알고리즘 스터디
1.#1 탐색 (완전탐색과 이분탐색)
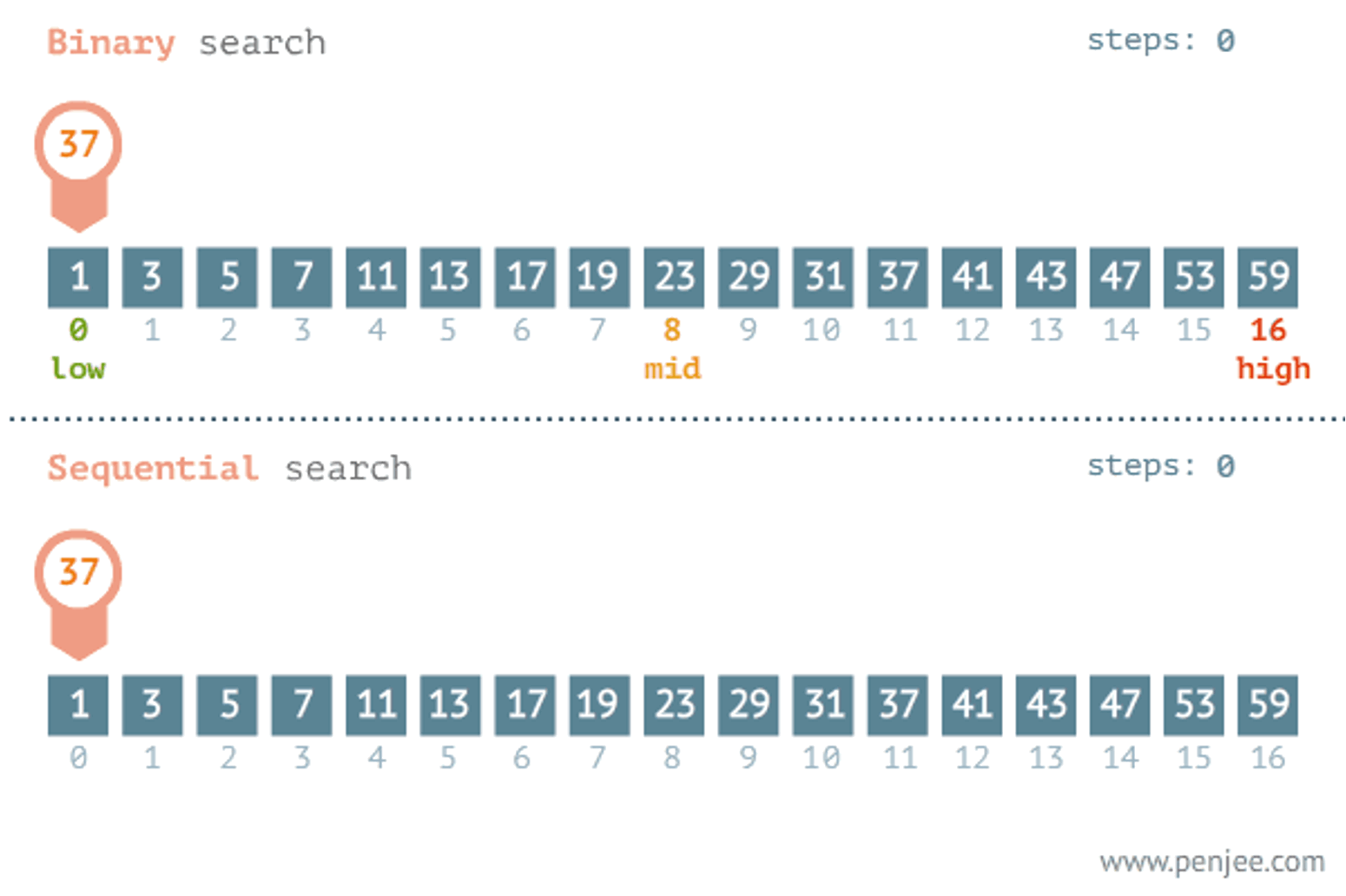
탐색 문제 저장된 데이터들 중에서 원하는 값을 찾는 문제 1. 선형 탐색 알고리즘 (Linear Search Alogorithm) 맨 앞이나, 맨 뒤부터 순서대로 하나하나 찾아보는 알고리즘 가장 단순하고 간단함 맨 앞부터 하나하나 원하는 값을 찾아
2.#2 그리디 알고리즘 (탐욕법)

그리디 알고리즘 (탐욕법) 현재 상황에서 지금 당장 좋은 것만 고르는 방법 각 단계에서 최적이라고 생각되는 것을 선택해 나가는 방법 항상 최적의 값을 보장하는 것이 아니라, 최적의 값의 '근사한 값'을 목표로 함 가장 큰 값을 구한다고 할 때, 최적의 값은 10
3.#3 동적 계획법 (DP)
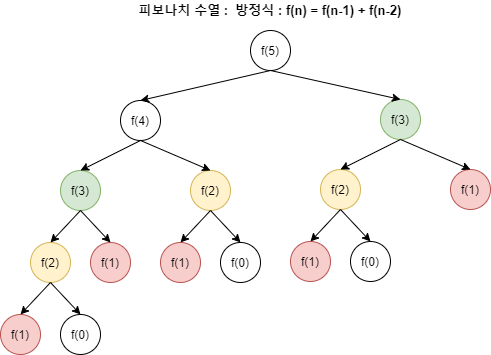
하나의 큰 문제를 여러 개의 작은 문제로 나누어서 그 결과를 저장하여 다시 큰 문제를 해결할 때 사용하는 것큰 문제를 작은 문제로 쪼개서 그 답을 저장해두고 재활용 -> 기억하며 풀기, 메모이제이션 그러나 한 번 구한 작은 문제의 결과 값을 저장해두고 재사용 한다면
4.#5 DFS와 BFS
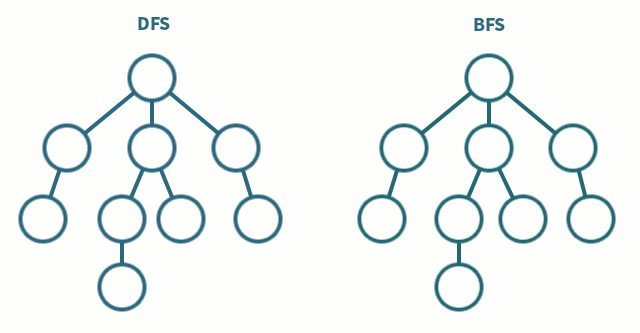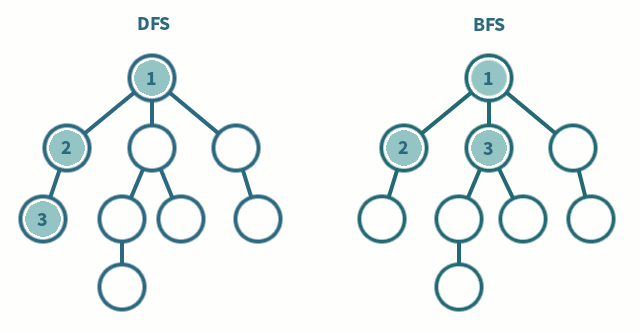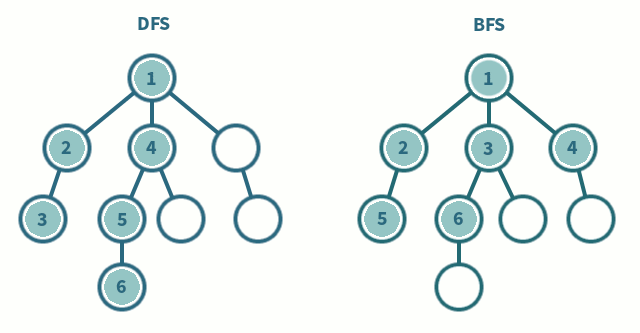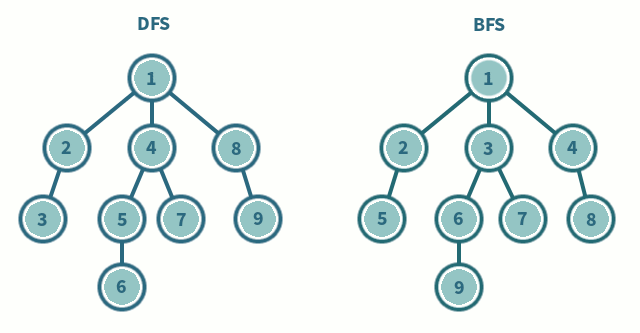
