이글은
조대협님의 "HBase 와 구글의 빅테이블 #1 아키텍쳐" 글과,Nosey님의 Column Oriented DBMS란? 읽고 공부한 내용을 정리한 글입니다.
칼럼형 데이터베이스
칼럼형 데이터베이스란 일반적으로 잘 알려진 로우형 데이터베이스와 대비되는 용어로, 실제 물리적 데이터를 컬럼을 기준으로 묶어서 저장/압축/집계하는 데이터베이스이다. 대표적으로 Google Bigtable, HBase등이 있다.

로우형 데이터베이스 저장 방식
로우형 데이터베이스에서는 데이터가 파일에 로우들이 일렬로 나란히 저장되는 것이 특징이다. 따라서, 하나의 행(레코드)를 추가하는 것은 매우 간단하다. 반면, 특정 컬럼의 값을 읽기 위해서는 오프셋을 계산하며 모든 데이터를 순차적으로 읽어야 한다는 단점이 있다.
반면, 컬럼형 데이터베이스는 컬럼을 기준으로 데이터가 저장된다. 따라서, 특정 컬럼에 대한 연산에 최적화되어 있으며 압축 효율이 높다는 장점이 있다. 반면, 하나의 데이터 로우를 읽거나 쓰기 위해서는 모든 컬럼 패밀리 파일에 데이터를 읽고 써야하기 때문에, 읽기/쓰기 작업에 대한 효율성이 떨어진다.
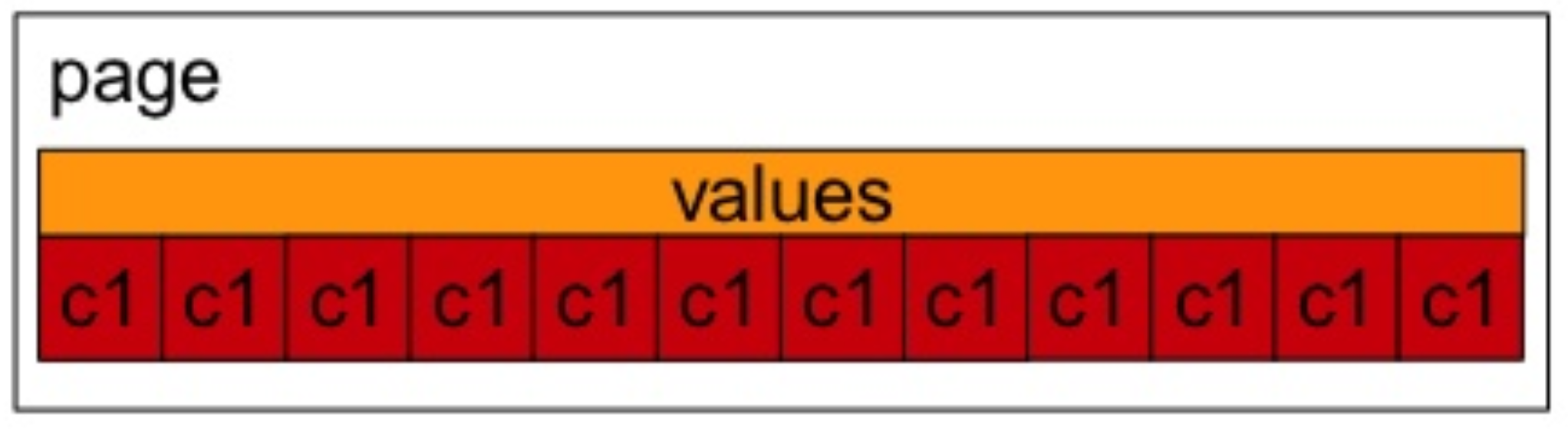
컬럼형 데이터베이스 저장 방식
보다 구체적으로, 컬럼형 데이터베이스에서는 유사한 성격의 컬럼을 묶은 컬럼 패밀리를 기준으로 파일을 분리하여 저장한다. 각각의 데이터는 SSTable에 RowKey(Primary Key와 유사)를 기준하여 정렬하여 Timestamp와 함께 저장된다. 실제 물리적으로 데이터가 저장될 때에는 아래와 같이 컬럼 패밀리를 구성하는 각각의 컬럼(name, address, gender) 마다 하나의 레코드가 생성된다.
