

본 포스트는 boostcourse의 '모두를 위한 컴퓨터 과학 (CS50 2019)'를 바탕으로 작성되었습니다.
메모리 주소
16진수(Hexadecimal)
: 컴퓨터과학에서는 숫자를 16진수로 표현하는 경우가 많다. 데이터를 처리할 때 장점이 있기 때문이다.
16진수는 0~9,10은 A, 11은 B, ... , 15는 F를 대입한다. 알파벳의 경우 대소문자를 구별하지 않는다.
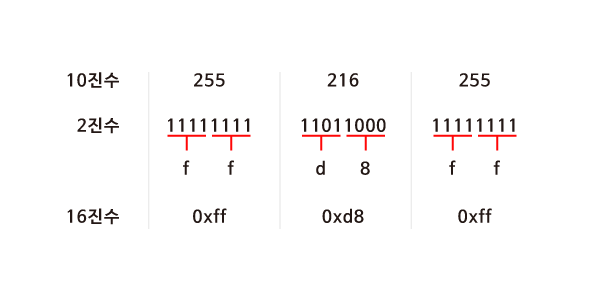
2의 4제곱이 16이기 때문에 2진수를 4bits씩 두 덩어리로 나눠보면 16진수로 표현할 수 있다는 걸 알 수 있다.
(앞에 0x를 붙이면 16진수, 0으로 시작하면 8진수로 인식한다. 물론 컴퓨터 내부적으로는 2진수 형태로 값을 저장한다.)
ASCII 코드를 각각 2진수와 16진수로 표현해보면 16진수의 유용성을 알 수 있다.
예를 들어 A는 2진수로 01000001이다. 16진수로는 0x41이다. 훨"씬 간단하게 표현할 수 있다. 또, 컴퓨터는 8개의 bit를 byte 단위로 표현하는데 2개의 16진수롤 1byte의 2진수로 변환되기 때문에 정보를 표현하기 더욱 유용하다.
(+만약 CS50을 16진수로 표현한다면 50을 세 가지 경우로 나누어 판단할 수 있다. 1)50을 오십이라는 하나의 숫자로 판단하는 경우, 2) 5, 0으로 각각의 숫자로 판단하는 경우, 3)각각 문자로 판단하는 경우. 이럴 때는 CS와 50을 따로 변수 처리하지 않아도 되도록 모두 문자로 판단하여 한꺼번에 처리하는 것이 효율적일 것이다.)
메모리 주소
변수를 선언하면 컴퓨터 메모리 속에 그 변수의 자료형에 따라 자리를 차지하며 저장된다. 이때 변수의 메모리상 주소를 받으려면 '&'라는 "피연산자의 주소 값을 반환하는 연산자"를 사용한다.
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%p\n", &n);
}위와 같은 코드를 실행하면 50이라는 int형 변수가 메모리 속 어디에 4byte를 차지하고 있는 지 알 수 있다. 이 때 돌려 받는 값을 '포인터 값'이라고 하는데, 16진수로 표현된 메모리 주소이다.
'*'을 사용하면 그 메모리 주소에 자리잡은 실제 값을 얻을 수 있다. '*'은 "~의 주소로 가줘"라는 의미로 생각하면 된다.
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%i\n", *&n);
}위 코드에서는 '&' 연산자로 먼저 n의 주소를 얻고, '*'연산자로 그 주소로 가 그곳에 위치한 값을 얻어와 출력하게 된다. 결국 50이라는 값이 출력되는 것이다.
포인터
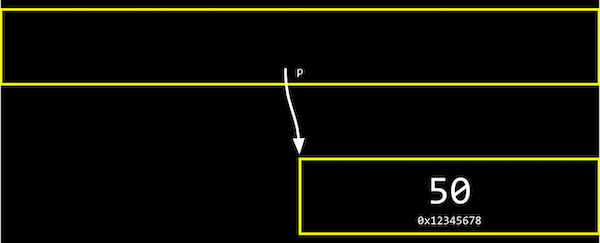
C에는 포인터라는 개념이 있어 변수의 주소를 쉽게 저장하고 접근할 수 있다. 포인터란 변수인데 저장되는 값이 주소다!