그래프의 모든 꼭짓점을 방문하는 알고리즘을 의미둘의 차이는 노드 방문 순서<span style="background-color: - 예를 들어, 경로에 같은 숫자가 있으면 안 된다, 각각의 경로마다 특징을 저장해둬야 한다 등 검색 대상 그래프 큰 문제<sp
5.#8 우선순위 큐 (heap)
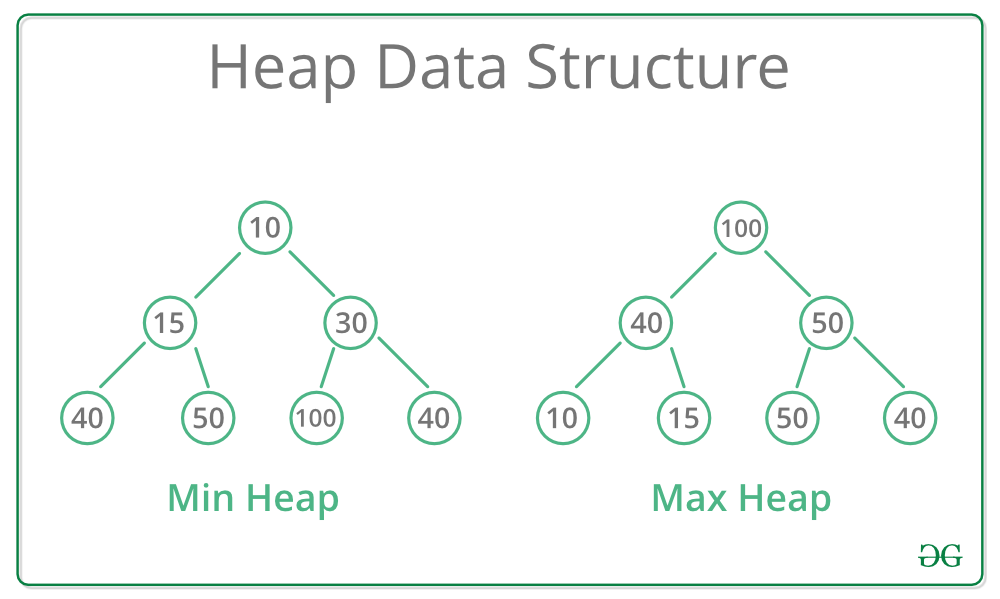
최소 힙: 부모 노드의 키값이 자식 노드의 키값보다 항상 작은 힙최대 힙: 부모 노드의 키값이 자식 노드의 키값보다 항상 큰 힙힙에서는 가잔 낮은 (혹은 높은) 우선순위를 가지느 노드가 항상 루트에 오게 되고, 이를 이용하여 우선순위 큐와 같은 추산적 자료형 구현 가능
6.#9 위상 정렬
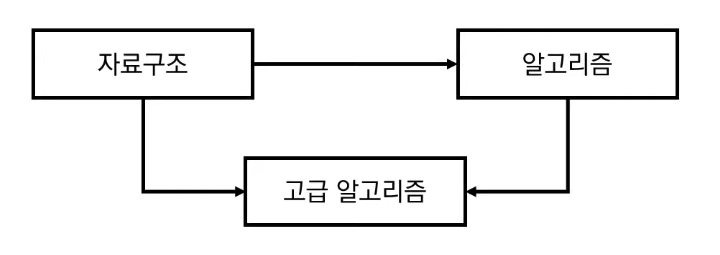
위 세 과목을 모두 듣기 위한 적절한 학습 순서는? \- 자료구조 -> 알고리즘 -> 고급 알고리즘동작 예시이때 그래프는 사이클이 없는 방향 그래프여야 함진입차수가 0인 모든 노드를 큐에 넣음큐에서 노드 1을 꺼낸 뒤 노드 1에서 나가는 간선 제거 -> 새롭게 진입차
7.[알고리즘] 서로소 집합 자료구조
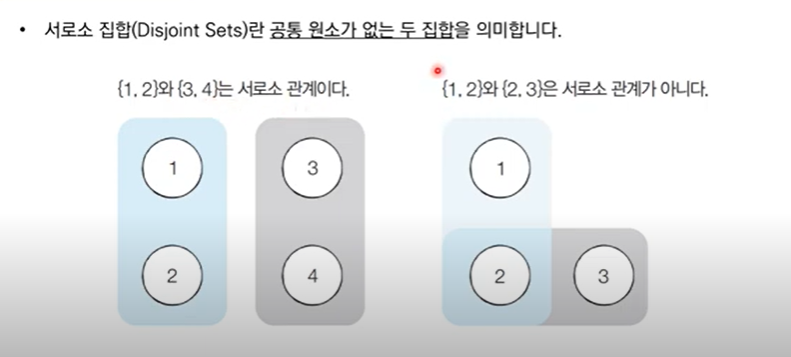
서로소 집합 자료구조서로소 집합공통 원소가 없는 두 집합을 의미서로소 집합 자료구조서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조두 종류의 연산 지원 \- 합집합: 두 개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산찾기: 특정한 원소가
