

자료구조란 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케하는 자료의 조직, 관리, 저장을 뜻한다.
malloc과 포인터 복습
int main(void)
{
int *x;
int *y;
x=malloc(sizeof(int));
*x=42;
*y=13;
}위 main 함수 코드에는 문제가되는 부분이 있다.
*y=13;y는 포인터로만 선언되었을 뿐, 어디를 가리킬지 정의되지 않았는데 13이라는 값을 저장하고 있다. 초기화되지 않은 포인터는 쓰레기 값(랜덤한 주소)을 가지고 있는데, 쓰레기 값이 가리키는 메모리 주소에 접근하는 경우 예기치 못한 오류가 발생할 수 있다.
포인터 뿐 아니라 변수의 값을 초기화 시키지 않으면 그 변수에는 쓰레기 값이 존재하게 되므로 모든 변수는 초기화를 꼭 해주어야 한다.
배열의 크기 조정하기
배열의 크기를 키우려면 어떻게 해야할까? 단순하게 생각하면 현재 배열이 저장되어 있는 메모리 위치 옆에 메모리를 더해 사용하면 될 것 같지만, 실제로는 이미 다른 데이터가 담겨있을 확률이 높다.
따라서 새로운 공간에 원하는 크기의 메모리를 다시 할당하고 기존 배열의 값들을 하나씩 옮겨줘야 한다. 이 과정은 O(n), 배열의 크기만큼의 실행시간이 소요될 것이다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
//정수에 대한 포인터 list를 선언하고 3개의 int자료형이 들어갈만큼 메모리 할당
int *list = malloc(3 * sizeof(int));
//malloc은 공간 할당 불가 시 NULL을 반환, 포인터가 잘 선언되었는지 확인
if(list == NULL)
{
return 1;
}
//list 배열의 각 인덱스에 값 저장.
list[0] = 1;
list[1] = 2;
list[2] = 3;
//int 자료형 4개 크기의 tmp라는 포인터 선언과 메모리할당
int *tmp = malloc(4 * sizeof(int));
//메모리 할당할 때마다 NULL이 반환되었는지 확인
if(tmp == NULL)
{
return 1;
}
//list의 값을 tmp로 복사
for (int i = 0; i<3; i++)
{
tmp[i] = list[i];
}
//tmp배열의 네 번째 값 저장
tmp[3] = 4;
//list의 메모리 해제
free(list);
//list가 tmp가 가리키는 곳을 가리키도록 지정
list = tmp;
//새로운 배열 list의 값 확인
for (int i = 0; i<4; i++);
{
printf("%i\n", list[i]);
}
//list 메모리 초기화
free(list);메모리를 할당하고, 값을 옮기고, 메모리를 초기화(free)하는 작업은 사실 realloc이라는 함수를 이용해 더욱 간단하게 수행할 수 있다.
realloc은 메모리리를 새로 할당한다는 뜻으로 이미 할당받은 기존 메모리 덩어리를 새롭게 가져와 새롭게 설정된 크기로 바꾸는 작업을 한다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *lsit = malloc(3 * sizeof(int));
if (list == NULL)
{
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
int *tmp = realloc(list, 4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
list = tmp;
list[3] = 4;
for (int i = 0; i<4; i++)
{
printf("%i\n", list[i]);
}
free(list);
}realloc(이미 할당한 포인터 변수, 바꾸고 싶은 메모리크기);
realloc이 기존 배열에서 새로운 배열로 데이터를 복사해주기 때문에, 우리는 NULL이 반환되지 않았는지 체크하고, 추가하고싶은 값을 저장하기만 하면 된다.
연결 리스트: 도입
데이터 구조는 컴퓨어 메모리를 더 효율적으로 관리하기 위해 새로 정의하는 구조체이다. 데이터 구조 중 하나인 연결 리스트에 대해 알아보자.
연결 리스트는 각 인덱스의 메모리 주소에서 자신의 값과 함께 바로 다음 값의 주소(포인터)를 저장한다.