'*'연산자는 어떤 메모리 주소에 있는 값을 받아오는 것과 더불어 포인터 역할을 하는 변수(포인터 변수)를 선언할 수 있다. 선언할 때 사용하면 "이 변수는 포인터 변수이구나!"하고, 호출할 때 사용하면 "이 변수의 주소로 가서 값을 가져온다!"라고 생각하면 된다.
#include <stdio.h>
int main(void)
{
int n = 50;
int *p = &n;
printf("%p\n", p);
pintf("%i\n", *p);
}위 코드를 보면 먼저 정수형 변수 n에 50이라는 값을 저장하였다.
그리고 *p라는 포인터 변수에 &n이라는 값을 저장하였다. 앞서 '&'는 주소를 의미한다했으니 n의 주소값을 저장한 것이다. 앞에 int가 붙는 이유는 int타입의 변수를 가리키기 때문이다.
따라서 첫 번째 printf문에서는 포인터 p의 값(포인터를 처음 선언할 때만 ''을 붙이면 된다.)인 n의 주소를 출력하게 되며, 두 번째 printf문에서는 ''연산자를 통해 그 주소로 가게되어 값을 가져오기 때문에 포인터 p가 가리키는 변수 n의 값 50이 출력된다.
(첫 번째로 출력되는 주소값은 해당 데이터가 저장되어 잇는 블록의 '시작점' 주소이다.)
('*'의 역할이 두 가지라 헷갈릴 수 있는데, 계속 보다보면 이해가 조금씩 된다...)
사실, 16진수로 표현된 메모리 주소 값을 이용하는 경우는 거의 없으므로 추상적으로 포인터는 해당 변수를 "가리키고 있다"는 것으로 생각하면 된다.
(+포인터의 크기는 컴파일러의 bit에 따라 달라진다. 34bit 컴파일러는 32bit 주소로 이루어져있어 포인터의 크기가 4byte(32bit), 64bit 컴파일러는 8byte이다.)
문자열
CS50 라이브러리에서는 string이라는 자료형을 사용할 수 있었지만, 실제로 C에서는 존재하지 않는 자료형이다. string이 어떤 의미였는지 포인터를 통해 다시 생각해볼 수 있다.
문자열은 결국 문자(char)의 배열이다. 배열의 가장 마지막에는 '\0'이라는 0으로만 이루어진 바이트가 들어가 문자열의 끝을 표시한다. 컴퓨터에게 문자가 이제 끝이다라고 알려주는 것이다.
string s = "EMMA";그렇다면 결국 변수 s는 문자의 배열을 가리키는 포인터가 된다. 포인터에 저장되는 주소는 시작점의 주소라고 하였으니 문자열의 가장 첫 번째 글자인 s[0]의 위치를 가리키는 포인터이다.
이제 CS50 라이브러리 안에서 string 자료형이 어떻게 만들어졌는지 이해할 수 있다.
typedef char *stringtypedef는 새로운 자료형을 선언하는 것이다. string은 자료형의 이름이며 '*'가 붙었으니 포인터임을 알 수 있다. char가 앞에 붙어있으니 "문자에 대한 포인터구나~ 이 string은 문자의 주소가 되는 것이구나!"라는 것을 알 수 있다.
#include<stdio.h>
int main(void)
{
char *s="EMMA"; // char형 변수의 주소값을 저장하는 포인터 변수 s를 선언
printf("%s\n",s); //s가 가리키는 "EMMA"출력 (널 종단 문자를 만날 때까지 출력함)문자열 비교
배열은 메모리상에 나란히 저장 된다. 문자열도 배열이니 첫 번째 문자를 시작으로 메모리상에서 바로 옆에 줄 지어 저장될 것이다. 그렇기 때문에 가장 첫 번째 문자의 주소값부터 하나씩 주소값을 증가시키면 바로 옆에 있는 문자의 값에 접근할 수 있는 것이다.
#include<stdio.h>
int main(void)
{
char *s="EMMA";
printf("%p\n",s); // 문자열의 첫 값 "E"의 메모리 주소 출력
}사용자로부터 두 개의 문자열을 입력받고 두 문자열이 같은지 비교를 해야한다고 가정해보자.
#include<stdio.h>
#include<cs50.h> // string 자료형 사용을 위해 cs50라이브러리 포함
int main(void)
{
string s = get_string("s: ");
string t = get_string("t: ");
if (s == t)
{
printf("Same\n");
}
else
{
printf("Different\n");
}
}위 코드를 실행시킨다면 같은 단어를 입력한다해도 무조건 다르다는 "Differnet"가 출력될 것이다.
string 자리에 char *를 넣어보면 왜 이런 결과가 나오는 지 알 수 있다.