8.[Python] 0-1 BFS
가중치가 0과 1로만 이루어진 그래프 상에서 최단거리를 찾는 알고리즘가중치가 있는 경우에는 다익스트라 알고리즘을 통해 구할 수 있음BFS는 큐를 사용하여 현재 노드에서 연결된 노드를 목표로 탐색하기 때문에 가중치가 있는 그래프에서는 사용 X (가중치가 있을 경우 더 멀
9.[Python] SWEA D3 최대 상금
처음 풀이 가장 큰 값을 구해서 line2 리스트에 하나씩 넣어주고 바뀐 애들은 line에 둬서 둘을 합쳐서 출력해주는 방법 (max 값으로 가장 앞에 설정해둔 게 다른 인덱스로 계속 바뀌는 걸 못하게 하려고...) 사실 풀면서도 알았는데 이렇게 풀면 예시 그림에
10.[Python] 백준 14888 연산자 끼워넣기
정답 코드계산 결과값 범위가 문제에 주어져있어서 설정해준다연산자 개수를 따로 따로 받아서 계산할 연산자가 남았을 경우 계산해주고 다시 dfs 탐색해준다도저히 모르겠어서https://www.youtube.com/watch?v=6mbVfrwb3Qc강의를 참고했다백
11.[Python] 백준 11724 연결 요소의 개수
연결 요소의 개수문제방향 없는 그래프의 연결 요소 개수를 구하기입력N: 정점의 개수, M: 간선의 개수u,v : 간선의 양 끝점같은 간선은 한 번만 주어짐출력연결 요소의 개수 출력항상 dfs는 개수 셀 때 헷갈린다...!!!구현만 하면 풀리는 간단한 문제였다 다행 ☺️
12.#6 투 포인터
