이글은 아래의 글들을 읽고 공부한 내용을 정리한 글입니다.
조대협님의 ZooKeeper란 무엇인가?
TOM님의 [Algorithm] ZooKeeper의 이해
슭님의 [ZooKeeper] (1) ZNode - ZooKeeper가 data를 저장하는 방법.
ZooKeeper란?
ZooKeeper는 분산 시스템을 구성하기 위해 필요한 분산 합의 및 데이터 복사 등의 과정을 효율적으로 처리하기 위해 사용되는 분산 코디네이션 서비스이다.
Apache 재단의 프로젝트는 관례적으로 동물 이름을 사용한다. Zookeeper의 사전적 의미는 사육사로, Apache의 주요 프로젝트들을 관리하기 위한 프로젝트 정도라고 할 수 있다.
ZooKeeper 아키텍처
ZooKeeper는 다음과 같은 아키텍처를 가지고 있다.
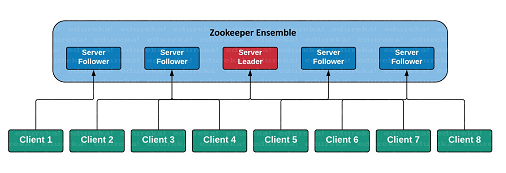
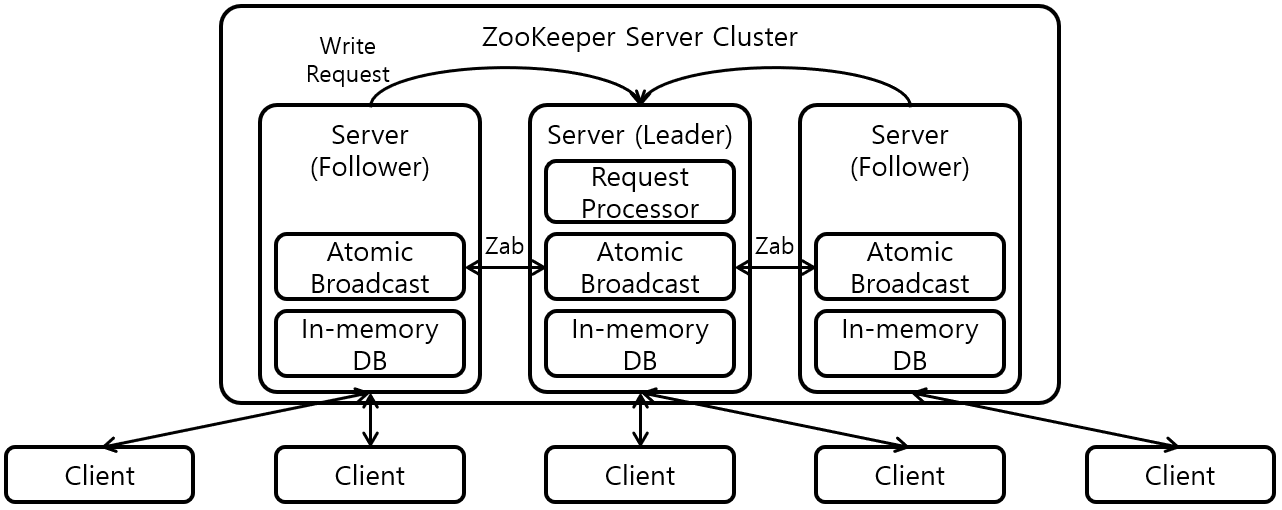
ZooKeeper는 기본적으로 복수 개의 ZooKeeper 서버의 집합인 Ensemble로 구성된다. Ensemble은 leader-follower 구조를 사용하며, Leader가 Follower에게 동기화를 위한 명령을 내리게 된다.
Quorum
Leader가 새로운 트랜잭션을 수행하기 위해서는 자신을 포함하여 과반수 이상의 서버의 합의를 얻어야 한다. 과반수의 합의를 위해 필요한 서버들을 Quorum이라고 한다. Ensemble을 구성하는 서버의 수가 5개라면, Quorum은 3개의 서버로 구성이 된다.
트랜잭션 처리
ZooKeeper에서 트랜잭션 처리는 아래의 과정을 거쳐 이뤄진다.
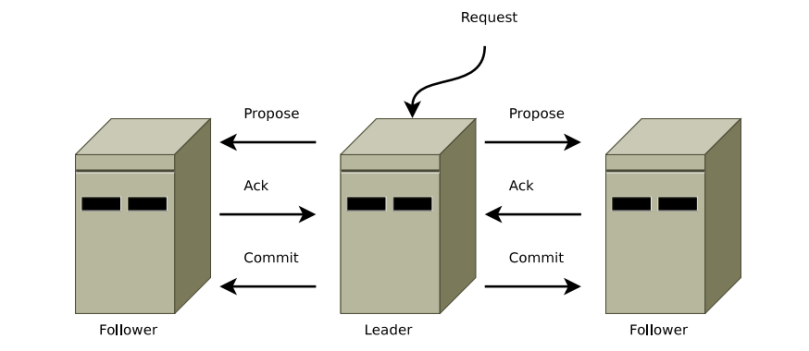
1. Leader에게 Request 전달
새로운 트랜잭션 요청이 Follower에게 도착하였을 경우, Follower는 Leader에게 요청을 전달한다.
