Index

Index란?
Index를 한글로 직역하면 색인으로 번역된다. 간단하게, 인덱스는 책의 목차 혹은 책 중간에 꽂는 책갈피 정도로 이해할 수 있다. 목차나 책갈피를 사용하면 책의 많은 페이지 중에서 원하는 지점을 빠르고 쉽게 찾아낼 수 있다. 데이터베이스에서 인덱스도 동일한 기능을 수행한다. 인덱스는 무수히 많은 데이터가 저장된 데이터베이스에서 원하는 데이터를 쉽고 빠르게 찾기 위한 책갈피로 사용된다.
사용 목적
인덱스는 데이터베이스에 대한 읽기/쓰기 성능과 직결된다. 책의 목차나 책갈피를 사용하면 빠르게 원하는 페이지를 찾아낼 수 있다. 그러므로, 적절한 인덱스 사용은 데이터베이스에 대한 읽기 성능을 크게 향상시킬 수 있다. 그러나, 책의 목차가 과도하게 길어지는 경우를 떠올리면 과도한 인덱스의 사용이 꼭 긍정적인 결과를 가져오지 않는다는 것을 짐작할 수 있다. 일반적으로 인덱스는 SELECT 쿼리 성능을 향상시키기 위해 INSERT, UPDATE, DELETE 등의 데이터 조작 쿼리 성능을 일부 포기하는 형태로 사용된다.
B+- Tree
B+ Tree와 B- Tree는 일반적으로 데이터베이스에서 인덱스를 저장하기 위한 자료구조로 널리 사용된다. 이 글에서는 B- Tree에 대한 내용을 다루었다. B- Tree의 주요 특징은 다음과 같다. B- Tree는 내부적인 정렬 알고리즘을 기반으로 빠르게 원하는 데이터를 찾을 수 있도록 설계된 자료구조이다. B- Tree에 대한 보다 자세한 설명은 링크를 참조하시면 좋을 것 같습니다.
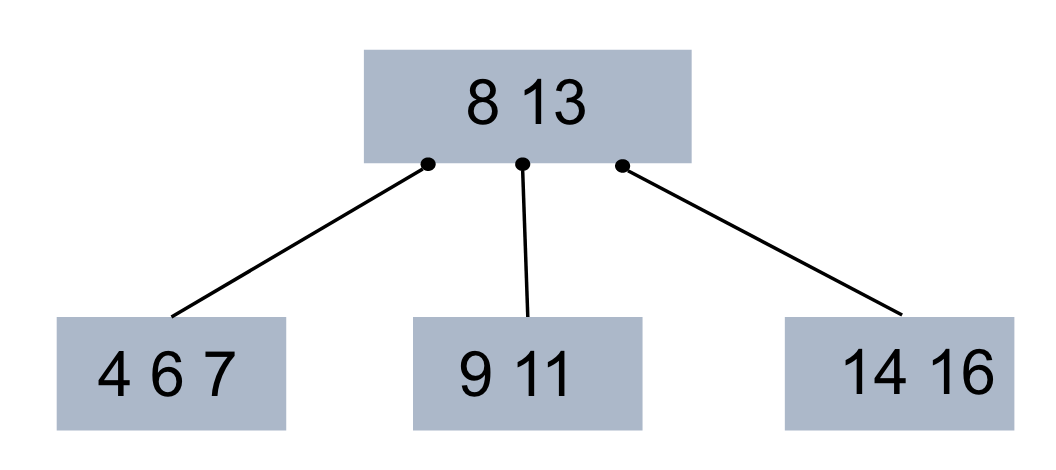
- 2개 이상의 자식 노드를 가질 수 있다. 자식 노드 수는
부모 노드에 저장된 데이터 수 +1개 이다. - 내부적으로 배열 형태로 데이터를 저장하며, 데이터는 항상 정렬되어 있다.
- 부모 노드의 데이터를 기준으로 작은 값은 왼쪽 자식 노드에, 큰 값은 오른쪽 자식 노드에 저장된다.
- 잎사귀 노드는 모두 같은 레벨에 위치해야 한다.
B+- Tree를 사용하는 이유
데이터베이스 쿼리는 크게 Exact Match와 Range로 나뉜다. 일반적으로 데이터베이스에서 인덱스를 저장하기 위해 B- Tree가 주로 사용된다. 하지만, 이는 데이터베이스에서 주로 사용되는 쿼리 성격에 따라 달라질 수 있다.
해쉬형 자료구조는 Exact Match Query과 같이 조건을 만족하는 특정 레코드를 찾는 작업에 최적화되어 있다. 그러나, 해쉬형 자료구조는 데이터 정렬을 보장하지 않는다. 해쉬형 자료구조는 Range Query를 처리하기 위해 모든 데이터를 탐색해야 한다는 단점이 있다. Redis와 같은 in-memory key-value 데이터베이스에서는 내부적으로 secondary index를 sorted set과 같이 정렬된 해쉬형 자료구조를 통해 저장한다.
B- Tree는 내부적으로 저장된 인덱스의 정렬을 보장하며 이진검색트리와 유사하게 데이터의 값을 비교하여 어떤 자식 노드를 탐색해야 하는지 빠르게 선택할 수 있다. Exact Match Query에서도 트리의 높이에 해당하는 O(log(n))이라는 준수한 성능을 보장한다. B- Tree는 특히 Range Query에서 강점을 보인다. B- Tree는 내부적으로 정렬상태를 유지하므로 지정된 범위에 속하는 데이터를 빠르게 탐색할 수 있다.
주의점
인덱스는 INSERT, DELETE, UPDATE 쿼리 성능을 악화시킬 수 있다.
인덱스는 데이터 조작 시, 추가적인 오버헤드를 발생시킨다. 데이터베이스에 새로운 데이터가 추가(INSERT)되면 인덱스를 생성/저장하는 과정이 추가로 발생한다. 데이터를 삭제(DELETE)할 때에는 인덱스 자료구조 내부의 정렬 상태를 보존하기 위해 인덱스를 제거하지 않고 사용하지 않는 상태로 전환한다. 즉, 데이터를 삭제하여도 인덱스는 여전히 남아있는 상태이다. 데이터를 수정(UPDATE)하는 경우에는 INSERT와 DELETE에서 발생하는 문제가 동시에 발생한다. 수정 작업은 내부적으로 새로운 데이터를 추가하고 기존 데이터를 삭제하는 방식으로 이뤄지기 때문이다.
인덱스를 생성하기 위한 데이터는 넓게 분산되어 있어야 한다.
인덱스는 Exact Match Query와 Range Query를 최적화하기 위해 사용된다. 극단적으로, 모든 레코드가 동일한 인덱스 칼럼 값을 갖는다면 인덱스를 생성하는 의미가 퇴색된다. 인덱스의 사용 목적을 극대화하기 위해서는 인덱스를 생성하는 칼럼의 데이터가 고유한 값을 가질 때 유용하다.
References
B-Tree 개념 정리
개념 정리 - (9) 데이터베이스 편
Interview Question for Beginner