#include<stdio.h>
#include<cs50.h> // string 자료형 사용을 위해 cs50라이브러리 포함
int main(void)
{
char *s = get_string("s: ");
char *t = get_string("t: ");
if (s == t)
{
printf("Same\n");
}
else
{
printf("Different\n");
}
}get_string이 반환하는 것은 입력된 문자열이 아닌 그 문자가 저장된 메모리 공간의 첫 바이트의 주소이다. 즉 포인터를 반환하는 것이다. 두 문자열은 제각각 다른 곳에 저장되었기 때문에 주소가 달라 비교해보았을 때 무조건 다르다는 결과가 나온 것이다. 비교한 것은 두 변수의 주소(포인터)이니 말이다.
그렇기 때문에 s와 t를 비교하는 것이 아니라 1)s와 t가 가리키는 곳을 시작점으로 주소 값을 증가시키며 비교 하거나 2)새로운 변수에 복사하여 원본 문자를 하나씩 비교해야 한다.
문자열 복사
문자열을 다른 변수에 복사하려면 어떻게 해야 할까. 단순하게 생각해보았을 때는 그저 새로운 변수에 '=' 연산자를 사용하여 원하는 문자열이 담긴 변수로 정의하면될 것 같다.
#include<stdio.h>
#include<cs50.h>
#include<stdio.h>
int main(void)
{
string s = get_string("s: "); // 사용자는 emma를 입력한다 가정
string t = s; // string t를 s로 정의
t[0] = toupper(t[0]); // t의 첫 번째 문자를 toupper 함수로 대문자로 바꿈
printf("s: %s\n", s);
printf("t: %s\n", t);
}위 코드를 실행시켜 보면, 단순한 예상과 달리 s와 t 모두 "Emma"라고 출력된다.
string s에는 "emma"라는 문자열이 아닌 그 문자열의 메모리 주소가 저장되기 때문이다. 따라서 t에 복사된 것은 마찬가지로 "emma"를 가리키고 있는 포인터이고, t를 수정하면 t가 가리키는 "emma"의 값이 변경된다. s와 t 모두 같은 값을 가리키고 있으니 t를 통한 수정이 s에도 그대로 반영되는 것이다.
사실상 복사본이 아닌 하나의 데이터를 가리키는 두 개의 이름이 생겼다고 생각하면 된다.
문자열을 실제로 메모리상에서 복사할면 메모리 할당 함수인 malloc을 사용해야 한다. malloc은 정해진 크기만큼 메모리를 할당하는 함수이다.
(포인터 = malloc(크기); -> 크기 만큼의 메모리 일부분을 가져와 그 곳을 가리키는 포인터를 주는 것)
#include <cs50.h>
#include <ctype.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1); // malloc을 이용해 t를 정의(s문자열의 길이에 널 종단 문자(/0)에 해당하는 1을 더해 메모리를 할당)
// 루프를 돌며 s 문자열의 문자 하나 하나를 t에 복사
for (int i = 0, n = strlen(s); i < n + 1; i++)
{
t[i] = s[i];
}
t[0] = toupper(t[0]);
printf("s: %s\n", s);
printf("t: %s\n", t);
}위 코드를 실행시키면 첫 번째 printf 문에서는 s인 "emma"가 두 번째 printf에서는 t인 "Emma"가 의도대로 출력되는 것을 확인할 수 있다.
메모리 할당과 해제
malloc을 이용하여 메모리를 할당한 후에는 꼭 free라는 함수로 메모리를 해제시켜야 한다. 해제시켜주지 않는 경우 메모리에 저장한 값이 쓰레기 값으로 남아 메모리 용량이 낭비되는 '메모리 누수'현상이 일어난다.
이러한 메모리 누수와 같은 메모리 관련 문제를 검사해주는 디버거 valgrind를 이용하여 아래 함수의 어떤 문제가 있는 지 알아보자.
#include <stdlib.h>
void f(void)
{
inf *x = malloc(10*sizeof(int)); //10개의 정수를 위한 40byte할당
x[10] = 0; // error1
}
int main(void)
{
f();
return 0;
}
// error 2위 코드에 대해 valgrind는 두 가지 에러를 발견해준다.
