
최근 내가 운영중인 그라운드 플립 서비스에 마커 클러스터링을 적용했다. 클라이언트 측의 마커 클러스터링 방법은 레퍼런스가 많은 반면 백엔드에서 구현방법은 레퍼런스가 잘 없어 어려웠었던 것 같다. 그래서 이번 글에서는 직접 마커 클러스터링을 구현해보며 어떤 방식으로 클러스터링을 구현 하였는지 소개해보고자 한다.
그라운드 플립이란?
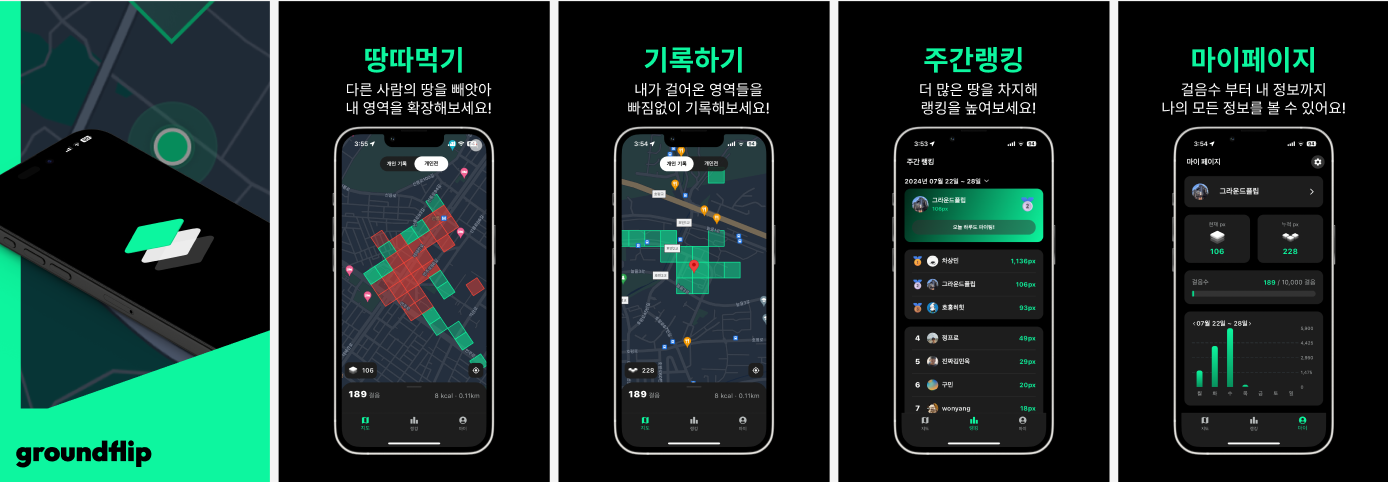
우선 그라운드 플립은 서비스를 소개하겠다. 그라운드 플립을 한마디로 소개하자면 땅따먹기 만보기 서비스이다. 단순히 걷는 것에서 끝나지 않고, 걸은 길을 점령할 수 있는 시스템을 제공한다. 내가 걷는 경로가 내 땅이 되고, 다른 사람들이 점령한 영역도 뺏을 수도 있다.
걸으면 걸을수록 점령한 영역이 지도에 표시되고, 다른 사용자와 경쟁하는 재미를 느낄 수 있는 서비스이다. 현재 앱스토어와 플레이스토어에 배포되어 있으니, 언제나 다운로드해서 땅따먹기를 할 수 있다!
[iOS] : https://apps.apple.com/app/ground-flip/id6550922550
[Android] : https://play.google.com/store/apps/details?id=com.m3pro.ground_flip
[랜딩페이지] https://ground-flip2.imweb.me/
마커 클러스터링을 왜 도입할까?
마커 클러스터링을 왜 도입 하는지 부터 설명해보려한다. 우리 서비스는 지도에 사용자가 걸어간 영역을 사각형으로 표시한다.
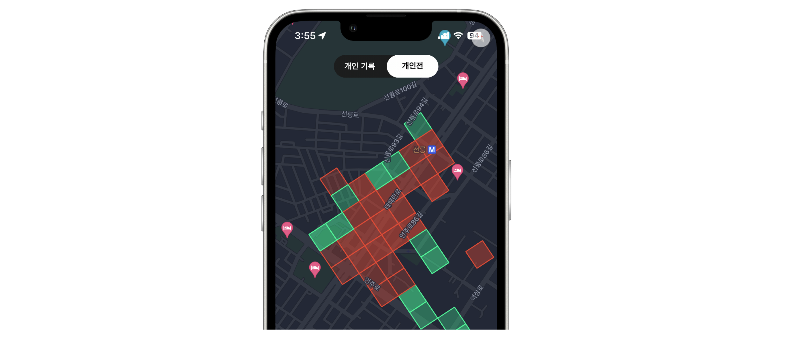
사각형을 지도에 띄우는 방법은 Flutter의 Google map api 에서 제공하는 Polygon 을 사용한다. 이 Polygon 들을 지도가 축소 되었을 때도 전부 띄우면 가장 좋은 방법이겠지만 불가능 하다.
우선 모바일 앱에서 엄청 많은 양의 polygon을 렌더링 할 수 없다. 실제로 테스트 해보니 약 200개 정도의 polygon 이 화면에 렌더링 되면 앱이 엄청 버벅거리는 것을 확인 할 수 있었다.