2. Propose
Propose는 Leader가 Quorum을 구성하는 서버들에게 트랙잭션을 수행해도 되는지 여부를 요청하는 과정을 의미한다.
3. Ack
Quorum을 구성하는 서버들은 Leader로 부터 Propose 요청을 받으면, 트랙잭션을 수행해도 된다는 Ack 응답을 Leader에게 전송한다.
4. Commit
모든 Quorum으로 부터 Ack를 받으면, Leader는 트랙잭션을 처리하라는 Commit 명령을 broadcast 형태로 모든 Follower에 전파한다. ZooKeeper에서는 Commit 명령을 전달할 때, ZAB(ZooKeeper Atomic Broadcast) 알고리즘을 사용한다. Atomic Broadcast는 broacast 방식 중 하나로, 멀티 프로세스 시스템에서 모든 프로세스에게 동일한 순서로 메시지가 전달된다는 것을 의미한다.
이러한 과정을 도식화한 그림은 아래와 같다.
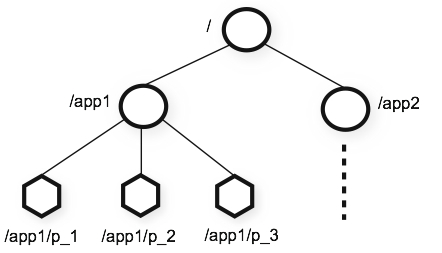
ZooKeeper 데이터 모델
ZooKeeper에서 모든 데이터는 디렉토리 구조를 기반으로 znode라 불리는 key-value 타입의 데이터 저장 객체의 형태로 저장된다. znode는 일반적인 파일 시스템에서 하나의 파일에 대응된다고 볼 수 있다. 이를 도식화한 그림은 다음과 같다.
ZNode
znode는 ZooKeeper가 데이터를 저장하기 위해 사용하는 가장 작은 단위의 데이터 저장 객체이다. ZooKeeper는 빠른 분산처리를 위해 모든 znode를 메모리에 저장한다. 일반적인 데이터베이스나 파일시스템과 달리, ZooKeeper는 분산 코디네이션을 위한 데이터만을 저장한다. 따라서, 메모리에 올리기 위한 부담이 적다. znode의 크기 또한, 최대 1MB로 제한적이다.
znode는 메모리에 저장되기 때문에 서버가 종료되면 사라지지만, ZooKeeper는 transaction log를 따로 저장하기 때문에, 데이터 복구가 가능하다.
znode는 저장할 데이터의 성격에 따라 크게 3가지 종류로 나뉜다.
Persistent Node
Persistent znode에 저장된 데이터는 영속성이 부여된다.
Ephemeral Node
노드를 생성한 클라이언트와의 세션이 끊어지면 삭제되는 데이터가 저장된다.
Sequence Node
생성 시점에 10자리의 sequence number을 차례로 부여받아 post-fix로 사용하는 znode이다. Sequence는 atomic하게 증가하기 때문에, 동일한 이름의 znode를 생성하여도 부여받는 순번이 달라 결과적으로 다른 이름을 갖게 된다. 주로 분산락을 구현하는데 활용된다.
ex) /app1/myapp1을 이름으로 갖는 Sequence Node를 2개 생성한 경우, /app1/myapp1-0000000001, /app1/myapp1-0000000002와 같이 순번에 따라 다른 이름을 갖는다.
Watcher
ZooKeeper는 znode에 변화를 감지할 수 있는 Watcher를 클라이언트가 설정할 수 있도록 한다. Watcher는 자신이 감시하고 있는 znode에 수정이 발생하였을 때, 클라이언트로 callback 호출을 전송하는 알림 기능을 제공한다.
ZooKeeper 활용 방안
앞선 내용을 정리하면, ZooKeeper는 여러 서버에 분산되어 있는 znode를 관리하기 위한 서비스이다. znode는 메모리에 저장되어 빠른 속도를 보장하지만, 크기에 제한을 갖는다. 그러므로, ZooKeeper는 여러 클러스터에 공유되어야 하는 설정 값이나 리소스 상태 정보등을 저장할 때 매우 유용하다.
Queue
Watcher와 Sequence Node의 특성을 활용하면 간단한 큐를 만들 수 있다.
서버 설정 정보
클러스터를 구성하는 서버의 설정 정보에 수정이 발생한 경우, ZooKeeper를 활용하여 분산 합의를 통해 안전하게 수정 내역을 반영할 수 있고 Watcher를 활용하여 수정 사항을 전파하는 것도 가능하다.
클러스터 상태 정보
Ephemeral Node는 클라이언트와 세션이 끊어지면 데이터가 삭제된다는 특성이 있다. 따라서, 클러스터를 구성하는 모든 서버의 상태 정보를 Ephemeral Node에 저장하면, 서버와의 연결이 끊어진 경우 해당 데이터가 삭제된다. 이를 통해, 실시간으로 클러스터 상태 정보를 업데이트 할 수 있고, 응용하면 Leader를 선출하는 voting algorithm에서도 활용할 수 있다.