먼저 error1 지점을 보면 포인터 x는 10개의 int형 배열을 가리키기 때문에 인덱스 10은 정의되지 않았다. 그런데 만들어지지 않은 x[10]에 값을 할당하고 있으니 '버퍼 오버플로우'가 발생한 것이다.
(배열의 인덱스는 0부터 시작하므로 인덱스 10은 11번째 인덱스를 의미한다. 메모리나 메모리 배열을 다룰 때 공간을 넘어 접근하는 경우 오버플로우라고 한다.)
또 다른 에러는 '메모리 누수'이다. x라는 포인터를 통해 할당한 메모리를 해제하기 위해 free(x)라는 코드를 추가하여 해결할 수 있다.
메모리 교환, 스택, 힙
#include <stdio.h>
void swap(int a, int b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(x, y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}위 코드대로 출력해보면 의도와 달리 x와 y값이 바뀌지 않고, 첫 번째 pritf문과 두 번째 printf문이 똑같이 출력된다.
문제의 이유는 swap 함수가 교환한 것이 x, y 자체가 아닌 함수 내에 새롭게 정의된 a,b라는 것에서 발견할 수 있다. a와 b는 x와 y의 값을 가지고 서로 다른 메모리 주소에 저장된다.
그런데 메모리 안에는 데이터가 저장되는 구역이 나누어져 있다.

- 위 쪽 머신 코드 영역에는 프로그램을 실행할 때 clang이 컴파일한 0과 1(머신코드)가 저장된다.
- 그 아래에는 프로그램 내 공통적으로 쓰여지는 값인 전역변수나 정보가 저장된다.
- 힙 heap 영역은 메모리를 할당받을 수 있는 영역으로 malloc으로 할당된 메모리의 데이터가 저장되고 아래 쪽으로 쌓여나간다.(런 타임 때 크기가 결정되는 동적인 영역)
- 스택 stack 영역에는 함수와 관련된 것들이 저장되며 위로 쌓여나간다.(컴파일 타임 때 크기가 결정)
(위와 같이 메모리 영역을 구분하게 되면 각 영역의 특성에 맞게 효율적으로 관리할 수 있고 중첩되어 프로그램의 중요한 부분이 침범되는 경우를 예방할 수 있다.)
데이터 구역을 바탕으로 다시 생각해보자. a, b, x, y, tmp 모두 함수와 관련된 변수로 스택 영역에 저장될 것이다. 하지만 그 안에서도 서로 다른 위치에 저장된다. 따라서 a와 b를 바꾸는 것은 x와 y를 바꾸는 것에 영향을 미치지 못 한다.
이를 해결하기 위해 main 함수에서 x와 y의 값을 전달하는 것이 아니라 x와 y의 주소를 알려주면 swap 함수가 그 주소로 가서 값을 바꿀 수 있다.
#include <stdio.h>
void swap(int a, int b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(&x, &y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int *a, int *b)
{
int tmp = *a; // a가 가리키는 값을 tmp에 저장
*a = *b; // b가 가리키는 값을 a에 저장
*b = tmp; // tmp의 값을 b가 가리키는 주소에 저장
}파일 쓰기
지금까지 사용한 get_int나 get_string같은 사용자에게 입력을 받는 함수는 어떻게 구현된 것인지 멤리 교환, 스택의 정의와 함께 알아보자.

앞서 본 메모리 구조를 보면 heap 영역과 stack 영역은 서로 침범할 수 있다는 것을 알 수 있다. 이를 힙 오버플로우 또는 스택 오버플로우라고 일컫는다.
- Heap overflow : malloc을 계속 호출해서 너무 많은 메모리를 할당하면 메모리 속 다른 내용을 덮어 쓸 수 있다.
- Stack overflow : 함수가 시작점 없이 자기 자신을 계속 호출하면 stack이 넘칠 수 있다.
스택은 get_int나 get_string 같은 함수에서도 사용된다.
