
B-Tree 에 대한 공부를 하던 중 좀 더 깊게 학습을 해보고 싶었다. 직접 구현해보고 성능을 비교하는 것 만큼 좋은 학습은 없다고 판단해 직접구현해보았다.
이 글에서는 B-Tree 의 개념에 대해 살짝 다루긴 하겠지만 깊게 설명하는 글은 아니다. 개념보다는 구현 방법, 성능 비교 위주로 다루고자 한다. B-Tree 에 대해 잘 모르는 분들은
[자료구조] B-트리(B-Tree)란? B트리 그림으로 쉽게 이해하기, B트리 탐색, 삽입, 삭제 과정
위 글들을 읽어보고 오면 도움이 될 것 같다.
B-Tree 란?
우선 B-Tree 를 구현하기 전에 간단한 소개부터 하고 시작하려고 한다. B-Tree 는 트리 자료구조의 일종으로 이진 트리를 확장해 하나의 노드가 자식 노드를 2개 보다 많이 가질 수 있는 트리 구조이다. B-Tree 는 파일 시스템, 데이터 베이스 등 대용량 데이터의 효율적 탐색과 수정이 필요한 곳에 사용된다.
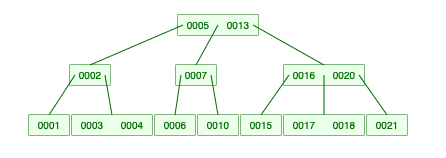
B-Tree 의 주요 특징
- 하나의 노드가 최대로 가질 수 있는 자식의 수를 ‘차수’ 라고 한다. (이하 k 라고 부르겠다.)
- 노드의 차수가 m 라면 최대로 가질 수 있는 키의 개수는 m - 1, 최소로 가질 수 있는 키의 개수는 ⌈m / 2⌉ - 1 (⌈⌉ 은 올림 이라는 뜻이다.)
- 최소 키의 개수는 root 노드에는 적용되지 않는다.
- 각 노드에서 최대로 가질 수 있는 자식의 수는 m, 최소로 가질 수 있는 수는 ⌈m / 2⌉
- 각 노드에서 키는 정렬된 상태로 유지된다.
- 모든 leaf 노드 들은 같은 레벨에 있어야 한다.
위 특징들은 B-Tree 를 구현하기 위해 반드시 알아야 하기에 기억해두길 바란다.
B-Tree 가 데이터 베이스에 사용되는 이유
그렇다면 B-Tree 가 어떤 장점을 가지기에 데이터 베이스 등에서 사용될지 알아 보자.
일관된 성능
B-Tree 의 B는 Balanced 를 의미하는 만큼 모든 leaf node 가 같은 level 로 유지된다. 때문에 최악의 경우에도 성능이 O(log n) 일정하게 유지된다는 장점이 있다.
디스크 접근 최소화
그리고 한 노드에 여러개의 데이터가 들어가는 특징덕분에 데이터 베이스 등에서 디스크에 저장될 때 디스크 접근 횟수를 최소화할 수 있다. 보통 페이지 단위로 하나의 노드가 저장되는데 한 노드의 여러 데이터가 들어있어 페이지를 조회하는 횟수를 최소화 할 수 있어 디스크 접근을 줄일 수 있다.
즉, 대용량 데이터의 효율적인 탐색과 수정이 필요하기 때문에 B-Tree 가 널리 사용된다.
B-Tree 구현하기
B-Tree의 동작 방식에 대해 잘 이해하기 위해 직접 구현해보았다. 구현 언어는 Java 를 사용했다. 전체 코드는 깃허브에서 확인 할 수 있다.
클래스 구조
먼저 클래스 구조를 보자. B-Tree 를 구현하기위해 BTree 와 BTreeNode 클래스를 만들었다.
BTree
public class BTree {
private final int degree;
private BTreeNode root;
private final int minimumKeyCount;
public BTree(int degree) {
this.degree = degree;
this.root = new BTreeNode(degree);
if (degree % 2 == 0) {
this.minimumKeyCount = degree / 2 - 1;
} else {
this.minimumKeyCount = degree / 2;
}
}
}degree: B-Tree 의 차수를 저장한다.root: B-Tree 의 root 노드를 저장한다. 연산 실행시 root 노드가 바뀔 수 있어final이 아니다.minimumKeyCount: 노드가 가질 수 있는 최소 key 의 개수를 저장한다.
BTreeNode
public class BTreeNode {
public final List<Integer> keys;
public final List<BTreeNode> children;
public final int degree;
public BTreeNode(int degree) {
keys = new ArrayList<>(degree - 1);
children = new ArrayList<>(degree);
this.degree = degree;
}
}keys: 노 의 key 들을 저장하고 연산을 간단하게 하기 위해 ArrayList 로 선언했다.children: 노드의 자식 노드를 저장하고keys와 같은 이유로 ArrayList 를 사용했다.
삽입
첫번째로 만들 메서드는 삽입 작업을 하는 insert 메서드이다. 검색보다 먼저 만든 이유는 데이터가 없으면 검색도 못하기 때문에 먼저 구현했다.
요소를 삽입하는 과정을 다음과 같다.
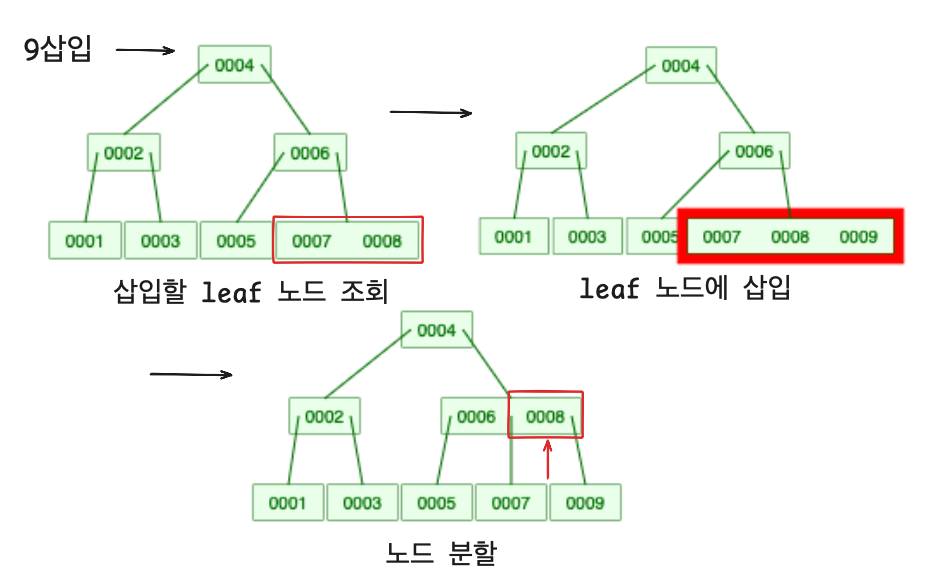
- 요소를 삽입할 leaf 노드를 찾는다.
