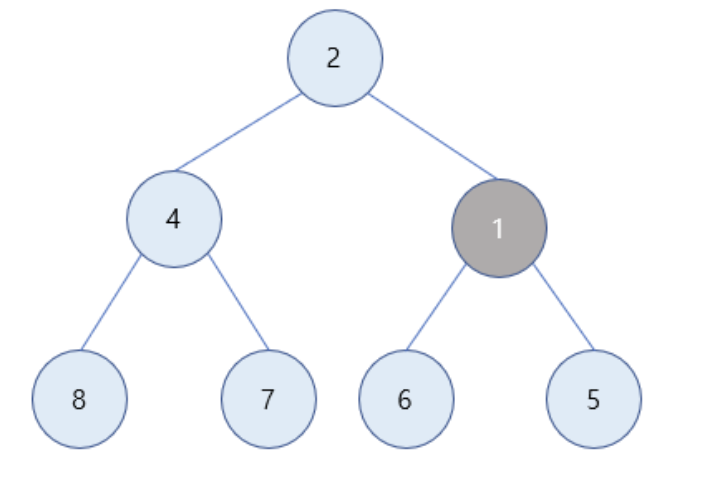
-
마찬가지로 1은 값이 2인 부모 노드보다 값이 작으므로 최소 힙의 성질을 만족하기 위해 부모 노드와 자리를 바꿈
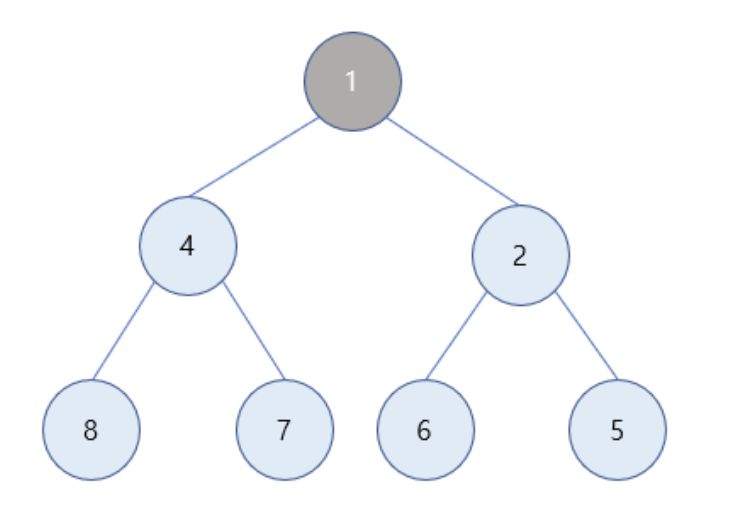
삭제
- 최소 힙에서의 삭제는 값이 제일 작은 노드 -> 루트 노드의 삭제를 의미
-
1값을 가진 노드가 삭제됨
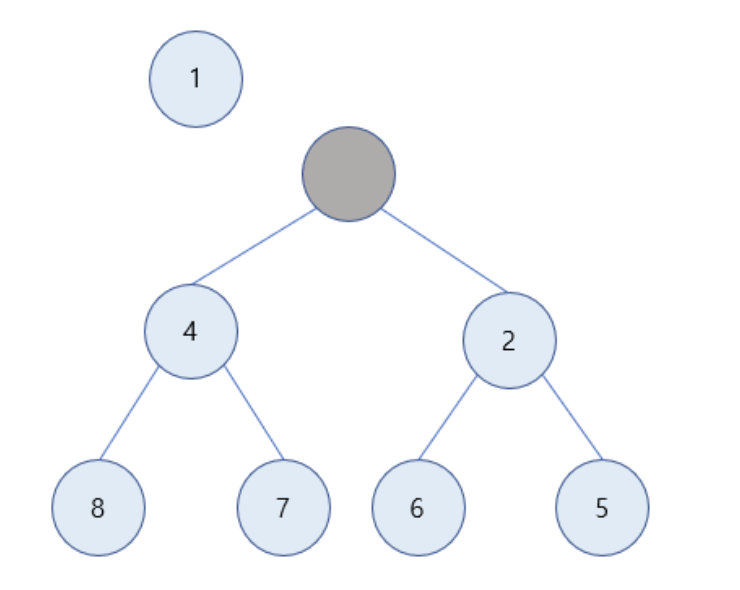
-
루트 노드가 비게 되며, 이를 마지막 노드가 채움
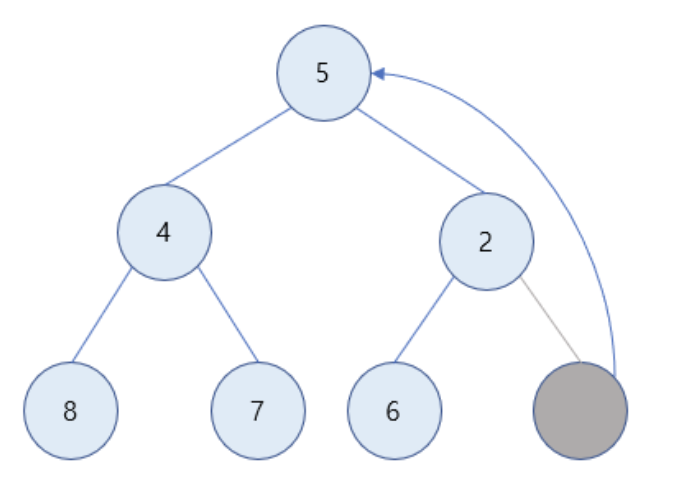
-
자식 노드가 값이 더 작으므로 값을 교환해주기 위해 더 작은 값을 구함 -> 2가 4보다 작으므로 2의 값을 가진 노드와 루트 노드를 바꿈
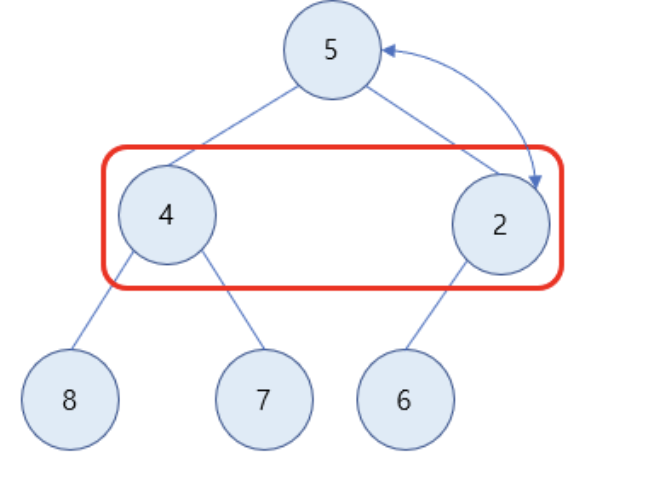
-
최소힙 만족 삭제 종료
-> 삽입 삭제는 트리의 높이까지 비교가 이루어지기 때문에 데이터가 N개라면 O(logN)의 시간 복잡도를 가짐
