이 글은 Understanding kubernetes networking: pods와
한우형님께서 작성해주신 Diving Deep Into Kubernetes Networking: Docker와 Kubernetes 네트워크 분석을 공부하며 개인적으로 정리한 글입니다.또한, 쿠버네티스의 Pod 네트워크에 대한 내용을 주로 다루기 위해 도커의 컨테이너 네트워크와 관련된 내용을 생략하였습니다. 관련 내용은 이전 포스팅(도커 네트워크 (Docker Network: Under the Hood), 도커 네트워크 (Docker Network Overview))을 참조해주시면 감사하겠습니다.
[Kubernetes] Understanding kubernetes networking: pods
Pods
Pod이란 동일한 호스트에서 네트워크 스택, 볼륨등을 공유하는 컨테이너의 집합으로, 쿠버네티스 어플리케이션을 구성하는 기본 단위이다. Pod 안에 속한 컨테이너들은 네트워크 스택을 공유하기 때문에, loopback을 통해 서로와 통신할 수 있다.
예를 들어, 웹 어플리케이션 컨테이너와 redis 컨테이너를 하나의 팟에서 생성할 경우, 웹 어플리케이션 컨테이너에서 loopback 주소(127.0.0.1)의 redis의 기본 포트(6379)로 접근하면 redis 프로세스와 통신이 가능하다. 이를 통해, 하나의 Pod에는 기능적으로 긴밀하게 연결(통신)된 있는 여러 개의 컨테이너가 함께 실행될 수 있다.
Pod은 어떻게 네트워크 스택을 공유할까?
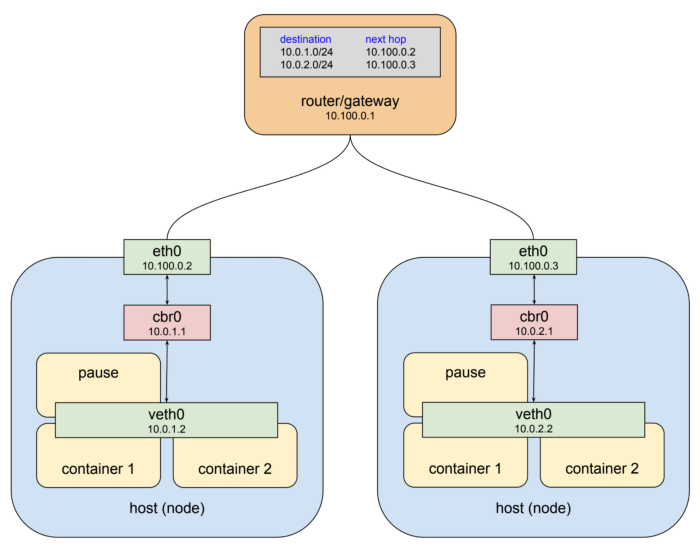
결론부터 이야기하면 네트워크 스택을 공유한다는 말은, 하나의 팟에 속한 모든 컨테이너는 하나의 네트워크 네임스페이스에 속하는 것을 의미한다.
쿠버네티스에서 새로운 Pod이 생성될 때에는 항상 내부적으로 Pause Container가 함께 생성된다. Puase Container는 이름 그대로 아무 작업도 처리하지 않는다. 쿠버네티스는 이 컨터이너를 이용하여 네트워크 네임스페이스를 생성하고, Pod 안의 모든 컨테이너가 Pause Container의 네트워크 네임스페이스를 공유하도록 한다. 이를 위해 쿠버네티스는 Pod 네트워크로 Containerd-Defined Network를 사용한다.
Network Plugin Interface
앞서, Pause Container를 이용해 컨테이너들이 같은 Pod에 있는 다른 컨테이너와 통신할 수 있다는 것을 살펴보았다. 그러나, 각각의 Pod의 네트워크가 연결되어 있지 않기 때문에 Pod 사이의 통신이 불가능하다. 쿠버네티스에서는 Pod Network가 의무적으로 갖춰야 하는 인터페이스인 NetworkPlugin Interface를 제공한다. 네트워크 플러그인이 갖추어야 할 조건은 다음과 같다.
- 모든 Pod은 고유한 IP를 갖는다.
- 같은 노드에 있는 모든 Pod은 서로 간에 통신이 가능해야 한다.
- 다른 노드에 있는 모든 Pod은 별도의 NAT 없이 통신이 가능해야 한다.