- leaf 노드에 삽입한다.
- 삽입한 leaf 노드의 키의 개수가 최대 키의 개수 보다 많다면 노드를 분할한다.
- 키의 중간 값을 부모 노드로 올린다.
- 나머지 키들을 부모노드의 자식노드로 연결한다.
- 분할 후 부모 노드도 최대 키의 개수 보다 많다면 다시 분할한다. (정상적인 모양이 될 때 까지 반복한다.)
삽입하는 과정을 간단하게 적었는데 더 자세한 과정이 필요하다면
들을 참고하자.
코드
public void insert(int key) {
insert(root, key);
// root 노드를 분리시켜야 할 경우
if (root.isFull()) {
BTreeNode newRoot = new BTreeNode(degree);
newRoot.children.add(root);
split(newRoot, 0);
root = newRoot;
}
}
// 가득 차지 않은 노드에 삽입하는 메서드
private void insert(BTreeNode node, int key) {
if (node.isLeaf()) {
node.addKey(key);
} else {
// 자식 노드로 내려가며 삽입
int nextNodeIndex = node.getNextNodeIndex(key);
BTreeNode nextNode = node.children.get(nextNodeIndex);
insert(nextNode, key);
if (nextNode.isFull()) {
split(node, nextNodeIndex);
}
}
}
// 노드를 분할하는 메서드
private void split(BTreeNode parentNode, int fullNodeIndex) {
BTreeNode fullNode = parentNode.children.get(fullNodeIndex);
BTreeNode newNode = new BTreeNode(degree);
int mid = degree / 2;
if (degree % 2 == 0) {
mid = mid - 1;
}
// 새로운 노드에 중간 값 이후의 키와 자식들을 이동
for (int j = mid + 1; j < degree; j++) {
newNode.keys.add(fullNode.keys.remove(mid + 1));
}
// leaf 노드가 아니라면 자식노드 들도 이동
if (!fullNode.isLeaf()) {
for (int j = mid + 1; j <= degree; j++) {
newNode.children.add(fullNode.children.remove(mid + 1));
}
}
// 부모 노드에 중간 키 추가
parentNode.keys.add(fullNodeIndex, fullNode.keys.remove(mid));
parentNode.children.add(fullNodeIndex + 1, newNode);
}우선 삽입할 leaf 를 찾기 위해 재귀적으로 insert 를 구현했다.
- 재귀적으로 탐색하며 leaf 노드를 찾으면 삽입할 key를 추가한다.
insert(nextNode, key);
if (nextNode.isFull()) {
split(node, nextNodeIndex);
}와 같이 구현하였기때문에 재귀적으로 leaf 노드에 추가 한 후 차래대로 삽입한 노드의 key 값을 검사하여 다 찼다면 분리를 시작한다.
- 중간 값을 기준으로 노드를 2개로 분리해야하는데 1개는 기존의 노드를 사용하고 1개는 새로 만든다.
- 중간 값 보다 작은 키들을 새로 만든 노드로 이동시킨다.
- 다음으로 중간 값을 부모 노드로 이동시킨다.
- 새로 만든 노드를 부모노드의 자식으로 연결시킨다. 분리시키는 노드가 leaf 노드가 아닌 경우에는 옮기려는 key와 연관된 자식 노드들도 옮겨주어야 한다.
root 노드를 분리시켜야 할 경우 새로운 root 노드를 만들어 중간 값을 이동시킨후 root 노드를 바꿔준다.
검색
검색하는 과정은 이진 탐색 트리와 비슷하다. 하양식으로 키들을 비교하며 조건에 맞는 노드들을 탐색하면 된다. 과정을 다음과 같다.
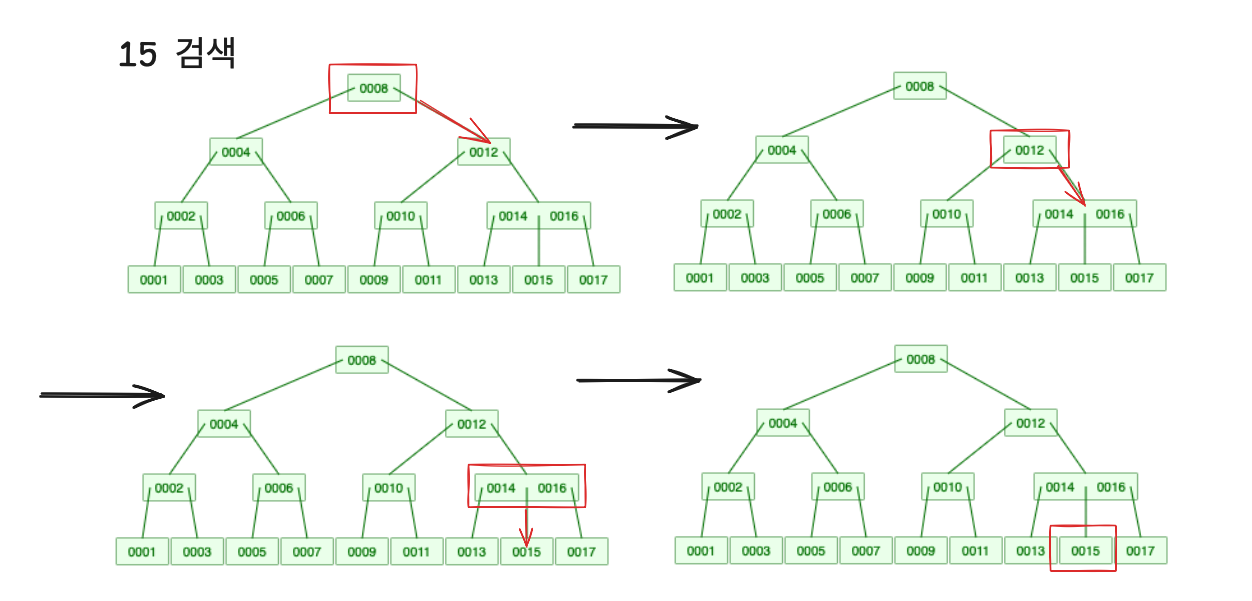
- root 노드 부터 시작하여 노드의 key 값을 순회한다.