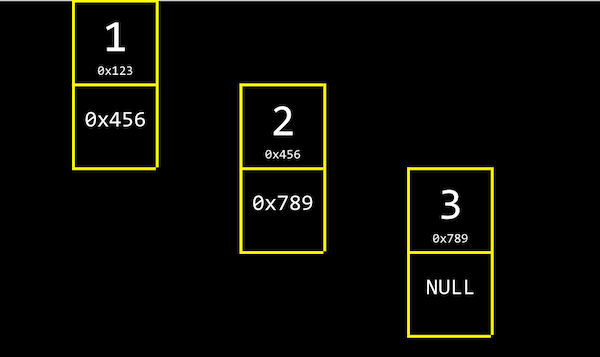
위 그림의 크기가 3인 연결 리스트에서 3은 다음 값이 없기 때문에 NULL(\0, 0으로 채워진 값)을 넣어 다음 값이 없다는 것을 나타낸다.
typedef struct node
{
int number;
struct node *next;
}
node;연결 리스트는 위 코드와 같이 구조체로 정의할 수 있다.
node라는 이름의 구조체는 숫자를 저장할 변수 number와 다음 노드를 가리킬 포인터 *next 가 저장되어 있다.
(typedef struct node라고 'node'를 함께 명시해주는 것은 구조체 안에서 'node'를 사용하기 위해서이다.)
따라서 위 코드는 "이 자료구조의 모든 node에는 숫자와 포인터가 있다. 포인터는 node 구조체를 가리키도록 정의되어 있다"라고 말하는 것이다.
연결리스트: 코딩
#include <stdio.h>
#include <stdlib.h>
//node 구조체 정의
typedef struct node
{
//정수형 값이 저장되는 변수를 name으로 지정
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정
struct node *next;
}
node;
int main(void)
{
// 연결 리스트의 첫 번째 node를 가리킬 포인터 정의
// 현재는 아무 것도 가리키지 않으므로 NULL로 초기화
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 임시로 n에 저장
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1을 저장 “n->number”는 “(*n).numer”와 같음
// 즉, n이 가리키는 node의 number 필드를 의미
n->number = 1;
// n 다음에 정의된 node가 없으므로 NULL로 초기화
n->next = NULL;
// list가 새로 만든 node n을 가리키도록 함
list = n;
// 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 umber와 next 값 각각 저장
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node
//이 node의 다음 node를 n 포인터로 지정합니다.
list->next = n;
// 세 번째 노드 생성
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
list->next->next = n;
// 각 node를 순서대로 방문하며 number값 출력
// 마지막 node의 next에는 NULL이 저장되어 있을 것이기 때문에 이 것이 for 루프의 종료 조건
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// 메모리를 해제. list에 연결된 node들을 처음부터 방문하면서 free해줌.
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}연결리스트: 시연
연결 리스트는 새로운 값을 추가할 때 다시 메모리를 할당하지 않아도 된다. 동적으로 추가가 가능한 것이다. 하지만 배열과 달리 임의 접근(random access)을 할 수 없으며, 원하는 위치까지 각 node들을 따라 이동해야 한다.
따라서, 연결 리스트에 값을 추가하거나 검색하는 경우 연결 리스트의 크기가 n일 때 그 실행 시간은 O(n)이 된다. 정렬되어 있는 배열의 경우 이진 검색을 이용하면 O(log n)의 실행시간이 소요되기 때문에 배열에 비해 불리한 경우도 있다.
연결리스트: 트리
이번에는 '트리'라는 연결 리스트기반의 자료 구조를 알아보자.
트리에서의 노드들은 2차원적으로 연결되어 있다. 각 노드는 일정한 층에 속하고, 다음 층의 노드들을 가리키는 포인터를 가진다.
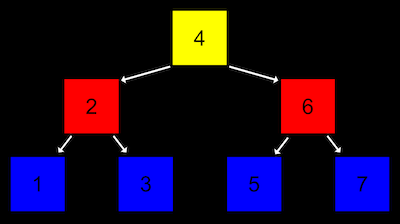
가장 높은 층의 트리가 시작되는 노드를 '루트'라고 한다. 루트가 가리키는 다음 층의 노드들은 '자식 노드'라고 한다.
위 그림의 트리를 구체적으로는 '이진 검색 트리'라고 하는데 일정한 규칙을 가지고 있다. 하나의 노드는 두 개의 자식 노드를 가지고, 왼쪽 자식 노드는 자신의 값보다 작고 오른쪽 자신 노드는 크다는 것이다.