두번째로 서버에 많은 부담이 간다. 백엔드 개발자라면 많은 데이터를 반환할 때 페이징 처리를 해서 전달하는 것을 알 것이다. 많은 데이터를 서버에서 지속적으로 처리한다면 메모리와 cpu 자원을 많이 사용하며 처리 속도가 느려져 응답속도가 느려질 것 이다. 따라서 모든 땅 정보를 반환한다면 심각한 성능저하로 이어질 수 있다.
때문에 우리는 지나치게 많은 polygon 을 렌더링 하지 않기 위해 지도를 일정 수준이상 축소시키면 땅을 렌더링 하지 않도록 구현하였다.
불편함
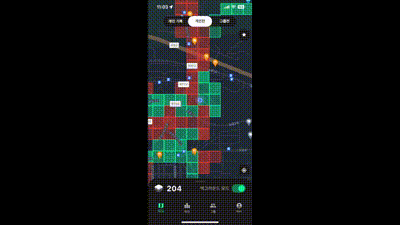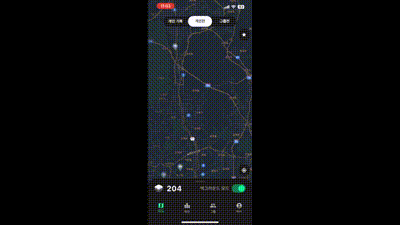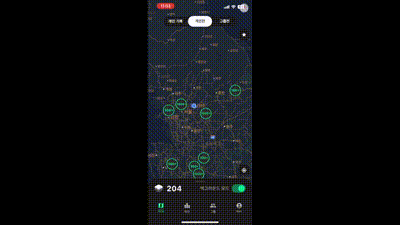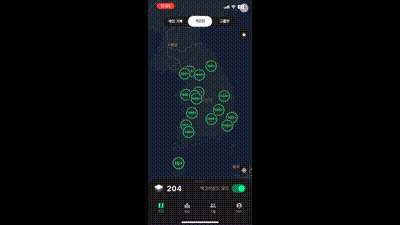
위 그림 처럼 지도를 축소 했을 때 아무것도 보이지 않으니 상당히 불편했다. 내가 어디에 방문 했는지 기억에 의존해서 찾아야했고 어떤 지역에 사람들이 점령하는지 확인하는 것이 어려웠다.
그리고 지속적으로 유저들한테서도 지도를 축소 했을 때 땅을 보고 싶다는 피드백이 많이 들어왔다. 개발 초기부터 개선 해야겠다는 생각이 있었기때문에 바로 마커 클러스터링을 도입해보았다.
마커 클러스터링이란? 지도가 축소 될 때 마커가 집중되어있으면 모든 마커가 겹쳐 보여서 가독성이 떨어지기 때문에 가까이 위치한 마커들을 묶어 표현하는 방식.
어떤 식으로 클러스터링 할까?
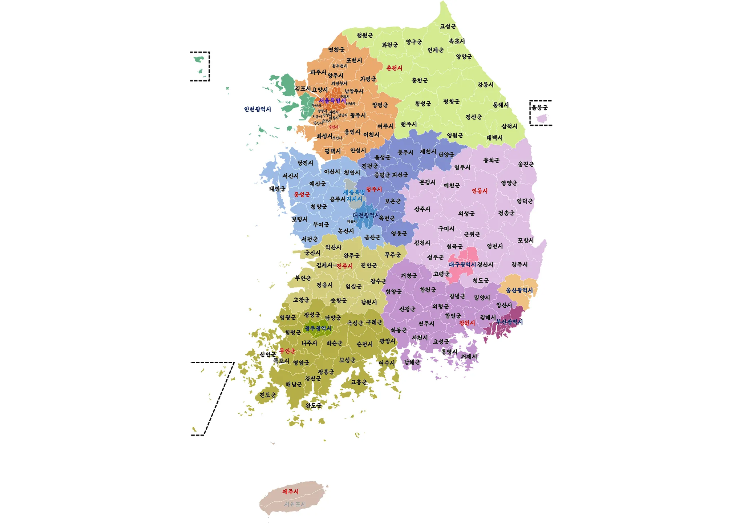
이제 어떤 것을 기준으로 클러스터링 할지 기준을 정해야한다. 우리는 대한민국의 행정구역 시군구 단위로 땅의 개수를 집계하여 표시하기로 했다. 대한민국의 전체 시군구 개수는 260 개로 클러스터링 하기 적당한 숫자라고 판단 했다.
구현 계획
이제 클러스터링 집계 단위를 정하였으니 어떻게 구현 할지 계획을 세워야했다. 각 항목에 대해서는 밑에서 자세히 설명하고 여기서는 개요만 나열한다.
- 지도에 클러스터링 된 마커를 표시할 시군구의 좌표 얻기.
- 땅이 어떤 시군구에 위치하는 지 판단하는 로직
- 지도의 축소 여부에 따라 클러스터링 된 마커를 보여주는 로직
- 시군구 기준으로 땅의 개수를 집계하여 응답하는 로직
크게 위의 작업이 필요했다. 이제 각 구현 방식을 알아보자!
지도에 표시할 시군구의 좌표 구하기
우선 지도에 표시할 시군구에 해당할 마커들의 좌표를 구하는 것이 중요했다. 각 시군구의 좌표를 어떻게 구할지 고민하다가 이전에 GDG의 GIS 관련 세션에서 들은 GeoJson 이 떠올라 이번 기회에 사용해보기로 했다.