- 일치하는 key 값이 있다면 종료한다.
- 없다면 탐색하려는 key보다 작은 값과 큰 값 사이의 노드로 이동한다. (찾으려는 key가 첫번째 값이나 마지막 값이면 사이노드가 없을 수 있다.)
- 찾으려는 key를 찾을 때 까지 반복한다.
코드
public BTreeNode search(int key) {
return search(root, key);
}
// 재귀적으로 검색하는 메서드
private BTreeNode search(BTreeNode node, int key) {
int i = 0;
// 현재 노드에서 키와 비교
while (i < node.keys.size() && key > node.keys.get(i)) {
i++;
}
// 키가 현재 노드에 있는 경우
if (i < node.keys.size() && key == node.keys.get(i)) {
return node; // 키를 찾았으므로 해당 노드를 반환
}
// 리프 노드에 도달한 경우, 트리에 키가 없음
if (node.isLeaf()) {
return null;
}
// 자식 노드로 내려가서 계속 검색
return search(node.children.get(i), key);
}삽입에서 leaf 노드를 찾는 것과 비슷하게 재귀적으로 탐색한다.
- 먼저 while 문을 통해 현재 노드에서 key 값이 있는지 확인한다.
- 찾는 값이 있다면 반환한다.
- 하지만 leaf 노드까지 내려왔는데 찾는 값이 없다면
null을 반환한다.
트리 출력
트리가 정상적으로 삽입되는지 확인하기 위해 트리를 출력하는 메서드도 만들었다.
// 트리 형식으로 키 값을 출력하는 메서드
public void printTree() {
if (root != null) {
printNode(root, 0); // 루트 노드부터 출력 시작
}
System.out.println("\n-------------------------\n");
}
// 각 노드를 재귀적으로 출력하는 메서드
private void printNode(BTreeNode node, int level) {
System.out.println(" ".repeat(level) + "Keys: " + node.keys);
// 자식 노드가 있으면, 각 자식 노드에 대해 재귀 호출
for (BTreeNode child : node.children) {
printNode(child, level + 1); // 레벨을 증가시켜 들여쓰기 조절
}
}중간 결과
지금 까지 구현한 결과를 확인해보자! 차수가 3인 B-Tree 에 1 ~ 15 까지 넣은 결과이다.
Keys: [8]
Keys: [4]
Keys: [2]
Keys: [1]
Keys: [3]
Keys: [6]
Keys: [5]
Keys: [7]
Keys: [12]
Keys: [10]
Keys: [9]
Keys: [11]
Keys: [14]
Keys: [13]
Keys: [15]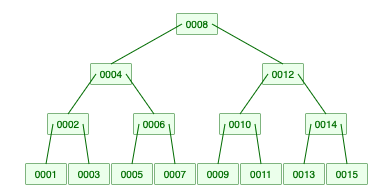
B-Tree Visualization 과 비교해보면 잘 들어가는 것을 알 수 있다. 차수가 다를 때도 잘 들어간다. 다른 차수들도 넣으면 글이 너무 길어지기 때문에 차수가 4인 것만 확인해보자.
Keys: [4, 8]
Keys: [2]
Keys: [1]
Keys: [3]
Keys: [6]
Keys: [5]
Keys: [7]
Keys: [10, 12]
Keys: [9]
Keys: [11]
Keys: [13, 14, 15]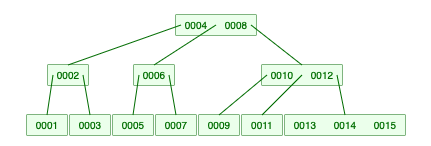
차수가 4일때도 잘 삽입 되는 것을 볼 수 있다!
삭제하는 과정이 삽입 , 검색 보다 훨씬 복잡하기 때문에 글의 길이가 너무 길어져서 삭제는 다음 편에서 소개한다.
B-Tree 성능 비교
이제 B-Tree 를 구현해보았기때문에 여러 자료구조들과 성능을 비교해보려고 한다. 또한 차수에 따라서 성능이 어떻게 바뀌는지도 테스트 해보았다.
ArrayList VS B-Tree
먼저 트리 구조가 아닌 List 와 비교해보았다. List 중 자주 쓰이는 ArrayList 와 비교하려고 한다. 테스트 조건은 100,000 개의 데이터를 삽입하고 조회하는 속도를 비교한다. 이때 1 부터 100,000 까지 순차적으로 값을 넣는 것과 랜덤으로 100,000 개의 데이터를 넣는 경우로 나누었다.
먼저 결과 부터 확인하자!