1차원 배열에서 각자 다른 원소를 가리키고 있는 2개의 포인터를 조작해가면서 원하는 값을 찾을 때까지 탐색하는 알고리즘리스트에 순차적으로 접근해야 할 때 두 개의 점의 위치를 기록하면서 처리회전 초밥문제귀여운 라이언문제라이언 인형은 1, 어피치 인형은 2라이언 인형이
13.[알고리즘] 백트래킹
N과 M자연수 N과 M이 주어졌을 때, 1부터 N까지 자연수 중에서 중복 없이 M개를 고른 수열을 모두 구하는 프로그램수열은 사전 순으로 증가하는 순서로 출력
14.[Python] SWEA 3727 가능한 시험 점수
가능한 시험 점수문제문제 수와 각 문제 배점이 주어짐나올 수 있는 시험 점수의 경우의 수를 구하기입력T : 테스트 케이스 수N : 문제의 개수두번째 줄 ~ : 각문제의 배점 (1 <= 배점 <= 100)출력나올 수 있는 시험 점수의 경우의 수를 출력첫 풀이
15.[알고리즘] 이진탐색
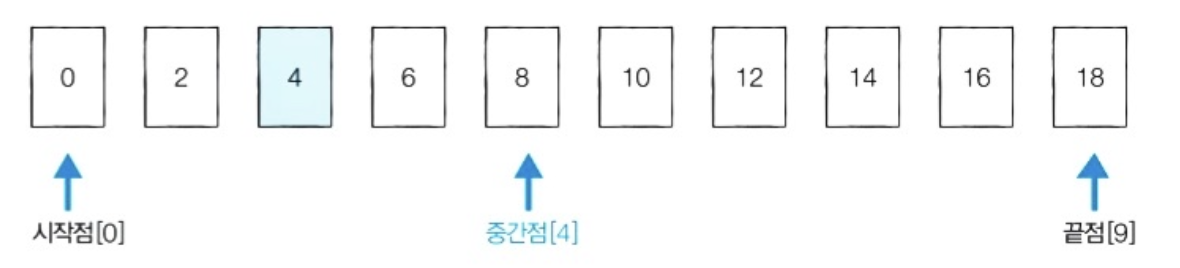
이진 탐색 순차 탐색 순차 탐색(Sequential Search)이란 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법 -이름 그대로 순차로 데이터를 탐색한다는 의미이며, 보통 정렬되지 않은 리스트에서 데이터를 찾아야 할
16.[알고리즘] 에라토스테네스의 체
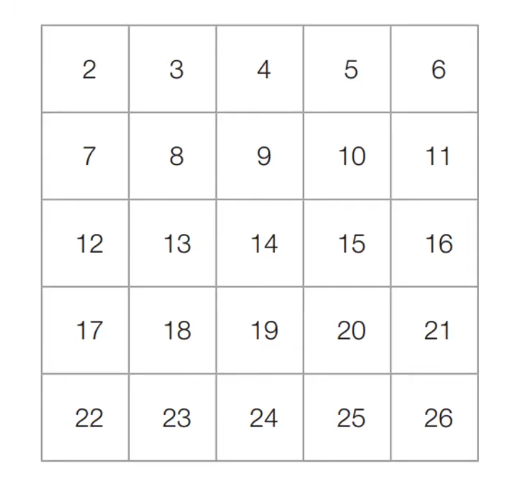
다수의 소수 판별특정한 수의 범위 안에 존재하는 모든 소수를 찾아야 할 경우에 '에라토스테네스의 체' 알고리즘을 사용할 수 있다다수의 자연수에 대하여 소수 여부를 판별할 때 사용하는 대표적인 알고리즘에라토스테네스의 체는 N보다 작거나 같은 모든 소수를 찾을 때 사용할