GeoJson 이란? 위치정보를 갖는 점을 기반으로 하여 체계적으로 지형을 표현하기 위해 설계된 개방형 공개 표준이다. GeoJson 을 활용하여 행정 구역의 경계선을 그릴 수도 있고 다양한 지리 데이터를 분석 할 수 있다.
그래서 공공포탈에 대한민국 시군구의 GeoJson이 있는지 확인해보았다.
이 사이트에서 대한민국 시군구의 경계 파일을 찾을 수 있었는데 파일 형식이 GeoJson 형식이 아니고 shp 형식이었다.
shp 형식이란? Shapefile 포맷의 파일로, 지리정보 시스템(GIS)에서 공간 데이터를 저장하는 데 사용된다. 주로 위치 정보나 지형 정보를 표현하기 위해 사용되며 벡터 데이터를 기반으로 한다.
결국 shp 파일도 GeoJson 처럼 지형 정보를 저장한 파일이기 때문에 shp 를 사용해도 무방하겠다고 판단하여 shp 를 사용하는 방식으로 변경하였다.
좌표 뽑기
시군구의 위치가 점이 아니라 면이기 때문에 마커를 표시할 특정 위치를 계산하여야 했다. 그래서 우리는 각 시군구의 중심좌표에 마커를 표시하기로 정하였다.
파이썬의 geopandas 라이브러리를 사용하면 각 shp 파일에 저장된 시군구의 중심 좌표를 쉽게 뽑을 수 있었다.
import geopandas as gpd
from shapely.geometry import Point
from pyproj import Transformer
import pandas as pd
import os
SHP_FILES_PATH = "/shp/파일/위치"
transformer = Transformer.from_crs("EPSG:4326", "EPSG:5186", always_xy=True)
def load_all_shp():
# 1. SHP 파일들이 저장된 디렉토리 경로 설정
shapefile_directory = SHP_FILES_PATH # SHP 파일들이 저장된 디렉토리 경로
# 2. 모든 SHP 파일 읽어와서 병합
gdf_list = []
for folder_name in os.listdir(shapefile_directory):
folder_path = os.path.join(shapefile_directory, folder_name)
if os.path.isdir(folder_path):
for file in os.listdir(folder_path):
if file.endswith(".shp"):
# SHP 파일 읽어오기
filepath = os.path.join(folder_path, file)
gdf = gpd.read_file(filepath)
gdf_list.append(gdf)
# 3. 병합된 GeoDataFrame 생성
merged_gdf = gpd.GeoDataFrame(pd.concat(gdf_list, ignore_index=True))
return merged_gdf
merged_gdf = load_all_shp()
# 중심 좌표 계산하여 새로운 컬럼으로 추가
merged_gdf['centroid'] = merged_gdf['geometry'].centroid
# 중심 좌표를 WGS84 좌표계로 변환
merged_gdf = merged_gdf.set_geometry('centroid')
merged_gdf = merged_gdf.to_crs(epsg=4326)
# 중심 좌표의 위도와 경도를 별도의 컬럼으로 분리
merged_gdf['latitude'] = merged_gdf['centroid'].y
merged_gdf['longitude'] = merged_gdf['centroid'].x
# 'name' 컬럼을 기준으로 정렬하여 출력
sorted_gdf = merged_gdf.sort_values(by='SGG_NM', ascending=True)
sorted_gdf['id'] = range(1, len(sorted_gdf) + 1)
# 결과를 CSV 파일로 저장
csv_file_path = "/저장할/위치/sorted_districts_with_centroids.csv" # 저장할 CSV 파일 경로와 이름 설정
sorted_gdf[['id', 'SGG_NM', 'latitude', 'longitude']].to_csv(csv_file_path, index=False, encoding='utf-8-sig')
print(f"정렬된 구역 정보가 '{csv_file_path}' 파일로 저장되었습니다.")땅 분류 로직
다음은 땅을 시군구에 맞게 분류하는 로직을 구현하였다.
region 테이블 생성
우선 시군구 데이터를 넣을 region 테이블을 만들었다.