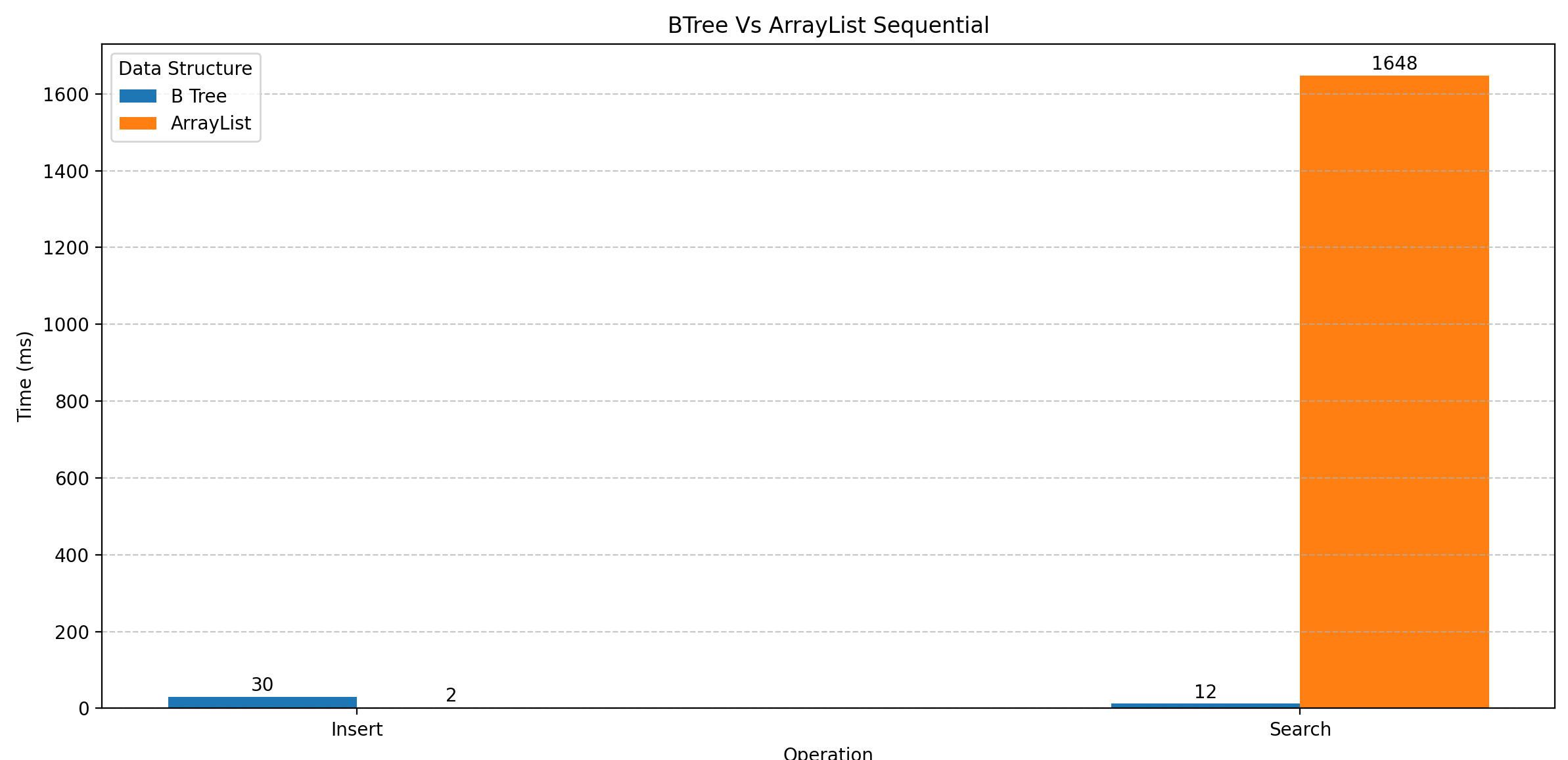
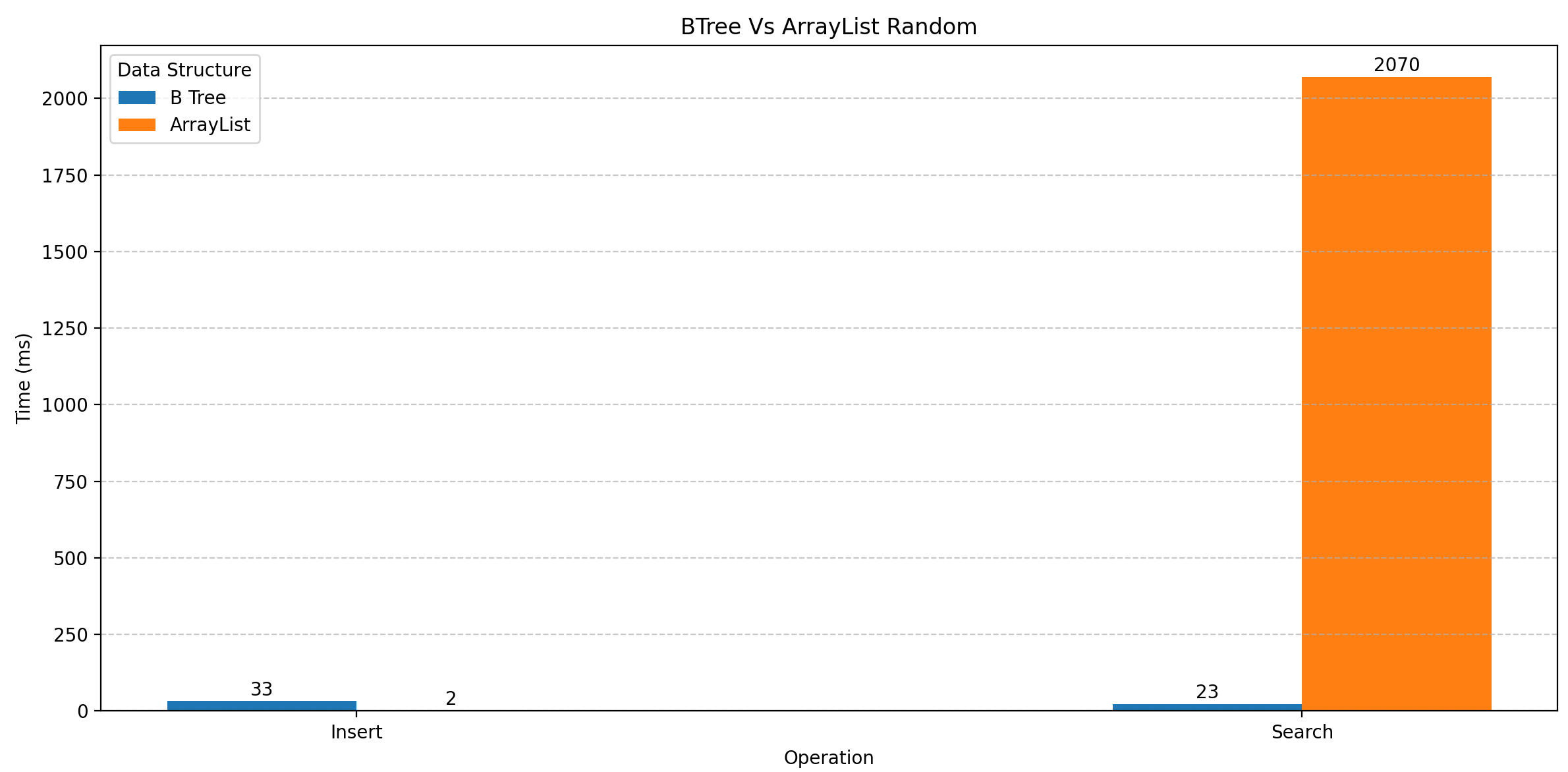
결과
- 결과를 보면 삽입 성능은 B-Tree와 ArrayList 가 비슷한 반면 조회 속도는 압도적으로 차이나는 것을 볼 수 있다.