데이터가 추가될 때에는 기존에 작성한 데이터를 수정하는 것이 아니라, 새로운 레코드를 추가한다. 잦은 업데이트로 데이터가 중복되어 쌓이는 것을 방지하기 위해, 오래된 데이터를 제거하는 compact 작업도 주기적으로 수행된다
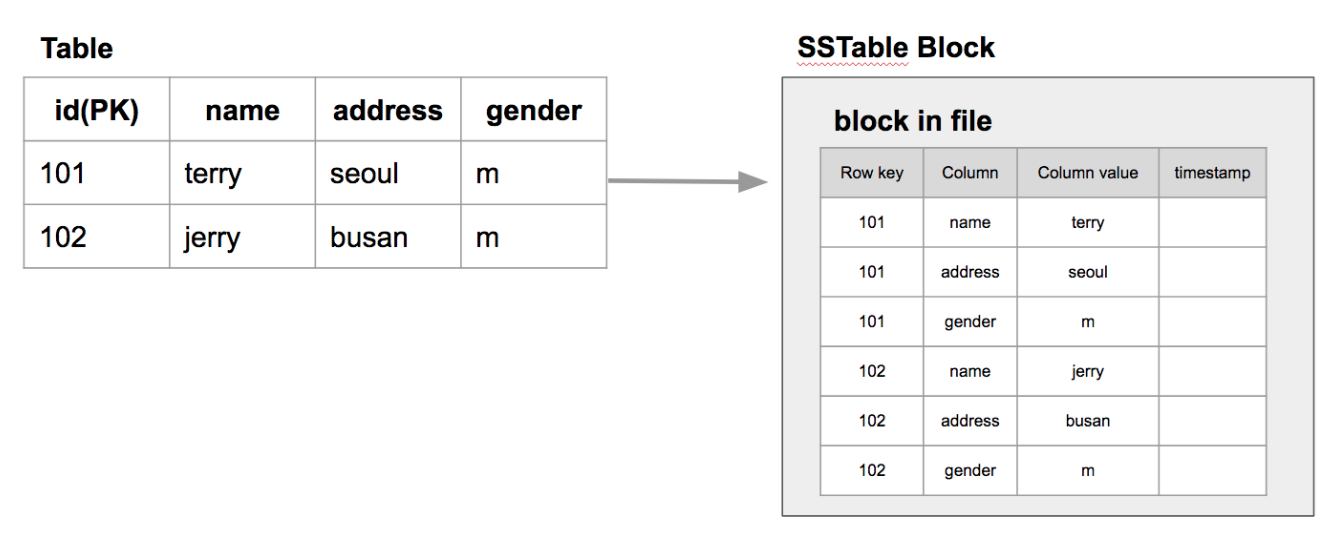
SSTable 예시
Bigtable
빅테이블은 2015년 구글에서 발표한 NoSQL계열 컬럼형 데이터베이스로, HBase와 같은 컬럼형 데이터베이스의 원조격으로, 컬럼 패밀리 모델 등의 개념은 Bigtable에서 시작되었다고 볼 수 있다. Bigtable은 앞서 언급한 컬럼형 데이터베이스의 장점을 모두 갖고 있으며, 내부 아키텍처를 활용하여 단점을 개선하였다.
Bigtable의 아키텍처는 아래와 같다.
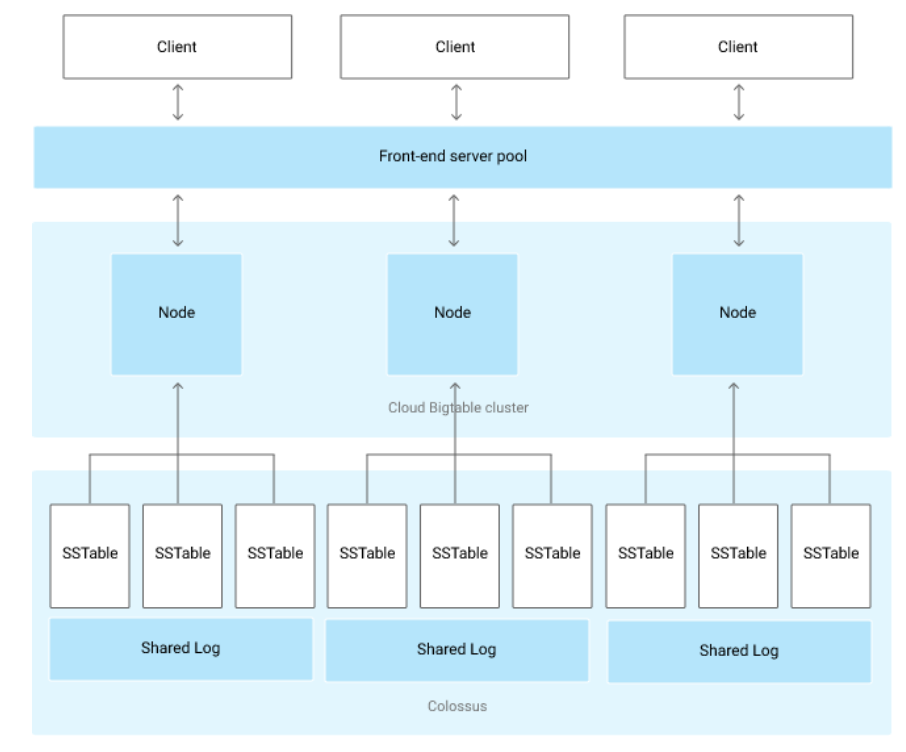
기본적으로 모든 데이터는 RowKey를 기준으로 분리된 데이터 노드에 SSTable이라 불리는 파일 형태로 저장된다. 컬럼형 데이터베이스는 컬럼에 대한 연산 및 압축 효율이 뛰어나지만, 데이터를 쓰는 과정이 비효율적이라는 단점이 있었다. Bigtable은 tablet log와 memtable를 활용하여 읽기/쓰기 요청을 최적화하였다.
tablet log는 RDBMS의 백로그와 유사한 개념으로, 데이터베이스에 대한 쓰기 요청을 기록한다. 다음으로 memtable이라 불리는 메모리 기반 중간 저장소에 캐싱한 후, 쓰기 요청에 대한 응답을 전송한다. 데이터는 memtable이 비워지는 시점에 물리적으로 저장되지만, tablet log를 기반으로 복구가 가능하기 때문에 쓰기 요청에 대한 성능을 개선하였다.
핫스팟
두 개 이상의 노드로 구성된 경우, 데이터는 RowKey를 기반으로 샤딩이 이루어진다. 따라서, 요청이 특정 RowKey 범위에 몰리게 되는 경우, 노드별로 분산이 잘 이뤄지지 않고 특정 노드에 많은 부하가 걸리게 되는데 이러한 현상을 HotKey, 데이터가 몰리는 Rowkey 범위를 HotSpot이라고 부른다. HotSpot 문제를 해결하기 위해서는 적절한 해쉬 알고리즘 혹은 UUID를 활용하여 RowKey를 골고루 퍼트려 주는 것이 중요하다.
References

큰 도움이 되었습니당 ~~!!