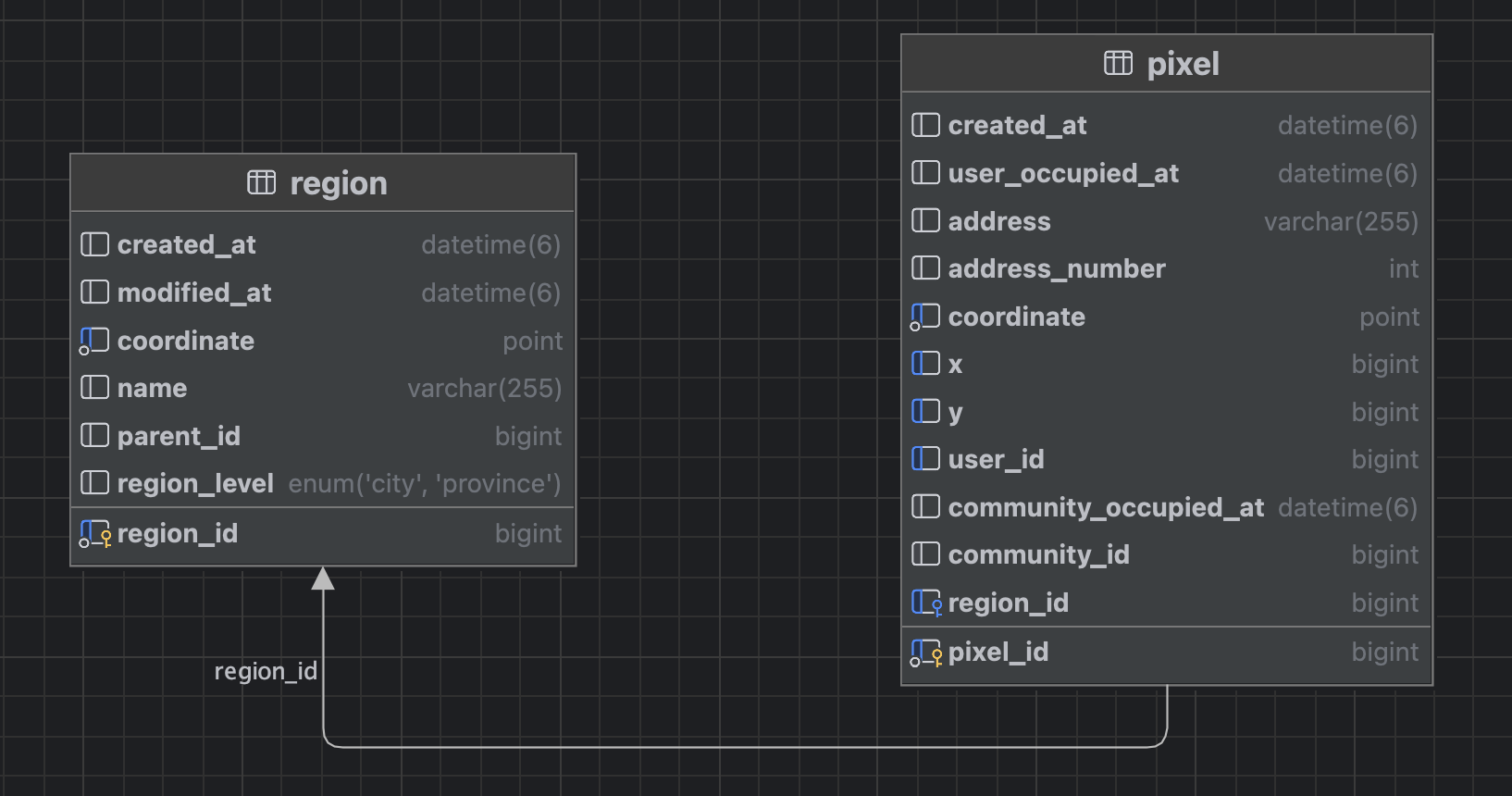
region 테이블에는
name: 지역 이름 (강남구)coordinate: 시군구 중심 좌표 (37.19294, 126.934948)created_at: 데이터가 생성된 날짜modified_at: 수정된 날짜
이렇게 컬럼이 들어가있다. (parent_id, region_level 은 해프닝이 있어 밑에서 설명한다 ㅎㅎ) 그리고 땅 정보를 나타내는 pixel 테이블에 region_id 를 넣어 region 테이블과 1:n 관계를 맺었다.
region 테이블에는 위에서 얻은 중심좌표 데이터를 바탕으로 데이터를 삽입했다.
땅 분류 서버 구현
각 픽셀의 좌표를 기반으로 지역을 분리할 수 있는 로직이 필요했다. 시군구 경계 데이터를 다운 받은 사이트에서 좌표를 시군구로 변환해주는 Reverse Geocoding api 를 제공해주었다. 하지만 테스트 해봤을 때 응답 속도가 그렇게 빠른 편은 아니었고 하루에 호출 가능한 횟수가 나와있지 않아 안정적이지 않다고 판단했다. 또한 외부 서비스이다 보니 이쪽에서 장애가 발생했을 때 대응이 어렵다고 판단하여 사용하지 않았다. 네이버 api 도 있었지만 위와 같은 이유와 일정량 사용 후 금액이 부과되어 선택하지 않았다.
결국 선택한 방법은 직접 Reverse Geocoding 서버를 만들기로 했다!
위에서 사용한 geopandas 라이브러리를 사용하면 충분히 특정 좌표가 지역에 속하는 지 판단하는 로직을 만들 수 있었다. 하지만 좌표를 분류할 때 마다 실행 시키기에는 초기 로딩시간이 꽤 길었다. 많은 양의 shp 파일을 읽어 메모리에 적재하는 과정이 오래걸렸다. 때문에 나는 이 로직을 Flask 를 사용하여 간단한 was 를 만들었고 서버에 항상 띄어두기로 했다.