- 순차적인 데이터와 랜덤한 데이터를 비교했을 때 차이는 거의 없다.
ArrayList 의 삽입 조회 과정을 알면 당연한 결과이다. ArrayList 에서 데이터는 단순히 들어오는 순서로 저장된다. 때문에 삽입 과정은 B-Tree와 크게 다르지 않다. 오히려 약간 빠른 성능을 보여준다.
하지만 검색 과정은 저장된 모든 데이터를 다 순회하고 반환하기 때문에 O(n) 시간이 걸린다. B-Tree의 검색 성능인 O(log n) 와 비교하면 당연히 크게 차이 날 수 밖에 없는 결과 였다.
랜덤으로 데이터를 삽입한 경우도 어차피 ArrayList는 모든 데이터를 순회하기 때문에 순차적으로 데이터를 삽입한 경우와 성능이 크게 다르지 않다.
이진 탐색 트리 VS B-Tree
이번에는 같은 트리 구조인 이진 탐색 트리(Binary Search Tree, BST)와 비교해보았다. 균형을 유지하는 것과 아닌 것의 차이를 볼 수 있었다. 테스트 조건은 ArrayList 와 거의 같지만 이번에는 값을 찾을 때 까지의 노드 방문 횟수도 테스트 하였다.
사실 테스트 조건에서 삽입하는 데이터의 개수가 10,000 으로 줄었다.. BST를 재귀로 구현하였더니 순차적으로 데이터를 넣으니까 콜스택이 다 차서 Stack Over Flow 가 나버렸다 😅