#include <stdio.h>
// get_int 함수
int main(void)
{
int x;
printf("x:");
// scanf 함수 : 사용자로부터 형식 지정자에 해당하는 값을 입력받아 저장
scanf("%i", &x); // x의 주소를 전달(그 주소로 직접 찾아가 값을 저장)
printf("x: %i\n", x);
}
// get_string 함수
int main(void)
{
char s[5]; // 사용자가 emma를 입력한다 가정하고 크기 5인 배열 선언
printf("s:");
scanf("%s", s); // clang 컴파일러는 문자 배열의 이름을 포인터처럼 다룸 -> s배열의 첫 바이트 주소를 넘겨 준 것
printf("s: %s\n", s);
}위 코드에서 유의할 점이 있다. get_int 함수를 만들 때는 scanf 함수의 변수가 스택 영역 안에 s가 저장된 주소로 찾아가 값을 저장할 수 있도록 x의 주소를 전달받았다. 하지만 get_string 함수를 만들 때는 s가 크기가 5인 배열로 정의되었고, 문자 배열의 이름은 포인터와 같다고 볼 수 있기 때문에 scanf에 s를 그대로 입력하였다.
아래의 코드는 사용자로부터 입력을 받아 파일에 저장하는 프로그램이다.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
// Open file
FILE *file = fopen("phonebook.csv", "a");
// Get strings from user
char *name = get_string("Name: ");
char *number = get_string("Number: ");
//Print(write) strings to file
fprintf(file, "%s,%s\n", name, number);
//Close file
fclose(file);
}fopen 함수는 이름 그대로 파일을 열어주는 함수이다. 첫 번째 매개변수로 경로를 포함한 파일의 이름을, 두 번째 매개변수로 파일을 어떤식으로 오픈할 것인지(r: 읽기, w: 쓰기, a: 덧붙이기) 입력받는다. 해당 파일을 가리키는 파일 포인터를 반환한다.
사용자에게 name과 number라는 문자열을 입력받고 fprintf함수를 이용하여 파일에 내용을 출력한다.
(fprintf(파일 포인터, 서식, 값1, 값2, ...); -> 성공하면 쓴 문자열의 길이를, 실패하면 음수를 반환한다.)
작업이 끝난 후에는 fclose함수로 파일에 대한 작업을 종료해줘야 한다.
이 과정을 통해 우리에게 익숙한 행렬 형태의 CSV파일로 데이터를 생성할 수 있다.
파일 읽기
파일의 내용을 읽어 JPEG 형식의 파일인지 검사해보자!
#include <stdio.h>
int main(int argc, char *argv[])
{
// 사용자가 프로그램을 실행할 때 두 단어를 prompt에 입력했는지 검사
if (argc != 2)
{
return 1;
}
// 사용자가 입력한 파일명(두 번째 문자열)으로 파일 오픈
FILE *file = fopen(argv[1], "r");
// 파일이 잘 열리지 않은 경우
if (file == NULL)
{
return 1;
}
// 크기가 3인 문자 배열을 만들고 file의 첫 3 바이트를 읽음
unsigned char bytes[3];
fread(bytes, 3, 1, file);
// 읽어들인 바이트가 각각 0xFF, 0xD8, 0xFF인지 확인
if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff)
{
printf("Maybe\n");
}
else
{
printf("No\n");
}
fclose(file);
}먼저 argc가 2가 아니라면(두 단어를 입력하지 않았다면) 파일명이 입력되지 않았거나 파일명 외의 다른 인자가 입력된 것이기 때문에 1(오류)를 리턴한다. argc가 2인 경우 프로그램이 진행된다.
사용자가 입력한 파일명(argv[1])을 읽기(r)모드로 연다.
fopen, malloc 등의 함수는 에러가 생기면 NULL을 반환하므로 NULL이 반환되었는 지 확인하고, 에러없이 잘 열렸으면 프로그램을 진행한다.
크기가 3인 문자 배열을 만들고, fread 함수로 파일의 첫 3바이트를 읽는다.
fread(배열, 읽을 바이트 수, 읽을 횟수, 읽을 파일)
읽은 바이트의 값이 각각 0xFF, 0xD8, 0xFF인지 확인하여 맞다면 Maybe를 아니라면 No를 출력한다. 파일득은 각각 고유한 포맷을 가지고 있다. 파일의 가장 처음에 위치하는 특정 바이트들로 파일 포맷을 구분할 수 있다. (JPEG 형식의 파일의 경우 이러한 파일 시그니처가 0xFF, 0xD8, 0xFF이다.)
마지막으로, fclose로 파일을 닫아준다.