도커 네트워크에서 사용한 브릿지와 가상 이더넷(veth), 라우팅 테이블 개념을 응용하면 간단한 오버레이 네트워크(overlay network)를 구현하여 주어진 조건을 만족하는 네트워크 플러그인을 만들 수 있다. 이처럼 Pod 네트워크 구현을 위한 조건을 CNI(Container Network Interface)라고 하며, 이를 만족하는 구현체를 CNI 플러그인이라고 한다. 구현 방식에 따라 CNI 플러그인은 무수히 많이 존재할 수 있으며, 대표적인 구현체로는 리눅스 브릿지와 veth 쌍으로 구현한 kubenet이 있다.
Advanced CNI Plugin: Weave
오버레이 네트워크는 기본적으로 리눅수 브리지, veth, 라우터(혹은 라우팅 테이블)을 사용하여 구성된다. 그러나, Pod의 개수가 늘어남에 따라 라우팅 테이블에 의존하는 방식에는 한계점이 존재하게 된다. Weave에서는 각 노드에 패킷을 가로채서 라우팅 테이블을 거치지 않고 패킷을 직접 전달하는 Weave Agent를 배포하여 성능을 개선시켰다.
이 밖에도, CNI 플러그인은 다양한 구현체가 존재하며 대표적으로 flannel Calico, Weave 등이 있다.

Images from
한우형님의 기술 블로그
Kubelet
kubelet은 클러스터 노드에서 실행되는 프로세스이다. kubelet은 여러 경로를 통해 전달받은 PodSpec을 토대로 노드에 실제로 팟을 생성하는 역할을 수행한다. kubelet은 실행될 때,리--cni-bin-dir 옵션을 통해 CNI 바이너리의 위치를 입력받는다. kubelet은 해당 바이너리를 통해 네트워크 플러그인에 CNI 명령을 전달한다.
Kubernetes Service
앞서서 쿠버네티스에서 Pod의 네트워크가 어떻게 구현되는지 살펴보았다. 그러나, IP를 이용한 통신은 치명적인 한계를 갖는다. 바로, Pod의 IP 주소가 영구적이지 않다는 것이다. 쿠버네티스에서는 특정 Pod에 대한 영구적인 엔드포인트를 제공하기 위해 Service를 사용한다. Service는 삭제되기 전까지 영구적으로 유지되며, Pod은 Service를 통해 서로 다른 Pod에 접근할 수 있다. Service는 Pod의 label 정보를 기준으로 연결할 Pod을 찾기 때문에, 가변적인 Pod Ip에 영향을 받지 않는다.
Kubernetes Service 동작 방식: Kube-Proxy
쿠버네티스의 Service는 개별 노드에 위치한 Pod과 달리, 클러스터 전체에 공유되는 글로벌 자원이다. Service는 모든 노드에서 접근이 가능해야 하기 때문에, 각 노드는 kube-proxy라 불리는 데몬을 항상 실행한다. kube-proxy는 iptables(default mode)를 활용하여 netfilter의 각 체인에 NAT와 관련된 룰을 추가함으로써, Service IP 주소로 들어온 패킷을 어떤 방식으로 처리할지 모든 노드에 등록한다. 이 과정을 거치면, Service는 모든 노드에서 동일하게 접근 가능한 글로벌 자원의 기능을 충족한다.
Kubernetes DNS Server:
앞서 살펴본 예제들에서는 Pod과 Service가 IP 주소를 사용하여 통신을 하는 것으로 가정하였다. 그러나, IP 주소는 사람에게 익숙하지 않고 기억하기 어렵다. 따라서, 관리의 편의성을 위해 DNS를 활용하여 IP 주소를 의미있는 이름으로 변환할 수 있다. 쿠버네티스에서 도메인 이름은 다음과 같은 규칙을 따른다.

Images from
한우형님의 기술 블로그
쿠버네티스에서는 CoreDNS를 사용하여, DNS 서비스를 제공한다. CoreDNS는 kube-system 네임스페이스에서 Deployment의 형태로 짝을 이루는 kube-dns Service와 함께 배포된다. 생성된 모든 Pod은 /etc/resolv.conf 파일에 kube-dns 서비스의 IP 주소를 가지고 있어서, Pod에서 실행 중인 프로세스는 도메인 명으로 접근할 때, 해당 파일을 확인하고 CoreDNS Pod에 요청하여 실제 주소를 가져온다.
References
Understanding kubernetes networking: pods
[번역] 쿠버네티스 네트워킹 이해하기#1: Pods
Diving Deep Into Kubernetes Networking: Docker와 Kubernetes 네트워크 분석