17.[Python] SWEA 1289 원재의 메모리 복구하기
원재의 메모리 복구하기문제 분석메모리의 원래값이 주어짐메모리는 0과1로 이루어짐메모리 숫자 하나를 고치면 그 뒤 모든 숫자도 고친 숫자로 변함 ex) 0100 ->(3번째를 1로 바꿈) 0111메모리를 복구하기 위한 최소 수정 횟수를 구하기입력T : 테스트 케이스 수
18.[Python] 12865 평범한 배낭
평범한 배낭분석각 물건은 무게와 가치를 가짐무게와 가치를 고려하여 버틸 수 있는 무게 안에서 준서가 최대한 즐거운 여행을 하기 위해 넣을 수 있는 물건들의 최댓값입력N: 물품의 수, K: 버틸 수 있는 무게출력한 줄에 배낭에 넣을 수 있는 물건들의 가치합의 최댓값접근
19.[Python] 욕심쟁이 판다
욕심쟁이 판다분석대나무를 먹고 상,하,좌,우 중 한 곳으로 이동하여 또 먹음자리를 옮기면 옮긴 지역에 전 지역보다 대나무가 많이 있어야 한다어떤 지점에 처음 풀어 놓아야 하고, 어떤 곳으로 이동을 시켜야 최대한 많은 칸을 방문할 수 있는지입력N: 대나무 숲의 크기대나무
20.[Python] 10026 적록색약

적록색약문제그리드의 각 칸에 R, G, B 중 하나로 색칠한 그림이 있음그림은 몇 개의 구역으로 나뉨 -> 구역은 같은 색으로 이루어짐같은 색상이 상하좌우로 인접해 있는 경우에 두 글자는 같은 구역에 속함이 예시에서는 적록색약이 아닌 사람이 봤을 때 구역은 4개 (빨2
21.[Python] 백준 4179 불!