이진 탐색 트리 : 각 노드의 왼쪽 자식은 부모보다 작고, 오른쪽 자식은 부모보다 큰 값을 가지는 트리이다. 이를 통해 효율적인 데이터 검색, 삽입, 삭제가 가능하며, 평균적으로 O(log n)의 시간 복잡도를 가집니다. 모든 서브트리도 이진 탐색 트리의 특성을 만족해야 합니다.
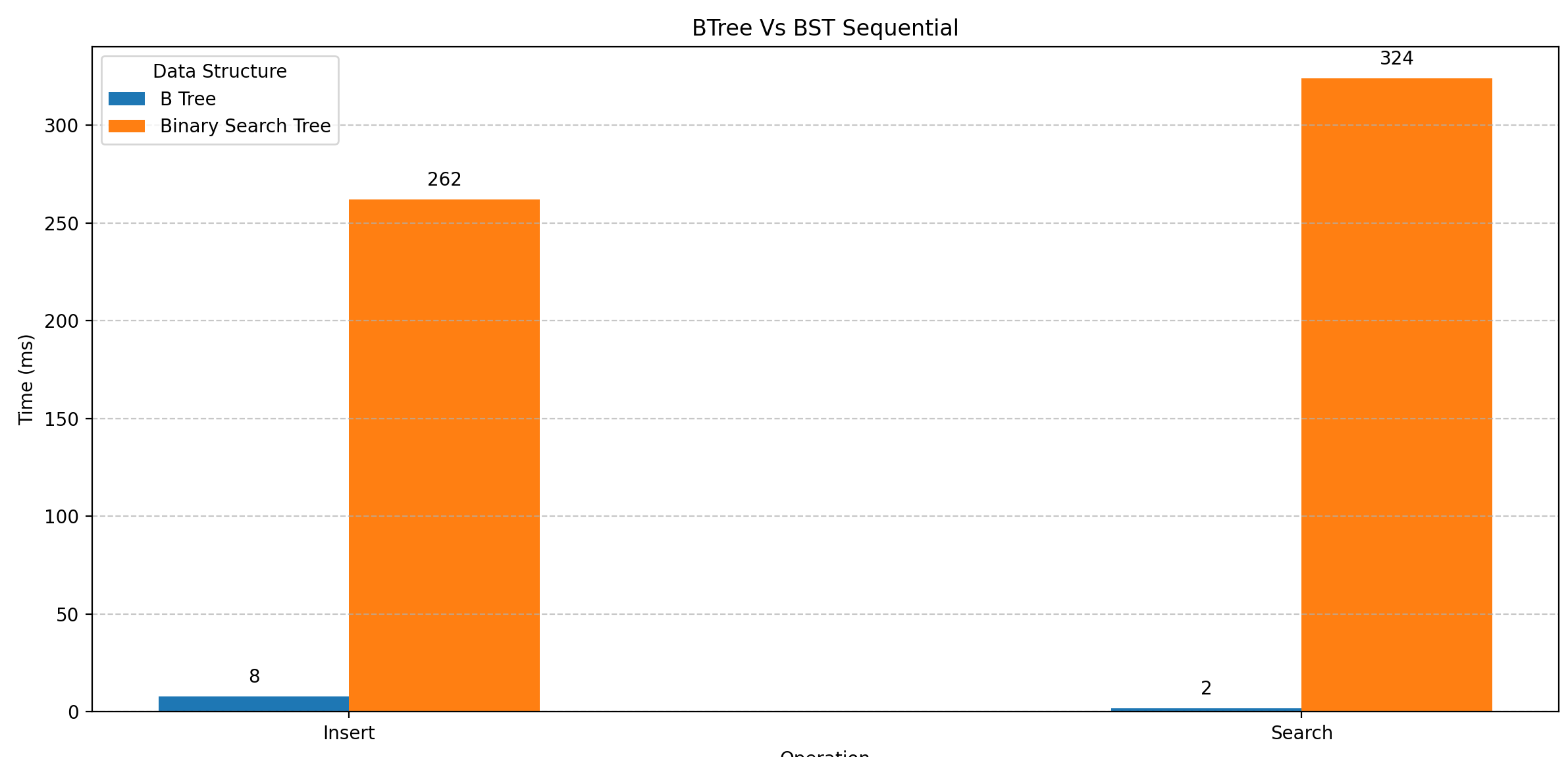
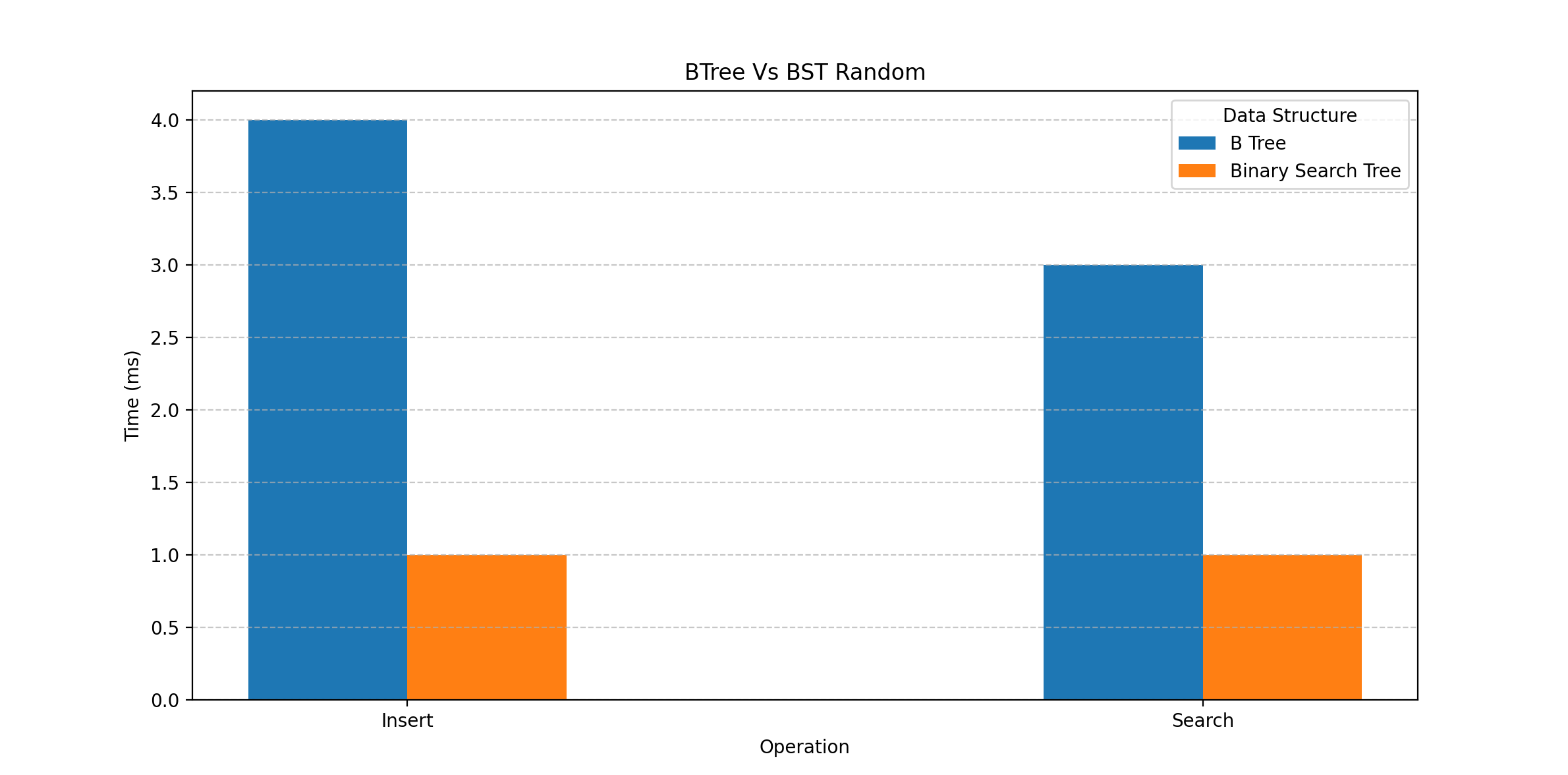
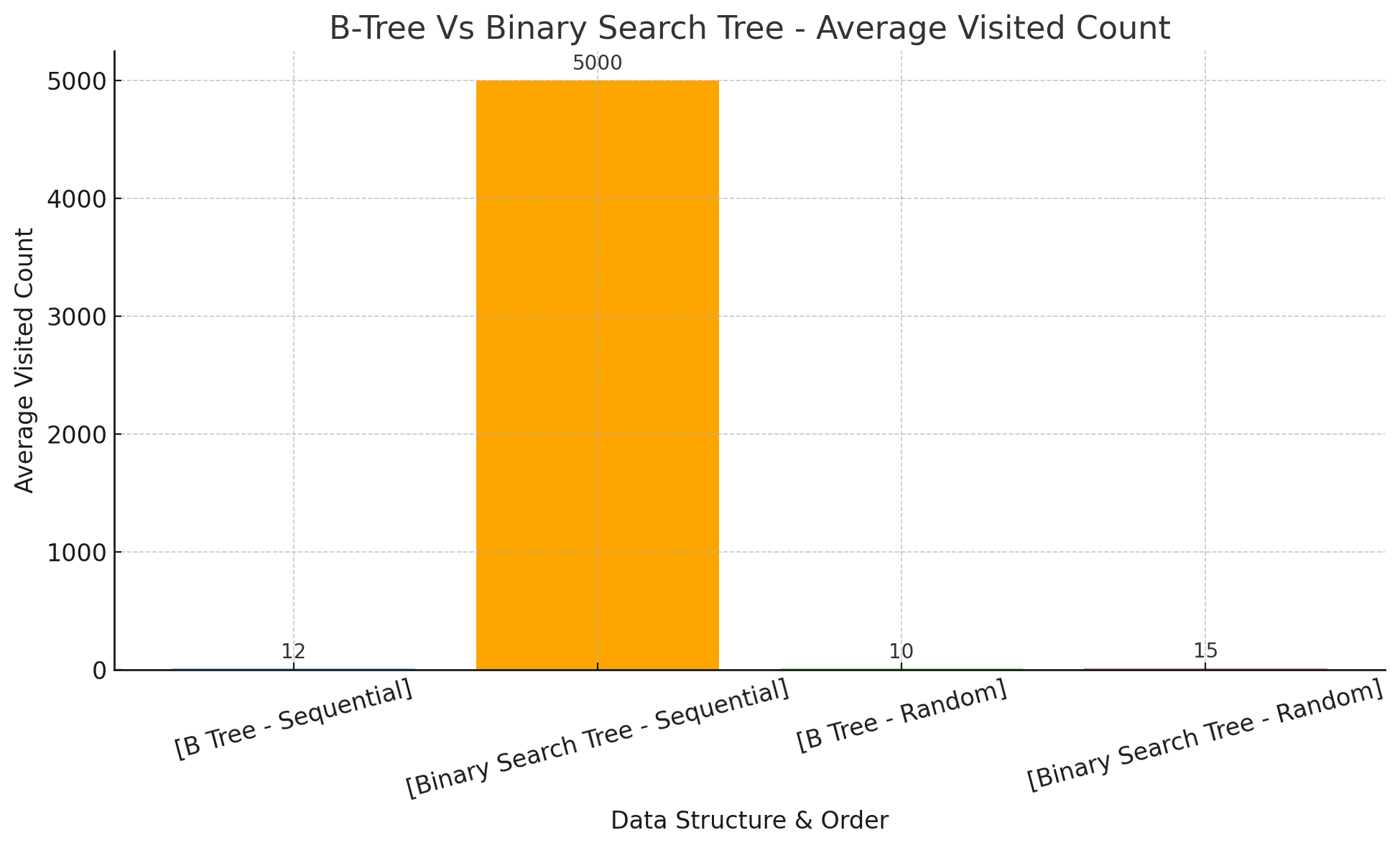
결과
- 순차적으로 삽입하고 조회 했을 때는 BST 의 성능이 압도적으로 떨어진다.
- 랜덤으로 삽입하고 조회 했을 때는 B-Tree와 BST 의 성능이 비슷하다.
- 그래프 상으로는 time이 작고 차이가 적어서 크게 차이나는 것 처럼 보이지만 실제 값은 얼마 차이나지 않는 것을 볼 수 있다.
- 값을 찾기 위해 방문하는 노드의 수가 BST 가 훨신 많다.
원인
B-Tree 는 항상 균형을 유지 하기 때문에 성능의 차이가 거의 없지만 BST는 다르다. 위에 평균적으로 O(log n) 의 시간 복잡도를 가진다고 하였지만 빠진 설명이 있다. 최악의 경우에는 O(n) 의 시간복잡도를 가진 다는 것이다.
순차적으로 데이터를 넣는 것 처럼 한 쪽으로 편향되게 데이터를 넣으면 트리가 일종의 연결리스트 처럼 된다. 이렇게 되면 삽입할 때 보다 긴 level을 지나 삽입 해야해서 속도가 느려진다. 검색 할 때도 연결 리스트를 순회하는 것과 다를 것 없어지기 때문에 굉장히 느려진다.