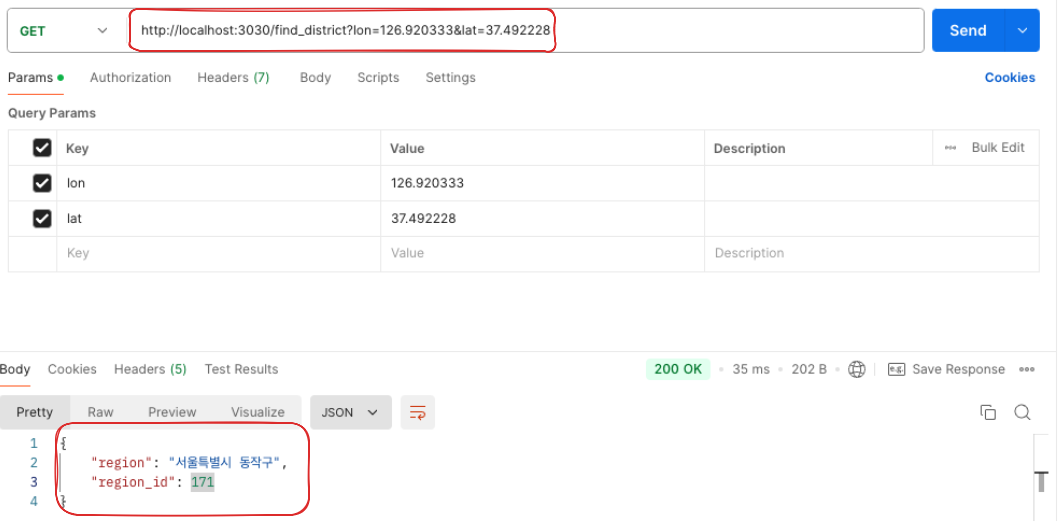
결과는 찾고자하는 좌표를 담아 요청하면 위 결과와 같이 우리 DB 에 저장된 region_id 와 지역 이름이 반환된다!
이번 글에서 Reverse Geocoding 서버를 구현하는 것 까지 다루기는 글이 너무 길어질 것 같아 깃허브 주소를 남기겠다. 혹시나 이 글을 보고 따라해보고 싶으신 분은 깃허브에서 다운 받아 도커 이미지를 실행시키면 된다. 구현 방법은 다음 글에서 자세히 풀어보도록 하겠다.
땅 분류 로직 구현
사용자가 걸어서 땅을 방문하게 되면 방문 요청이 서버에 전송된다. 이때 두가지 경우로 나눌 수 있다.
- 기존에 발견된 땅을 방문한 경우 →
pixel테이블에 이미 땅 데이터가 저장되어 있다. - 처음 방문된 땅을 방문한 경우 →
pixel테이블에 땅 데이터가 저장되어있지 않다.
기존에 발견된 땅인 경우 이미 지역 정보가 삽입되어있다. 테이블 업데이트를 하면서 지역 정보를 미리 집어 넣어두었다.
처음 방문한 땅의 경우 땅 정보를 만들어 pixel 테이블에 삽입해야한다. 이때 생성하기 전에 위에서 구현해둔 Reverse Geocoding 서버에 요청을 보내 시군구 데이터를 받아와서 저장하게 된다!
private Pixel createPixel(Long x, Long y) {
Long pixelId = getPixelId(x, y);
Point coordinate = getCoordinate(x, y);
// 지역 정보를 Reverse Geocoding 서버로 부터 받아온다.
ReverseGeocodingResult reverseGeocodingResult = getRegion(coordinate);
log.info("x: {}, y: {} pixel 생성", x, y);
Region region = reverseGeocodingResult.getRegionId() != null
? regionRepository.getReferenceById(reverseGeocodingResult.getRegionId()) : null;
Pixel pixel = Pixel.builder()
.id(pixelId)
// 생략
.build();
return pixelRepository.save(pixel);
}
private ReverseGeocodingResult getRegion(Point coordinate) {
double longitude = coordinate.getX();
double latitude = coordinate.getY();
try {
return reverseGeoCodingService.getRegionFromCoordinates(longitude, latitude);
} catch (Exception e) {
String errorLog = "[Reverse Geocoding Error] longitude : " + longitude + ", latitude : " + latitude + " ";
log.error("{}{}", errorLog, e.getMessage(), e);
return ReverseGeocodingResult.builder().regionId(null).regionName(null).build();
}
}여기서 중요한 점은 Reverse Geocoding 서버에서 오류가 나더라도 땅은 저장되게 구현했다. 대신 시군구 데이터를 얻어오는데 실패했다는 로그를 남기고 추후에 따로 넣어주게 구현했다.
Reverse Geocoding 서버의 장애가 메인 서버에 전파가 되지 않게 구현했다!
클러스터링 된 마커를 지도에 표시하는 로직
우선 서버의 클러스터링된 데이터를 응답하는 로직을 만들기전에 Client 에서 클러스터링 하는 로직을 먼저 구현했다. 내가 플러터는 시작하지 얼마되지 않아 구현 할 수 있을지 확신이 없었기에 먼저 만들어 검증했다. ㅎㅎ
앞서 말했다시피 그라운드 플립은 Flutter 로 만들어져있고 지도 api 는 Google map api 를 사용한다. map api가 잘 되어있어 생각보다 구현 난이도가 복잡하지는 않았다.
마커 디자인

먼저 지도에 표시할 마커를 디자인 했다. 최대한 우리 그라운드 플립 디자인에 어울리게 해봤는데 내 기준에서는 나름 만족스럽게? 된 것 같다! 😁😁 (공돌이에게 디자인은 어렵다…)
추후 사용량이 더 많아지면 실시간으로 정확한 숫자를 집계하기는 어려울 수도 있을 것 같다는 생각이 들어, 정확한 숫자를 보여주기 보다는 대략적인 숫자를 보여주도록 디자인 했다.