처음 든 생각최단거리니까 bfs + 지훈이도 탐색을 돌고 불도 돌리자그런데 어떻게...?처음 작성했을 때 불과 지훈이를 동시에 돌려서 문제 해결이 되지 않았다둘 다 돌리는 건 맞지만 불이 먼저 확산되고, 지훈이가 움직일 수 있는지를 체크하는 게 중요할 듯불 먼저 구현
22.[Java] 백준 12863 뮤탈리스크
뮤탈리스크분석뮤탈리스크는 한번에 3개의 SCV를 공격함첫번째로 공격하는 SCV는 9의 체력을 소모두번째로 공격하는 SCV는 3의 체력을 소모세번째로 공격하는 SCV는 1의 체력을 소모SCV의 체력이 0이하가 되면 파괴공격횟수를 최소로 해서 모든 SCV를 파괴하기입력N
23.[Python] 백준 3986 좋은 단어
좋은 단어문제좋은 단어 -> 같은 글자끼리 (A는 A끼리, B는 B끼리) 쌍을 짓는 것좋은 단어 개수 세기풀이스택이 비었다면 스택에 값을 넣어주고, 스택의 가장 뒷 값과 같으면 pop 해주기. 아니라면 값을 또 넣어주고 반복하기.마지막에 stack이 비었다면 개수 세주
24.[알고리즘] 우선순위 큐
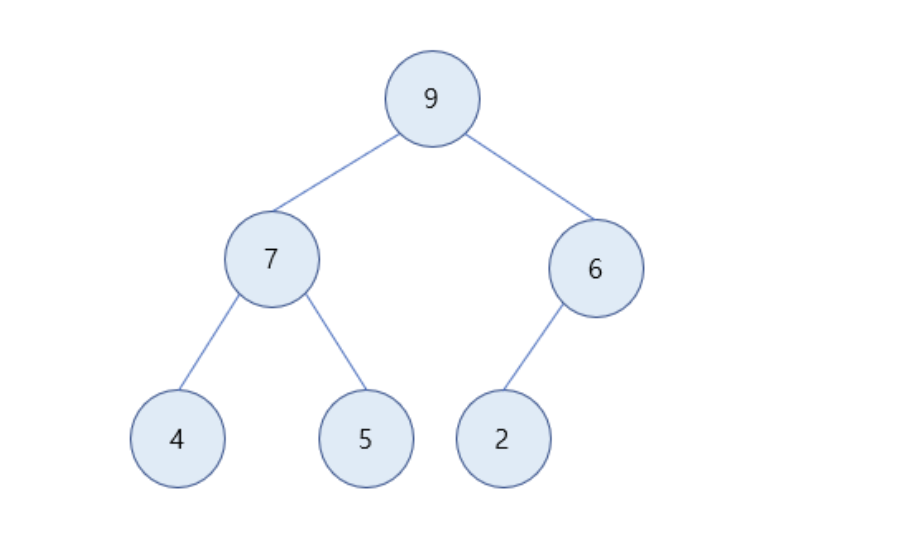
일반적인 큐 자료구조는 FIFO 구조우선순위 큐란? \-> 먼저 들어온 데이터를 무작정 처리하는 구조가 아니라 데이터에 우선순위에 따라 우선순위가 높은 데이터를 먼저 처리하는 구조 1) 4가 큐에 들어옴 -> 현재 큐에 있는 데이터 중 우선 순위가 가장 높음2) 6
25.[Java] 분할 정복 (Divde & Conquer)
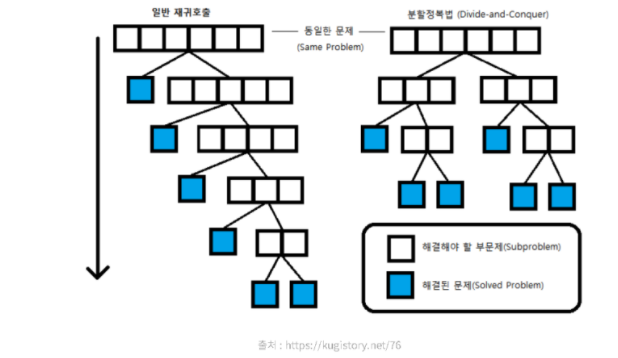
참고 블로그참고 블로그둘 이상의 부분 문제로 나눈 뒤 각 문제에 대한 답을 재귀 호출을 이용해 계산각 부분 문제의 답으로부터 전체 문제의 답을 계산함재귀 호출과 다른 점 -> 문제를 한 조각과 나머지 전체로 나누는 대신 거의 같은 크기의 부분 문제로 나누는 것1) Di
26.[Java] 정렬과 람다식
Java에서 배열을 정렬할 때는 Arrays.sort(배열)함수를 사용하면 된다오름차순 정렬내림차순 정렬내림차순 정렬하는 또 다른 방법첫 번째 인자 - 두 번째 인자 => 오름차순두 번째 인자 - 첫 번째 인자 => 내림차순