데이터 베이스에 적합하지 않은 이유
위 결과를 통해 BST 가 데이터 베이스 같은 곳에 사용하지 않는 이유를 알 수 있다. 첫째 균형이 유지 되지 않아 케이스에 따라 성능 차이가 심하다. 두번째 하나의 노드를 디스크의 페이지라 하면 디스크에 접근하는 횟수가 B-Tree 보다 많다. BST는 하나의 노드에 하나의 데이터만 저장되기 때문이다. 이는 위 그래프의 결과로도 알 수 있다.
avl 트리와 red-black 트리는?
avl 트리와 red-black 트리는 이진 탐색 트리와 달리 균형을 이루는 트리이다. 시간이 부족해 이 자료구조들과 비교하는 테스트는 하지 못했지만 아마 결과는 순차적으로 넣는 것과 랜덤하게 넣는 경우 모두 B-Tree 와 속도 면에서는 비슷한 성능을 보여줄 것 이라고 예상한다. 이유는 균형을 이루기 때문이다.
하지만 노드 하나에 데이터 하나가 들어가는 것은 이진 탐색 트리와 다르지 않기 때문에 데이터를 찾기 위해 방문하는 노드의 수는 B-Tree 보다 많을 것이다. 때문에 이 트리들도 데이터 베이스 같은 곳에서는 적합하지 않다.
B-Tree 의 차수별 성능 비교
마지막으로 B-Tree 끼리 차수가 달라지면 성능 면에서 어떻게 다를지 확인하고 마치려고 한다. 테스트는 각 차수 별로 1,000,000 개 씩 데이터를 넣어 보고 삽입, 조회, 방문하는 노드의 수를 측정 해보았다.
결과 부터 보자!