클러스터링 구현하기
GoogleMap 위젯에는 카메라에 대한 속성을 제어하고 확인 할 수 있다. 여기서 카메라는 화면에 보이는 지도 화면을 의미한다. 이 카메라 속성을 기반으로 우리가 설정해둔 임계 값을 벗어나게 지도를 축소하면 클러스터링 된 마커들을 지도에 뿌리도록 구현했다.
void updateMap() async {
if (_isMapOverZoomedOut()) {
pixels.value = [];
await updateClusteredPixelCountMarkers();
return;
} else {
markers.clear();
await updatePixels();
await updateCurrentPixel();
}
}이런식으로 지도를 업데이트 할 때 확대 여부에 따라 다른 데이터를 업데이트하게 하였다.
결과
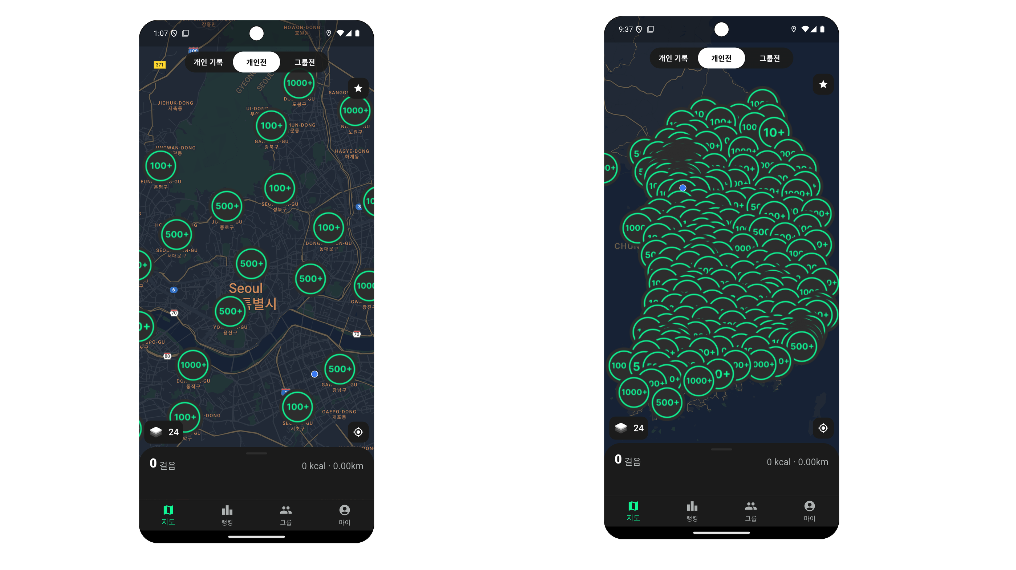
위 그림 처럼 각 시군구에 해당하는 위치에 마커가 잘 뜨는 것을 확인 할 수 있다. 하지만 여기서 간과한 것이 하나 있었다. 지도를 대한민국 전체가 보일정도로 축소하면 마커가 너무 많아 구분이 어렵다는 것이다! 그래서 내린 결론은 클러스터링 레벨을 2단계로 나누는 것이다.
어느 정도 축소하면 시군구 레벨로 클러스터링 하고 더 많이 축소하면 도, 광역시 레벨로 축소하는 것이다. 축소 정도는 각 앱에 따라 다를 수 있기 때문에 직접 실험해보고 정하는 것이 좋다.
2 단계 클러스터링
클라이언트 측에서 2단계 클러스터링을 구현할 필요는 없다. 클라이언트에서는 응답 받은 데이터만 지도에 표시하면 된다. 백엔드에서 클라이언트로부터 받은 반지름에 따라 응답해줄 클러스터링 된 데이터를 구분해서 보내주면된다.
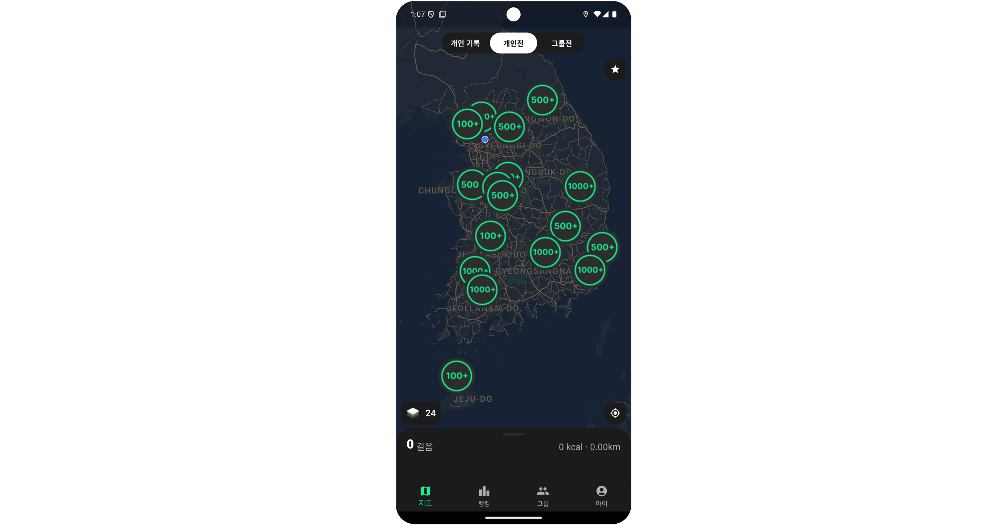
결과는 마커들이 촘촘이 붙어있을 때 보다 훨신 보기 좋다!