따라서 이진 검색을 다시 수행할 수 있게되었으며, 포인터를 가졌기 때문에 연결리스트처럼 역동성도 가지고 있다.
하지만 좌우 균형이 다른 한쪽으로 치우친 트리의 경우 연결리스트와 큰 차이가 없으니 주의해야 하며, 두 개의 자식노드의 주소값을 저장해 메모리를 더 많이 사용하게 된다는 단점이 있다.
이진 검색 트리의 노드 구조체와 '50'을 재귀적으로 검색하는 이진 검색 함수를 구현해보자.
//이진 검색 트리의 노드 구조체
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 ‘true’ 반환
else {
return true;
}
}이진 검색 트리를 활용하였을 때 검색 실행 시간과 노드 삽입 시간은 모두 O(log n)이다.
해시 테이블
해시 테이블은 '연결 리스트의 배열'이다. 각 값들은 해시함수라는 맞춤형 함수를 통해 어디(바구니)에 담길지 결정된다.
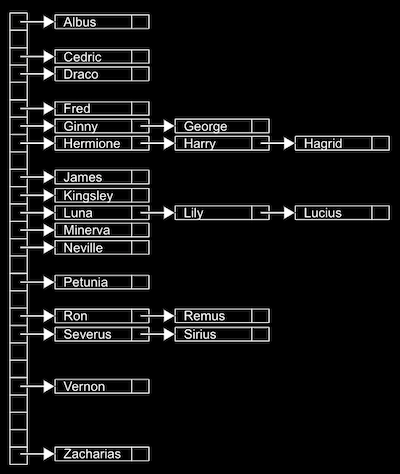
위 그림은 해시 함수가 '이름의 가장 첫 글자'인 경우 사람의 이름이 해시 테이블에 어떻게 저장되었느지 보여준다.
만약 해시 함수가 이상적이라면 각 바구니에는 단 하나의 값이 담겨 값을 검색할 때 O(1)이 된다. 하지만 최악의 경우에는 단 하나의 바구니에 모든 값들이 담겨서 O(n)이 될 수 있다.
(어떤 값을 넣으려 하는데 이미 무언가 들어있는 경우를 충돌이라고 한다.)
그렇기 때문에, 시간과 공간 사이의 균형을 찾아 이상적인 해시함수를 사용하는 것이 관건이다.
트라이
트라이는 트리와 배열의 조합이다. 기본적으로 '트리'형태이며 각 노드가 '배열'로 이루어진 자료구조이다.
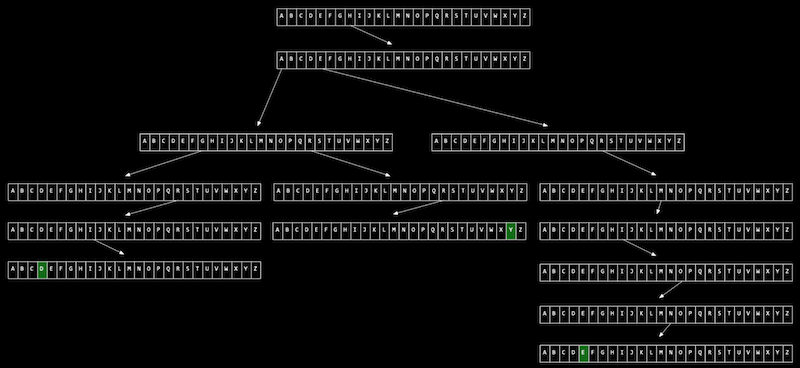
위 그림은 Hermione, Harry, Hagrid 세 문자열을 트라이에 저장한 것을 보여준다. 위 그림의 트라이에서 값을 검색하는데 걸리는 시간은 해당 문자열의 길이와 같다. 이름의 길이를 n이라고 했을 때, 검색 시간은 O(n)이지만, 대부분의 이름은 길어봤자 상수값이기 때문에 O(1)이나 마찬가지라고 할 수 있다.
트라이는 문자열을 저장하고 관리하기에 적합한 자료구조로 검색 엔진이나 사전의 자동완성기능 등에 사용할 수 있다. 직접 구현하기에는 난이도가 높다.