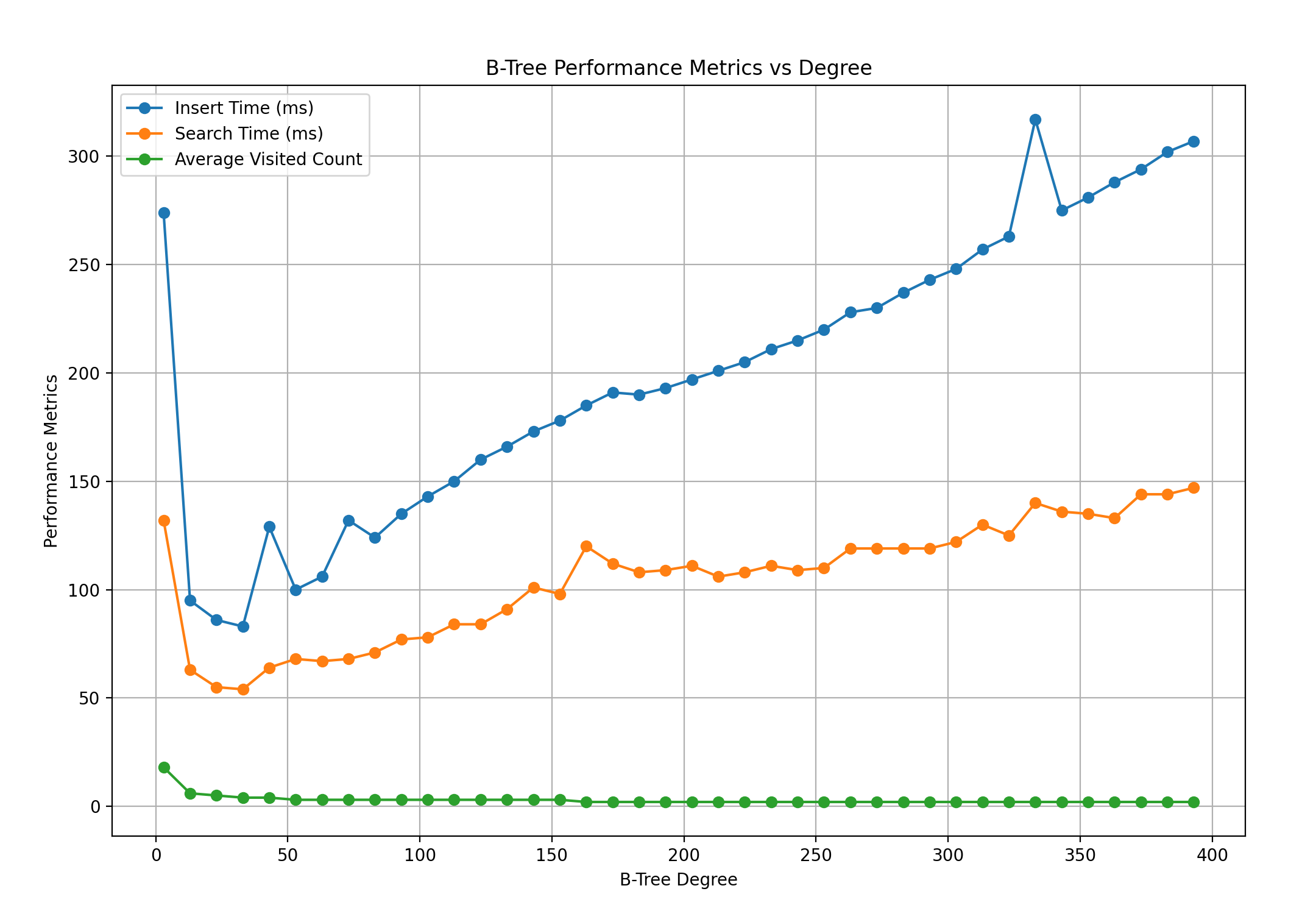
결과
- 어느 정도 차수가 커지면 성능은 빨라진다.
- 일정 차수가 넘어가면 다시 성능이 느려진다.
차수가 올라가면 성능이 빨라질 것이라고 예상 하였는데 반은 맞고 반은 틀렸다. 그래프를 보면 성능이 좋아지는 한계가 있다. 이를 넘어 차수를 올리면 오히려 성능이 제일 기본 차수인 3보다 느려지는 것을 확인 할 수 있었다.
왜 그럴까?
우선 차수가 높아지면 트리의 높이가 낮아진다. 하나의 노드에서 더 많은 key 값을 갖기 때문이다. 때문에 어느 정도 차수가 높아지면 탐색할 높이가 줄어들어서 속도가 빨라진다.
하지만 차수가 너무 많이 높아지면 하나의 노드에서 많은 양의 key 값을 가진다. 이렇게 되면 탐색할 때 방문하는 노드의 수는 줄어들지만 노드 안에서 순회 해야할 데이터가 많아지기 때문에 성능이 더 줄어든다.
때문에 무작정 차수를 늘리는 것 보다 데이터의 상황, 시스템의 하드웨어 환경을 고려하고 성능 테스트를 통해 최적의 차수를 찾는 것이 중요한 것 같다.
마무리
B-Tree를 직접 구현하고 성능을 비교해본 과정은 결코 쉽지 않았지만, 결과는 나쁘지 않은 것 같다.
처음에는 B-Tree를 구현하는 것이 크게 어렵지 않을 것이라고 생각했다. B-Tree가 어떻게 작동하는지 설명하는 글들이 많았기 때문이었다. 그러나 실제로 구현해보니 예상보다 훨씬 어려웠다. 작동 방식을 코드로 옮기는 것은 생각보다 복잡했고, 참고할 만한 구현 예제도 많지 않아서 특히 더 힘들었다. 그래도 직접 구현해보니, 단순히 개념만 공부했을 때보다 B-Tree의 작동 방식과 원리를 더 깊이 이해할 수 있었다.
성능 비교는 B-Tree를 오랜 시간 걸려서 구현한 뒤, 여기서 멈추기 아쉬워서 시도해본 작업이었다. 그런데 오히려 더 좋은 공부가 되었다. 다른 자료구조와 비교해보면서 각각의 특징을 이해할 수 있었고, 왜 B-Tree가 데이터베이스에 많이 사용되는지도 체감할 수 있었다.
구현 하면서 아쉬운 점은 테스트 코드를 작성하지 않은 점이다. B-Tree Visualization 과 비교하며 다 테스트 했지만 일일이 비교하다 보니 시간이 오래걸렸다. 테스트 코드를 작성했다면 버튼 하나로 테스트 가능 했을 텐데.. 이부분이 아쉽다.
결과적으로, B-Tree의 구현과 성능 비교를 통해 많은 것을 배울 수 있었고, 실무적으로도 중요한 자료구조에 대해 더 깊이 이해할 수 있었던 유익한 경험이었다.