테이블에 2단계 클러스터링 추가
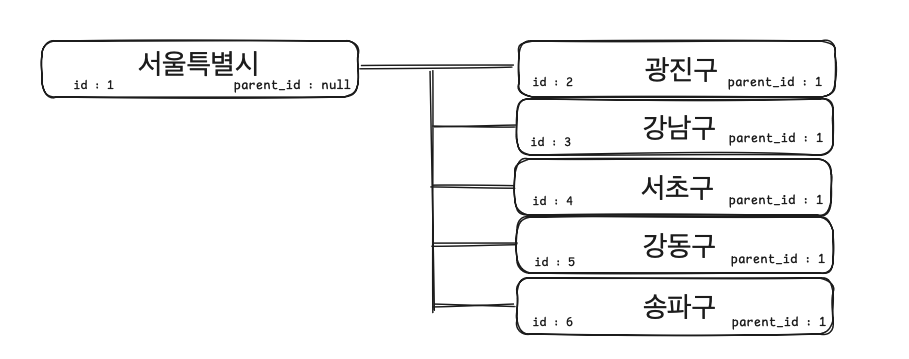
2단계 클러스터링을 위해 region 테이블에 parent_id, region_level 컬럼이 있다. 시군구 데이터 외에도 경기도, 서울특별시, 강원도 같은 상위 레벨 행정구역을 삽입하고 각 시군구 지역이 속한 상위 행정구역의 id를 parent_id 에 넣게 설계하였다.
이를 통해 pixel 데이터에는 시군구 id 만 있어도 어떤 상위 행정구역에 속하는지 판단 할 수 있다.
데이터를 집계하여 응답하는 로직
이제 마지막이다. 데이터를 지역별로 집계하여 응답하면 클러스터링이 완성된다!
집계 방식
매 요청마다 지역별로 땅의 개수를 count 하는 방법은 효율적이지 않다고 판단했다. 매번 집계한다면 DB의 부하가 증가 할 것이다. 이는 이 글의 경험으로 알 수 있었다. 따라서 미리 집계해두는 방식을 사용하려고 한다.
집계 방식 설명에 앞서 그라운드 플립에서 지도를 보여주는 방식은 3가지이다.
- 개인기록 : 개인 별로 지금 까지 방문한 모든 땅을 보여준다.
- 개인전 : 전체 사용자들을 대상으로 각 사용자들이 점령하고 있는 땅을 보여준다.
- 그룹전 : 전체 그룹을 대상으로 각 그룹이 점령하고 있는 땅을 보여준다.
여기서 방식을 크게 2가지 성격으로 나눌 수 있다. 개인기록은 개인에 맞춰서 데이터를 보여주어야 하고 개인전과 그룹전은 모든 사용자들에게 같은 데이터를 보여준다. 그래서 집계 방식을 2가지로 나누었다. 개인전과 그룹전은 지금부터 경쟁모드 라고 말하겠다.
집계 테이블 생성
이제 데이터를 집계 해둘 테이블을 생성해야한다. 개인 기록, 경쟁모드를 위한 2가지 테이블을 만들었다.
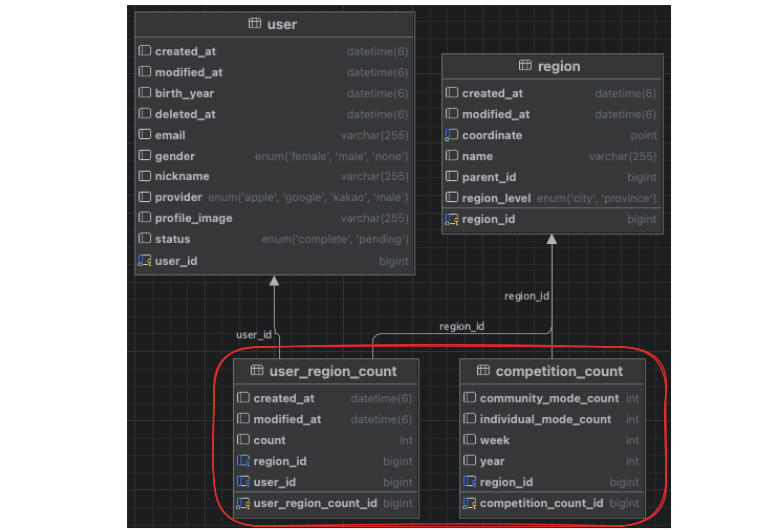
user_region_count 테이블은 개인기록을 집계하기 위한 테이블이다. 유저 별로 지역별 값을 다르게 가져야하기 때문에 user_id 컬럼이 존재한다. 어떤 지역의 집계 데이터인지 구별하기 위한 region_id 도 존재한다. 유저별로 모든 지역의 집계 데이터를 다 넣어두면 데이터가 많아진다. 따라서 유저가 방문한 지역의 데이터만 넣어두게 했다. 그리고 상위 행정구역의 데이터는 하위 행정구역의 집계 값을 합치면 얻을 수 있기에 따로 데이터를 넣지는 않았다.
competition_count 테이블은 경쟁 모드를 집계하기 위한 테이블이다. 모든 유저에게 동일한 데이터가 보여지기 때문에 유저 별로 데이터를 만들 필요가 없다. 그리고 경쟁전은 매주 일요일 자정에 초기화 되기 때문에 어떤 시기의 데이터인지를 판단하기 위한 week , year 컬럼이 있다. user_region_count 똑같이 지역을 구분하기위한 region_id 컬럼도 있고 개인전, 그룹전을 판단하기 위한 individual_mode_count , community_mode_count 가 있다.
집계 로직
집계로직은 간단하다. 땅을 방문하는 요청이 들어왔을 때 해당 땅이 속한 지역의 count 를 올려주면 된다.
- pixel 테이블에서 땅 조회
- pixel 데이터에서 region_id 에 해당하는 데이터를
user_region_count에서 찾은 후 count 를 1 추가하여 update- 없는 경우
user_region_count데이터 생성 후 update
- 없는 경우
- pixel 데이터에서 region_id 와 현재 날짜의 년도와 주차에 해당하는 데이터를 찾은 후
competition_countcount 를 1 추가하여 update- 없는 경우 현재 날짜에 해당하는
competition_count생성후 update
- 없는 경우 현재 날짜에 해당하는
집계 데이터 조회
api 스펙을 먼저 보자.
Endpoint
- Method:
GET - URL:
/{지도 모드}/clustered
설명
- Description: 지정된 좌표와 반경 내에 있는 클러스터링된 픽셀 정보를 반환합니다.
요청 파라미터
| Parameter | Type | Description | Constraints | Example |
|---|---|---|---|---|
current-latitude | double | 원의 중심 위도 | -90 ≤ value ≤ 90 | 37.503717 |
current-longitude | double | 원의 중심 경도 | -180 ≤ value ≤ 180 | 127.044317 |
radius | int | 반경 (미터 단위) | value ≥ 0 | 1000 |
응답
{
"data": [
{
"regionId": 1234,
"regionName": "광진구",
"count": 3,
"latitude": 37.6464,
"longitude": 127.6897,
"regionLevel": "CITY"
},
{
"regionId": 5678,
"regionName": "강남구",
"count": 5,
"latitude": 37.5172,
"longitude": 127.0473,
"regionLevel": "CITY"
}
],
}조회할 반경의 중심좌표와 반경의 반지름을 파라미터로 받아 응답한다.
조회 쿼리
요청된 반지름에 따라 시군구 레벨의 집계 데이터를 조회 할 지, 도,광역시 레벨의 집계 데이터를 조회 할 지로 나뉜다.
시군구 레벨
region 테이블에서 coordinate 가 반경안에 들어있고 region_level 이 “city” 인 데이터를 조회하고 해당 지역의 집계 데이터를 JOIN 하여 조회한다.
SELECT
r.region_id,
ST_LATITUDE(r.coordinate) AS latitude,
ST_LONGITUDE(r.coordinate) AS longitude,
r.name,
cc.individual_mode_count AS count
FROM
region r
JOIN competition_count cc
ON r.region_id = cc.region_id
WHERE
ST_CONTAINS((ST_Buffer(:center, :radius)), r.coordinate)
AND r.region_level = 'city'
AND cc.week = :week
AND cc.year = :year
AND cc.individual_mode_count > 0;도,광역시 레벨
region 테이블에서 coordinate 가 반경안에 들어있고 region_level 이 “province” 인 데이터를 조회하고 해당 지역의 하위 지역의 집계 데이터를 SUM 하여 조회한다.
SELECT
p.region_id,
ST_LATITUDE(p.coordinate) AS latitude,
ST_LONGITUDE(p.coordinate) AS longitude,
p.name,
SUM(cc.individual_mode_count) AS count
FROM
region p
JOIN region r
ON p.region_id = r.parent_id
JOIN competition_count cc
ON r.region_id = cc.region_id
WHERE
p.region_level = 'province'
AND cc.week = :week
AND cc.year = :year
AND cc.individual_mode_count > 0
GROUP BY
p.region_id;응답
이렇게 조회된 데이터를 api 스펙에 맞게 잘 가공하여 클라이언트에 전달한다. 시군구를 반환할지, 도, 광역시를 반환할지는 실제 앱으로 렌더링 해보며 테스트를 통해 적절한 값을 찾아야한다.
결과
결과는 위 영상처럼 2단계 클러스터링이 정상적으로 동작하는 것을 확인 할 수 있었다!
마무리
마커 클러스터링은 사실 개발 초기부터 생각했던 기능이었다. 하지만 그 당시에는 구현할 적당한 방법이 떠오르지 않아 구현하지 못한채 첫 출시를 했어야 했다. 하지만 지금 이라도 구현할 수 있어서 뿌듯하다. 작은 기능 같지만 사용자 경험에서 큰 장점을 가져온다 생각한다. 혹시나 지도기반 앱을 만들고 있다면 꼭 넣어보길 추천한다!
한가지 걱정되는 점도 있다. 지금은 대한민국만 서비스하고 있어 이 정도 지역으로 가능하다. 하지만 후에 글로벌화를 한다면 각 나라에 맞는 클러스터링 레벨을 찾아야할 텐데 이 부분이 좀 걱정된다… 글로벌화 하면 나라별 클러스터링도 추가해야할 듯 하다.
그리고 지역이 평생 바뀌지 않는 것이 아니다. 시간이 지나면 행정구역의 경계가 변할 텐데 그때 마다 업데이트 하는 작업도 필요할 것 같다.
마커 클러스터링에 대한 백엔드 레퍼런스가 거의 없어 고생했지만 만족할 만한 결과가 나와서 기분이 좋다. 사용자들도 좋게 써주면 좋겠다!
